TDEngine快速入门

目录
概述
TDEngine创始人在官方出品的书籍中写到:我观察到,无论是出行行业还是更广义的运输行业,以及分布式能源系统,都将产生海量的时序数据。这些数据的规模超出了传统数据库或大数据平台的高效处理能力,迫切需要专用的时序数据处理工具。读到这段话我看到了创始人使命感,而我正是从事能源电力行业,电力行业有很大的一部分是物联网业务,所以个人肩负着对时序数据库知识的传播的”使命“。
本篇旨在帮助大家深入理解TDEngine,按照个人学习一项新技术的路线,我们首先需要去了解涉及到的核心概念,然后去学习基本的操作,另外会找一款趁手的可视化管理工具,这三方面是深入理解一项技术的关键。
一、核心概念解析
TDengine 采用 SQL 作为查询语言,大大降低学习成本、降低迁移成本,但同时针对时序数据场景,又做了一些扩展,以支持插值、降采样、时间加权平均等操作。既然采用的是SQL作为查询语言那我们就可以运用之前学习MySQL的经验了,首先了解一下支持的数据类型、数据库、表、函数、运算符等概念。
要了解清楚基本概念我们需要阅读快速入门这一章中三小结的内容,首先数据模型一章节讲解了如下内容:

在这一章节为了清晰地阐述时序数据的基本概念,官方通过结合示例的方式来讲解的,这里对比于MySQL有几个新的概念大家需要去理解一下
采集量
采集量是指通过各种传感器、设备或其他类型的采集点所获取的物理量,如电流、电压、温度、压力、GPS 等。
这些采集点在物联网领域称为测点,时序库中每一个测点占一列,而列中值就是采集量,类比MySQL中表的字段值。
标签
标签是指附着在传感器、设备或其他类型采集点上的静态属性,这些属性不会随时间发生变化,例如设备型号、颜色、设备所在地等。
在我理解标签也类比MySQL中表的字段值,只不过这一列的值同一设备时静态不变的值。
数据采集点
数据采集点是指在一定的预设时间周期内或受到特定事件触发时,负责采集物理量的硬件或软件设备。一个数据采集点可以同时采集一个或多个采集量,但这些采集量都是在同一时刻获取的,并拥有相同的时间戳。对于结构复杂的设备,通常会有多个数据采集点,每个数据采集点的采集周期可能各不相同,它们之间完全独立,互不干扰。
这里采集点也就是物联网业界称为测点,一个设备会有很多采集点。
超级表
TDengine 引入超级表(Super Table,简称为 STable)的概念。超级表是一种数据结构,它能够将某一特定类型的数据采集点聚集在一起,形成一张逻辑上的统一表
这里我理解超级表类比MySQL中视图的概念,不是具体的表,大家可以这样来理解这一概念。
时间戳
时间戳在时序数据处理中扮演着至关重要的角色,特别是在应用程序需要从多个不同时区访问数据库时,这一问题变得更加复杂。
时间戳是时序数据库比较有代表性的的一个特性,时序数据库是为了处理时序数据这一目标而设计的,而时序数据的特点就是根据时间连贯性的变化。
这些概念大概就这么多,我们在接触TDEngine架构的时候还会接触到几个新概念:dnode、mnode、vnode、qnode,要理解这几个概念我们需要看一张架构图:
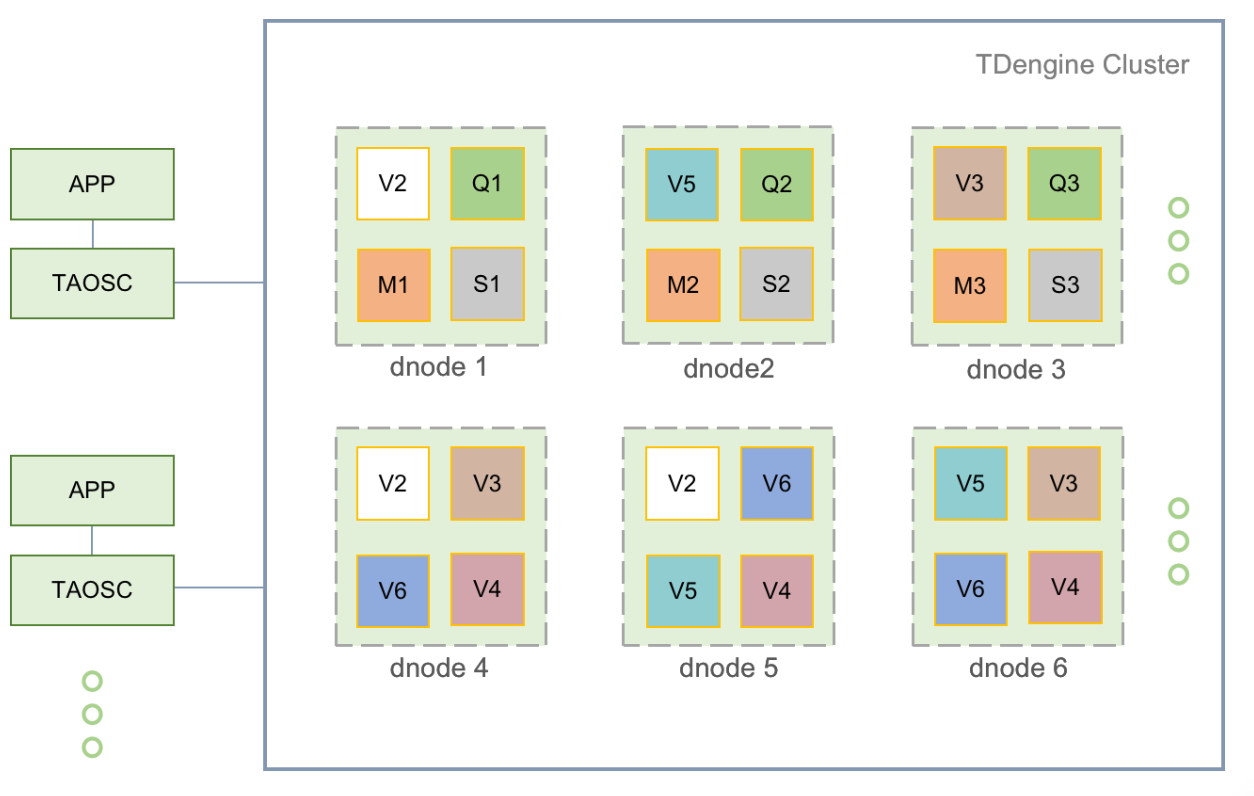
其中dnode是数据节点,mnode是管理节点,vnode是存储节点、qnode是查询节点。
了解清楚这些基础概念对我们整体理解TDEngine有很大的帮助。
二、基本操作
上一节分析了一下TDEngine的核心概念,有了这些概念,我们需要实际去操作一下才能更好的理解。
首先,我们需要部署安装实践环境,根据官方文档我们很容易搭建一个单机环境,部署集群环境比较复杂后续会出一篇文章来做讲解。搭建好数据库我们就需要建库、建表实践,之后去操作crud验证自己的理解。
创建数据库
创建一个数据库以存储电表数据的 SQL 如下:
CREATE DATABASE power PRECISION 'ms' KEEP 3650 DURATION 10 BUFFER 16;根据上面这条SQL我们就可以创建一个数据库了,但是这里需要注意如果生产使用我们需要事先配置好建库的参数,这里有些参数建库之后无法修改,例如vgroup默认是2,开源版只有建库的时候可以设置。
创建超级表
创建一张名为 meters 的超级表的 SQL 如下:
CREATE STABLE meters (
ts timestamp,
current float,
voltage int,
phase float
) TAGS (
location varchar(64),
group_id int
);
创建表
通过超级表创建子表 d1001 的 SQL 如下:
CREATE TABLE d1001
USING meters (
location,
group_id
) TAGS (
"California.SanFrancisco",
2
);
创建好实践环境我们就可以解析crud实践了,这里有一个不同点需要理解一下,时序数据库主要是适用新增和查询操作,其中删除优先考虑通过设置KEEP参数来实现,KEEP 是该数据库的数据保留多长天数,缺省是 3650 天(10 年),数据库会自动删除超过时限的数据,而更新则可以通过写入重复时间戳的一条数据来更新时序数据,新写入的数据会替换旧值。
三、可视化管理工具
日常管理数据库需要一款好用的可视化管理工具,这里推荐一款很好用的管理工具:
这个工具最大的优势是继承了市面上流行的数据库产品,实现了一个工具管理所有数据库的目标。
总结
本篇文章目标在于助力初学者快速掌握TDEngine这一款物联网大数据平台,大家在学习过程中如果有疑问欢迎留言交流。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【二】TDEngine快速入门

发表评论 取消回复