神经网络通俗理解学习笔记(1)
神经网络原理
汇聚n个线性变换,最后做一个非线性变换。
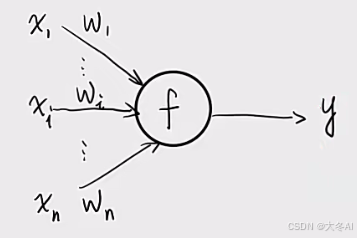
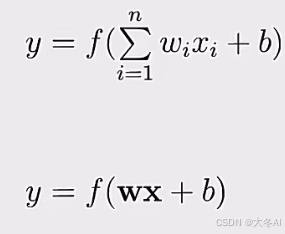
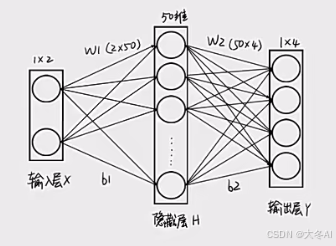
神经网络本质上是很多个线性模型的模块化组合
输入层是样本本身,维度就是样本维度
输出层是样本类别标签
隐藏层是最重要的神经元,并不是层数越多维度越大泛化能力越好,会出现过拟合问题。
隐藏层层数和维度多了容易过拟合,少了模型比较弱,隐藏层层数和维度2个指标需要综合考量,都是重要的超参数。
激活函数
用于非线性变换,必须是可导的
为什么引入非线性?
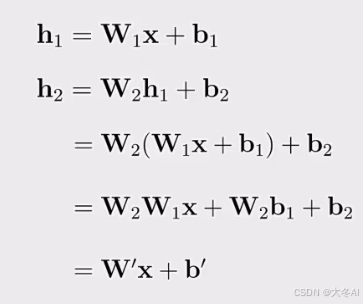
线性组合无法表示复杂的非线性数据。
神经网络模型的本质其实是如何用线性模型去解决非线性问题。
怎么引入非线性?
通过激活函数。(就可以对空间进行扭曲变换)
线性空间的非线性,在高维非线性空间却线性可分。
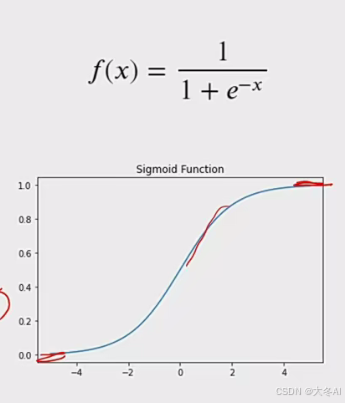
sigmoid函数
输出值压缩到(0,1),常用于二分类问题,其他一般不用,容易导致梯度消失问题
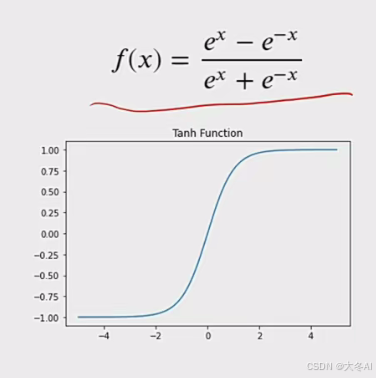
Tanh函数
是sigmoid函数的改进版,输出值压缩到(-1,1),输出以0为中心,更快的收敛速度,适用于多分类,输入值较大的时候也容易导致梯度消失
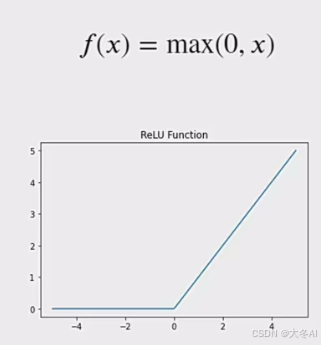
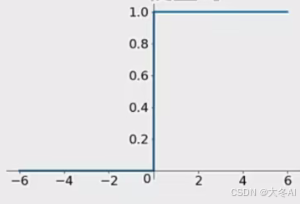
Relu函数
多数情况下的第一选择,解决梯度消失问题,计算速度快,但当输入为负数时某些权重无法更新。
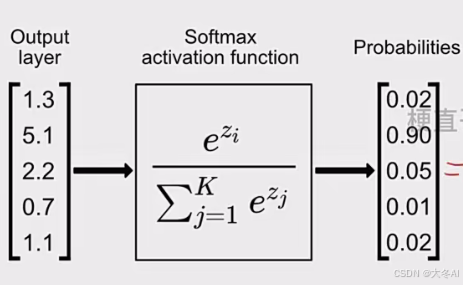
softmax函数
输入值映射到概率分布上
主要用在多分类问题
使得输出具有可解释性
激活函数用于给线性的矩阵运算非线性化
softmax作用是将输出转化为概率值,相当于归一化
损失衡量当前模型的好坏
反向传播是优化调整参数(权重w、截距b)
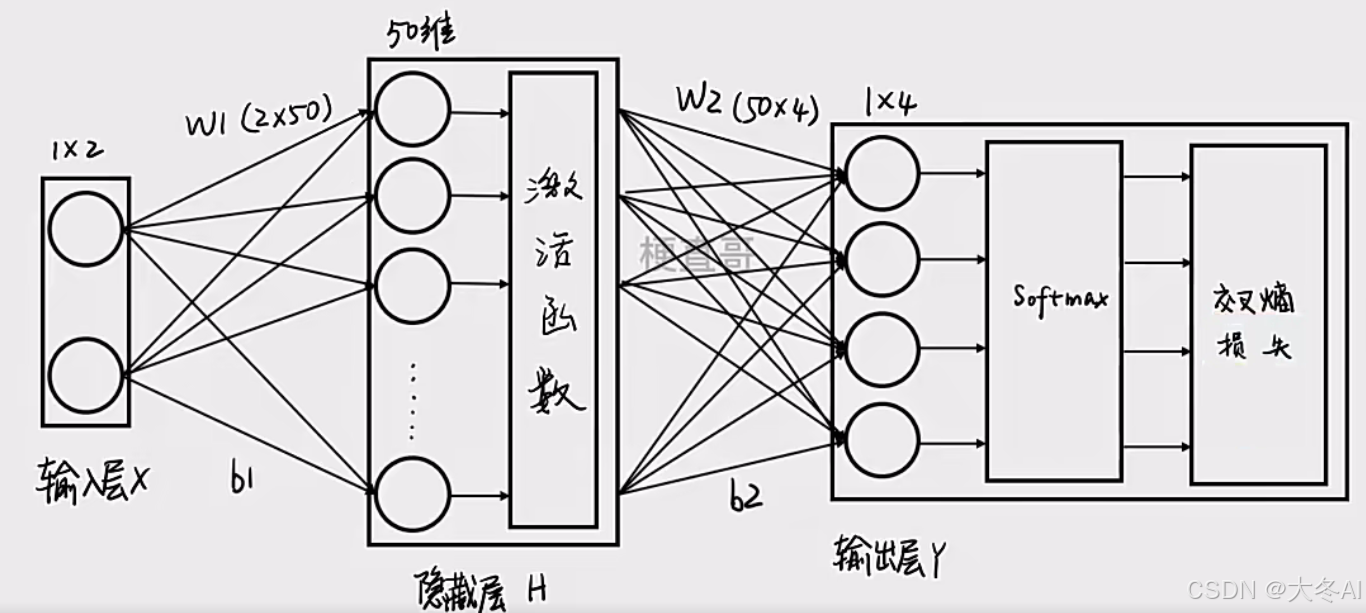
不同网路模型区别体现在:
网络模型结构、损失函数、动态求解损失函数过程、对问题(过拟合等)的解决方式
前向传播和反向传播
损失函数
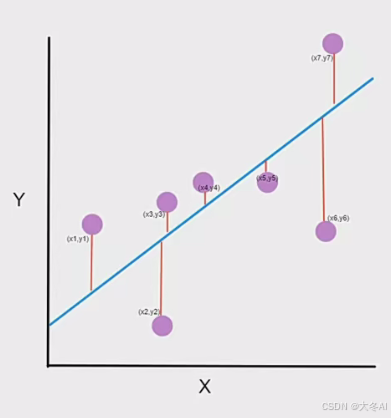
均方误差
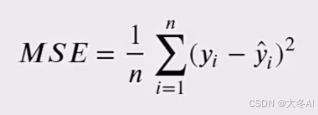
前向传播(本质传递数据和信息):
不断往前传计算损失
深度前馈网络
前馈神经网络
反向传播(本质传递误差、梯度/偏导数):
通过训练参数(w和b)使损失函数的值越来越小
损失倒查分解(偏导数的链式法则)
计算每层参数梯度
目的是找到这些参数的偏导数,然后以此为依据更新模型参数。
多层感知机代码实现
举初级阶段便于理解的神经网络代码实现的例子。
加载数据
先加载数据
由于直接全部拿去训练内存吃不消,所以批量进行训练,训练集需要设置shuffle为true,消除顺序影响,提升泛化能力。


网络结构
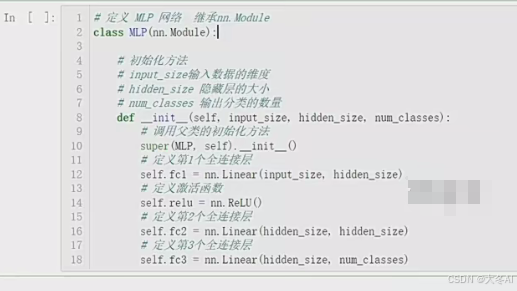


损失函数
根据分类问题或是回归问题确定
这里是分类问题,所以用交叉熵损失函数

优化器
优化器Adam

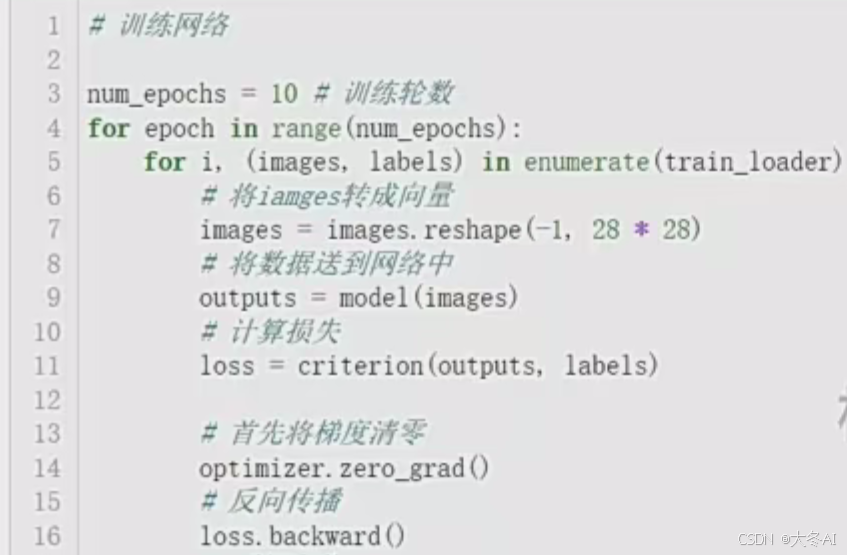
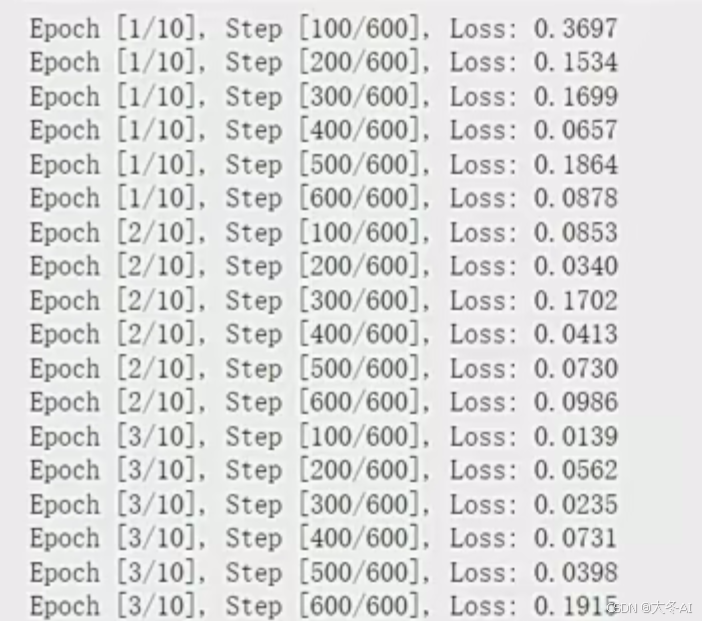
训练
在图片任务中,一般采用小批量策略读取数据和训练
外层循环表示训练10次,里面的循环表示从dataloader中循环读取数据,每次读取batchsize大小的批数据

测试



保存

回归问题
一元线性回归
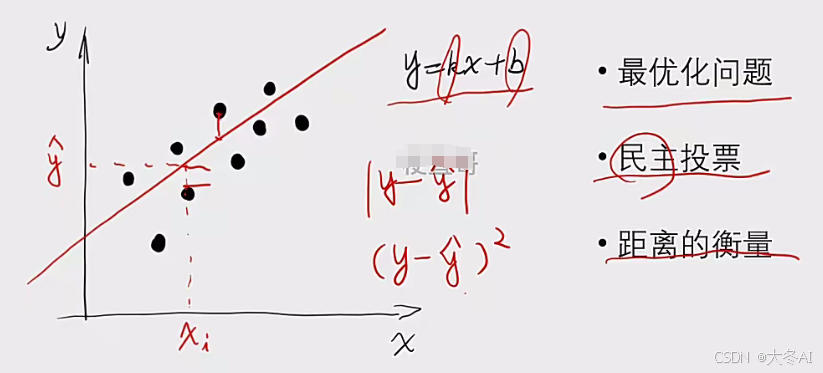
用于对数据进行预测
找最优的拟合直线 转化为 最优化问题,反复迭代参数使得目标函数值最小
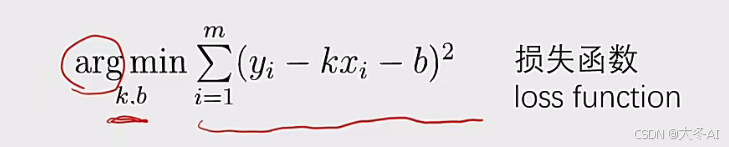
多元线性回归
X 变成矩阵的形式
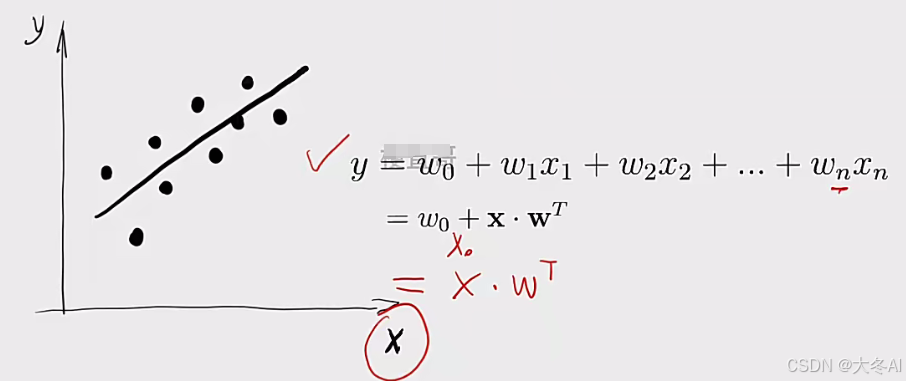

多项式回归
把非线性问题转化为线性问题去求解
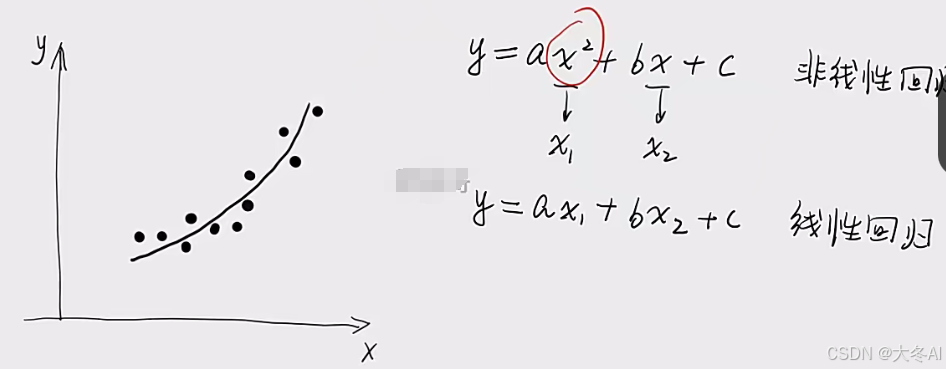
这个X可能是高维的

线性回归代码实现
本质上是一个神经元的神经网络
数据生成
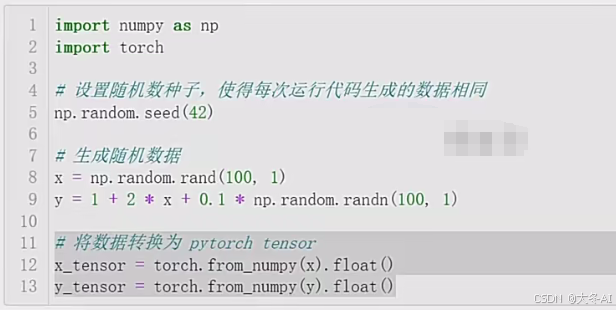
tensor是张量的意思,一种多维数组,在机器学习领域,tensor通常用来表示训练数据、模型参数、输入数据等。
维度可以是一维、二维、n维
pytorch中的基本数据结构,具备良好的计算性能,可以使得GPU加速,大大提高计算效率。
设置超参数
学习率和最大迭代次数

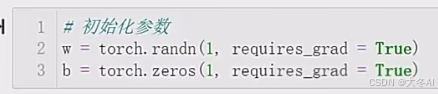
初始化参数
用pytorch的randn函数初始化参数w
用zeros函数初始化参数b
randn函数会生成均值为0标准差为1的随机张量
zeros函数会生成全部元素都为0的张量
grad参数设为true 表示在反向传播时计算梯度
初始化方法:
1、常数 zeors
2、随机数 randn
3、预训练好的参数
具体使用哪种视问题而定


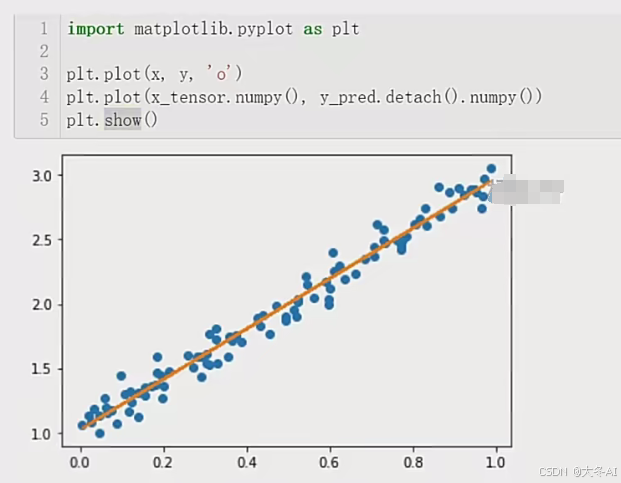
可视化
Pytorch模型实现
设置超参数以及前面的生成数据一样
为什么要清空梯度?
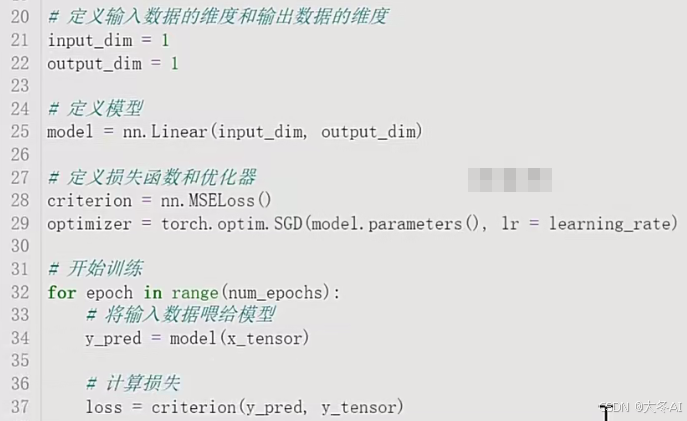

- 避免梯度累加:在神经网络训练过程中,每次迭代都会计算梯度。如果不清空梯度,那么在下一次迭代时,新的梯度会与之前的梯度累加。这会导致梯度值非常大,从而使得模型参数更新过大,影响模型的收敛。
- 确保每次迭代独立:清空梯度可以确保每次迭代都是独立的,每次更新模型参数都是基于当前批次的损失函数计算出的梯度,而不是之前批次的累积梯度。
- 防止梯度爆炸:在某些情况下,如果梯度没有被清空,梯度可能会随着迭代次数的增加而指数级增长,导致所谓的梯度爆炸问题,这会使得模型参数更新变得不稳定。
分类问题
输出是离散的类别标签,而不是连续的值
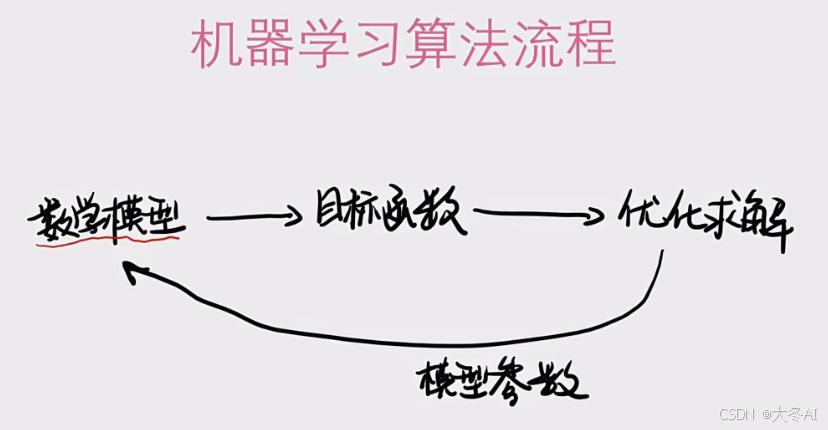
把一个问题用数学模型表示,然后找到目标函数,用优化求解办法获得模型参数
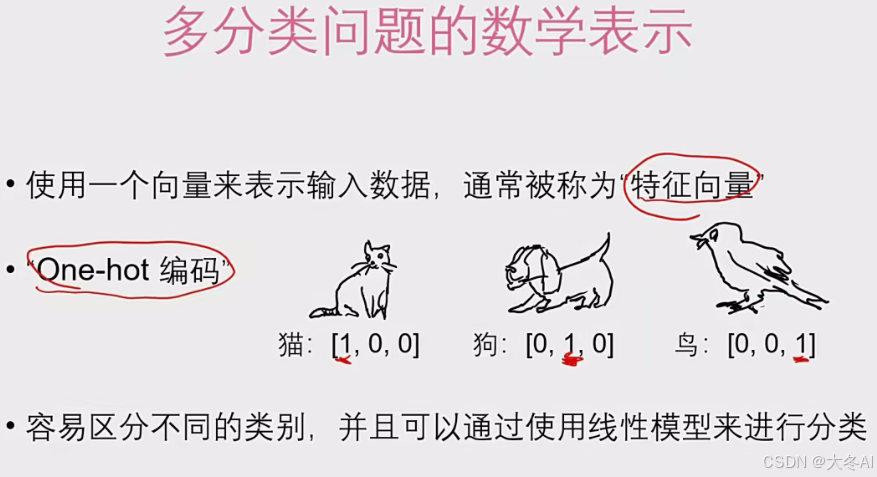
数学表示
softmax可以使所有类别的概率和等于1
可以将输入的特征值转化为概率值,方便决策
神经网络中一般用概率这种表示


损失函数
均方误差适合衡量回归预测结果与真实值的差距,但不能很好衡量分类结果与真实值之前的差距

在二分类中,当y为1时 后面项为0;当y为0时,前面项为0

对数运算的好处:
- 单调性质
- 结合性质 将多个乘转化为和的形式
- 缩放性 可以把一个大数范围进行压缩
m样本数,n类别数, Yij 表示样本i的类别标号是j,p(Xij)表示预测的样本i属于类别j的概率
二分类问题上本质上和对数损失函数等价
多分类表示上略有区别,更适合神经网络模型

通常二分类用对数损失函数,多分类用交叉熵损失函数
多分类问题代码实现
在二分类中 可以用sigmoid函数
在多分类中 通常用softmax函数
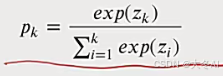
神经网络的最后一层称为softmax层,这一层的输出是概率分布,表示输入数据属于每个类别的概率,为了计算这个概率,我们使用softmax函数
在训练神经网络时,通常使用交叉熵损失函数度量预测值和真实值的差距,对于多分类问题,交叉熵损失函数可以计算为
y是预测值,p是预测值
通过最小化交叉熵损失函数,可以训练模型参数。训练完之后,可以使用他进行多分类,为了做出预测,需要将输入数据输入到神经网络中,并根据输出的概率分布决定它属于哪个类别
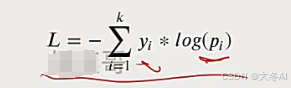
使用softmax函数和交叉熵损失函数是一种多分类的常见方法。
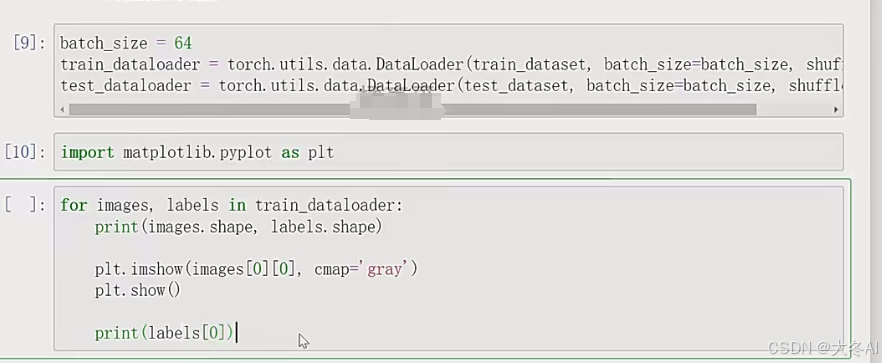
加载MINIST数据集
可以使用torchvision中的数据加载器轻松访问这个数据集

数据加载器
pytorch中加载和预处理数据的工具
可以将数据分成若干批,每次送入一个批次的数据到神经网络中,可以减少内存的使用,使得训练更快
cmap显示灰度图
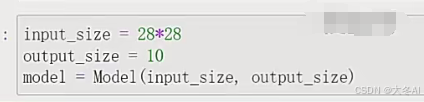
构建网络
定义模型
定义一个线性层
实例化模型

损失函数和优化器

模型评估
model.eval 设置模型为评估模式不会更新权重
torch.no_gard 上下文管理器 适用于不需要求梯度的情况
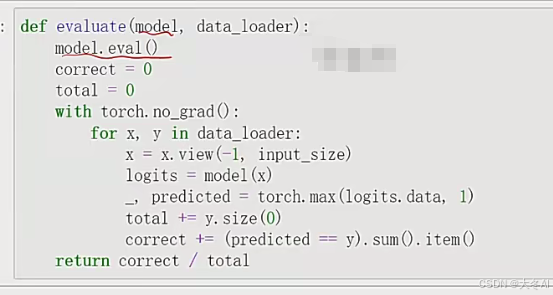
x.view(-1,input_size) -1 是pytorch中特殊符号表示这个数据维度由数据其他维度决定
实际上是将数据拉伸成一个二维矩阵,每一行对应一个样本,每一列对应特征
使输入数据的形状满足模型的要求
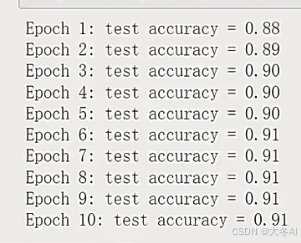
模型训练

常见问题及对策
训练常见问题
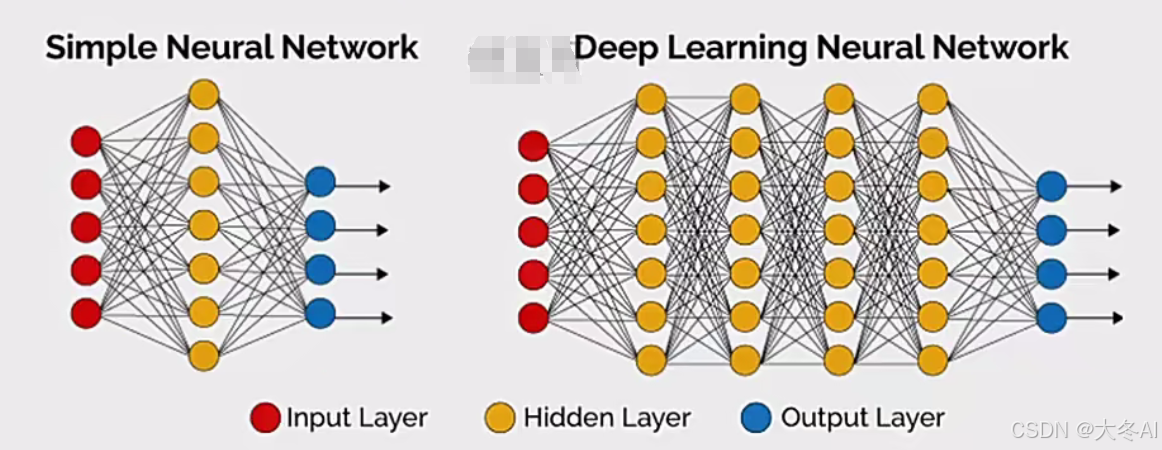
模型架构设计
网络结构、节点数量、网络层数、不同类型的层、层间链接关系等
万能近似定理
一个具有足够多的隐藏节点的多层前馈神经网络,可以逼近任意连续的函数。
必须包含一种 有挤压性质的激活函数(例如sigmoid函数),让他能够进行非线性空间变换
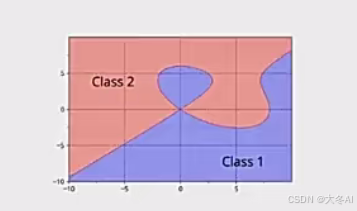
宽度 or 深度
增加深度更有助提高泛化能力
实践证明,在宽度不变的情况下,增加深度,每一层更有助于捕获新的特征,更有助于提高泛化能力
过拟合问题
Overfitting;模型在训练数据上表现良好,在测试数据上不佳
泛化能力:训练后的模型应用到新的、未知的数据上的能力
产生原因:通常是由模型复杂度过高导致的
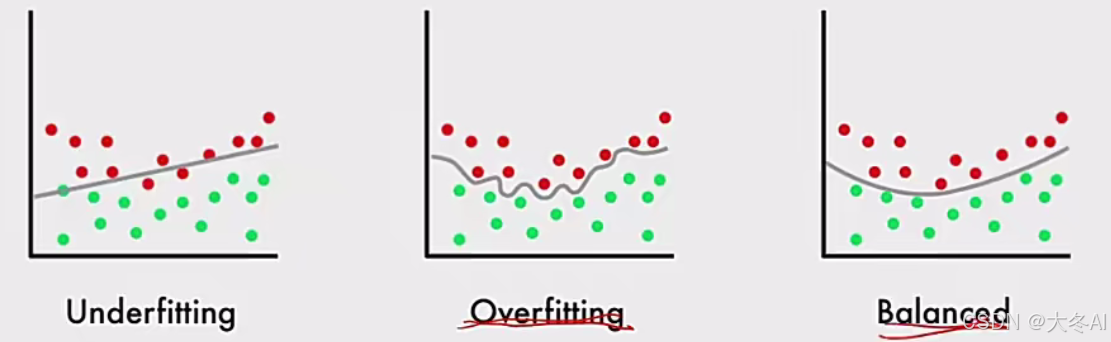
欠拟合问题
Underfitting:学习能力不足,无法学习到数据集中的“一般规律
产生原因:模型学习能力较弱,而数据复杂度较高的情况
解决办法:增加模型层数或者神经元数量或者更复杂的网络模型结构
模型复杂度越高,其表征能力越强
实际中,我们想要泛化误差尽可能小,着重解决过拟合问题
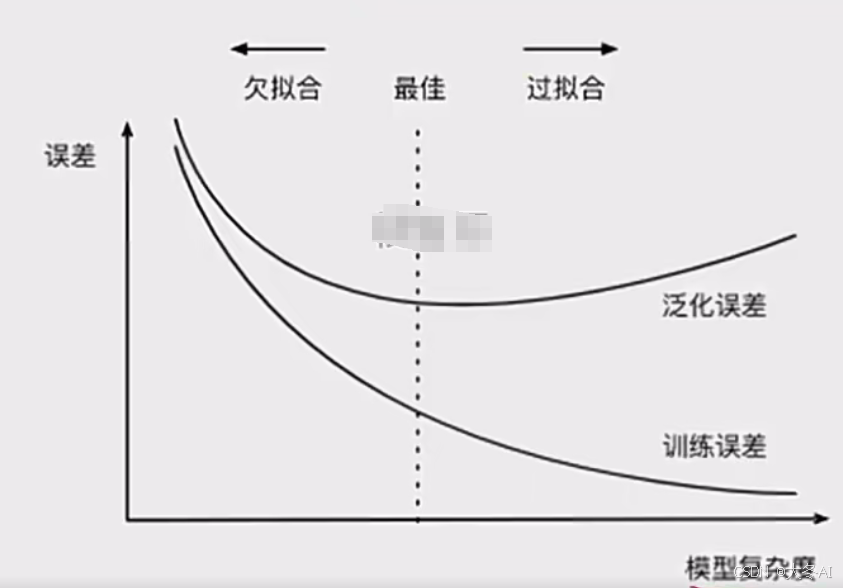
过拟合欠拟合应对策略
本质原因:数据和模型匹配问题
- 数据复杂度
- 模型复杂度
- 训练策略
数据集大小选择
数据角度
数据集较小,很容易出现过拟合
数据集过大可能导致训练效率降低
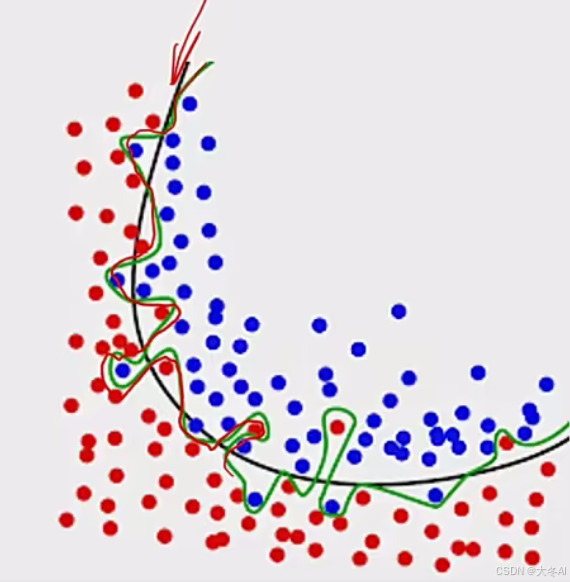
数据增强
数据角度
对训练数据进行变换,圳增加数据数量和多样性
有效解决过拟合问题,提高模型在新数据上的泛化能力
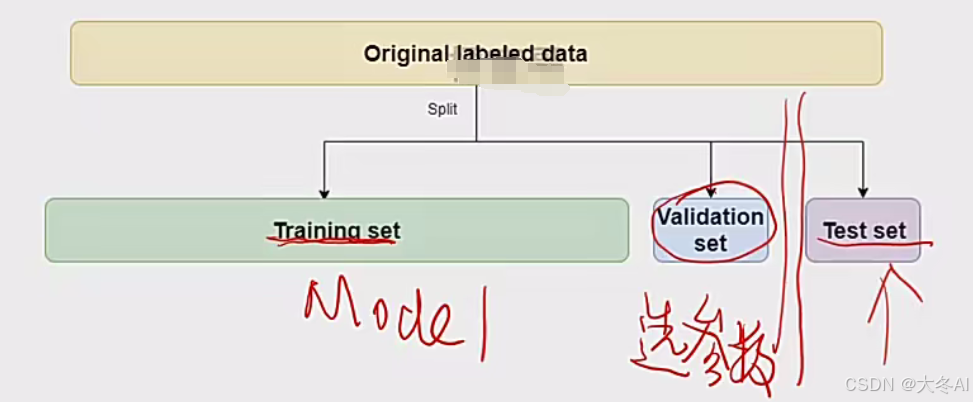
使用验证集
数据角度
验证集(validation set) : 训练中评估模型性能,调整超参数
在训练中就可以对模型进行评估
模型选择
奥卡姆剃刀法则:选择简单合适的模型解决复杂的问题
deeper is better
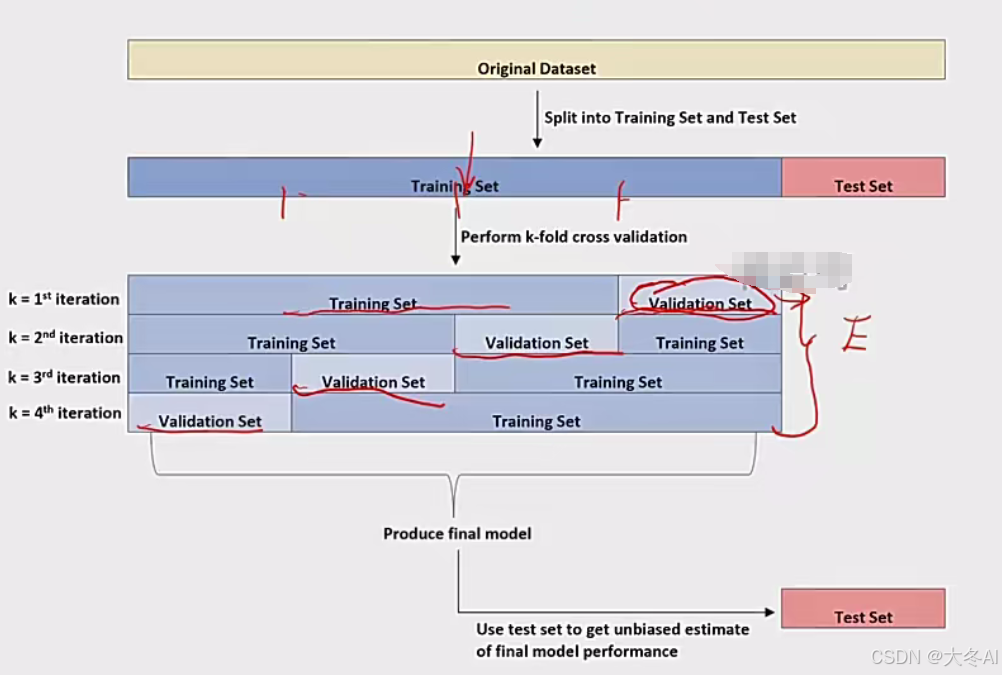
K折交叉验证
训练策略角度
1.将训练数据划分为K份
2.对于每份数据作为验证集,剩余的 K-1 份数据作为训练集,进行训练和验证。
3.计算 K 次验证的平均值。
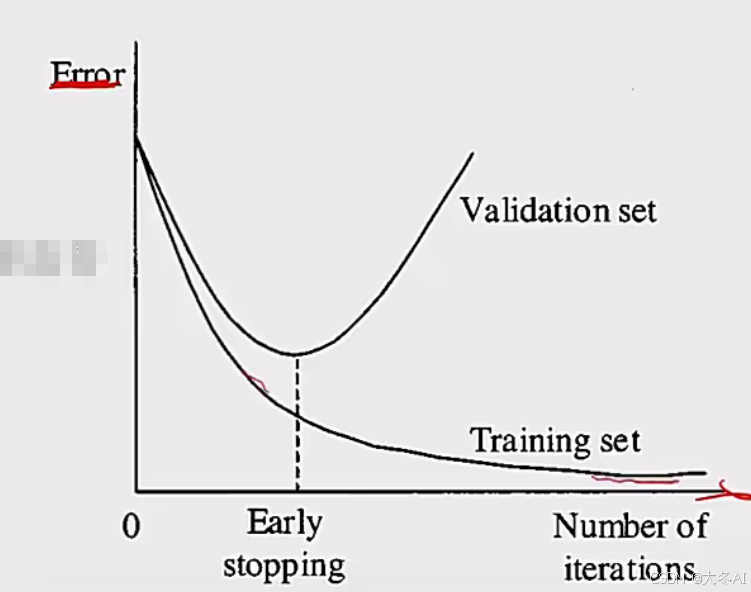
提前终止
训练策略角度
Early stopping:模型对训练数据集迭代收敛之前停止迭代来防止过拟合
如果在验证集上发现测试误差上升,则停止训练
过拟合欠拟合代码示例
数据生成
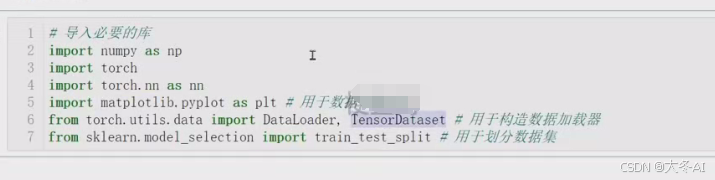

数据划分
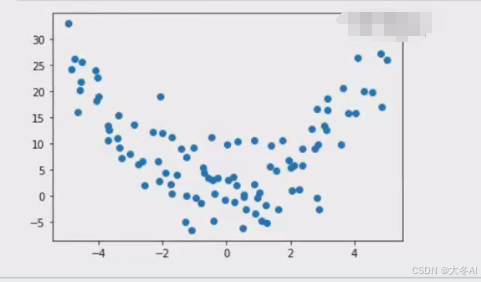
DataLoader 封装数据加载器
shuffle打乱顺序,提高泛化能力

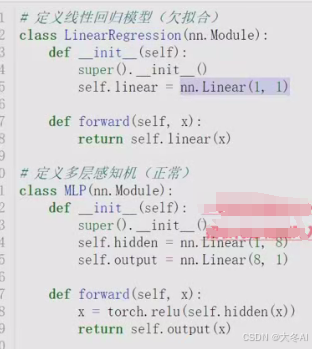
模型定义
nn.Linear(a,b) 分别是输入输出维度

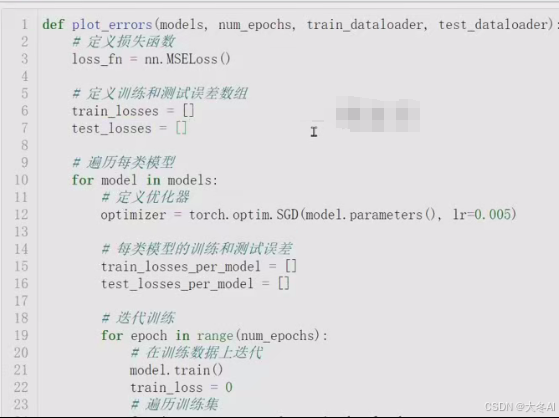
辅助函数
注意测试模型的时候 不用计算梯度

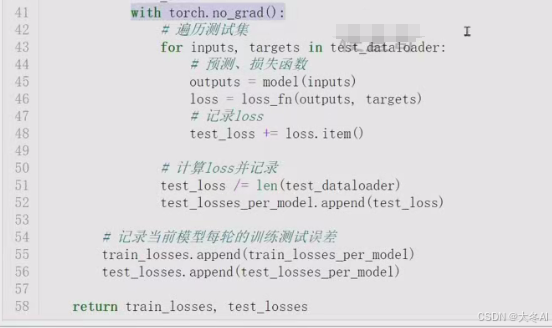

可视化

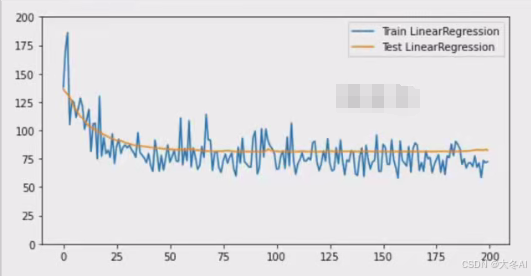
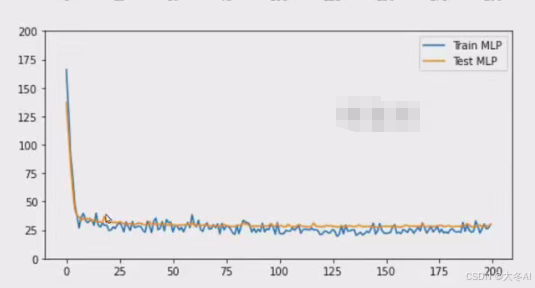
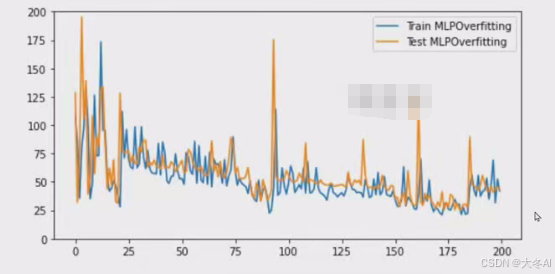
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 神经网络通俗理解学习笔记(1)

发表评论 取消回复