将这两种排序放在一起的原因是它们都属于 “插入”(式)排序。
还有很多排序思想,这里不放在一篇文章介绍是因为会导致篇幅过长,我们会按分类多次介绍不同的排序方法,最终会合并为一个排序总集。
插入排序
算法介绍
这里的插入排序指的是直接插入排序是一种简单直观的排序算法。它的工作方式是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。 插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,找到排序位置后,需要将已排序元素逐步向后挪位,为新元素提供插入空间。
具体步骤如下:
- 从第一个元素开始,该元素可以认为已经被排序。
- 取出下一个元素,在已经排序的元素序列中从后向前扫描。
- 如果该元素(已排序)大于新元素,将该元素移到下一位置。
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置。
- 将新元素插入到该位置后。
- 重复步骤2~5。
【图示】
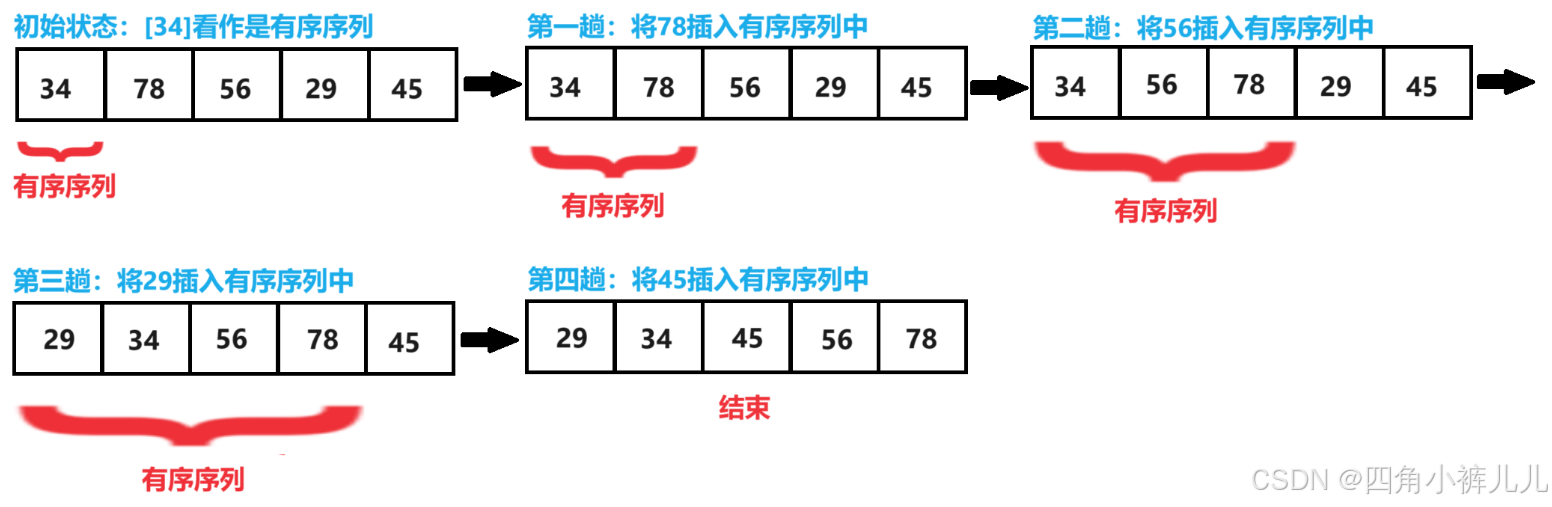
代码实现
代码演示均采用升序:
public void insertSort(int[] array) {
//从第2个位置开始向有序序列中插入
for(int i = 1; i < array.length; i++) {
int tmp = array[i];
int pos = i - 1;
//向前扫描
for(int j = i - 1; j >= 0; j--) {
if(array[j] > tmp) {
array[j+1] = array[j];
pos--;
}else {
break;
}
}
array[pos+1] = tmp;
}
}
复杂度和稳定性
时间复杂度:
- 平均情况:
O(N^2) - 最好情况:
O(N),当序列基本有序时
空间复杂度:O(1)
稳定性:稳定,我们可以通过控制条件达到稳定:相等就不再继续向前扫描比较。
希尔排序
算法介绍
希尔排序,又称缩小增量排序,是插入排序的一种更高效的改进版本。
当序列基本有序时,直接插入排序的时间复杂度可以达到O(n),而当原序列随机性很大时直接插入排序的时间复杂度为O(n^2),基于这一点,在直接插入排序前,进行预排序,使得原序列接近有序,再执行直接插入排序,那么效率就比直接插入排序高。
希尔排序的基本思想就是将整个待排序的记录序列分割成为若干个子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
分割为若干个子序列意味着需要分组,为什么要分组?
如果一下对所有元素(假设n个)进行直接插入排序,时间性能差;但是,当分组后,对每个组内的元素进行直接插入排序,相当于n值变小了,有时可以忽略,性能有所提升。
那么怎样分割出若干个子序列,怎么分组?分组后怎么做?
分组需要确定gap值,gap值在希尔排序中用于定义元素间比较的“跳跃”距离,关于gap值的选取是另一个问题,我们先选择gap = gap / 2的方案(按照gap = gap / 2来不断减小gap值,直到最后为1)来讲解分组,如图:
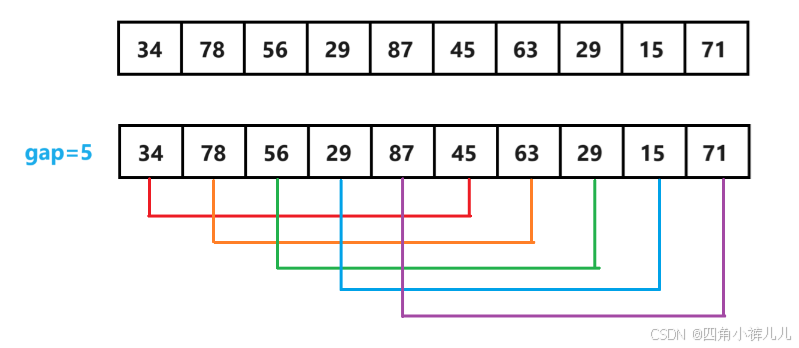
如图,希尔排序采用的是跳跃式分组,如34和45为一组,而不是34和紧挨的78为一组,跳跃式分组后,采用组内(相同颜色的线连接)直接插入排序,跳跃式分组并排序的好处是:能让较小的数更快地到达前面,较大的数更快地到达后面。且gap的值越大,小数就能越快地到达前面,大数就能越快地到达后面。

如图,这一趟完成了gap = 5时的组内排序,每个组内元素组成的序列均有序,使得整体变得有序起来。
接着,以gap = 5 / 2 = 2分组并排序:

以gap = 2 / 2 = 1 进行整体的直接插入排序,此时整体已经基本有序,时间性能较好。

算法步骤如下:
- 选择增量序列:首先取一个整数d1=n/2(n是数组的长度),将元素分为d1个组,每组相邻元素之间相隔d1个位置。在各组内进行直接插入排序;
- 重复分组排序:然后,取第二个增量d2=d1/2,重复上述的分组排序过程,直到di=1,即所有记录在同一组内进行直接插入排序。
关于gap值,通常采用gap = gap / 2或者gap = gap / 3 + 1的方案,但没有最优解:

【图示】
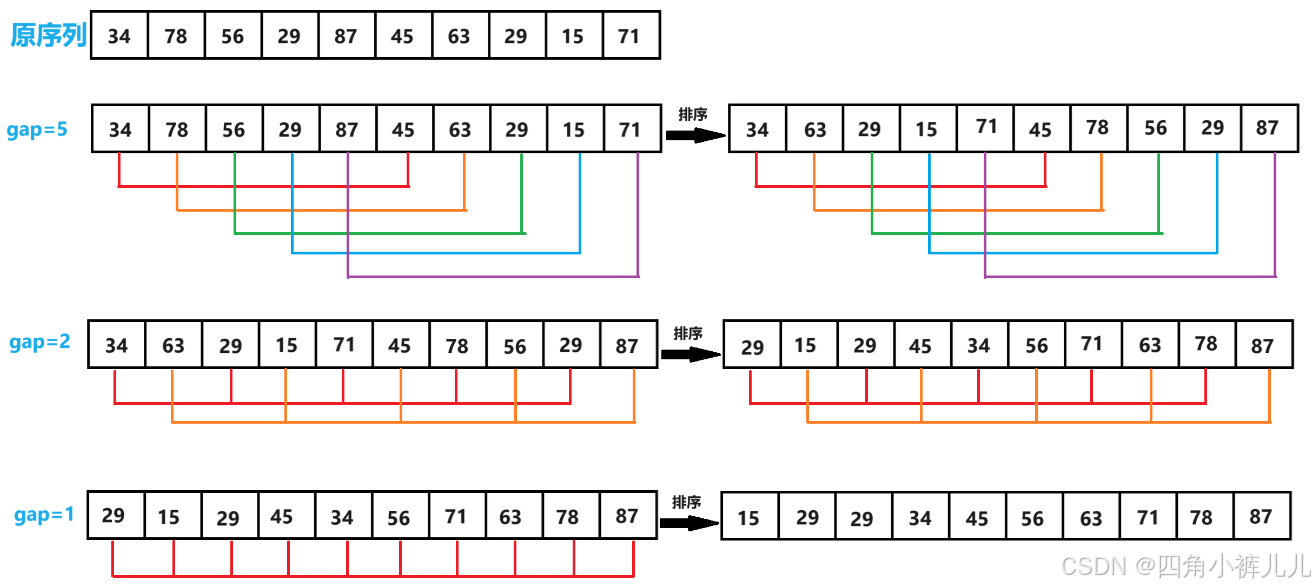
代码实现
代码演示均采用升序:
public void shellSort() {
int gap = array.length;
//gap值(增量)会不断缩小
while(gap > 1) {
gap /= 2;
//直接插入排序,但有所修改
for(int i = gap; i < array.length; i++) {
int tmp = array[i];
int pos = i - gap;
for(int j = i - gap; j >= 0; j-=gap) {
if(array[j] > tmp) {
array[j+gap] = array[j];
pos-=gap;
}else {
break;
}
}
array[pos+gap] = tmp;
}
}
}
-
直接插入排序逻辑部分,外层for循环的循环变量要初始化为
gap,因为要寻找组内"第二个"元素(第一个元素已经有序),内层for循环的循环变量从int j = i - 1修改为int j = i - gap,同时j-=gap保证了在组内进行比较,包括后面array[pos+gap] = tmp也是保证"组内性" -
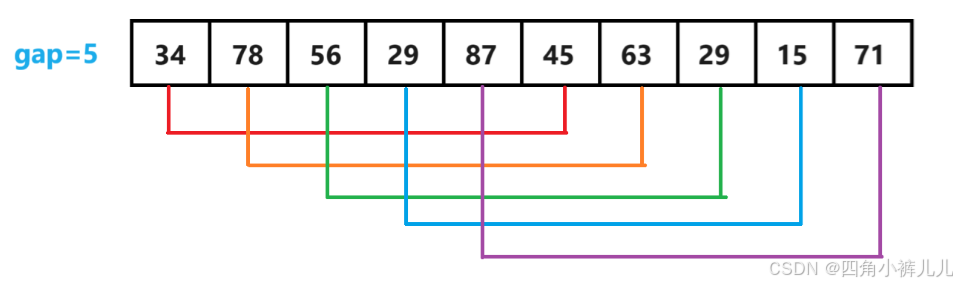
值得讨论的就是外层的for循环为什么使用
i++,而不是i+=gap,通过图来解释一下:第一次进入外层for循环,i 的值为45,这一次循环对[34, 45]组进行了组内排序;
完成后,如果循环变量的变化为
i+=gap,此时 i 的值变化为10,直接结束了gap = 5时的这一次预排序,但实际上还有4组没有完成组内排序;如果循环变量的变化为i++,此时 i 的值变化为6,即指向63的位置,继续进行预排序。继续观察
gap = 2:此时,第一次进入外层for循环,i 指向29,按照
i++的变化,第二次进入外层for循环时,i 指向15,指向了另一个分组,有影响吗?其实不影响,这种 组间跳跃式排序最终可以完成任务,因为有
j-=gap的约束,即使跳组了,也是在该组内进行排序。

复杂度和稳定性
时间复杂度:O(N*log2N)
实际上,希尔排序的时间复杂度并不是严格的O(N*log2N)。希尔排序的性能与所选择的增量序列有很大关系,不同的增量序列会导致算法的性能有所不同。其最坏时间复杂度仍可能是O(N^2),还是依赖于增量序列的选择,但 通常被认为是比O(N^2)要好,但不如O(N*log2N)那么优秀。 具体一点,其平均时间复杂度在O(N^1.3)~O(N^1.5)。

空间复杂度:O(1)
稳定性:不稳定,由于子序列的划分和插入排序的特性,相同大小的元素可能会在不同的子序列中被重新排序,从而改变了它们之间的相对位置。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Java数据结构(八)——插入排序、希尔排序

发表评论 取消回复