布隆过滤器
布隆鸟过滤器(Bloom Filter)是一中数据结构,由一个bit数组和多个hash函数构成,可以用于快速判断某个元素是否在某个集合里面。相比于传统的哈希表,更加节省空间,但存在一定的误报率(false positives),即可能会错误地报告一个元素存在于集合中,但实际上并不存在。
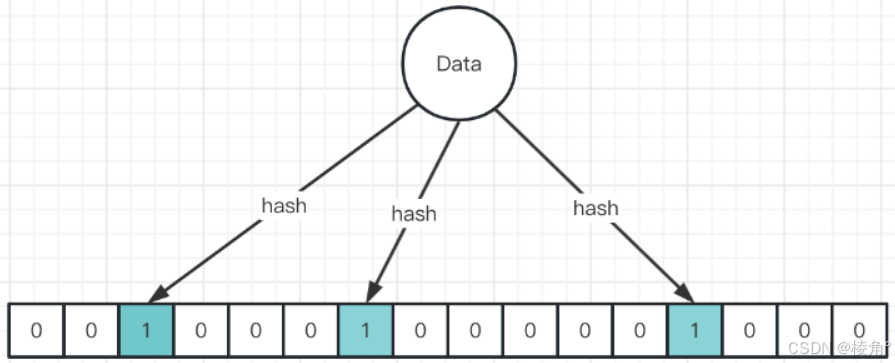
布隆过滤器的基本原理
- 初始化:
- 布隆过滤器由一个很长的二进制bit数组和 k 个独立的哈希函数组成。
- 位数组初始化时所有位都是0。
- 插入操作:
- 当一个元素被加入到布隆过滤器时,它会通过多个不同的哈希函数进行哈希。
- 每个哈希函数会产生一个索引位置,该位置在位数组中对应的位会被设置为1。
- 查询操作:
- 查询一个元素是否存在时,同样使用k个哈希函数计算出位数组中的索引位置。
- 如果所有这些位置上的值都为1,则认为该元素可能存在于集合中;否则确定该元素不在集合中。
优点:
- 因为只存储0或1,在只需要判定元素是否存在的情况下,极大地节省存储空间。
- 插入和查询的时间复杂度接近O(1),非常高效。
缺点:
- 无法删除元素(因为直接把某个元素的key都置为零会影响到其它元素),只能增加或者查询元素
- 只能准确判断元素不存在,若判定某个元素存在集合中,有误判的可能(可通过添加多个hash函数来解决),不容许误判的场合不适用
- 只是判断元素是否存在,没有进行冲突处理
应用场景
布隆过滤器适用于对存储空间敏感且可以接受一定误报率的场景,例如:
- 解决缓存穿透问题,比如查询redis前先经过布隆过滤器,那些不存在于MySQL的数据就会被提前过滤掉
- 网络爬虫中过滤已访问的网页URL。
- 数据库系统中快速判断一个键是否存在于大型数据集中。
- 内存缓存系统中检查数据是否已被缓存。
- 黑名单或白名单的实现。
由于布隆过滤器的这些特性,它在大数据处理、数据库优化以及网络应用中都有广泛的应用。
如何降低误判率?
增加hash函数个数
如何实现过滤?
被布隆过滤器判定为不存在集合中的元素可以直接排除掉(实现过滤),当然,被布隆过滤器判定存在时,只是可能存在,需要要做进一步判定,这就是过滤的意义,把绝大多数不存在的情况先排除掉,剩下的小部分情况做特殊操作。
面试问到布隆鸟过滤器是什么怎么回答?
布隆鸟过滤器是一个数据结构,由一个bit数组和多个hash函数构成,可以用于快速判断某个元素是否在某个集合里面。它的基本工作原理是:当添加一个元素到集合里的时,依次通过各个hash函数去计算对应的hash值,每个hash值对应bit数组的一个位置,让对应位置的都置为1。然后要判断某个元素是否在集合里面时,只需要依次判断对应hash值的位置的值是否全为1即可,如果不是全为1则说明不在集合里,如果全为1则说明在集合里(当然全1的情况可能存在误判)。
布谷鸟过滤器
布谷鸟也就是纠缠雀巢中的“鸠”,习惯于把蛋下在别人的鸟窝,然后占领别人的地盘。
布隆过滤有一个很严重的问题就是无法删除元素,这样会导致误判率越来越高。
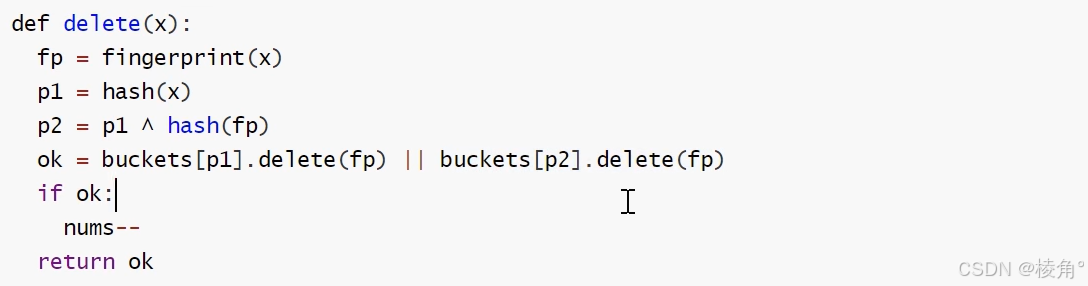
布谷鸟过滤器有2个hash函数,插入时是让hash值对应位置存入数据的指纹信息,而不是像布隆过滤器一样存入0或1,如果所有hash值对应位置已经有指纹信息,则换下一个,全都有则随机踢走一个,然后给踢走的元素重新找一个位置。
数据结构
注:布谷鸟过滤器里面存储的不是0和1,而是原数据的指纹信息,放在桶里面,空间占用非常小。

如何添加数据?
依次往两个位置尝试添加

都不行则随机抢占一个位置,然后让被抢占的元素重新找位置

注意:只有第一个hash计算时需要用到原数据x;计算后续hash值的时候不需要对原数据x做hash,只需要对其指纹做hash然后和上一个hash做异或即可
如何判断某个元素在不在集合里面?
只需要查找两个hash位置对应的桶里有没有元素的指纹即可,

删除过程?
如何降低误判率?
增加hash函数个数;进行分块;扩容
优点:
- 查找、插入速度快,空间占用率低
- 支持删除元素
缺点:
-
实现相对复杂。
-
因为指纹信息也可能重复,也有误判的情况,把不存在的判定为存在了;另外,还有误删除(删除一个不存在的元素时把真实存在的元素删除了)的可能
-
插入性能可能会随着冲突的增加而显著下降,因为需要重新定位现有元素
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 布隆过滤器和布谷鸟过滤器

发表评论 取消回复