文章目录
Multi-agent
ChatDev
ChatDev出自2023年7月的论文《ChatDev: Communicative Agents for Software Development》,它提出了一个基于聊天的用LLM来进行软件开发的框架。如下图所示,构建一个虚拟的基于聊天的软件开发公司ChatDev,它由具有不同社会角色的agent如执行官、程序员、测试工程师、设计师等组成,在给定一个任务时,这些agent一起合作来开发一个软件。在这个框架里,LLM作为核心思考组件,让agent模拟整个开发过程,避免额外的模型训练,也在一定程度上减轻了生成不良代码幻觉。

ChatDev遵循瀑布模型(waterfall model),将软件开发过程划分为四个阶段:设计(designing),编码(coding),测试(testing),写文档(documenting);每一个阶段分为多个原子聊天(atomic chat),每一个聊天由两个不同的角色来完成任务相关的角色扮演,如下图所示。这些解决任务的聊天序列被称为“chat chain",在每一个聊天中,指导者(instructor)发出指令,引导对话朝着任务完成的方向发展,助手(assistant)则按照指令,提供合适的解决方案并讨论可行性。指导者和助手通过多轮对话进行合作,直到达成共识并确定任务已成功完成。任务完成时,每个聊天的输出就对应着目标软件的一部分。
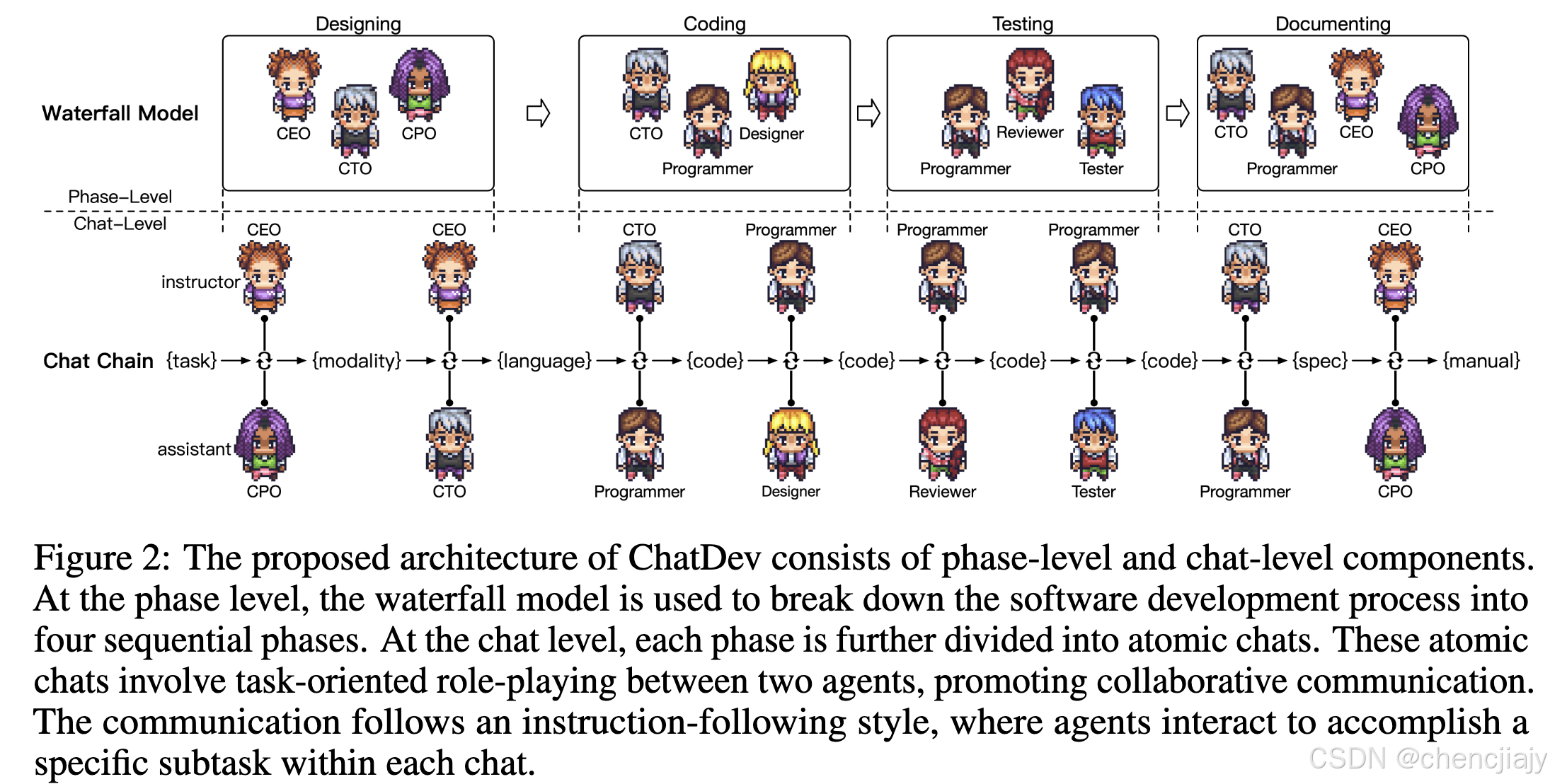
接下来是四个阶段的实现细节。
在设计阶段,ChatDev会从人类客户那收到需求。这个阶段包括三个预定义角色:CEO (chief executive officer),CPO (chief product officer), CTO (chief technology officer)。设计阶段分为两个原子对话任务:目标软件的模态决策、编程语言的选择。
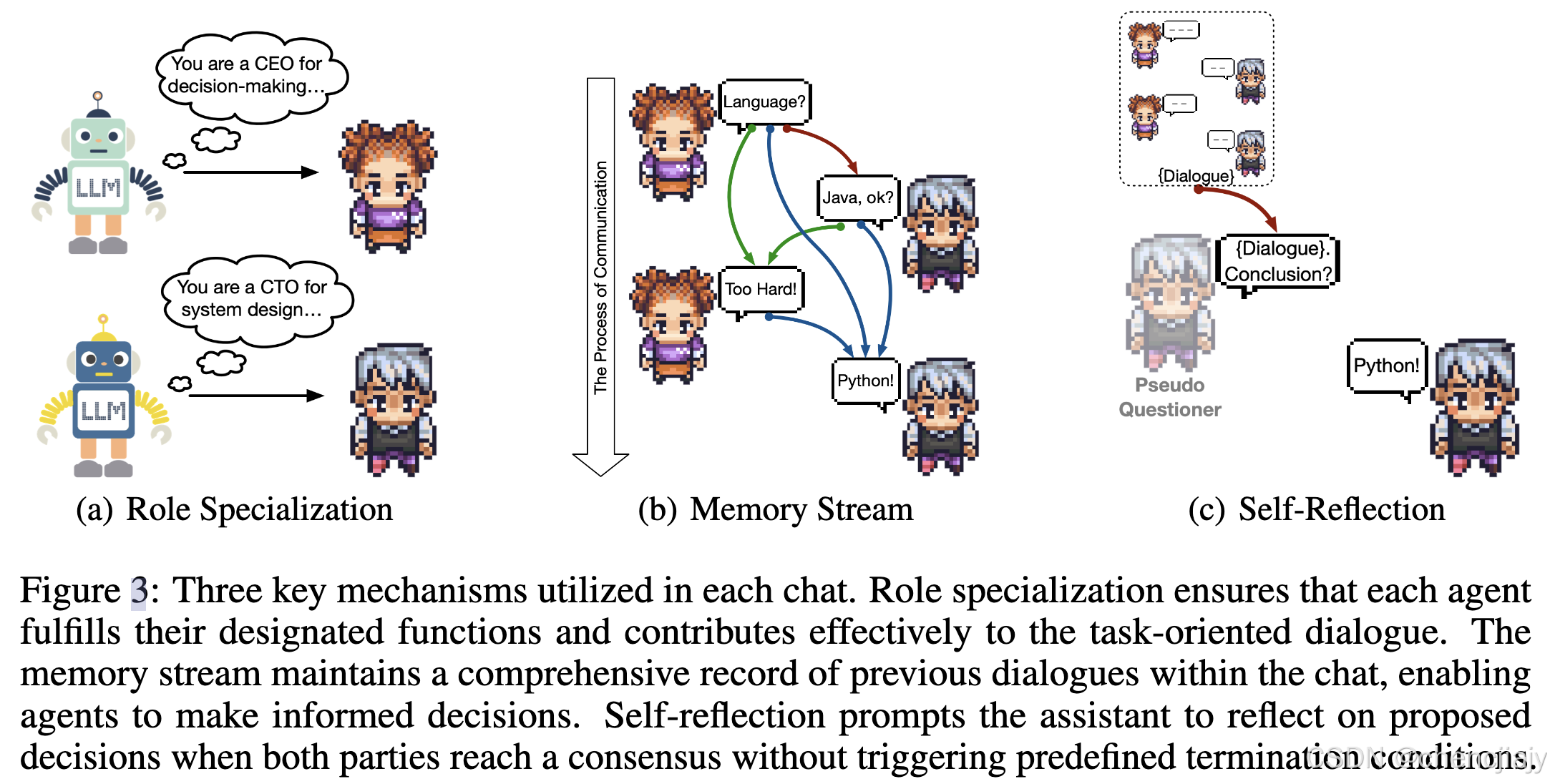
实现上有如下关键机制:
-
Role Specialization:在角色扮演过程中,system prompt用来给agent分配角色。设指导者的system prompt记为 P I \mathcal{P_I} PI,助理的system prompt记为 P A \mathcal{P_A} PA,在对话开始时这些prompt为agent分配角色;设 L I \mathcal{L_I} LI和 L A \mathcal{L_A} LA对应两个大模型,使用system prompt之后,将得到指导者agent I ← L I P I \mathcal{I} \leftarrow \mathcal{L^{P_I}_I} I←LIPI和助理agent A ← L A P A \mathcal{A} \leftarrow \mathcal{L^{P_A}_A} A←LAPA。 指导者被要求扮演CEO,负责互动规划;助理扮演CPO的角色,负责执行任务并提供响应,如上图(a)所示。 在实现角色扮演过程中,采用了inception prompting方法,即指导者和助理prompt包括了与任务和角色相关的重要细节、通信协议、终止条件、防止输出不想要行为的约束等等。
-
Memory Stream:Memory Stream一种维护agent之前的对话记录并用它们来辅助后续决策的机制。设在时刻t时指导者的消息记为 I t \mathcal{I_t} It,助理的消息记为 A t \mathcal{A_t} At,关联的决策记为 S t \mathcal{S_t} St。 下面公式1表示了在时刻t时封装的对话消息。
M t = ⟨ ( I 1 , A 1 ) , ( I 2 , A 2 ) , ⋯ , ( I t , A t ) ⟩ S t ← φ ( I t , A t ) ( 1 ) \mathcal{M_t} = \langle (\mathcal{I}_1, \mathcal{A}_1),(\mathcal{I}_2, \mathcal{A}_2),\cdots,(\mathcal{I}_t, \mathcal{A}_t) \rangle \qquad \qquad \mathcal{S}_t \leftarrow \varphi(\mathcal{I}_t, \mathcal{A}_t) \qquad \qquad \ (1) Mt=⟨(I1,A1),(I2,A2),⋯,(It,At)⟩St←φ(It,At) (1)
φ \varphi φ表示基于LLM的决定提取器,可通过通信协议发现来实现也可以通过self-reflection来实现。在后续时间步 t + 1 t+1 t+1,指导者利用历史对话消息集 M t \mathcal{M}_t Mt来给予新的指令 I t + 1 \mathcal{I}_{t+1} It+1,并将其与 M t \mathcal{M}_t Mt一起传递给助理,如上图(b)所示意。助理的响应或消息记为 A t + 1 \mathcal{A}_{t+1} At+1。整个过程如下公式2所示。
I t + 1 = A ( M t , S t ) A t + 1 = I ( M t , I t + 1 , S t ) ( 2 ) \mathcal{I}_{t+1} = \mathcal{A}(\mathcal{M}_t, \mathcal{S}_t) \qquad \mathcal{A}_{t+1} = \mathcal{I}(\mathcal{M}_t, \mathcal{I}_{t+1}, \mathcal{S}_t) \qquad \qquad (2) It+1=A(Mt,St)At+1=I(Mt,It+1,St)(2)
memory stream也跟着更新:
M t + 1 = M t ∪ ( I t + 1 , A t + 1 ) S t + 1 = S t ∪ φ ( I t + 1 , A t + 1 ) ( 3 ) \mathcal{M}_{t+1} = \mathcal{M}_t \ \cup \ (\mathcal{I}_{t+1}, \mathcal{A}_{t+1}) \qquad \mathcal{S}_{t+1} = \mathcal{S}_t \ \cup \ \varphi(\mathcal{I}_{t+1}, \mathcal{A}_{t+1}) \qquad (3) Mt+1=Mt ∪ (It+1,At+1)St+1=St ∪ φ(It+1,At+1)(3)
通信协议是通过prompt来实现的,比如当双方达成共识时将生成满足指定格式的结束消息(比如": Desktop Application")。系统会监控消息是否满足设计的格式,当满足格式时结束当前对话。 -
Self-Reflection:作者观察到存在角色扮演两方达成共识但未触发作为终止条件的通信协议的情况,所以引入了self-reflection机制。为了实现self-reflection机制,引入了一个"pseudo self"作为新的提问者并发起新的聊天;"pseudo self"会告知当前助手之前对话的所有历史记录,并要求其总结对话中的结论性信息,如上图©所示。这一机制有效地鼓励助手反思对话中提出和讨论的决定。
编码阶段涉及三个角色:CTO、程序员、设计师;分为生成完整的代码(CTO和程序员完成)、完成用户图形接口(设计师和程序员)两个原子任务。CTO用markdown格式指导程序员实现软件系统,程序员基于markdown指令来生成代码。设计师提出用户友好的图形用户界面 (GUI),该界面使用图形图标而不是基于文本的命令进行用户交互。接着,设计人员使用外部文本转图像工具创建具有视觉吸引力的图形后,程序员使用标准工具包将其合并到 GUI 设计中。
实现上有如下关键机制:
- Code management: ChatDev使用面向对象的编程语言如Python。使用“版本演化(version evolut)”机制以限制角色之间对最新代码版本的可见性,在Memory Stream中丢弃较早的代码版本。程序员使用与 Git 相关的命令管理项目。
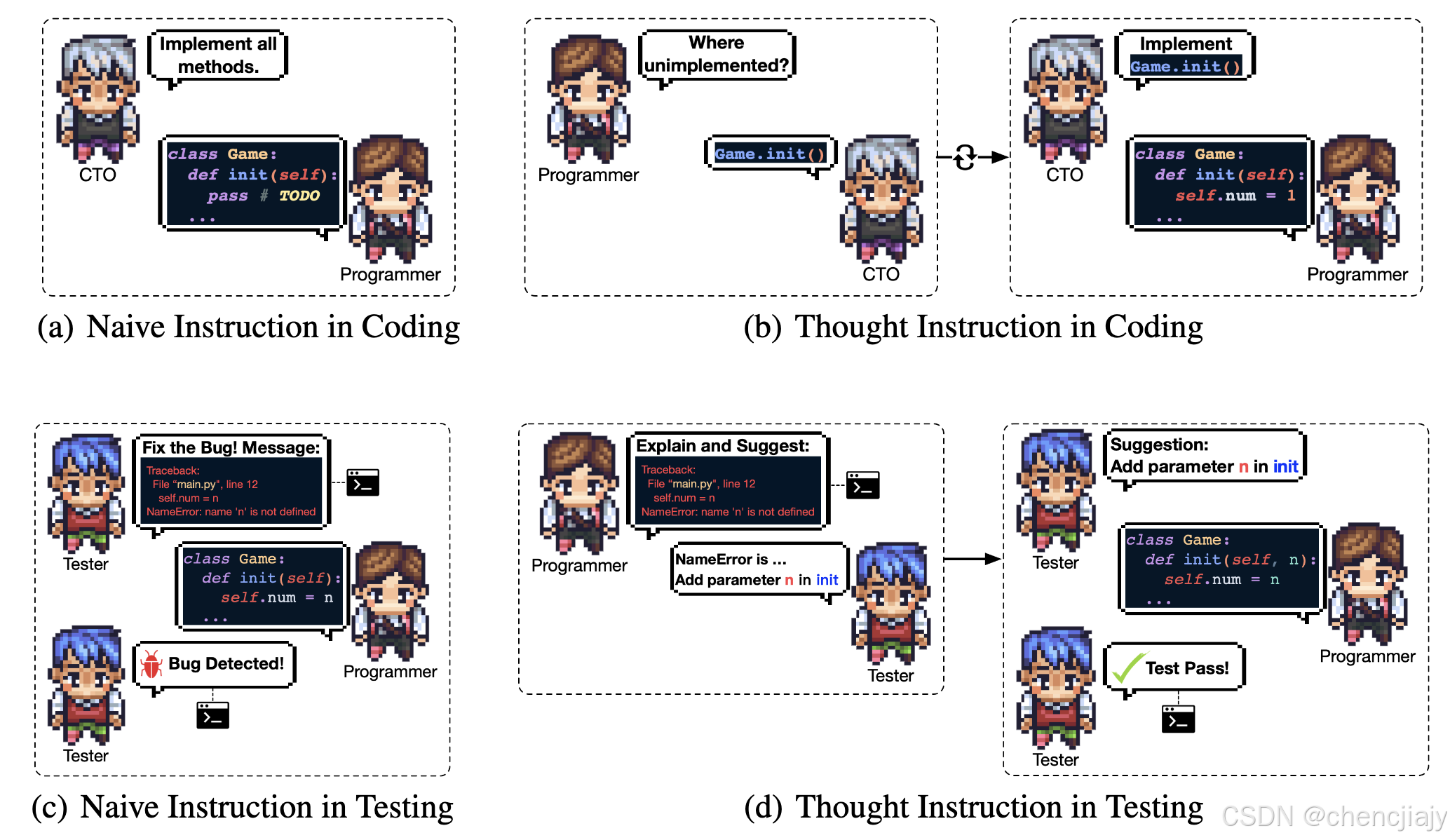
- Thought Instruction:为了减少幻觉,引入“thought instruction”机制。thought instruction受CoT的启发,在指令中明确特定的解决问题思路,例如按顺序解决子任务。如下图(a)和(b)所示,“thought instruction包括交换角色以询问哪些方法尚未实现,然后切换回来为程序员提供更精确的指令。thought instruction使编码过程变得更加集中和有针对性,在指令中明确表达特定的想法有助于减少歧义并确保生成的代码与预期目标一致。
测试阶段涉及到三个角色:程序员、评审员、测试员;分为代码评审(程序员和评审员)、系统测试(程序员和测试员)两个原子任务。代码评审检查源码识别潜在的问题;系统测试验证软件的执行过程。
使用“Thought Instruction”来显示地在指令中描述debug想法,如上图©和(d)所示,测试员执行软件、分析bug、提出修改意见并以此来指导程序员。这个迭代过程持续进行直到所有潜在bug都被消除软件可以成功执行。
当编译器无法正确识别细粒度的逻辑错误时,人类客户可以通过自然语言描述的反馈和建议来帮助改进软件系统。
-
文档编写
文档编写阶段涉及四个角色:CEO、CPO、CTO、程序员。用few-shot prompt来让LLM完成文档生成。CTO知道程序员提供环境依赖的配置文件,生成如requirements.txt的文件; CEO指导CPO生成用户手册。
MetaGPT
MetaGPT出自2023年8月初的论文《MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework》,它将SOPs(Standardized Operating Procedures)融入到基于LLM的multi-agent合作过程。
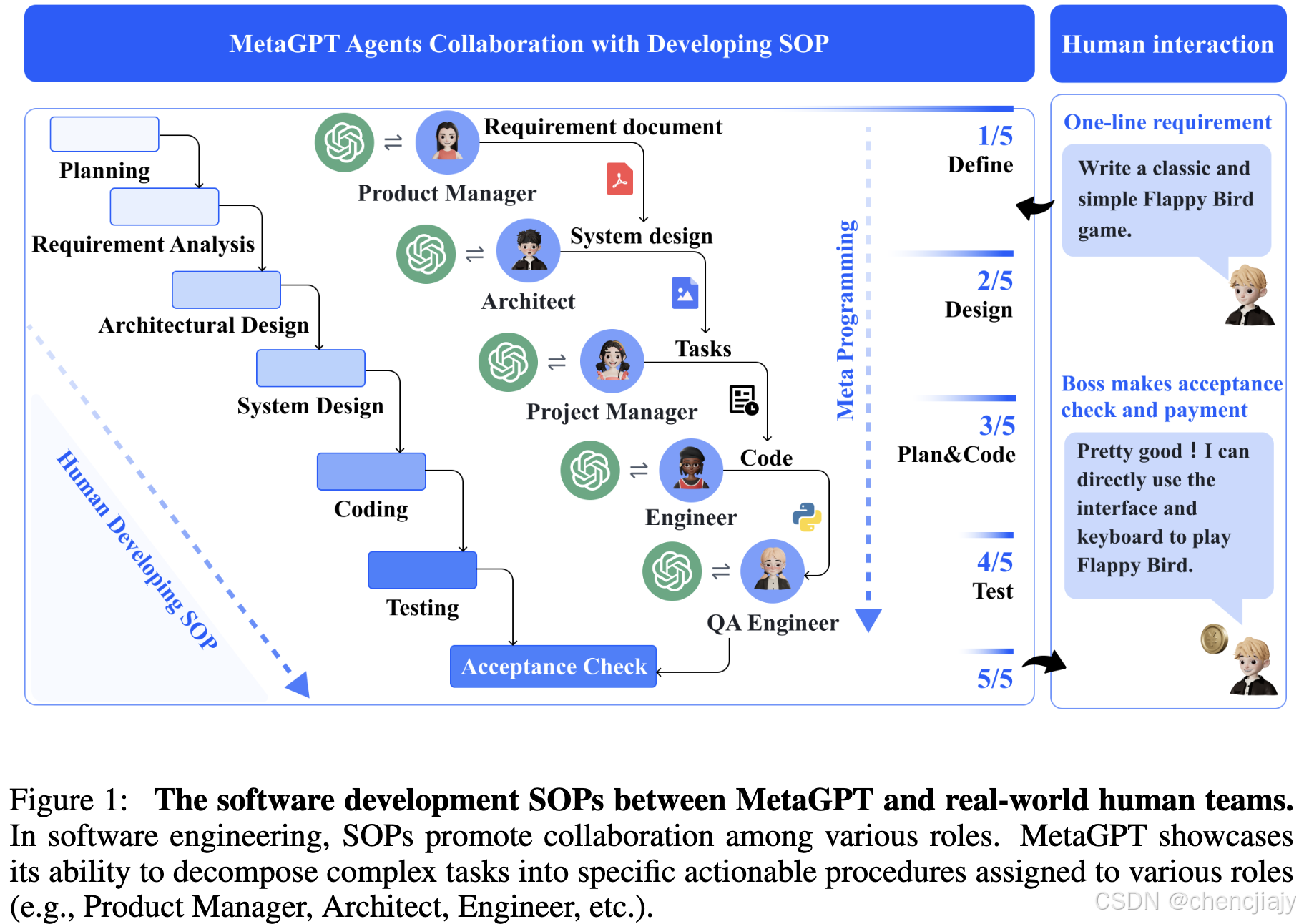
SOP模式下的Agent
MetaGPT为软件开发定义了五个角色:产品经理(Product Manager),架构师(Architect),项目经理(Project Manager),工程师(Engineer),QA工程师(QA Engineer),如上图所示。每一个角色包括具体的上下文或者技能,比如下图中的产品经理可以使用网络搜索工具,工程师可以执行代码。 MetaGPT给每个agent的画像包括名字、角色、目标、角色的约束,所有的agent都遵循类似React的行为模式。
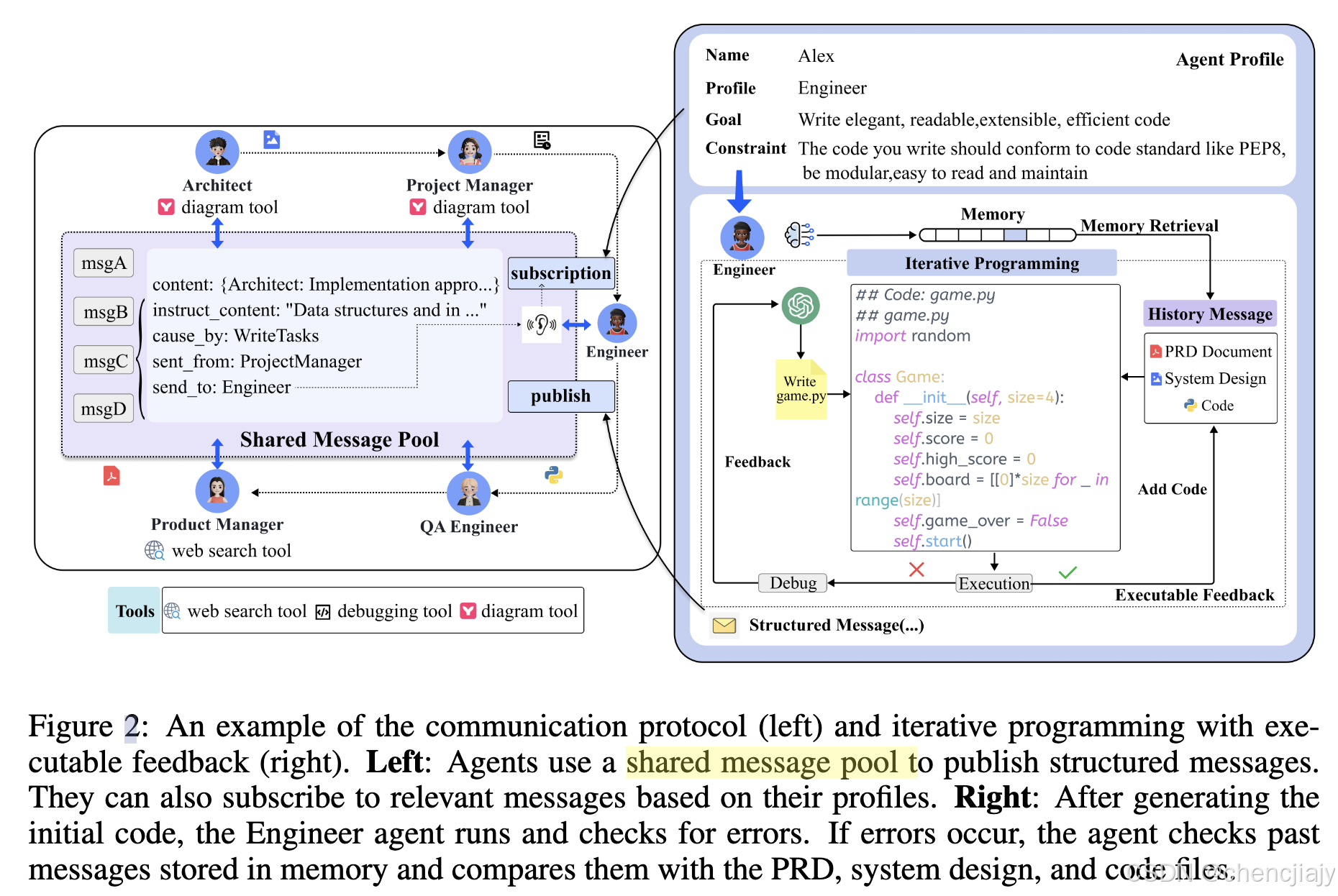
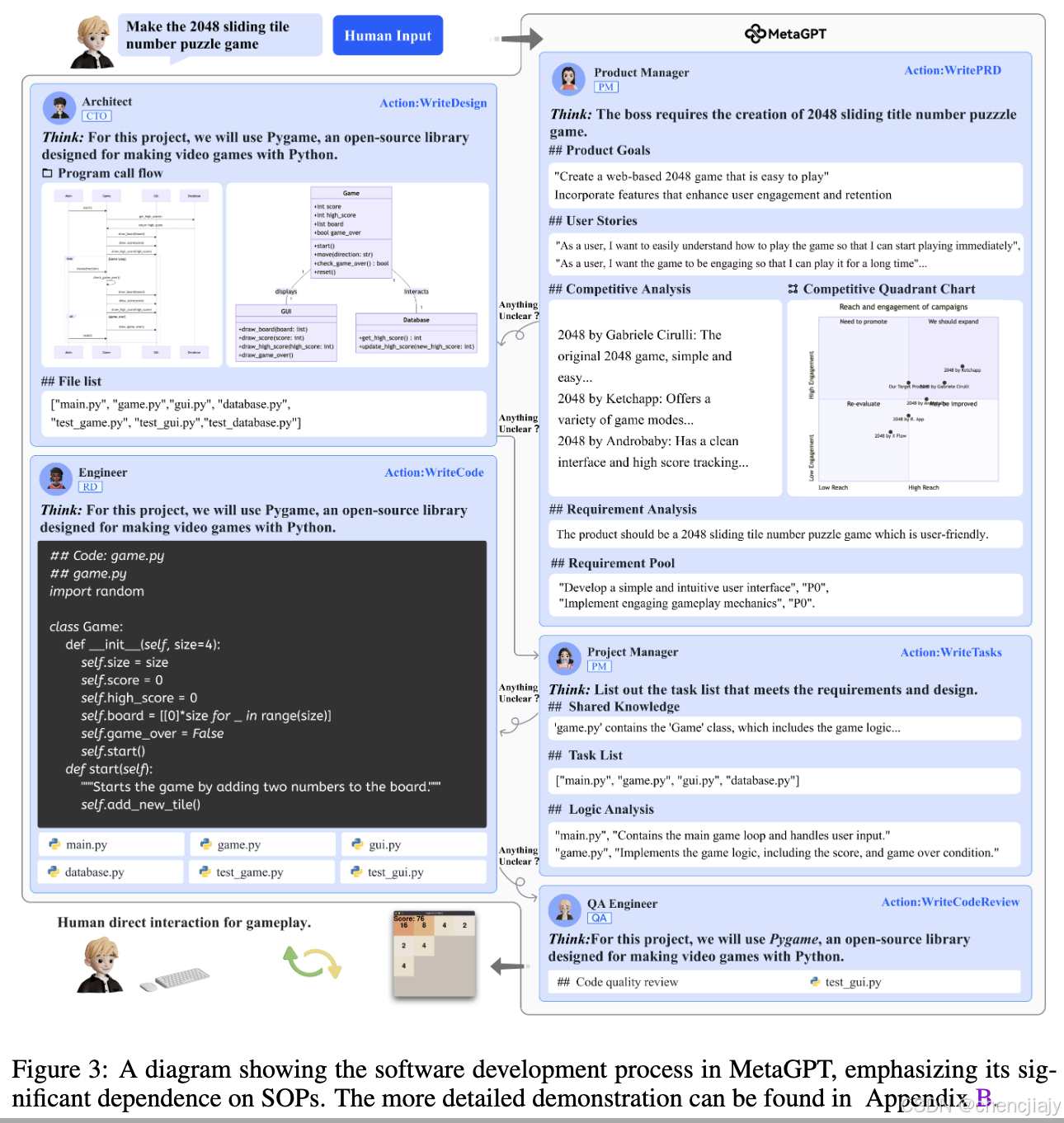
定义好agent的角色和技能后,MetaGPT遵循软件开发里的SOP,让所有agents按照一定的顺序来工作。如论文图1(上上图)所示,在获得用户需求后,产品经理会进行全面分析,制定一份详细的项目需求文档,其中包括用户故事和需求池,这可作为初步的功能细分。结构化的项目需求文档随后会传递给架构师,架构师会将需求转化为系统设计组件,例如文件列表、数据结构和接口定义。系统设计完成后,信息就会发送给项目经理进行任务分配;工程师执行指定的类和功能,如图 2 所示。在下一阶段,QA 工程师会制定测试用例,以严格执行代码质量。最终MetaGPT将生成一个软件解决方案。下图(论文图3)是整个流程的一个示意。
通信协议
Structured Communication Interfaces: MetaGPT使用结构化通信来进行agents之间的沟通,为每个角色建立一个schema和格式,并要求每个agent根据其特定角色和上下文提供必要的输出。在上图(论文图3)中,架构师agent生成两个输出:系统接口设计和一个时序图。与ChatDev不一样,MetaGPT中的agent通过文档和图表来进行通信而不是通过对话。
Publish-Subscribe Mechanism:MetaGPT有一个全局消息池(message pool),如上面图2所示左侧所示。共享消息池可以使所有agent直接交换消息。agent可以发布它们的结构化消息也可以访问其他agent发布的消息。如果要去关注所有其他agent发送的消息,很容易造成信息过载,所以MetaGPT有一个订阅机制(subscription mechanism),在实现时,一个agent只有在接收到了所有先决条件依赖之后才会激活它的动作。比如在前面图3的例子里,架构师主要关注产品经理提供的PRD消息。
带执行反馈的迭代编程
MetaGPT引入了可执行的反馈机制,以迭代方式改进代码。更具体地说,如上面图 2 所示,它要求工程师根据原始产品需求和设计编写代码。这使工程师能够使用自己的历史执行和debug记忆不断改进代码。为了获得更多信息,工程师编写并执行相应的单元测试用例,随后收到测试结果。如果结果令人满意,则启动其他开发任务;否则,工程师在恢复编程之前debug代码。这个迭代测试过程持续进行,直到测试通过或达到3 次最大重试次数。
AutoGen
AutoGen出自2023年8月中的论文《AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation》,它是一个基于对话的multi-agent 通用框架, 可用来创建和试验multi-agent系统。
AutoGen的核心设计原则是使用multi-agent对话来简化和整合multi-agent工作流,同时最大限度地提高已实现agent的可重用性。AutoGen有两大关键概念:conversable agents、conversation programming。
conversable agents
在AutoGen中,一个可对话的agent(conversable agent)是有特定角色的实体。 它可以传递消息,与其他可对话agent发送和接收消息,如开始或继续对话。可对话的agent根据发送和接收的消息维护其内部上下文,也可以为它配置由LLM、工具或人类输入等提供的能力,它们可以根据后面描述的编程行为模式采取行动。
- 由LLM、人类、工具赋能的agent(Agent capabilities powered by LLMs, humans, and tools):AutoGen灵活地赋予agent不同的能力,能力包括:
- LLM: 基于LLM的agent可以利用LLM的各种能力如角色扮演、隐式状态推理和基于对话历史的进展、提供反馈、根据反馈进行调整和编码等,这些能力通过prompt技术来激发,下图是论文中agent的system message,不同的颜色标识这不同的prompt技术。此外AutoGen提供了一个增强LLM推理层,其包括结果缓存、错误处理、消息模板等特点。
- 人类:在许多 LLM 应用中,人类参与是必需的甚至是必不可少的。AutoGen 允许人类通过人工支持的agent参与agent对话,这些agent可以根据agent配置在对话的某些轮次中请求人类输入。默认user proxy agent允许可配置的人类参与级别和模式,例如请求人类输入的频率和条件,包括人类跳过提供输入的选项。
- 工具:基于工具的agent拥有通过代码执行或函数执行来执行工具的能力。比如默认的user proxy agent可以执行LLM建议的代码或者调用LLM建议的函数。

- Agent定制和合作(Agent customization and cooperation):根据特定于应用程序的需求,每个agent都可以配置成具有多种基本后端类型,以显示multi-agent对话中的复杂行为。AutoGen 允许通过重用或扩展内置agent轻松创建具有专门功能和角色的agent。下图(论文图 2) 中的黄色阴影区域提供了 AutoGen 中内置agent的草图。
ConversableAgent类是最高级别的agent抽象,默认情况下可以使用 LLM、人类和工具。AssistantAgent和UserProxyAgent是两个预配置的ConversableAgent子类,每个子类都代表一种常见的使用模式,即充当 AI 助手(由 LLM 支持)并充当人类代理来征求人类输入或执行代码/函数调用(由人类和/或工具支持)。
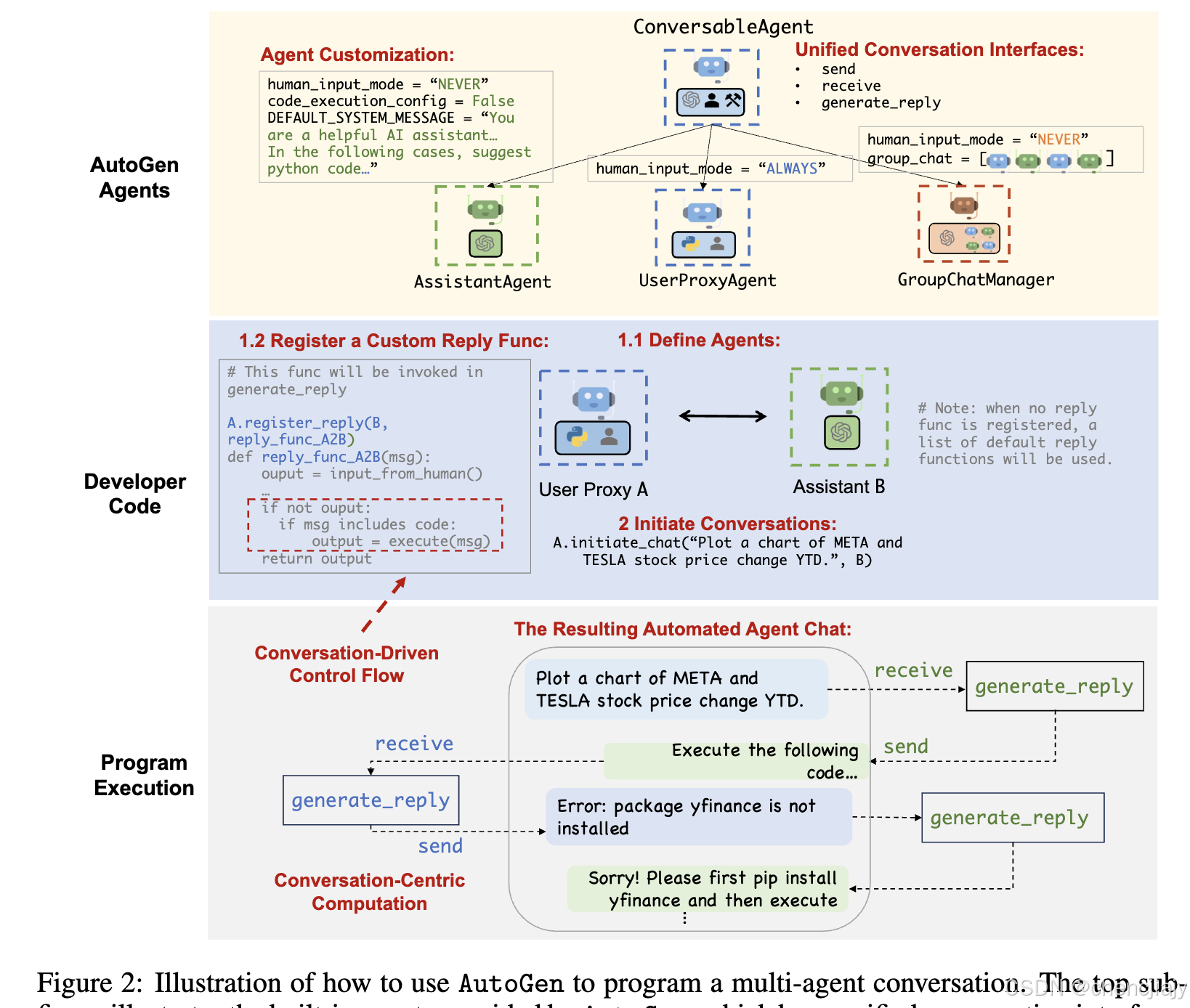
在下图(论文图 1) 右侧的示例中,一个由 LLM 支持的助理agent和一个由工具和人类支持的用户代理agent一起部署以处理一项任务。在这里,助理agent在 LLM 的帮助下生成解决方案并将解决方案传递给用户代理agent。然后,用户代理agent征求人类输入或执行助理的代码并将结果作为反馈传回助理。
Conversation Programming
通过允许自定义agent相互交谈,AutoGen 中的可交谈agent可充当有用的构建块。但是,要开发agent在任务上取得有意义进展的应用程序,开发人员还需要能够指定和塑造这些multi-agent对话。AutoGen利用对话编程(Conversation Programming)来解决这个问题。
对话编程这一范式(paradigm)有如下两个概念,AutoGen作者认为这种范式有助于人们直观地推理复杂的工作流程,如agent采取行动和agent之间对话的消息传递:
- 计算(computation):agents在multi-agent对话中计算其响应所采取的行动。在 AutoGen 中,这些计算以对话为中心。agent采取与其参与的对话相关的行动,其行动会导致后续对话的消息传递(除非满足终止条件)。
- 控制流(control flow):这些计算发生的顺序(或条件)。与计算类似,控制流是由对话驱动的——参与agent决定向哪个agent发送消息以及计算过程都是inter-agent对话的函数。
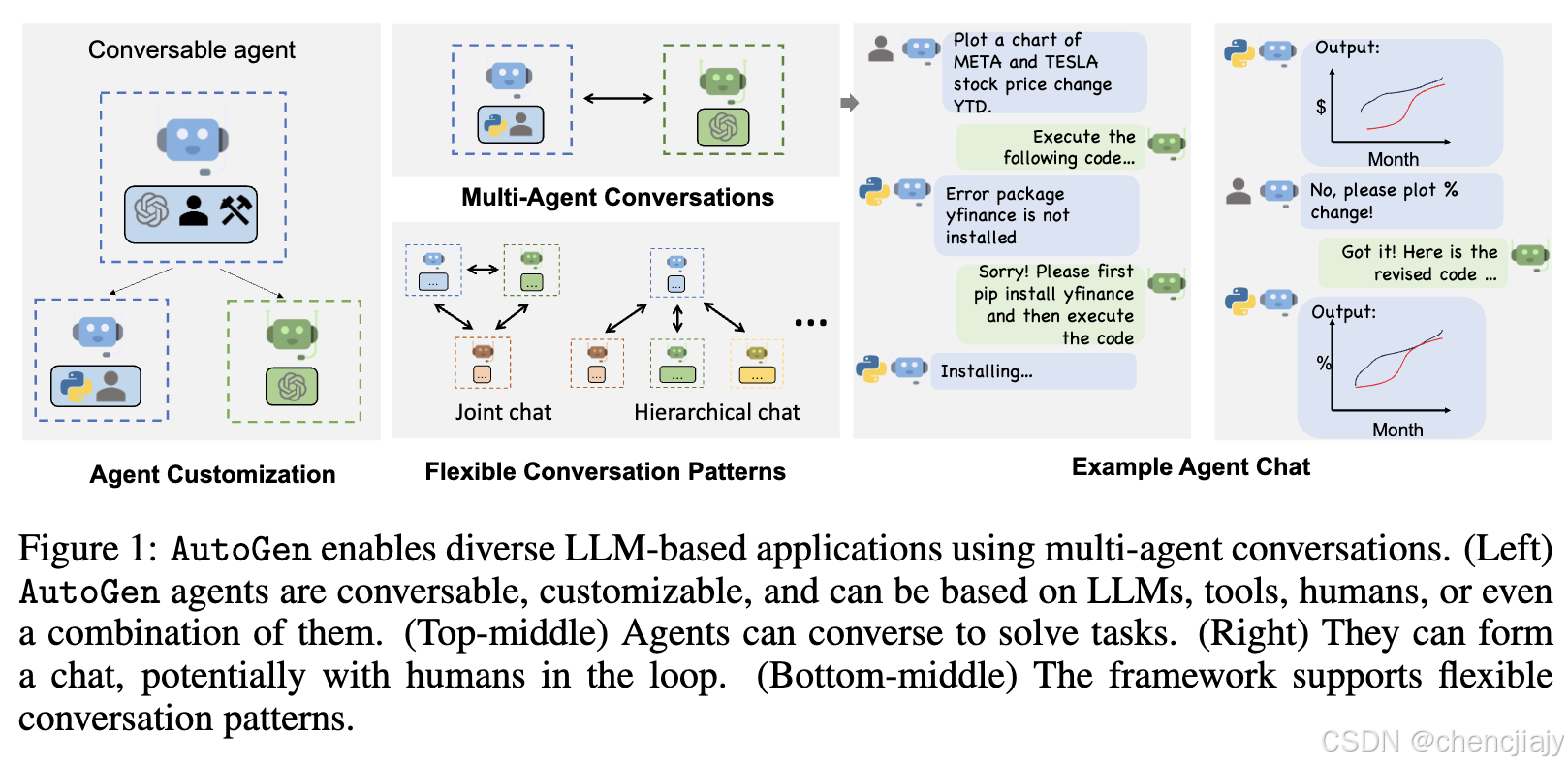
上上图(论文图 2) 提供了一个简单的示例。底部子图显示了各个agent如何执行特定于角色的、以对话为中心的计算以生成响应(例如,通过 LLM 推理调用和代码执行)。任务通过对话框中显示的对话进行。中间子图演示了基于对话的控制流,当助手收到消息时,用户代理agent通常会将人工输入作为回复发送;如果没有输入,它将改为执行助手消息中的任何代码。
AutoGen通过如下的设计模式来实现对话编程:
- 统一接口和自动回复机制,实现自动agent聊天。AutoGen 中的agent具有统一的对话接口,用于执行相应的以对话为中心的计算,包括用于发送/接收消息的
send/receive函数和用于根据收到的消息采取行动并生成响应的generate_reply函数。AutoGen 还引入并默认采用agent自动回复(agent auto-reply)机制来实现对话驱动控制:一旦agent收到来自另一个agent的消息,它就会自动调用generate_reply并将回复发送回发送者,除非已经满足终止条件。AutoGen 提供基于 LLM 推理、代码或函数执行或人工输入的内置回复函数。用户也可以注册自定义回复函数来定制agent的行为模式,例如,在回复发送者agent之前与另一个agent聊天。在这种机制下,一旦注册了回复函数并初始化对话,对话流就会自然而然地开始了,因此无需任何额外的控制平面(即控制对话流的特殊模块),agent对话就可以自然进行。例如,通过上上图(论文图 2)中蓝色区域(标记为“开发人员代码”)中的开发人员代码,可以很容易地触发agent之间的对话,并且对话将自动进行,如上上图(论文图 2)中灰色区域(标记为“程序执行”)中的对话框所示。自动回复机制提供了一种去中心、模块化和统一的方式来定义工作流程。 - 通过编程和自然语言的融合进行控制。AutoGen 允许在各种控制流管理模式中使用编程和自然语言:1) 通过 LLM 进行自然语言控制。在 AutoGen 中,可以通过使用自然语言提示 LLM 支持的agent来控制对话流。例如,AutoGen 中内置 AssistantAgent 的默认系统消息使用自然语言指示agent,如果先前的结果表明存在错误,则修复错误并再次生成代码。它还指导agent将 LLM 输出限制在某些结构中,使其他工具支持的agent更容易使用。例如,指示agent在所有任务完成后回复“TERMINATE”以终止程序。 2) 编程语言控制。在 AutoGen 中,可以使用 Python 代码来指定终止条件、人工输入模式和工具执行逻辑例如自动回复的最大数量。用户还可以注册编程的自动回复函数,使用 Python 代码控制对话流,如上上图(论文图 2) 中标记为“ConversationDriven Control Flow”的代码块所示。3) 自然语言和编程语言之间的控制转换。AutoGen 支持自然语言和编程语言之间的灵活控制转换。用户可以通过在自定义回复函数中调用包含某些控制逻辑的 LLM 推理来实现从代码到自然语言控制的转换;或者通过基于LLM的function call从自然语言控制转换为代码控制。
在对话编程范式中,可以实现多种模式的multi-agent对话。除了具有预定义流程的静态对话之外,AutoGen 还支持multi-agent动态对话流程。AutoGen 提供了两种实现此目的的常规方法:1) 自定义generate_reply函数:在自定义generate_reply函数中,一个agent可以保持当前对话,同时根据当前消息的内容和上下文唤起与其他agent的对话。2) function call:在这种方法中,LLM 根据对话状态决定是否调用特定函数。通过在调用的函数中向其他agent发送消息,LLM 可以驱动动态multi-agent对话。此外,AutoGen 通过内置的 GroupChatManager 支持更复杂的动态群聊,它可以动态选择下一个发言者,然后将其响应广播给其他agent。在后面的应用章节详细介绍此功能及其应用。
AutoGen的应用
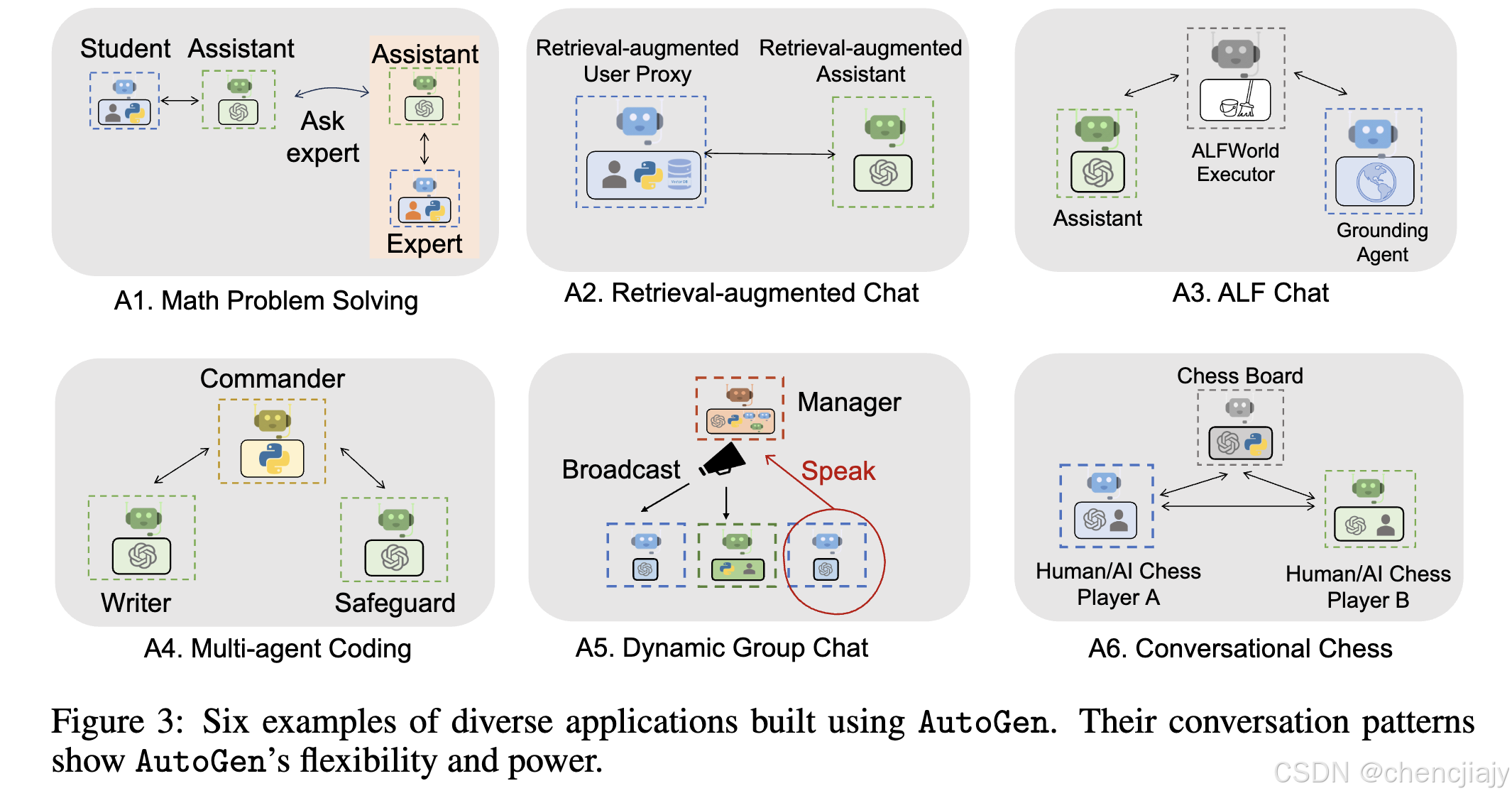
如上图所示,论文示例六种multi-agent应用来说明AutoGen的应用场景,应用(A1, A2, A4, A5, A6)是为了说明AutoGen的现实相关性, 应用 (A1, A2, A3, A4)是为了说明AutoGen能够解决问题的能力以及问题的难度, 应用 (A5, A6)是为了说明AutoGen应用的潜在创新性。
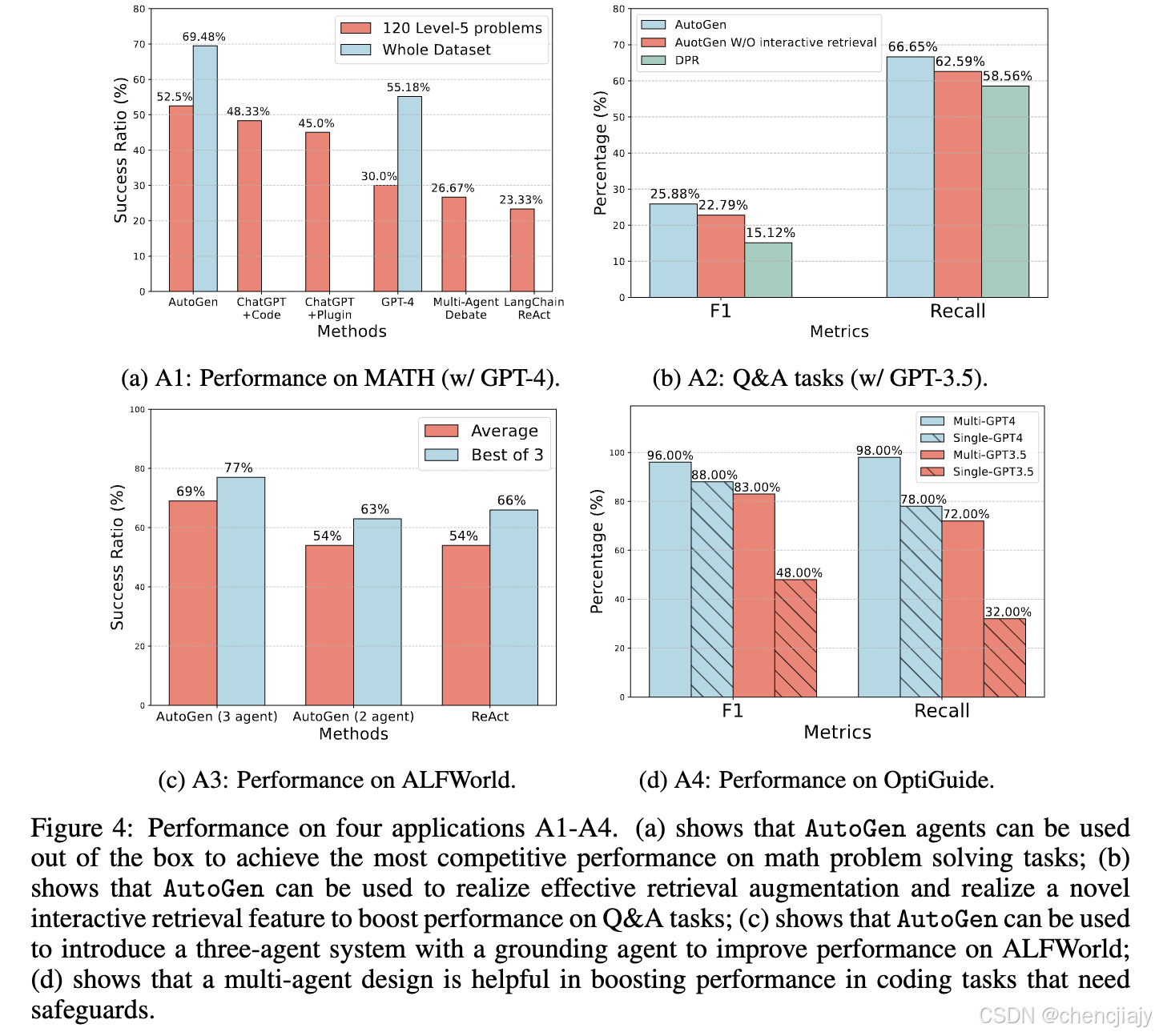
A1: Math Problem Solving:(场景 1)能够直接复用AutoGen 的两个内置agent来构建一个自主数学问题解决系统。作者在 MATH数据集上评估了搭建的系统和几种替代方法, 结果表明,与替代方法相比AutoGen 的内置agent已经具有更好的开箱即用性能。(场景 2)借助 AutoGen 展示了人机交互问题解决过程。要将人工反馈与 AutoGen 结合起来,只需在场景 1 中在系统的 UserProxyAgent 中设置human_input_mode =“ALWAYS”。论文证明该系统可以有效地结合人工输入来解决没有人工就无法解决的难题。(场景 3)多个人类用户可以在解决问题的过程中参与对话。论文实验表名在此场景下AutoGen 能够提供更好的性能或新体验。
A2: Retrieval-Augmented Code Generation and Question Answering:使用 AutoGen 构建了一个名为“检索增强聊天(Retrieval-augmented Chat)”的RAG系统。该系统由两个agent组成:Retrieval-augmented User Proxy agent 和Retrieval-augmented Assistant agent,这两个agent都是从 AutoGen 的内置agent扩展而来的。Retrieval-augmented User Proxy agent包括一个向量数据库 Chroma,其中 SentenceTransformers 作为上下文检索器。作者在问答和代码生成场景中对检索增强聊天进行了评估。(场景 1)在 Natural Questions 数据集上对自然问答进行评估,并与DPR进行比较。AutoGen 在此应用程序中引入了一种新颖的交互式检索(interactive retrieval)功能:每当检索到的上下文不包含信息时,基于 LLM 的助手不会终止,而是会回复"Sorry, I cannot find any information about… UPDATE CONTEXT."这将调用更多检索尝试。作者进行的消融研究表明交互式检索机制确实在此过程中发挥了重要作用。(场景 2)演示了检索增强聊天如何帮助根据未包含 GPT-4 训练数据中的代码的给定代码库生成代码。
A3: Decision Making in Text World Environments:用 AutoGen实现了一个two-agent系统来解决 ALFWorld 中的任务。它由一个 LLM 支持的助理agent负责建议执行任务的计划,以及一个执行agent负责在 ALFWorld 环境中执行动作。该系统集成了 ReAct 提示并且能够实现类似的性能。ReAct 和基于 AutoGen 的two-agent系统遇到的一个共同挑战是它们偶尔无法利用有关物理世界的基本常识知识;这种缺陷可能导致系统因重复错误而陷入循环。AutoGen解决这个问题的方法是:引入一个grounding agent,每当系统出现重复错误的早期迹象时,它都会提供关键的常识知识——例如"You must find and take the object before you can examine it. You must go to where the target object is before you can use it."。论文实验表明引入grounding agent后可以有效避免循环错误。
A4: Multi-Agent Coding:用 AutoGen 构建基于 OptiGuide 的multi-agent编码系统,该系统擅长编写代码来解释优化解决方案并回答用户问题,例如探索改变供应链决策的影响或理解优化器做出特定选择的原因。论文图 3 的子图显示了基于 AutoGen 的实现。工作流程如下:最终用户向commander agent发送问题,例如"What if we prohibit shipping from supplier 1 to roastery 2?“。commander与两个助理agent(包括Writer和Safeguard)协调以回答问题。Writer将编写代码并将代码发送给commander。收到代码后,commander使用Safeguard检查代码安全性;如果通过,commander将使用外部工具(例如 Python)执行代码,并请求Writer解释执行结果。例如,Writer可能会说"if we prohibit shipping from supplier 1 to roastery 2, the total cost would increase by 10.5%.” , commander向用户提供这个结论性答案。如果在某个特定步骤出现异常,例如 Safeguard 发出的安全红旗,commander会将问题重定向回Writer,并提供调试信息;这个过程可能会重复多次,直到用户的问题得到解答或超时。论文实验结论说这个系统的代码效率很高,multi-agent的抽象也是必要的。
A5: Dynamic Group Chat:AutoGen 支持动态群聊通信模式,在这种模式下,参与的agent共享相同的上下文并以动态方式与其他agent交谈,而不是遵循预定义的顺序。动态群聊依靠持续的对话来引导agent之间的交互流程,这使得动态群聊非常适合在没有严格通信顺序的情况下进行协作的情况。在 AutoGen 中,GroupChatManager 类充当agent之间对话的指挥者,并重复以下三个步骤:动态选择发言人、收集选定发言人的回复以及广播消息(论文图 3-A5)。对于动态发言人选择组件使用角色扮演风格的提示,通过对 12 个手工制作的复杂任务的初步研究,作者观察到,与纯粹基于任务的提示相比,使用角色扮演提示通常会在解决问题和选择发言人的过程中更有效地考虑对话背景和角色对齐,因此可以提高成功率并减少 LLM 调用。
**A6: Conversational Chess:**使用AutoGen开发了自然语言界面游戏Conversational Chess,如论文图 3 的最后一个子图所示。它具有内置的玩家agent,可以是人类或 LLM,以及用于提供信息并根据标准规则验证动作的第三方棋盘agent。基于AutoGen的Conversational Chess有两个基本功能:(1) 自然、灵活且引人入胜的游戏动态,由 AutoGen 中的可定制agent设计实现。Conversational Chess支持一系列游戏模式,包括 AI-AI、AI-人类和人类-人类,在单场游戏中可以在这些模式之间无缝切换。(2) Grounding,这是保持游戏公平性的关键方面。在游戏过程中,棋盘agent会检查每个提议的动作是否合法;如果某个动作无效,agent会以错误响应,提示玩家agent在继续之前重新提出合法的动作。此过程可确保只进行有效的动作,并有助于保持一致的游戏体验。消融实验表名棋盘agent的存在有助有提高游戏体验和灵活度。
参考资料
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » LLM agentic模式之multi-agent: ChatDev,MetaGPT, AutoGen思路

发表评论 取消回复