
一.实例:
1.用算法表白:“爱你n遍”。
#include<stdio.h>
//算法1:逐步递增型爱你
void loveYou(int n) //n为问题规模
{
int i=1; //爱你的程度 --> 设为语句1
while(i<=n) //设为语句2
{
i++; //设为语句3
printf("I love you %d \n",i); //设为语句4
}
printf("I love you more than %d \n",n); //设为语句5
}
int main() //程序入口
{
loveYou(3000); //调用函数,表达爱意
return 0;
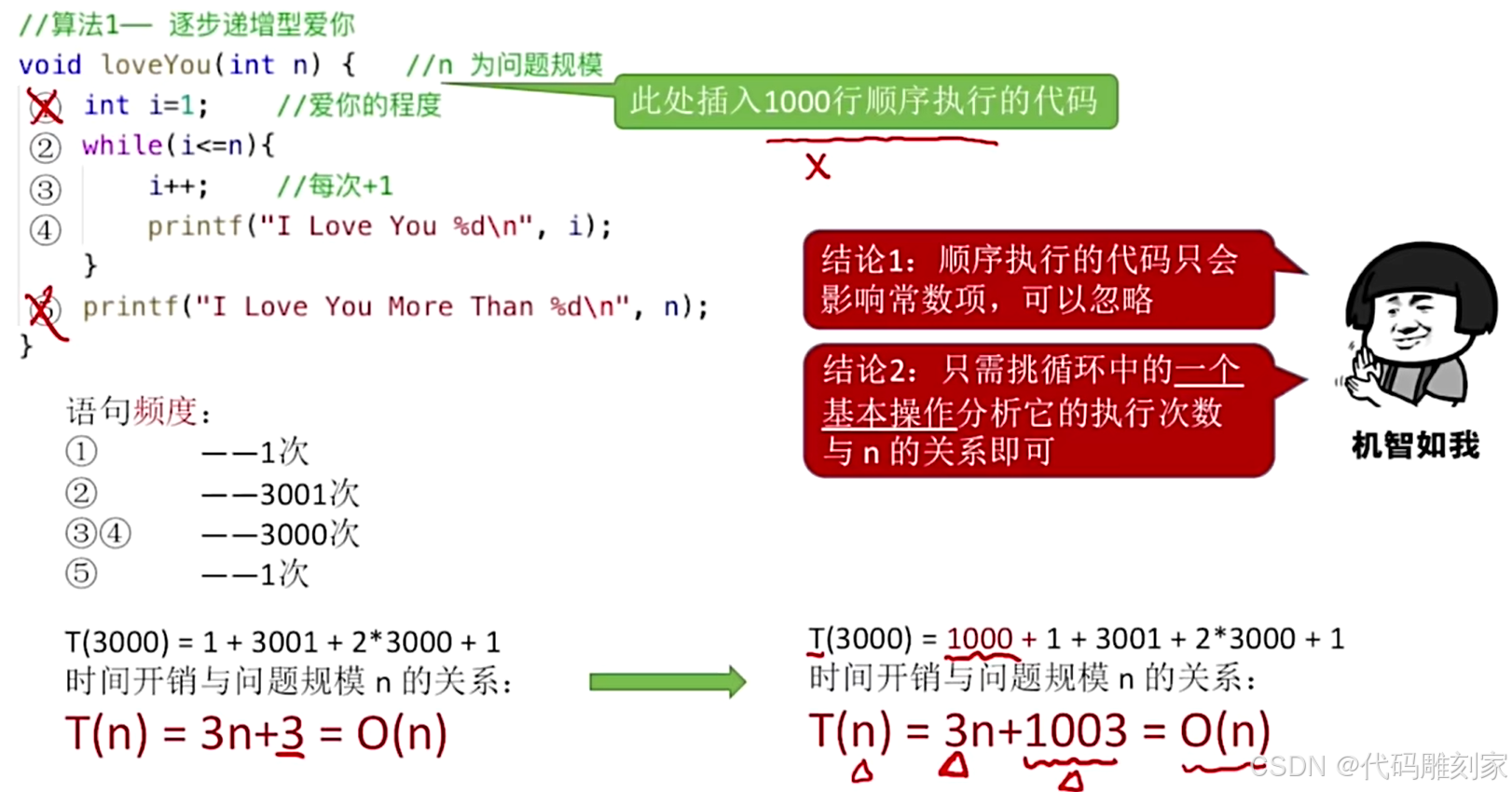
}假设上述标记的5条语句执行时间相同(实际上时间不同,但考虑太多外在条件,就难以论述时间复杂度)
语句频度:
语句1-->只执行一次,因为顺序结构
语句2-->执行了3001次,前3000次是符合i<=3000(i初值为1,n为3000,最后一次是i为3000时进行循环后i为3001,最后
进行了一次循环条件的判断,发现不符合,跳出循环)
语句3-->执行了3000次,因为只有进入循环才执行i++,循环了3000次
语句4-->执行了3000次,因为只有进入循环才执行该语句,循环了3000次
语句5-->只执行一次,因为顺序结构
所以,当问题规模n为3000时,就会花费T(3000)=1+3001+3000 * 2+1=3000 * 3+3
-->时间开销与问题规模n的关系:T(n)=3n+3
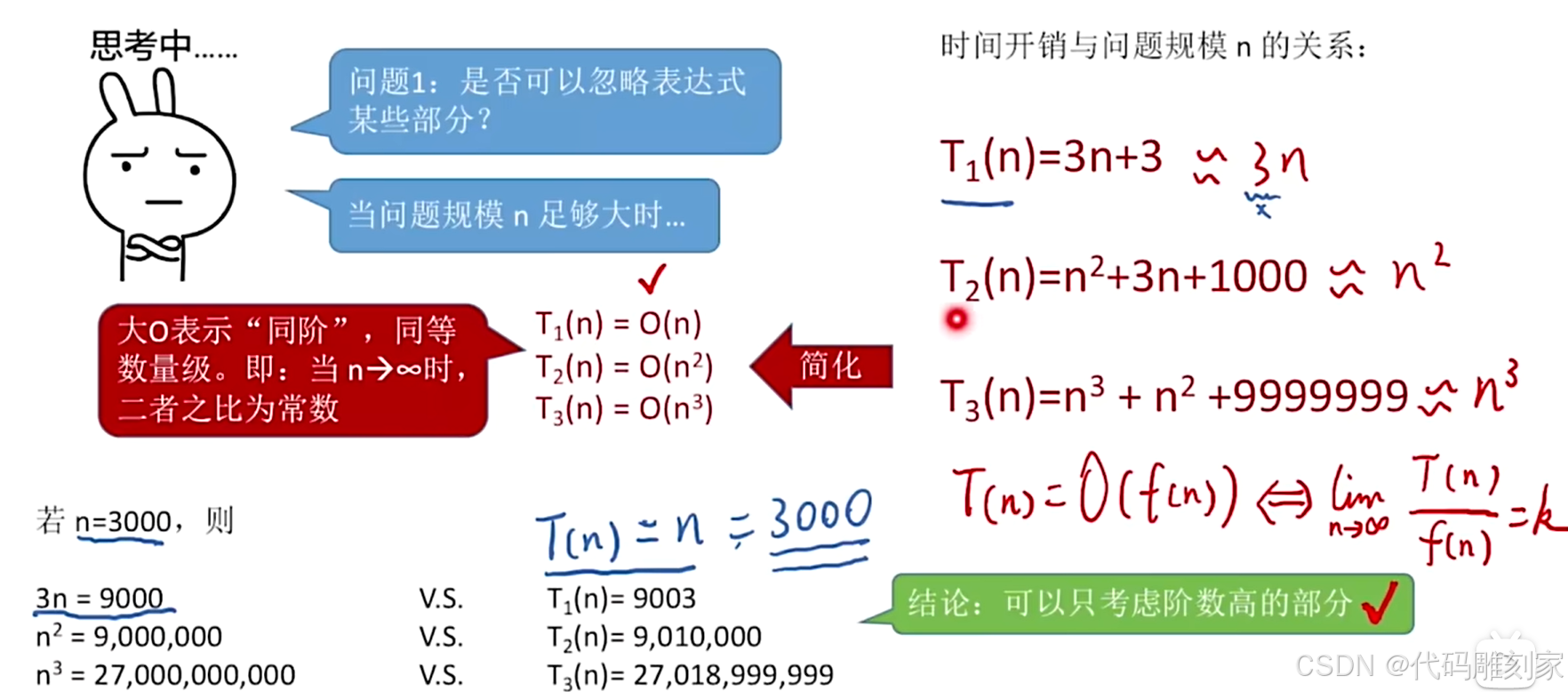
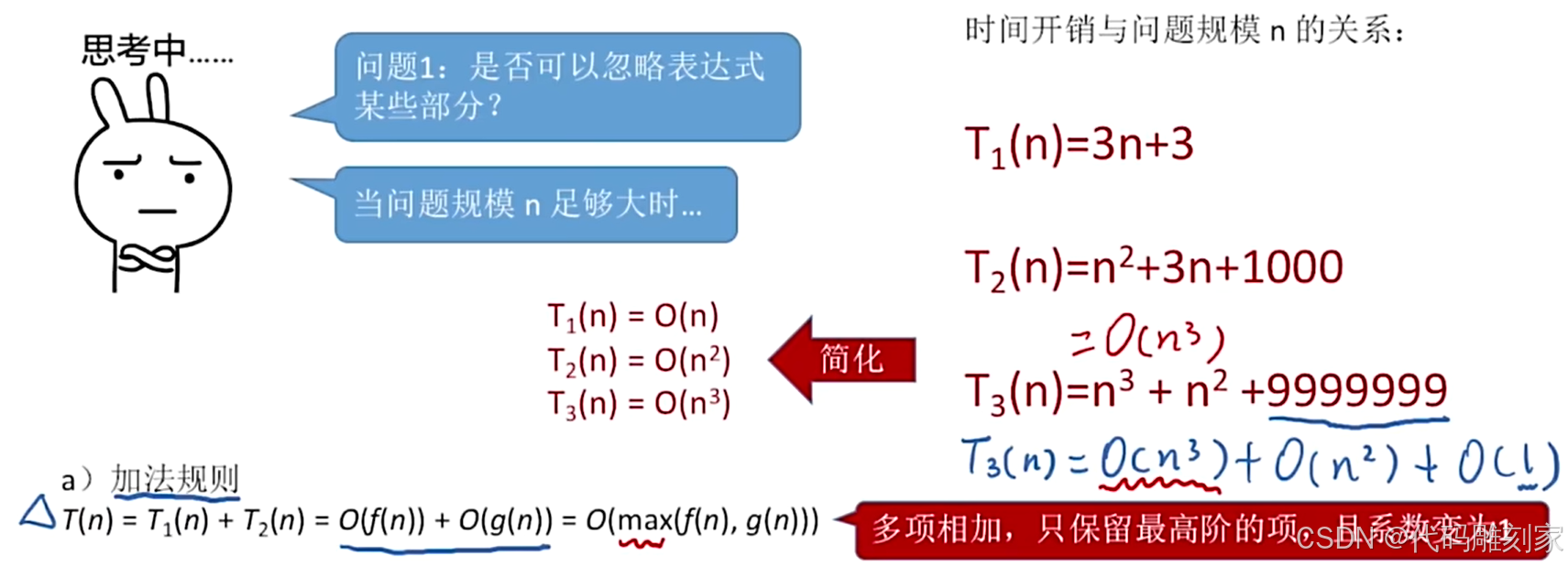
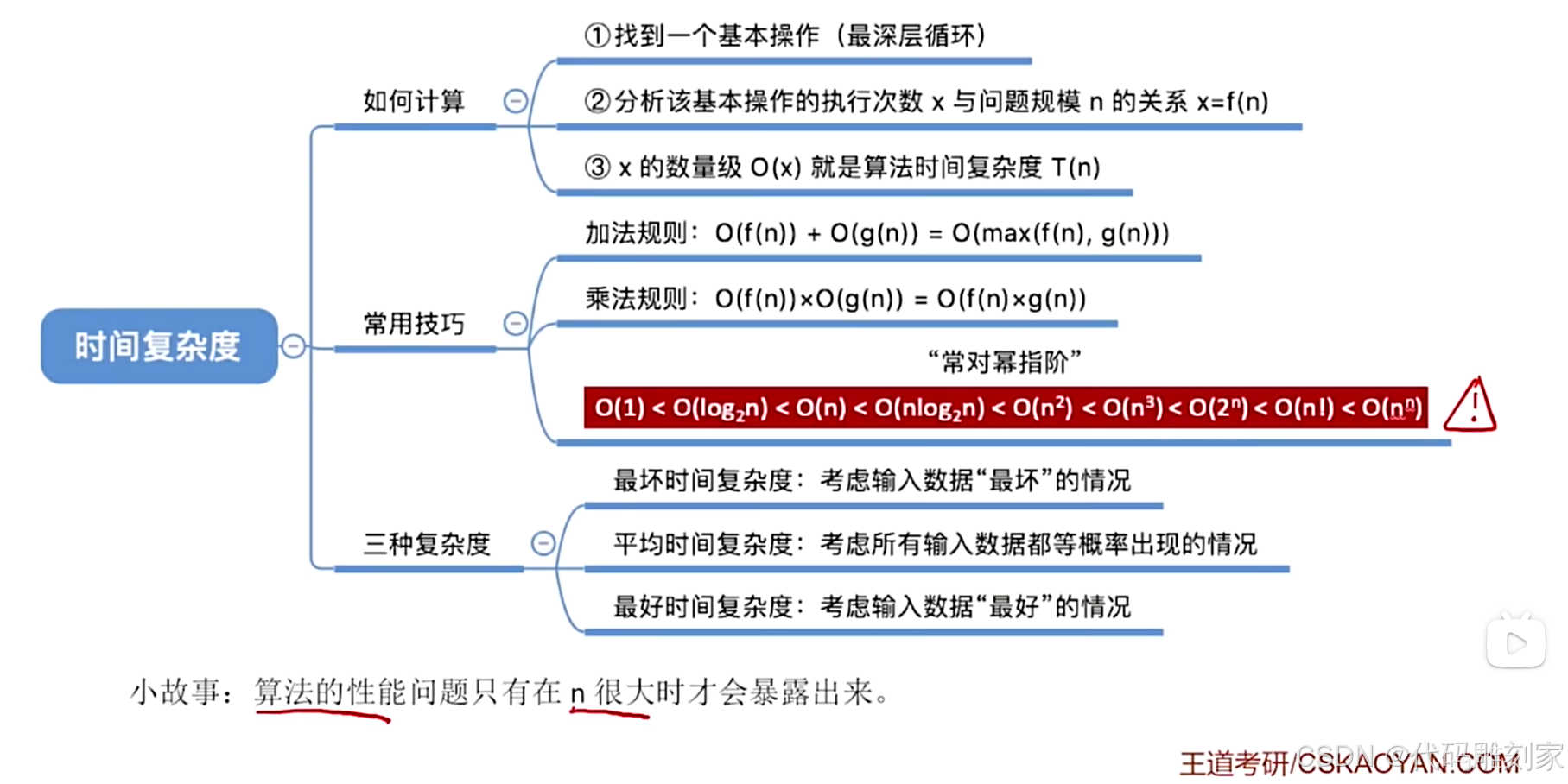
问题1:是否可以忽略时间复杂度表达式中的某些部分?
例如:T1(n)=3n+3,T2(n)=n * n +3n+1000,T3(n)=n * n * n + n * n + 9999999
当问题规模n足够大时,时间复杂度表达式中低阶的部分就可以忽略不计,因为最终差距相对没多大
且最高阶的问题规模n的系数可以化为1,常数可化为1,因为都是一个定值。

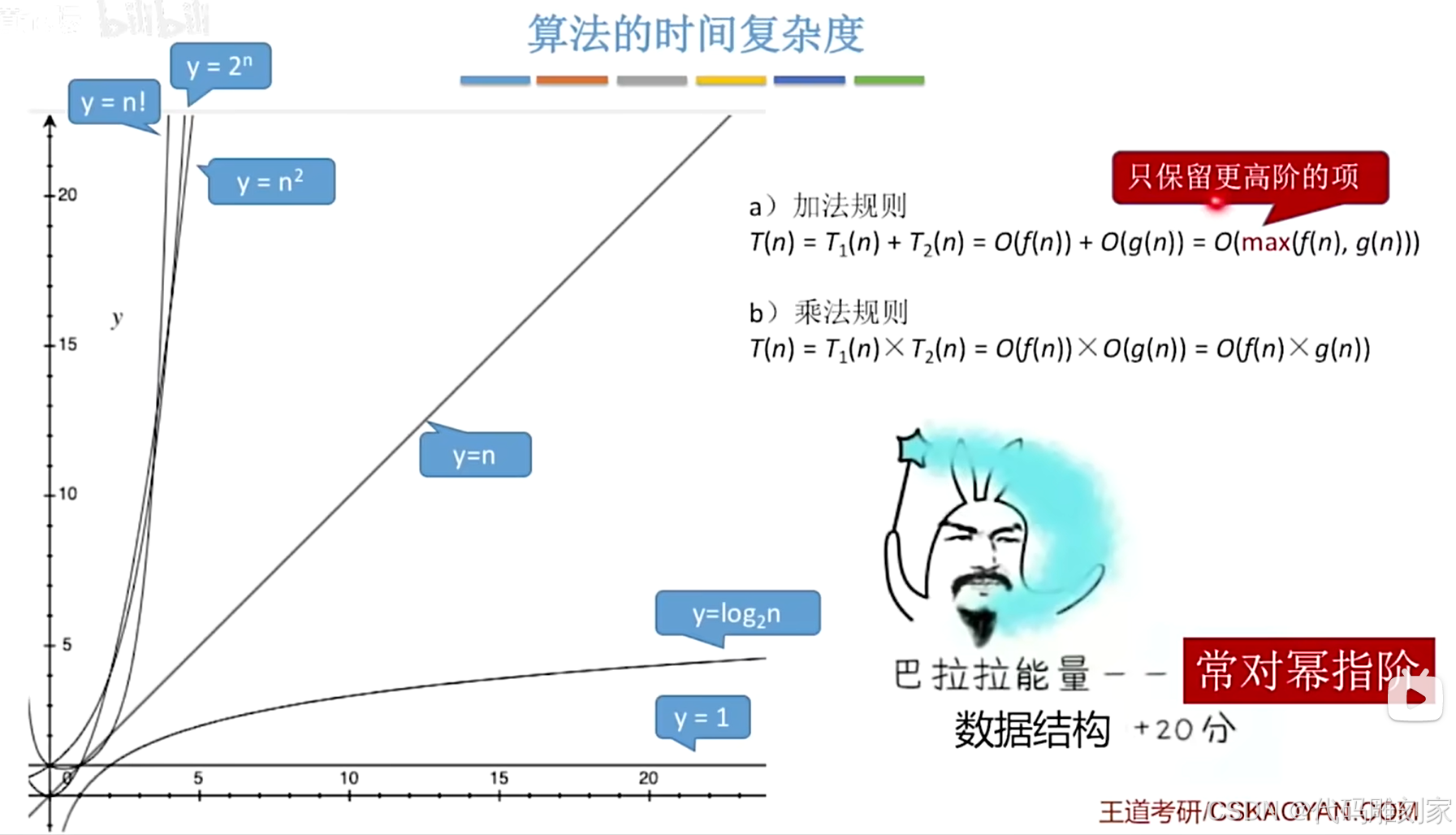
算法时间复杂度大小关系:越大代表阶数越高

解答:

问题2:如果有好几千行代码,难道要按这种方法一行一行数去统计代码的时间复杂度?
解答:


二.练习:
例一:

例如当循环一次时,i为2;循环两次时,i为4-->成等比数列
多一次是跳出循环时的判断
例二:


三.总结:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 算法的时间复杂度

发表评论 取消回复