Java技术栈 —— Spark入门(二)
参考文章:
| 参考文章或视频链接 |
|---|
| [1] 《Kafka + Spark Stream实时WordCount》 |
实验环境:
假设你的用户为root,以下软件安装路径为/opt
| 软件版本 |
|---|
| spark: 3.5.2 (scala 2.12) |
| kafka: 3.8.0 (scala 2.13) |
实验结构图
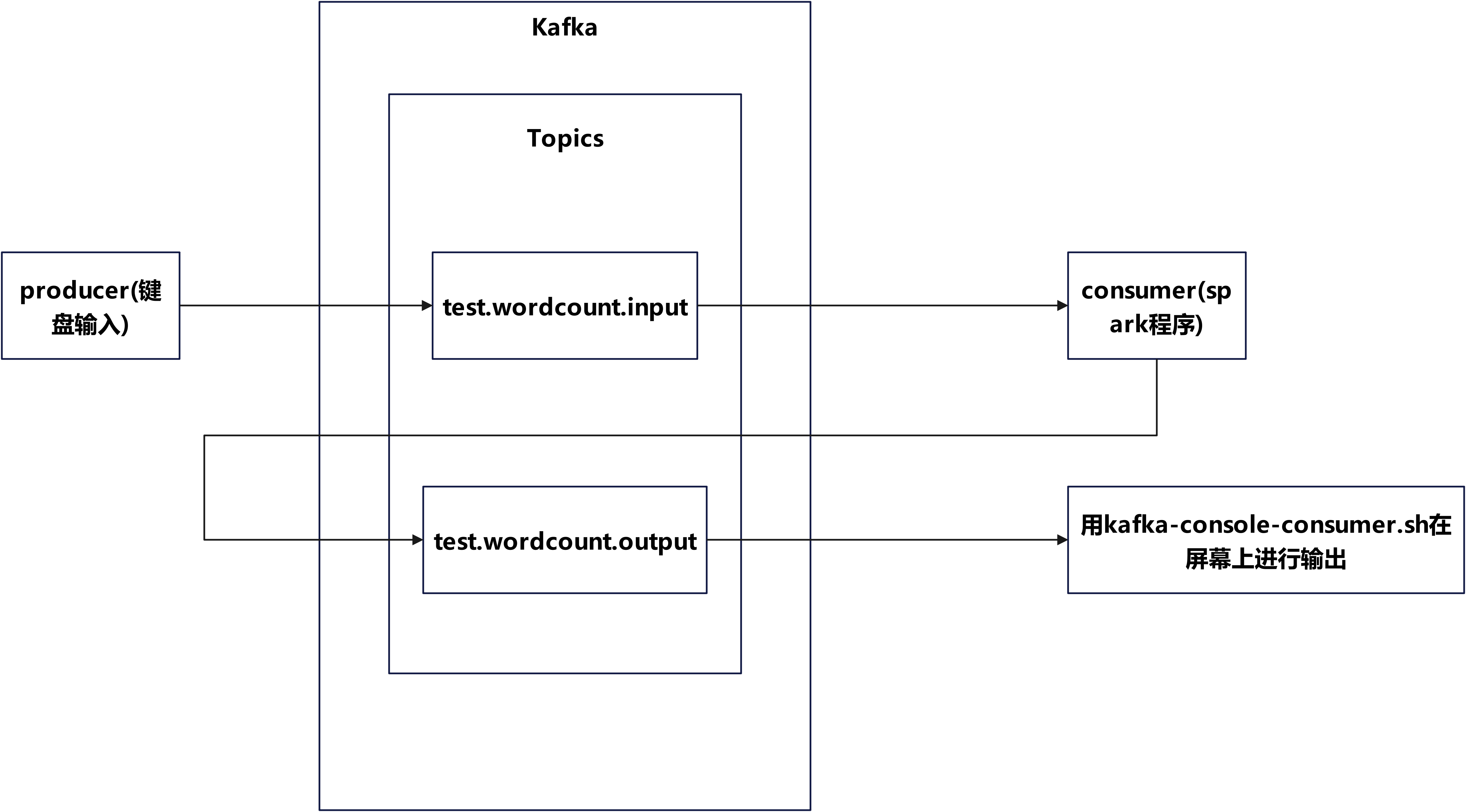
一、kafka
1.1 创建topic
# 创建input
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test.wordcount.input --partitions 1 --replication-factor 1
# 创建output
bin/kafka-topics.sh --bootstrap-server localhost:9092 --create --topic test.wordcount.output --partitions 1 --replication-factor 1
1.2 准备input与查看output
# 打开两个terminal终端
# 准备键盘输入作为prodcuer
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test.wordcount.input
# 在屏幕上查看输出
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test.wordcount.output
二、spark
2.1 spark下的程序文件
# coding=utf-8
# /opt/spark-3.5.2-bin-hadoop3/jobs/pyjobs/kafka-wordcount.py
from __future__ import print_function
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql import functions as F
bootstrapServers = "localhost:9092"
spark = SparkSession\
.builder\
.appName("StructuredKafkaWordCount")\
.getOrCreate()
# 基于来自kafka的数据流,创建dataframe
lines = spark\
.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers", bootstrapServers)\
.option("subscribe", "test.wordcount.input")\
.option("failOnDataLoss", False)\
.option("group.id", "wordcount-group3")\
.load()\
.selectExpr("CAST(value AS STRING)")
# 将单行数据拆分,转成多行数据
words = lines.select(
explode(split(lines.value, ' ')).alias('word')
)
# 对单词进行分组,并计算总数
wordCounts = words.groupBy('word').count()
# 将两列数据合并成单列数据
wordCounts = wordCounts.select(F.concat(F.col("word"), F.lit("|"), F.col("count").cast("string")).alias("value"))
# 测试时,可以不将结果写入kafka,直接输出到控制台
# query = wordCounts \
# .writeStream \
# .outputMode("complete") \
# .format("console") \
# .start()
# 将结果输出到 test.wordcount.output
query = wordCounts \
.writeStream \
.format('kafka') \
.outputMode('update') \
.option("kafka.bootstrap.servers", bootstrapServers) \
.option('checkpointLocation', '/spark/job-checkpoint') \
.option("topic", "test.wordcount.output") \
.start()
query.awaitTermination()
2.2 用spark-submit提交作业
# 提交Spark作业,这个过程需要保证网络畅通,会将一些依赖下载到/root/.ivy2/jars目录下
$SPARK_HOME/bin/spark-submit \
--packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.2,\
org.apache.kafka:kafka-clients:3.5.2 \
/opt/spark-3.5.2-bin-hadoop3/jobs/pyjobs/kafka-wordcount.py
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Java技术栈 —— Spark入门(二)之实时WordCount

发表评论 取消回复