目录
一.分区表
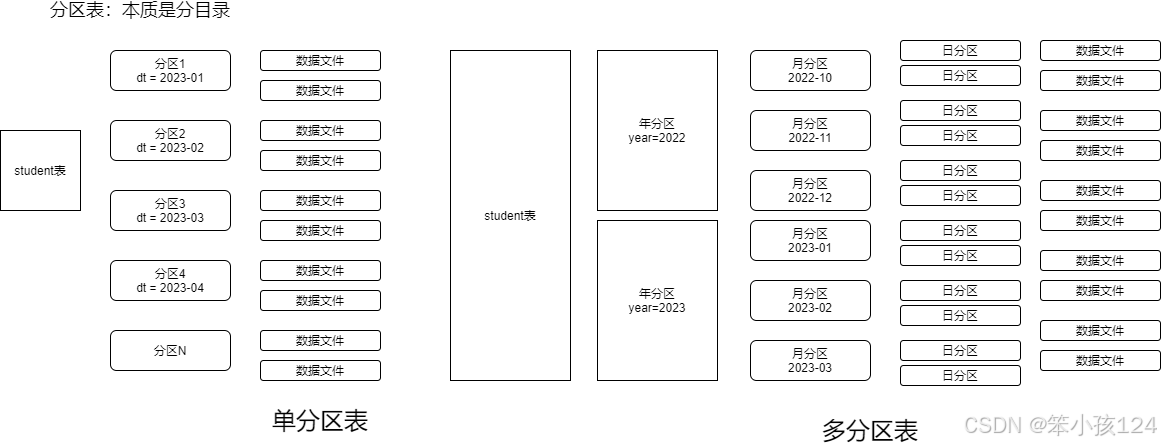
分区表特点:需要产生分区目录,查询的时候使用分区字段筛选数据,避免全表扫描,替身查询效率
效率上:如果分区表,在查询数据的时候没有分区字段去筛选数据,效率不变
分区字段名注意:分区字段名不能和原有字段名重复,因为分区字段名要作为字段拼接到表后
一级分区
知识点:
创建分区表:create [external] table [if not exists] 表名(字段名 字段类型,字段名 字段类型,...) partitioned by (分区字段名 分区字段类型)...;
自动生成分区目录并插入数据:load data [local] inpath '文件路径' into table 分区表名
partition (分区字段名='值');
注意:如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件
多级分区
知识点:
创建分区表:create [external] table [if not exists] 表名(字段名 字段类型,字段名 字段类型,...) partitioned by (一级分区字段名 分区字段类型, 二级分区字段名 分区字段类型 , ...);
自动生成分区目录并插入数据:load data [local] inpath '文件路径' into table 分区表名 partitioned (一级分区字段名='值',二级分区字段名='值' , ...);
注意: 如果加local后面文件路径应该是linux本地路径,如果没有加那么就是hdfs文件路径
分区操作
知识点:
添加分区:alter table 分区表名 add partition (分区字段名='值',....);
删除分区:alter table 分区表名 drop partition (分区字段名='值',...);
修改表名:alter table 分区表名 partition (分区字段名='旧值',...) rename to partition (分区字段名=‘新值’,...);
查看所有的分区:show partitions 分区表名;
同步/修复分区:msck repair table 分区表名;
hadoop_hive文档
hive文档: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
hdfs文档: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
yarn文档: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
mr文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
二.分桶表
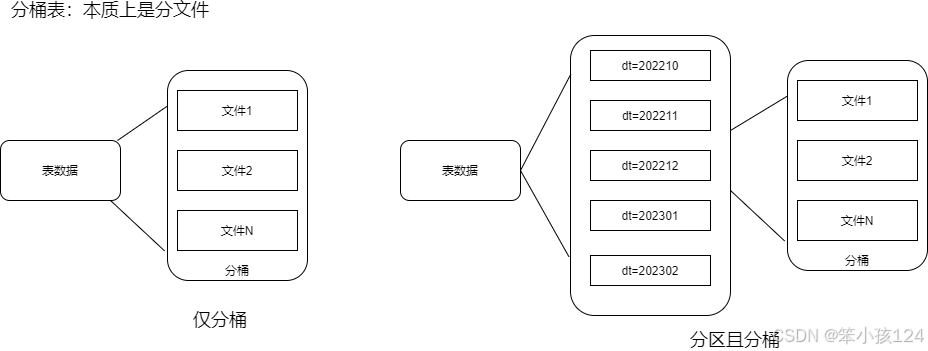
分桶表特点:需要产生分桶文件,查询的时候特定操作上提升效率(过滤,join,分组,抽样)
效率上:如果分桶表,在查询数据的时候没有使用分桶字段去筛选数据,效率不变
分桶字段名注意: 分桶字段名必须是原有字段名, 因为分桶需要根据对应字段值取余数把余数相同的数据放到同一个分桶文件中
基础分桶表:
知识点:
create [external] table [if not exists] 表名(
字段名 字段类型
)
clustered by (分桶字段名)
into 桶数量 buckets;
分桶表排序:
知识点:
create [external] table [if not exists] 表名 (
字段名 字段类型
)
clustered by (分桶字段名)
sorted by (排序字段名 asc|desc) # 注意:asc升序(默认) desc降序
into 桶数量 buckets;
分区表和分桶表区别
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python大数据之Hadoop学习——day07_Hive分区表和分桶表

发表评论 取消回复