第四章 TCP粘包/拆包问题
4.1 TCP 粘包/拆包
TCP是流协议,也就是没有界限的的一串数据,底层并不知道上层业务数据的具体含义,也就是说一个完整的包可能会被拆分成多个包进行发送,也可能把几个小包封装成一个大的数据包发送。这就是拆包和粘包
4.1.1 TCP粘包拆包问题说明
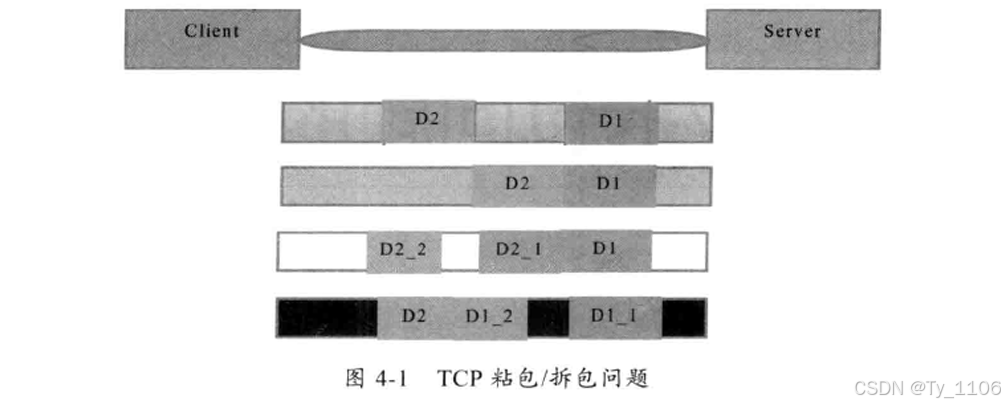
存在4种情况
-
服务端分两次读取到了两个独立的数据包,分别是D1和D2,没有粘包和拆包;
-
服务端一次接收到了两个数据包,D1和D2粘合在一起,被称为TCP粘包:
-
服务端分两次读取到了两个数据包,第一次读取到了完整的D1包和D2包的部分内容,第二次读取到了D2包的剩余内容,这被称为TCP拆包;
-
服务端分两次读取到了两个数据包,第一次读取到了D1包的部分内容D11,第二次读取到了D1包的剩余内容D12和D2包的整包。
如果此时服务端TCP接收滑窗非常小,而数据包D1和D2比较大,很有可能会发生第5种可能,即服务端分多次才能将D1和D2包接收完全,期间发生多次拆包。
4.1.2 原因
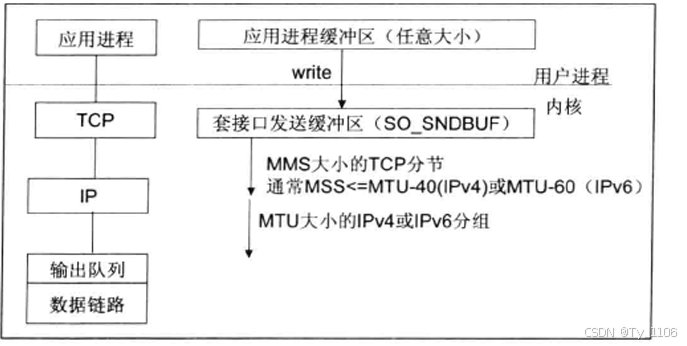
MTU(Maximum Transmission Unit),网络层能够传输的最大数据包大小(以字节为单位) MTU限制了在网络上传输的每个数据包的最大大小。
MMS(Maximum Segment Size),MMS是指TCP协议在一次传输中可以发送的最大数据量(不包括TCP头部的大小)。它是由MTU决定的,具体来说是MTU减去IP和TCP头部的大小。MMS定义了TCP每次发送数据时,数据段的最大大小。它保证了数据段能够顺利通过网络,而不会导致分片。
TCP粘包和拆包发生的原因:
- 应用程序write写入的字节大小大于套接口发送缓冲区大小
- 进行MSS大小的 TCP分段;
- 以太网帧的payload 大于MTU 进行IP 分片
4.1.3 粘包问题的解决
这个问题只能通过上层应用协议栈设计解决:
- 消息定长
- 包尾增加回车换行符进行分割,例如FTP协议
- 将消息分为消息头和消息体,消息头包含消息总长度(通常思路为消息头的第一个字段使用int32来表示消息总长度)
- 更复杂的应用层协议
4.2 TCP粘包导致的功能异常
会导致消息粘包,程序不能正常运作
4.3 利用LineBasedFrameDecoder解决
在Handler之前添加两个解码器,LineBasedFrameDecoder和StringDecoder
原理分析:
LineBasedFrameDecoder的工作原理是它依次遍历ByteBuf中的可读字节,判断看是否有“\”或者“\r\n”,如果有,就以此位置为结束位置,从可读索引到结束位置区间的字节就组成了一行。它是以换行符为结束标志的解码器,支持携带结束符或者不携带结束符两种解码方式,同时支持配置单行的最大长度。如果连续读取到最大长度后仍然没有发现换行符,就会抛出异常,同时忽略掉之前读到的异常码流。
StringDecoder的功能就是将接收到的对象转换成字符串,然后继续调用后面的 Handler。LineBasedFrameDecoder+StringDecoder 组合就是按行切换的文本解码器它被设计用来支持TCP的粘包和拆包。
Netty提供多种解码器
第五章 分隔符和定长解码器的应用
四种区分消息的方式:
- 消息定长,累计读取到长度总和为LEN的报文后,就认为读到了一个完整的消息,将计数器重置,读取下一个
- 包尾增加回车换行符进行分割,例如FTP协议
- 特殊分隔符作为消息的结束标志,比如回车换行符
- 将消息分为消息头和消息体,消息头包含消息总长度(通常思路为消息头的第一个字段使用int32来表示消息总长度)
Netty对这四种应用做了统一的抽象,提供了四种编码解码器
5.1 DelimiterBasedFrameDecoder
自动完成以分隔符做结束的消息的解码
5.1.1 服务端开发
创建一个DelimiterBasedFrameDecoder对象,加入到ChannelPipeline,有两个参数一个是单挑消息的最大长度,一个是分隔符缓冲对象
然后将StringDecoder加入Pipeline,将ByteBuf解码成字符串对象,再由ServerHandler处理业务
5.1.2 客户端开发
与服务端添加方法类似
5.2 FixedLengthFrameDecoder
固定长度解码器,能够按照指定长度对消息自动解码
5.2.1 服务端开发
在服务端的ChannelPipeline中新增FixedLengthFrameDecoder,长度设置为20,在依次添加字符串解码器和ServerHandler
利用 FixedLengthFrameDecoder 解码器,无论一次接收到多少数据报,它都会按照构造函数中设置的固定长度进行解码,如果是半包消息,FixedLengthFrameDecoder 会缓存半包消息并等待下个包到达后进行拼包,直到读取到一个完整的包。
第六章 编解码技术
进行远程传输时,将被传输的Java对象编码成字节数组或者ByteBuffer对象,远程服务读取到ByteBuffer对象或字节数组时,需要解码为发送时的Java对象。称为编解码技术
6.1 Java序列化的缺点
评判一个编解码框架的优劣时,往往会考虑以下几个因素。
- 是否支持跨语言,支持的语言种类是否丰富:
- 编码后的码流大小:
- 编解码的性能;
- 类库是否小巧,API使用是否方便;
- 使用者需要手工开发的工作量和难度。
几乎所有的Java RPC框架,都没有使用Java序列化作为编解码框架,有以下缺点
-
无法跨语言
-
序列化后的码流太大
-
序列化性能太低
6.2 主流的编解码框架
Netty中应用的一些编解码框架
6.2.1 Google的Protobuf
数据结构以.proto 文件进行描述,通过代码生成工具可以生成对应数据结构的POJO对象和Protobuf相关的方法和属性
特点:
- 结构化数据存储格式
- 高效的编解码性能
- 语言无关、平台无关、扩展性好
- 官方支持Java、C++和python
优点:
- 文本化的数据结构描述语言,可以实现语言和平台无关,特别适合异构系统间的集成;
- 通过标识字段的顺序,可以实现协议的前向兼容:
- 自动代码生成,不需要手工编写同样数据结构的C++和Java版本:
- 方便后续的管理和维护。相比于代码,结构化的文档更容易管理和维护。
6.2.2 Facebook的Thrift
支持数据序列化和多种类型的RPC服务,适用于静态的数据交换,需要先确定好数据结构,数据结构发生变化时,必须重新编辑IDL文件。支持二进制压缩编解码,所以性能表现也很优异
由五部分组成,
-
语言系统以及IDL编译器:负责由用户给定的IDL文件生成相应语言的接口代码;
-
TProtocol:RPC的协议层,可以选择多种不同的对象序列化方式,如JSON和Binary;
-
TTransport:RPC的传输层,同样可以选择不同的传输层实现,如socket、NIO、MemoryBuffer等:
-
TProcessor:作为协议层和用户提供的服务实现之间的纽带,负责调用服务实现的接口;
-
TServer:聚合TProtocol、TTransport和 TProcessor 等对象
编解码框架,与之对应的就是TProtocol。由于Thri的RPC服务调用和编解码框架绑定在一起,所以,通常我们使用Thrit的时候会采取RPC框架的方式。但是,它的TProtocol编解码框架还是可以以类库的方式独立使用的。
6.2.3 JBoss Marshalling
是一个Java对象的序列化API包,修正了JDK自带的序列化包的一些问题
优点:
- 可插拔的类解析器,提供更加便捷的类加载定制策略通 过口即可实现定制;
- 可插拔的对象替换技术,不需要通过继承的方式;
- 可插拔的预定义类缓存表,可以减小序列化的字节数组长度,提升常用类型的对象序列化性能;
- 无须实现 java.io.Serializable接口,即可实现 Java序列化;
- 通过缓存技术提升对象的序列化性能。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Netty权威指南:Netty总结-编解码与序列化

发表评论 取消回复