索引分类
根据索引的存储形式,又可以分为聚集索引和二级索引

索引语法
创建索引
CREATE [UNIQUE| FULLTEXT] INDEX index_name ON table name index_col_name,...);
查看索引
SHOW INDEX FROM table_name;
删除索引
DROP INDEX index_name ON table_name;聚簇索引
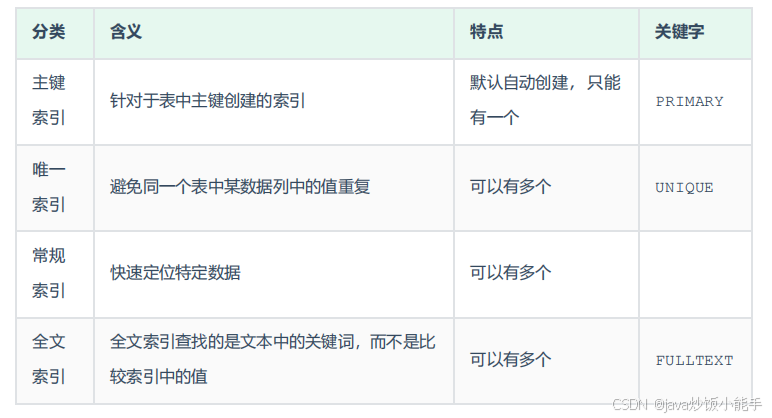
简单点理解就是将数据与索引放到了一起,找到索引也就找到了数据。也就是说,对于聚簇索引来说,他的非叶子节点上存储的是索引字段的值,而他的叶子节点上存储的是这条记录的整行数据。
在InnoDB中,聚簇索引指的是按照每张表的主键构建的一种索引方式,它是将表数据按照主键的顺序存储在磁盘上的一种方式。这种索引方式保证了行的物理存储顺序与主键的逻辑顺序相同,因此查找聚簇索引的速度非常快。
非聚簇索引
就是将数据与索引分开存储,叶子节点包含索引字段值及指向数据页数据行的逻辑指针。
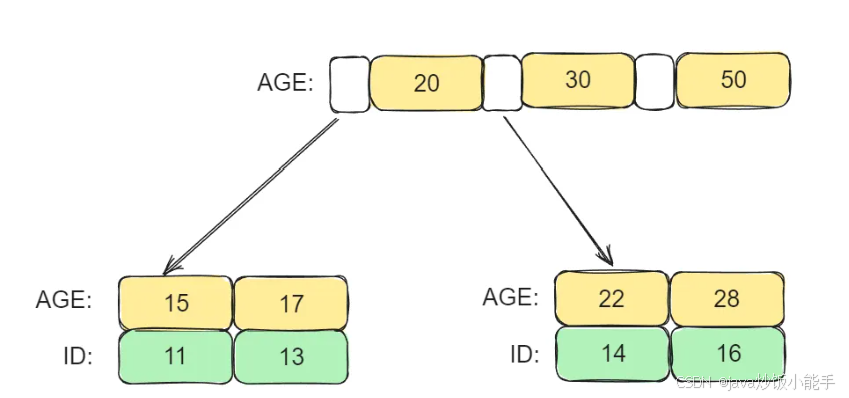
在Innodb中,非聚簇索引(Non-clustered Index)是指根据非主键字段创建的索引,也就是通常所说的二级索引。它不影响表中数据的物理存储顺序,而是单独创建一张索引表,用于存储索引列和对应行的指针。在InnoDB中,主键索引就是聚簇索引,而非主键索引,就是非聚簇索引,所以
总结就是:
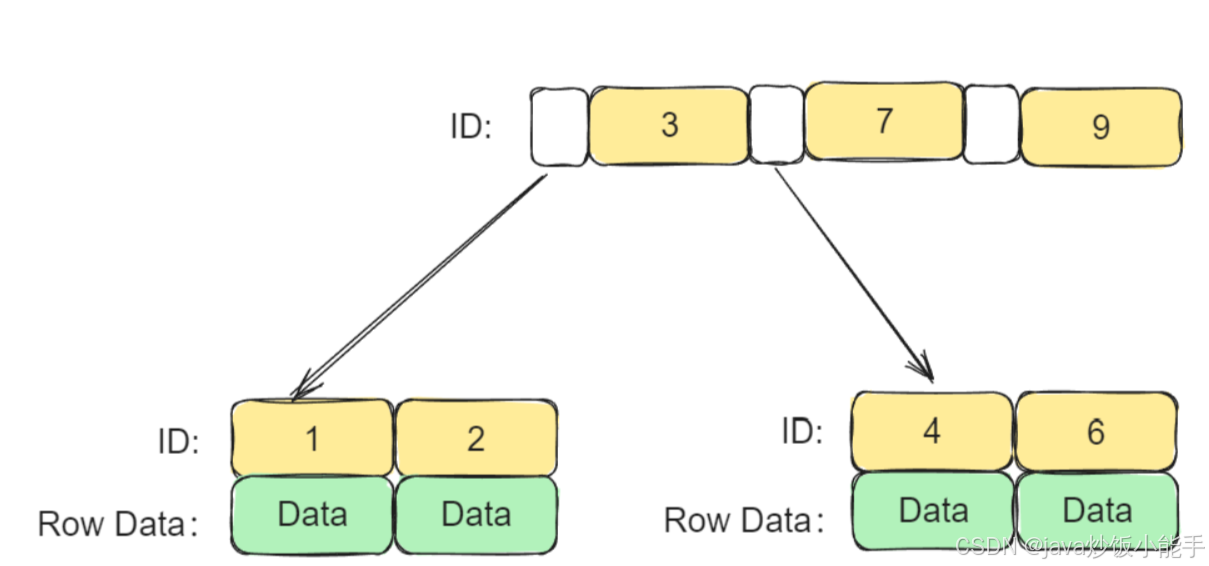
对于聚簇索引来说,他的非叶子节点上存储的是索引值,而它的叶子节点上存储的是整行记录。
对于非聚簇索引来说,他的非叶子节点上存储的都是索引值,而它的叶子节点上存储的是主键的值+索引值。
所以,通过非聚簇索引的查询,需要进行一次回表,就是先查到主键ID,在通过ID查询所需字段。
什么是回表?
那么,当我们根据非聚簇索引查询的时候,会先通过非聚簇索引查到主键的值,之后,还需要再通过主键的值再进行聚簇索引查询才能得到我们要查询的数据。而这个过程就叫做回表。
如何降低回表次数,提高查询效率
所以,在InnoDB中,使用主键查询的时候,是效率更高的,因为这个过程不需要回表。另外,依赖覆盖索引技术,我们也可以通过优化索引结构以及SQL语句减少回表的次数。
最左前缀法
首先创建一个联合索引,指的就是有多个字段组成的一个联合索引,如 idx_c1_c2_c3(c1,c2,c3))
如果你的查询条件是针对c1、(c1,c2)或者(c1,c2,c3),那么MySQL可以利用这个复合索引进行最左前缀匹配,反正就是从左往右,中间不能断。
而且如果你用的是(c1,c3)也是可以走索引的,只不过他用到的是 c1这个字段的索引。(前提是c1字段有索引,否则(c1,c3)就不走索引)
但是,如果查询条件涉及到的列只有c2或者只有c3或者只有c2和c3,总之就是如果不包含c1的话,那么是没有遵守最左前缀匹配,那么通常情况下(不考虑索引跳跃扫描等其他优化),就不能利用这个索引进行最左前缀匹配。
覆盖索引
覆盖索引(covering index)指一个查询语句的执行只用从索引中就能够取得,不必从数据表中读取。也可以称之为实现了索引覆盖。
当一条查询语句符合覆盖索引条件时,MySQL只需要通过索引就可以返回查询所需要的数据,这样避免了查到索引后再返回表操作,减少1/O提高效率。
如,表tb中有一个普通索引 idx_c1_c2(c1,c2).
当我们通过SQL语句:
select c2 from tb where c1 =‘keytest';的时候,就可以通过覆盖索引查询,无需回表。
解释:我们通过c1和c2的联合索引查询时,是不是已经可以得到c2了,我们不需要其他信息,那何必要回表呢。
select c1,c2 from tb where c1 =‘keytest';也是同样道理。
但是以下SQL,因为不符合最左前缀匹配,联合索引失效,虽然是索引覆盖,但是也无法用到索引
select c1 from tb wherec2 =‘keytest';
前缀索引
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » mysql索引

发表评论 取消回复