大家好,这里是小琳AI课堂。今天我们来深入学习Transformer模型,这个在深度学习领域引发革命的技术。
Transformer模型的革命性优势
Transformer模型被认为是引发了深度学习领域革命的技术,主要原因有以下几点:
- 突破性的性能提升:在自然语言处理(NLP)领域,Transformer模型取得了前所未有的性能提升。
- 并行计算能力:Transformer模型的自注意力机制允许并行处理序列数据,这在使用GPU或TPU等硬件加速时尤其高效。
- 长距离依赖处理:Transformer通过自注意力机制能够有效地处理长距离的依赖关系。
- 多尺度信息融合:多头注意力机制允许模型在不同的表示空间中学习到信息,然后将这些信息综合起来。
- 灵活性和可扩展性:Transformer模型的结构相对简单,易于扩展和修改,以适应不同的应用需求。
- 预训练模型的推动:随着BERT等预训练模型的推出,Transformer模型在NLP领域的应用得到了进一步的推动。
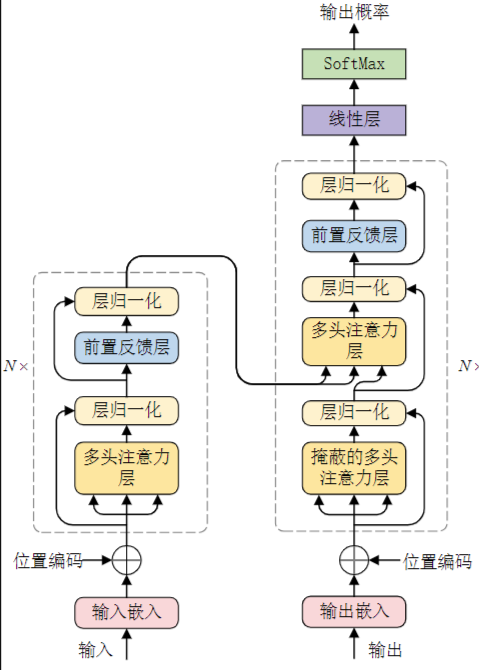
Transformer模型的核心组件
Transformer模型,主要用于处理序列数据,如自然语言文本,由以下几个核心组件构成:
- 输入嵌入层(Input Embedding):将输入序列(如单词或子词)转换为固定大小的向量。
- 位置编码(Positional Encoding):由于Transformer不包含循环结构,因此需要位置编码来表示序列中单词的位置信息。
- 多头注意力层(Multi-Head Attention):这是Transformer的核心,它允许模型在不同的表示空间中学习到信息,然后将这些信息综合起来。多头注意力机制有助于模型捕捉到不同尺度的特征。
- 层归一化(Layer Normalization):用于提高网络的训练稳定性。
- 前馈网络层(Feed Forward Neural Network):在每个注意力层之后,都有一个前馈网络,用于对注意力层的输出进行进一步的非线性变换。
- 残差连接(Residual Connections):通过残差连接,模型的每一层都可以直接访问前面所有层的输出,这有助于解决深度网络中的梯度消失问题。
- 掩码多头注意力层(Masked Multi-Head Attention):在某些情况下,如文本生成任务,我们需要确保模型在预测某个位置时只能看到该位置之前的输入。这时就需要使用掩码来自注意力机制。
- 输出层(Output Layer):在Transformer的末端,通常有一个或多个全连接层,用于生成最终的输出。
这些组件通常以特定的方式堆叠在一起,形成一个深度网络。
Transformer模型的主要特点
Transformer模型具有以下几个主要特点:
- 自注意力机制:Transformer能够在处理序列数据时考虑到序列中的每个位置。
- 并行处理能力:Transformer可以并行处理序列中的所有元素,大大提高了计算效率。
- 长距离依赖处理:有效地捕捉序列中的长距离依赖关系。
- 多尺度信息融合:通过多头注意力机制,有助于模型捕捉到不同尺度的特征。
与其他模型的比较
当将Transformer模型与CNN、RNN和LSTM进行比较时,我们可以从不同的角度来分析它们的特性、优势和局限性。
- CNN:在处理图像等空间数据时非常有效,计算效率较高。
- RNN:适合处理序列数据,能够捕捉时间动态变化,但受限于序列的长度。
- LSTM:在处理长序列时比标准RNN更有效,能够捕捉长期依赖关系。
- Transformer:在处理长序列时表现出色,具有高效的并行计算能力,适合用于大规模数据集的训练。
每种模型都有其独特的优势和应用场景。在实际应用中,选择哪种模型往往取决于具体任务的性质和数据的特点。
成功的关键因素
Transformer模型之所以取得成功,主要归因于以下几个关键因素:
- 自注意力机制:允许模型捕捉到序列中的长距离依赖关系。
- 并行处理能力:大大提高了计算效率。
- 多尺度信息融合:通过多头注意力机制,有助于模型捕捉到不同尺度的特征。
- 灵活性和可扩展性:结构简单,易于扩展和修改。
- 成功的应用案例:在自然语言处理领域取得了显著的成果。
- 社区的贡献和开源资源:推动了Transformer模型的研究和应用。
Transformer模型在处理序列数据方面具有强大的能力和广泛的应用前景,但同时也需要注意其内存消耗和对训练数据的需求。
本期的小琳AI课堂就到这里,希望对大家有所帮助!️
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 小琳AI课堂:深入学习Transformer模型

发表评论 取消回复