
个人主页:秋风起,再归来~
系列专栏:C++从入门到起飞
克心守己,律己则安
目录
前置声明:本文章对于list常用简单的接口不会介绍!
1、迭代器

假如我们想要在list的正向迭代器后的第三位置插入一个2,在上面的这种写法就不再支持了!而我们之前在string和vector的使用时这样玩是完全没有问题的!那是为什么呢!
通过查阅文档资料,我们可以发
现在list下的的迭代器是bidirectional iterator(双向迭代器)

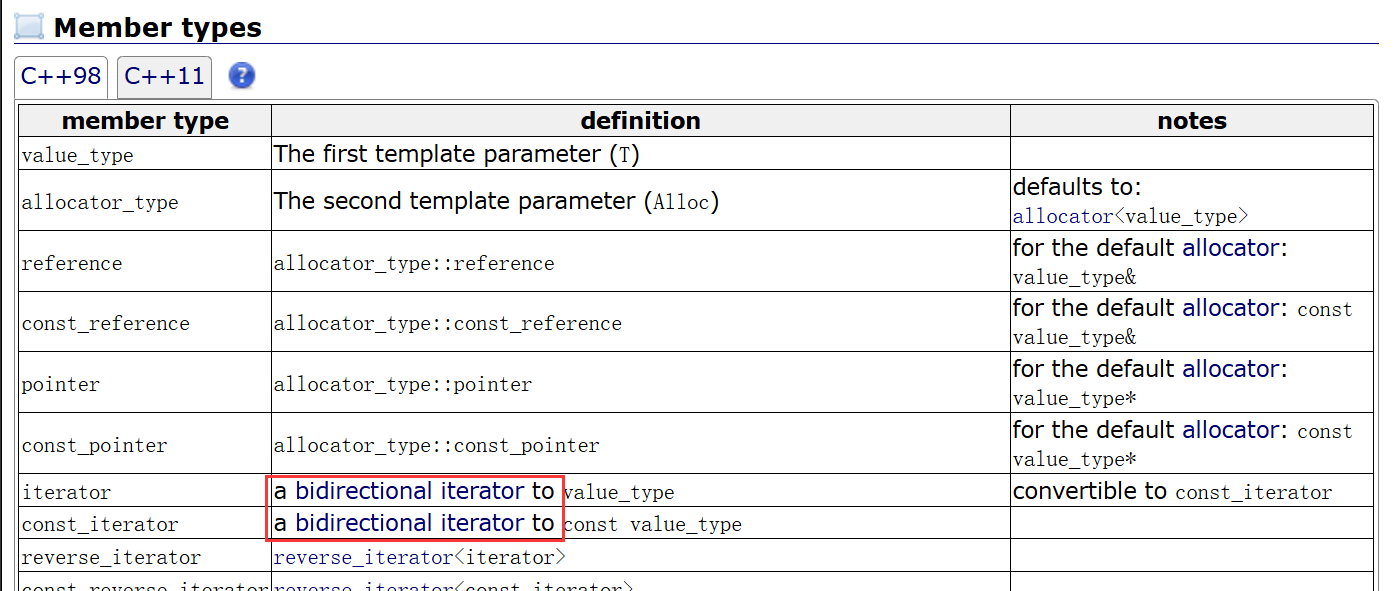
那双向迭代器又是什么意思呢?下面我就和大家总结一下迭代器从功能和性质上的分类:
>从功能上可分为以下四种:
1、正向迭代器
2、反向迭代器
3、正向常量迭代器
4、反向常量迭代器
所有容器的迭代器都具有以上四种功能,用起来也比较简单。
>从性质上可分为以下四种:
1、随机迭代器(RandomAccessIterator):string、vector、deque……(支持操作++ /-- / + / -)
2、双向迭代器(BidirectionalIterator):list、map、set……(支持操作++ /-- )
3、单向迭代器:forward_list、unordered_map……(支持操作++)
容器间迭代器性质上的差异是由容器的底层结构来决定的!而底层结构又决定容器可以使用库里面哪些算法
举个栗子:
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
sort(lt.begin(), lt.end());这段代码在编译上并没有报错,不过在运行时就有问题了!


我们可以看到,库里面Sort的参数必须是随机的迭代器,因为该Sort的底层是快排,涉及到了迭代器的+和-的操作。
我们还可以注意到第三个参数comp,这其实是一个比较器。这里只演示一下比较器的用法,其底层后面会详细讲解!
vector<int> v;
v.push_back(3);
v.push_back(4);
v.push_back(1);
v.push_back(7);
v.push_back(5);
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
sort(v.begin(), v.end());
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
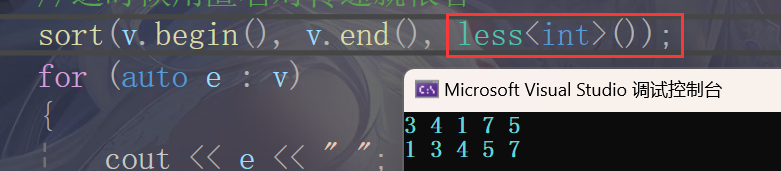
在默认情况下,Sort是按照从小到大的顺序排列元素的,如果我们想要按从大到小的顺序排列的话,我们就可以再传递一个比较器!
//greater<int> g;
//sort(v.begin(), v.end(),g); 有名对象这里用的有点烦
//这时候用匿名对传递就很香
sort(v.begin(), v.end(), greater<int>());
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
当然,也有小的比较器,这里我们还是要知道一下(效果其实和默认的没什么区别)!
>我们再来看看reverse:


要求传双向迭代器,不过我们也要明白这里不仅可以传双向迭代器,也可以传随机迭代器,毕竟随机迭代器是特殊的双向迭代器。
>我们再来看看find:

Find里面可以传递所有类型的迭代器!
2、push_back与emplace_back
先说结论,push_back与emplace_back的最终效果都是尾插一个元素,不过emplace_back在某些情况下比push_back的效率要更高一些!
下面举一个代码示例:
class A
{
public:
A(int a1 = 0, int a2 = 0)
:_a(a1)
, _b(a2)
{
cout << "A(int a1 = 0, int a2 = 0)" << endl;
}
A(const A& aa)
:_a(aa._a)
, _b(aa._b)
{
cout << "A(const A& aa)" << endl;
}
private:
int _a;
int _b;
};
void test3()
{
list<A> lt;
A a1(3, 3);
lt.push_back(a1);//有名对象传参
lt.push_back(A(2,2));//匿名对象传参
//lt.push_back(3,3); 报错!
A a2(3, 3);
lt.emplace_back(a2);
lt.emplace_back(A(2, 2));
cout << endl;
lt.emplace_back(3,3);//emplace_back还支持直接传递构造A对象的参数!那emplece_back到底高效在哪些地方呢?
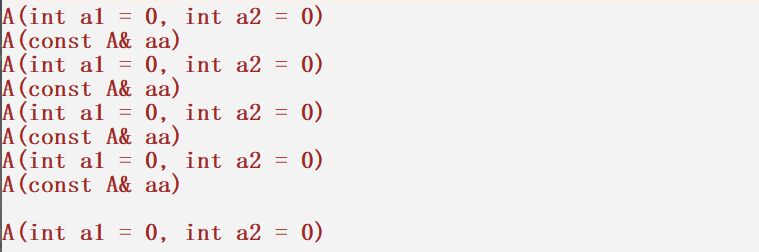
通过函数调用在屏幕上打印的结果我们发现,前面的传参都是构造加拷贝构造,唯有最后的传参是直接调用构造而并没有调用拷贝构造。这说明emplace_back的直接传递构造对象的参数是可以减少拷贝构造的,这也在一定程度上提高了效率。
至于其底层原理还不是我们目前可以明白的,以后我们再细说啦~
3、list成员函数sort与库sort比较
由于不能直接使用库里面的sort,所以list自己实现了一个sout(底层实际上用的是归并)
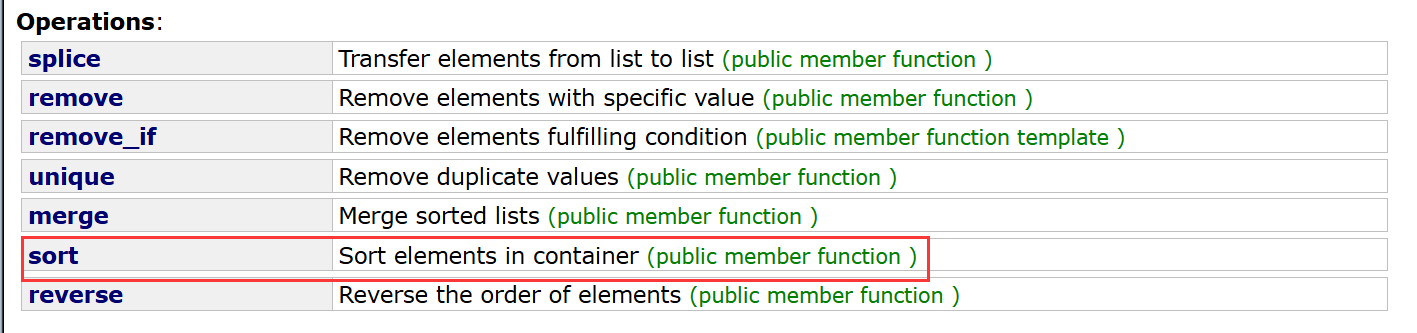
下面我们来比较一下在相同数据情况下vector调库里面的sort和list调自己的sort性能之间的优劣
srand((unsigned int)time(nullptr));
const int N = 1000000;
list<int> lt1;
vector<int> v;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
v.push_back(e);
}
int begin1 = clock();
// 排序
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);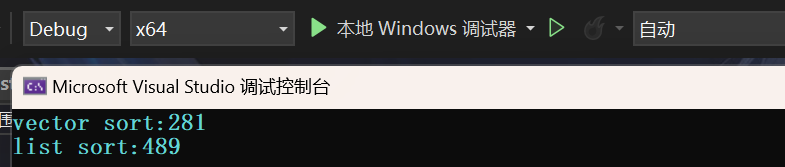
在debug模式下,库里面的sort略胜一筹
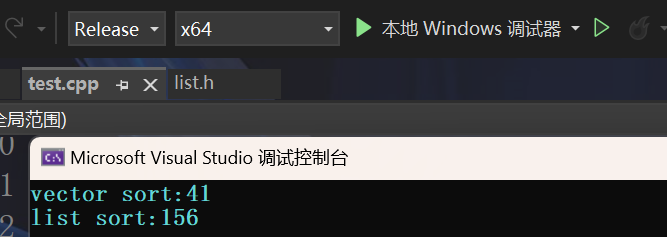
release模式下速度是list的将近4倍!
>下面我们再来看一段更有意思的比较!
下面这段代码主要的意思我们先在lt1和lt2中存储相同的数据,我们再分别计算两段时间进行比较!
第一段计算的时间是我们先把lt1中的数据拷贝到v中,在通过v调用库里面的sort来排序,最后再从v中将有序的数据拷贝回lt1中。
第二段计算的时间是我们直接通过lt2调用自己的sort来将数据进行排序!
void test_op2()
{
srand(time(0));
const int N = 1000000;
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
lt2.push_back(e);
}
int begin1 = clock();
// 拷贝vector
vector<int> v(lt2.begin(), lt2.end());
// 排序
sort(v.begin(), v.end());
// 拷贝回lt2
lt2.assign(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
printf("list copy vector sort copy list sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);
}

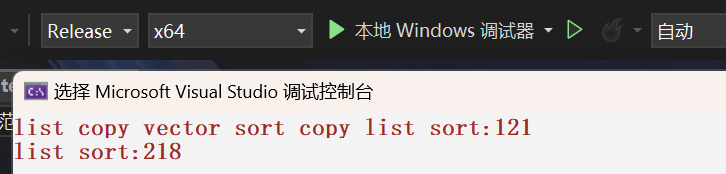
不过,在release发行版本下,第一段的速度依旧接近你的2倍!
通过这段测试想要告诉你们的是list内部实现的sort用起来方便,可效率却不高,我们写程序首先要确保层序的正确性,二是要追求程序的高效与安全!我们以后在用list存储数据进行排序时最好不要用它内置的sort,绕一下弯就可以大大提高效率!
4、merge
接口merge的主要功能是合并两个链表(但是要注意其中一个链表会变空,相当于把其中一个链表的节点连接到另一个链表的后面去了!)
std::list<double> first, second;
first.push_back(3.1);
first.push_back(2.2);
first.push_back(2.9);
second.push_back(3.7);
second.push_back(7.1);
second.push_back(1.4);
first.sort();
second.sort();
first.merge(second);
// (second is now empty)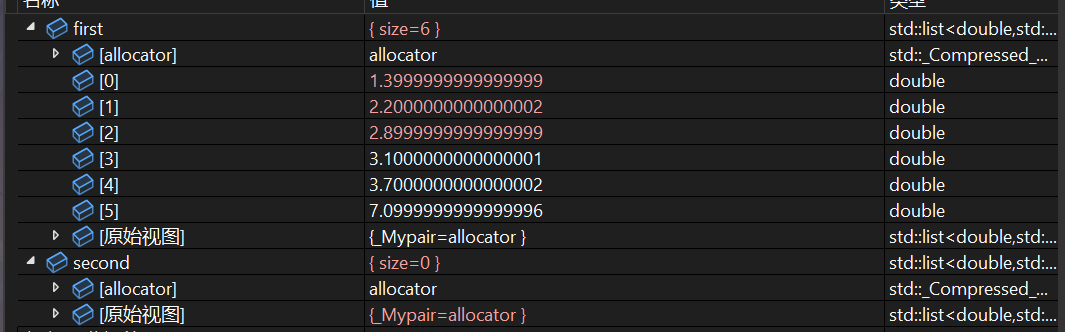
合并后链表是有序的!
注意:使用该接口时要确保两个链表的数据是有序的并且类型要匹配!
5、unique
unique是去重算法,使用的前提条件是链表必须有序!
std::list<int> lt;
lt.push_back(3);
lt.push_back(1);
lt.push_back(2);
lt.push_back(4);
lt.push_back(4);
lt.push_back(5);
lt.push_back(5);
lt.push_back(5);
lt.sort();
lt.unique();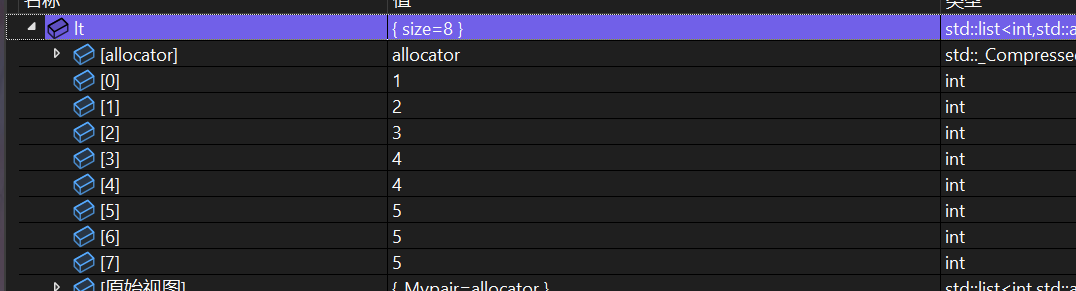

6、splice

用splice 将lt2的所有元素剪切到 lt.end()前面!
std::list<int> lt;
std::list<int> lt2;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt2.push_back(2);
lt2.push_back(3);
lt2.push_back(4);
lt2.push_back(5);
lt.splice(lt.end(),lt2);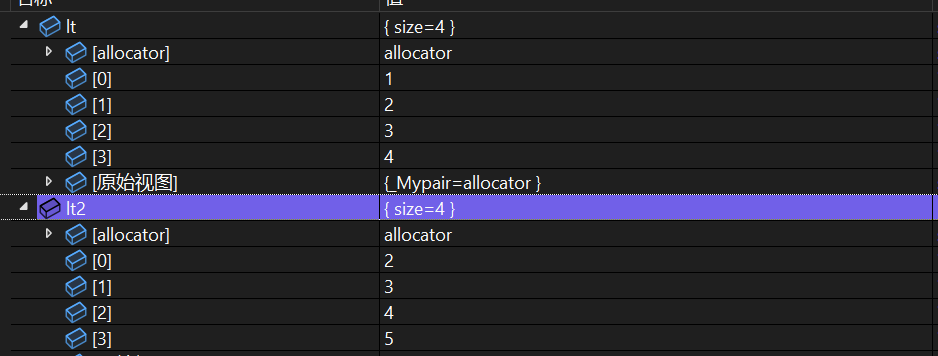
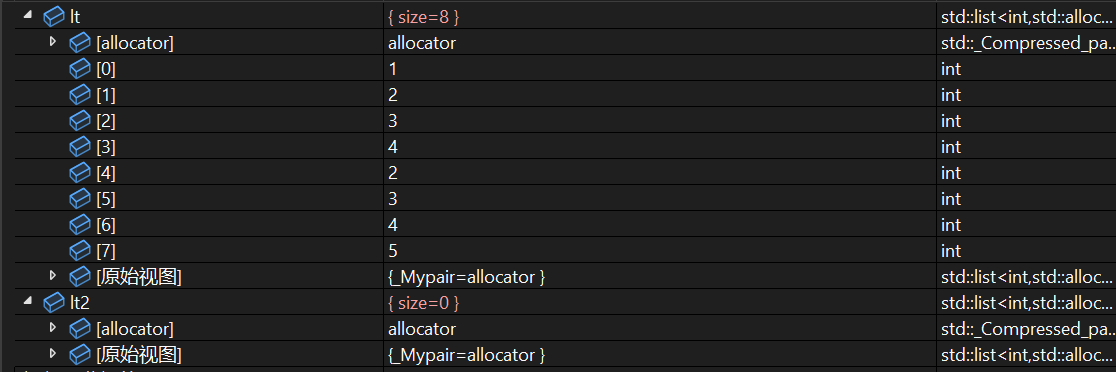
用splice将lt2的第一个元素剪切到 lt.begin()前面!
lt.splice(lt.begin(),lt2,lt2.begin());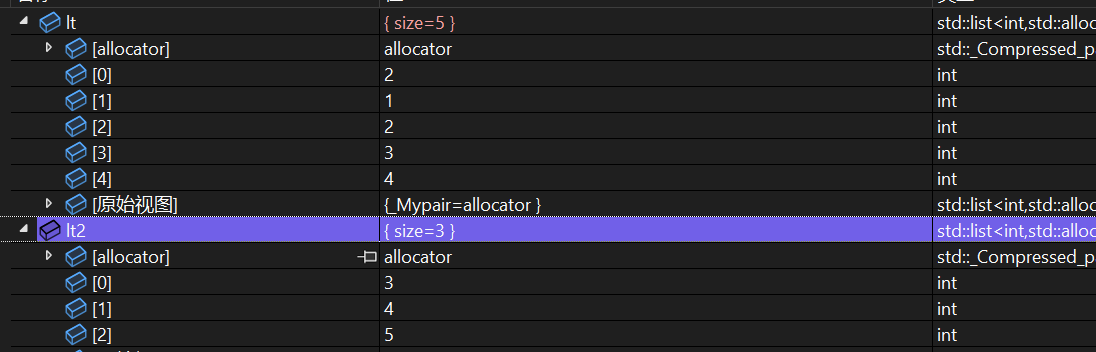
还可以将自己的元素进行剪切拼接!
假如我想要将元素5插入到2前面,我们可以这样操作!
std::list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.push_back(6);
auto pos1 = find(lt.begin(), lt.end(), 2);
auto pos2 = find(lt.begin(), lt.end(), 5);
lt.splice(pos1,lt,pos2)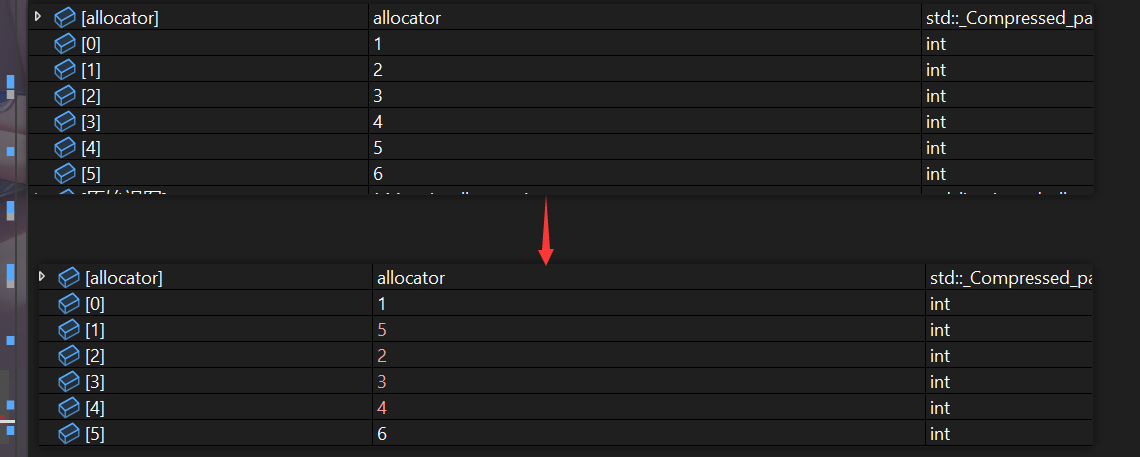
7、完结散花
好了,这期的分享到这里就结束了~
如果这篇博客对你有帮助的话,可以用你们的小手指点一个免费的赞并收藏起来哟~
如果期待博主下期内容的话,可以点点关注,避免找不到我了呢~
我们下期不见不散~~


本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » C++从入门到起飞之——list使用 全方位剖析!

发表评论 取消回复