语言模型定义
假设在给定长度为T的文本序列中的词元依次为


一个理想的与语言模型能够在一次抽取一个词元
学习语言模型
基于语言模型的基本规则,一个包含了四个单词的文本序列的概率是:
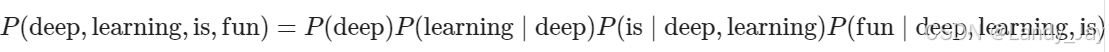
为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出现某个单词的条件概率。 这些概率本质上就是语言模型的参数。
马尔可夫模型与n元语法
当文本序列很长、文本量不够时,使用计数方法进行建模可能效果不佳。因此,可以在语言模型中引入马尔可夫模型以缓解这个问题。
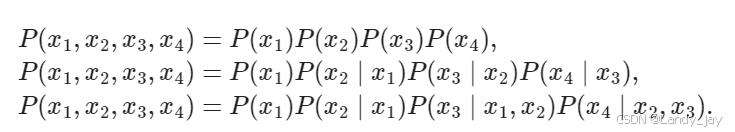
涉及一个、两个和三个变量的概率公式分别被称为 一元语法(unigram)、二元语法(bigram)和三元语法(trigram)模型。
n元语法对应马尔可夫模型中的tau=n。一元语法认为每个token都是独立的。二、三元语法认为每个token与当前token的前两个token相关。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 跟李沐学AI:语言模型

发表评论 取消回复