研究背景
大型语言模型(LLMs)已经成为解决多种自然语言处理(NLP)任务的主要工具。然而,尽管这些模型在生成流畅的文本方面表现出色,但它们往往难以遵循用户的复杂指令。这限制了它们在实际应用中的广泛使用。过去,NLP领域的研究主要依赖于人类编写的任务指令来训练这些模型,以改善它们的指令执行能力。然而,人工创建复杂指令数据既耗时又费力,且往往难以涵盖广泛的任务复杂度。当前指令数据集的难度分布通常偏向于简单或中等难度,而复杂指令的比例较低,这主要是因为创建复杂指令需要较高的专业知识和大量的脑力劳动。此外,人工标注人员容易疲劳,这进一步限制了复杂指令的生成。
为了克服这些挑战,研究者们开始探索通过自动化方法生成大规模且复杂的指令数据,以提高LLMs的表现。Evol-Instruct方法便是在这一背景下提出的,它通过使用LLMs来自动生成不同难度级别的开放域指令数据,从而减少对人工创建指令的依赖,并提高LLMs处理复杂任务的能力。
研究目标
本研究提出了一种新方法Evol-Instruct,旨在通过LLMs自动生成复杂度多样的开放域指令数据,以改进LLMs的性能。研究的目标是使用这一方法生成大规模的复杂指令数据,并验证这些数据对LLMs性能提升的有效性,最终得到的模型称为WizardLM。
相关工作
闭域指令微调
早期的指令跟随模型训练工作主要集中在跨任务的通用化上,即在广泛的公共NLP数据集上微调语言模型,并在不同的NLP任务上进行评估。例如,T5模型将多个NLP任务(如问答、文档摘要、情感分类)训练在统一的文本到文本格式中。类似的工作包括FLAN、ExT5、T0等,这些研究通过增加任务的数量和多样性,增强了模型在新任务上的表现。然而,这些方法通常仅适用于特定的NLP任务,且输入数据的形式较为简单,导致模型在实际用户场景中容易失效。
开放域指令微调
本研究属于开放域指令微调的研究范畴。OpenAI通过雇佣大量标注人员编写多样化的指令,并用这些人类生成的指令数据训练LLMs,成功开发了InstructGPT和ChatGPT。尽管这些开创性的工作取得了显著成功,但由于这些模型的封闭性,研究者们无法直接使用它们的数据。因此,Alpaca和Vicuna等后续工作积极探索基于开源LLM LLaMA的开放域指令微调。这些方法分别利用了Alpaca的自指令生成方法和Vicuna从ShareGPT收集的用户共享对话数据。与这些方法不同,本研究通过Evol-Instruct自动生成AI数据进行指令微调,不同于Alpaca的self-instruct方法,Evol-Instruct能够控制生成指令的难度和复杂度。
方法论
数据处理
以具体化输入(Concretizing)为例,prompt模板为:

以历史问答场景为例:
原始问答指令为:
谁是二战期间美国的领导人?
经过演化后的指令为:
在第二次世界大战期间,美国的总统和最高指挥官是谁?
解决方案
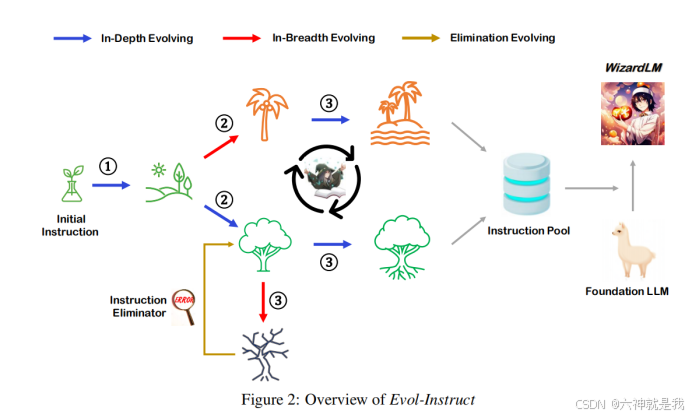
指令演化(Instruction Evolution):
- 研究首先从一个初始的简单指令数据集开始,通过预设的指令演化提示词,使这些简单指令逐步演化为更复杂的指令。这个过程包括了深度演化和广度演化两种方式。深度演化旨在增加指令的复杂性和难度,而广度演化则通过生成完全新的指令来增加指令集的多样性。
- 深度演化的主要策略包括增加约束条件、加深推理步骤、具体化输入、复杂化输入以及增加推理步骤。广度演化则是通过变异生成新的指令,以扩大指令集的覆盖面。
响应生成(Response Generation):
- 使用与演化相同的LLM来生成这些复杂指令的对应响应。生成的响应也将作为模型训练的一部分,以提高模型对复杂指令的处理能力。
演化淘汰(Elimination Evolving):
- 在每一轮的指令演化过程中,系统会通过特定的准则筛选出演化失败的指令。这些失败的指令包括那些无法带来信息增益的指令,以及模型难以生成有效响应的指令。这些淘汰指令将在后续的演化轮次中重新尝试改进。
架构如下:
实验
实验设计
基准模型选择:
实验中选择了ChatGPT、Alpaca、Vicuna作为基准模型进行对比。这些模型代表了当前指令微调技术的不同方法和水平。
数据集构建:
实验首先从Alpaca的52K初始指令数据集中开始,经过4轮演化,生成了250K条指令数据。为了公平比较,研究者从这250K数据中随机抽取了70K条用于训练LLaMA 7B模型,这一模型被命名为WizardLM。
为了验证模型在复杂任务上的表现,研究者手动创建了一个难度平衡的测试集,命名为Evol-Instruct testset。这个测试集包含了来自多种来源的真实世界指令,涵盖了29种技能。
测试集构建与评估方法:
研究设计了两个测试集:Evol-Instruct testset和Vicuna testset。前者更关注复杂指令的表现,而后者则用于比较模型在常规任务上的表现。
评估包括人类评估和gpt4自动评估:
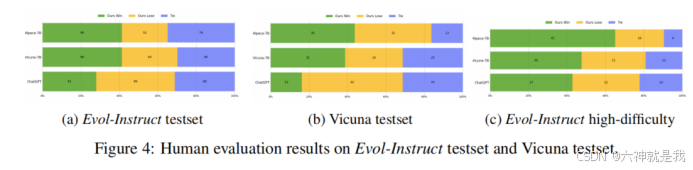
人类评估通过盲测的方式进行,10名高学历标注人员对每个模型的输出进行评分,评估维度包括相关性、知识水平、推理能力、计算准确性和整体准确性。
GPT-4自动评估是基于GPT-4模型来衡量不同语言模型输出质量的一种方法。这种方法最早由Vicuna项目提出,并用于对比多个开源模型的表现。研究者使用GPT-4模型来进行对话生成任务的评估,以此代替传统的人工评估,从而提高评估过程的效率和客观性。
实验结论
实验结果展示了WizardLM的显著优势:
模型性能:
在Evol-Instruct testset上的评估显示,WizardLM在复杂任务上的表现优于Vicuna和Alpaca,尤其是在高难度指令部分,WizardLM甚至超越了ChatGPT。这表明Evol-Instruct方法在增强LLMs处理复杂指令能力方面具有潜力。
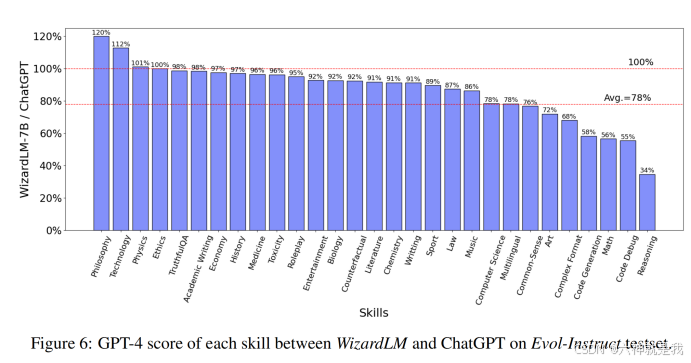
GPT-4的自动评估结果进一步证明了这一点,WizardLM在17项技能中达到了ChatGPT 90%以上的性能,尽管在代码、数学和推理场景上仍有一定的差距。
复杂性与广度的提升:
在实验中,Evol-Instruct生成的指令数据不仅在复杂性上超过了人类生成的数据(如ShareGPT),而且在主题覆盖和技能多样性上也优于现有的数据集。
结论
总结
本研究通过提出Evol-Instruct方法,成功展示了如何利用LLMs自动生成复杂指令数据,并在实验中证明了这些数据对提升LLMs性能的显著作用。通过对WizardLM的评估,研究表明该方法在处理复杂任务方面具有明显优势,并为未来的指令微调研究提供了新的思路和方向。未来的研究将致力于进一步优化这一方法,并探索其在更多应用场景中的潜力。
未来研究方向
- 优化自动评估方法:虽然GPT-4和人类评估方法为实验提供了可靠的数据支持,但如何进一步提高这些评估方法的可扩展性和准确性仍然是一个值得探索的问题。
- 扩大测试集的多样性和覆盖面:当前的测试集尽管涵盖了广泛的技能和任务,但仍有可能无法完全代表所有可能的使用场景。未来研究可以考虑引入更多领域的指令数据,以验证模型的通用性和适应性。
- 深入研究AI生成指令的伦理和社会影响:Evol-Instruct方法虽然在技术上展现了潜力,但其自动生成复杂指令的能力也可能带来伦理和社会问题。例如,生成有害或误导性指令的风险需要在未来的研究中得到充分的考虑和解决。
参考资料
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【LLM之Data】WizardLM论文阅读笔记

发表评论 取消回复