文章目录
前言
排序算法是计算机科学中最基础的算法之一,广泛应用于数据处理、搜索、优化等各种场景。排序的目的是将一组数据按一定的顺序(通常是升序或降序)排列,以便后续的高效处理。常见的排序算法有很多种,每种算法都有其特点和适用场景。本文将介绍排序算法的基本概念,并总结这些算法的优缺点和应用场景。
排序算法的稳定性
排序算法的稳定性是指当我们用排序算法对一组元素进行排序时,如果两个元素的值相同,它们在排序后的结果中保持原来的相对顺序,那么这个排序算法就是稳定的。如果排序后这两个元素的相对顺序可能改变了,那么排序算法就是不稳定的。
想象你在图书馆里整理书籍。你有一堆书,每本书都有一个作者和一个出版年份。如果你按出版年份排序这些书,但书的作者顺序保持不变(比如,《书A》和《书B》都是2010年出版的,且《书A》在《书B》前面),那么这个排序过程就是稳定的。
稳定排序算法的例子
-
冒泡排序(Bubble Sort):
- 冒泡排序会逐一比较相邻的元素,并交换它们的位置,使较大的元素逐渐“冒泡”到列表的末尾。它保证了相同值的元素在排序后保持原来的相对顺序。
-
插入排序(Insertion Sort):
- 插入排序将每个元素逐一插入到已经排好序的部分中。相同值的元素在插入时保持了它们原有的相对位置,因此插入排序也是稳定的。
-
归并排序(Merge Sort):
- 归并排序通过将数组分成小块,分别排序,再将小块合并。合并时,它会保持相同值元素的相对顺序,从而保证了稳定性。
不稳定排序算法的例子
-
选择排序(Selection Sort):
- 选择排序每次从未排序部分中选择最小(或最大)的元素,并将其放到已排序部分的末尾。这个过程中,如果遇到相同值的元素,可能会打破它们的相对顺序,因此选择排序是不稳定的。
-
快速排序(Quick Sort):
- 快速排序使用分治策略,通过选择一个基准元素,将数组分成两部分。相同值的元素在分组过程中可能会重新排列,因此快速排序通常是不稳定的。
-
堆排序(Heap Sort):
- 堆排序通过构建堆数据结构来排序。因为堆的构造过程可能会打破相同值元素的原始相对顺序,所以堆排序通常是不稳定的。
总结
排序算法的稳定性就是看相同值的元素在排序后是否保持原来的顺序。稳定排序算法确保了相同值元素的相对位置不会改变,而不稳定排序算法则可能会改变它们的相对顺序。理解这一点可以帮助你选择合适的排序算法来满足特定的需求。
有序度和逆序度
有序度和逆序度是用来描述一个序列中元素排列情况的两个概念。它们帮助我们理解数据的“有序程度”,即数据的顺序情况。
有序度(Sortedness)
有序度指的是一个序列中元素的有序程度。简单来说,就是有多少对元素是按照正确的顺序排列的。这里有几种常见的情况:
-
完全有序:
- 所有元素都按照升序或降序排列。例如,
[1, 2, 3, 4, 5]是完全有序的升序序列,[5, 4, 3, 2, 1]是完全有序的降序序列。
- 所有元素都按照升序或降序排列。例如,
-
部分有序:
- 序列中的某些部分是有序的,但整体上可能不是。例如,
[1, 3, 2, 4]是部分有序的,因为前两元素是升序的,后两元素也是升序的,但整体上不是完全有序的。
- 序列中的某些部分是有序的,但整体上可能不是。例如,
-
无序:
- 序列中没有明显的顺序。例如,
[4, 1, 3, 2]是无序的。
- 序列中没有明显的顺序。例如,
逆序度(Inversion Count)
逆序度是用来衡量一个序列中有多少对元素的顺序是相反的。换句话说,就是多少对元素在原始序列中的位置不符合升序排列的规则。
- 逆序对:
- 如果序列中第
i个元素大于第j个元素(i < j),那么(arr[i], arr[j])就是一个逆序对。
- 如果序列中第
计算逆序度的例子
假设我们有一个序列 [3, 1, 2]:
- 比较
3和1,3>1,所以(3, 1)是一个逆序对。 - 比较
3和2,3>2,所以(3, 2)是另一个逆序对。 - 比较
1和2,1<2,所以(1, 2)不是逆序对。
在这个例子中,总共有两个逆序对:(3, 1) 和 (3, 2)。因此,逆序度是 2。
总结
- 有序度:描述序列中元素有序的程度。可以是完全有序、部分有序或无序。
- 逆序度:计算序列中有多少对元素的顺序是相反的。用来衡量序列的无序程度。
理解这两个概念可以帮助你更好地分析和处理数据中的排序问题。
满有序度
满有序度(Sortedness Degree)是用来描述一个序列的有序程度的度量,它是用来表示一个序列在多大程度上接近完全有序的情况。简单来说,满有序度告诉我们,当前的序列距离完全有序的状态有多远。
想象你有一堆牌,你的目标是把这些牌按从小到大的顺序排好。如果你已经有一些牌排得很整齐,那么满有序度就可以告诉你这些整齐的牌占总牌的比例。
计算公式
满有序度的计算通常基于序列中的逆序对,它可以用以下公式来表示:

或者简单说,就是:

解释
- 当前逆序对数:序列中实际存在的逆序对的数量。即每对在原始序列中位置不符合升序排列的元素对。
- 最大逆序对数:在最大程度的无序状态下,序列中的逆序对总数。对于一个长度为
n的序列,最大逆序对数是
。
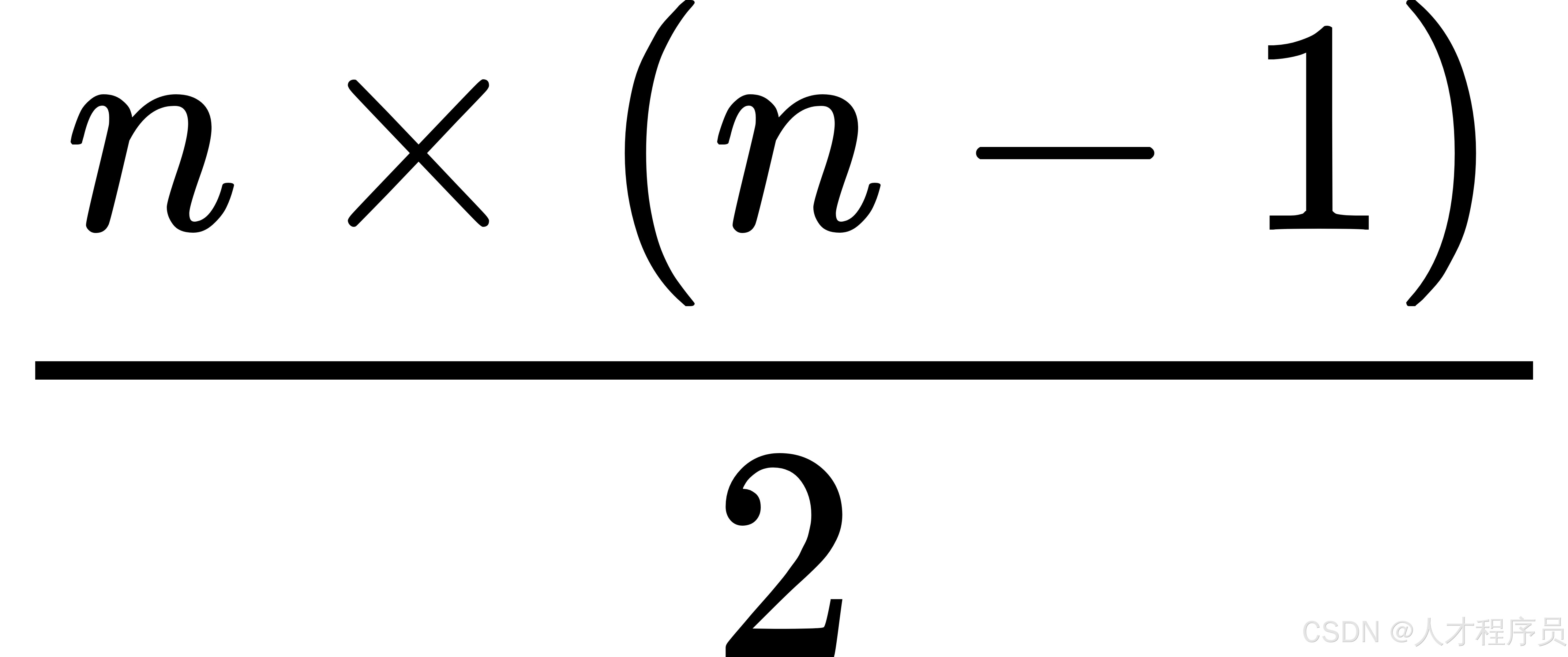
举个例子
假设你有一个序列 [3, 1, 2]:
-
计算当前逆序对数:
(3, 1)是一个逆序对。(3, 2)是另一个逆序对。- 总逆序对数是 2。
-
计算最大逆序对数:
- 序列长度是 3。
- 最大逆序对数是
。
-
计算满有序度:
- 满有序度 =
- 满有序度 =
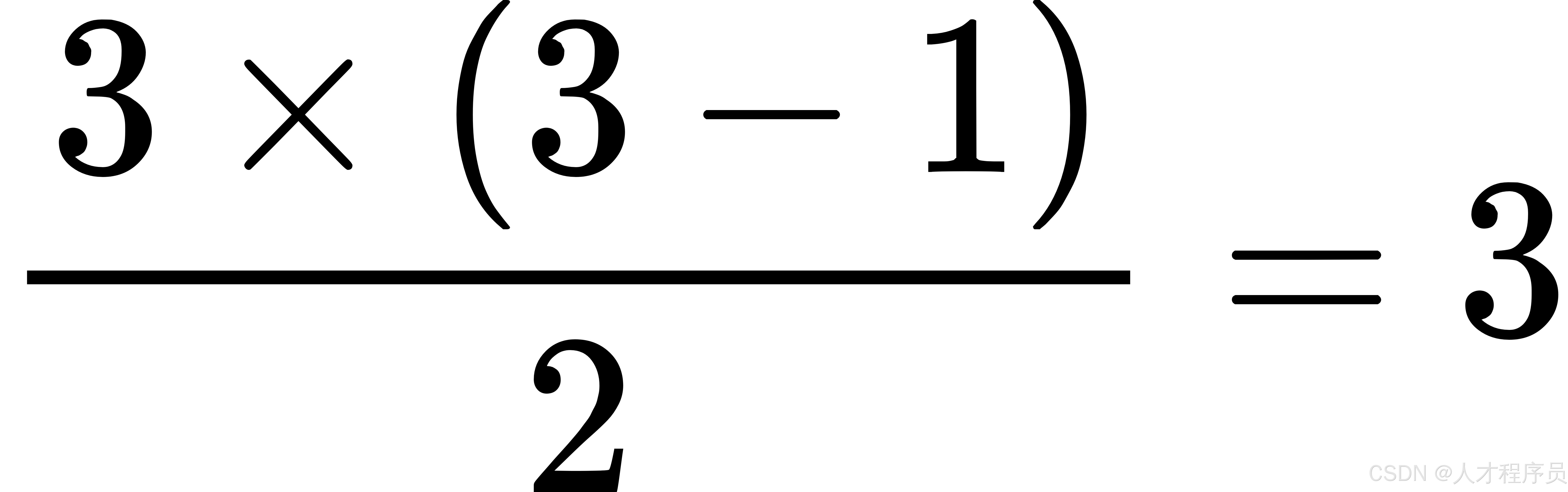
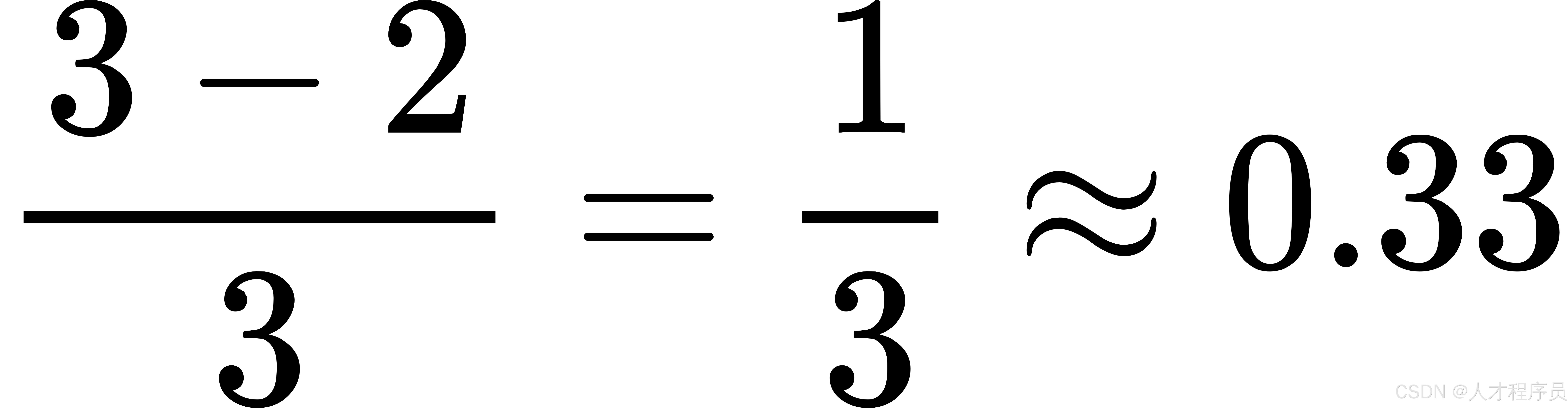
这意味着在这个例子中,序列的满有序度约为 0.33,表明它还距离完全有序的状态有一定的距离。
总结
满有序度是一个量化序列有序程度的度量,它通过计算逆序对的数量来反映序列的有序程度。它告诉我们序列离完全有序的状态有多远,从而可以帮助我们理解和优化排序过程。
总结
排序算法在不同的应用场景中扮演着重要角色,不同的算法在执行效率、空间复杂度、稳定性等方面各有千秋。比如,快速排序在平均情况下非常高效,适用于大量数据,但它是不稳定的;归并排序虽然在时间复杂度上表现优异且稳定,但需要额外的空间。理解各种排序算法的特性,可以帮助我们根据实际需求选择合适的算法,从而在程序设计中达到更高效、更合理的效果。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » CSP-J 算法基础 排序算法的基本概念

发表评论 取消回复