目录
一 线程池执行原理
首先我们先了解一下线程池里面几个参数:

第一个是核心线程数,第二个是线程池最大线程数。(线程池里面的线程分为核心线程和非核心线程,既然核心线程有3个,那么说明还可以创建最多2个非核心线程)
第三个是最大空闲时间,第四个是时间单位为秒,
第五个是阻塞队列(这个很重要),第六个是线程工厂,默认的,
最后一个是拒绝策略。
知道了每一个参数后,我们现在就来解释线程池的工作原理:
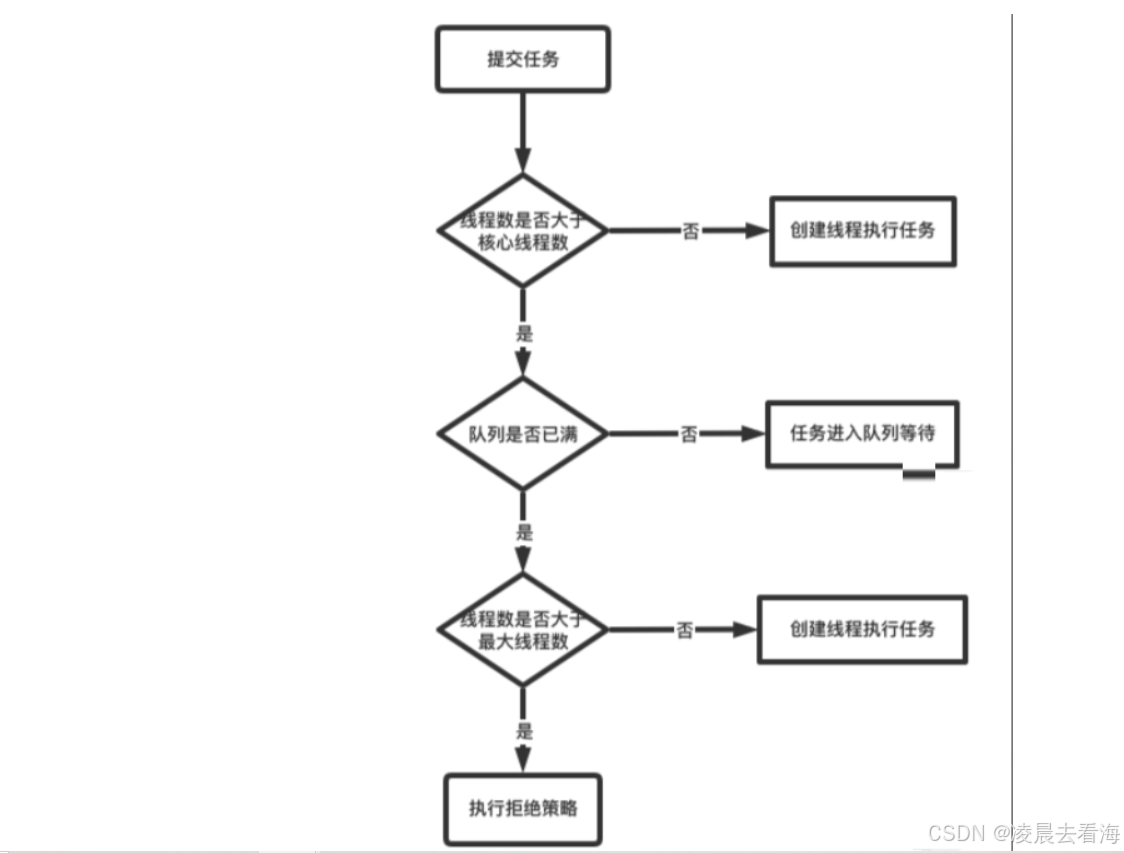
首先,当任务进入线程池后(这里假设线程池是正常运行状态,所以这个就不再做判断),线程池会先判断任务数量是否大于核心线程池的数量,如果不大于,那么就直接创建核心线程来执行任务,但是如果任务数量大于核心线程池数量,比如你只有三个核心线程池,但是你有四个任务,那么前三个任务会创建核心线程池去执行,而多出来的那个任务会放到阻塞队列里面,等核心线程空闲了再去执行阻塞队列里面的任务。
但是如果现在来了五个任务,那么,前三个交给核心线程池,第四个放在阻塞队列里面等待,而我们设置的阻塞队列只有一个,剩下的那个任务就会创建一个非核心线程去执行这个任务。
如果现在来了七个任务,前三个交给核心线程,第四个放在阻塞队列,第五和第六个会创建非核心线程执行,那么第七个呢?现在非核心线程也已经满了。那么这个时候就会有参数里面的拒绝策略去拒绝这个任务,抛异常处理等等。。。
二 线程池改造(一)
以上就是整个线程池执行原理,然后我们发现这里就会有个问题。就是当阻塞队列没满的时候,任务会等待核心线程执行完才会被执行,那如果核心线程执行的任务非常耗时那不是阻塞队列里面的任务就会一直等。
所以我们现在第一个改造,就是如果核心线程池占用完了,新的任务不是直接去阻塞队列等待,而是直接创建非核心线程去执行任务。
怎么改呢?
我们先看看ThreadPoolExecutor类里面的execute方法的代码:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
}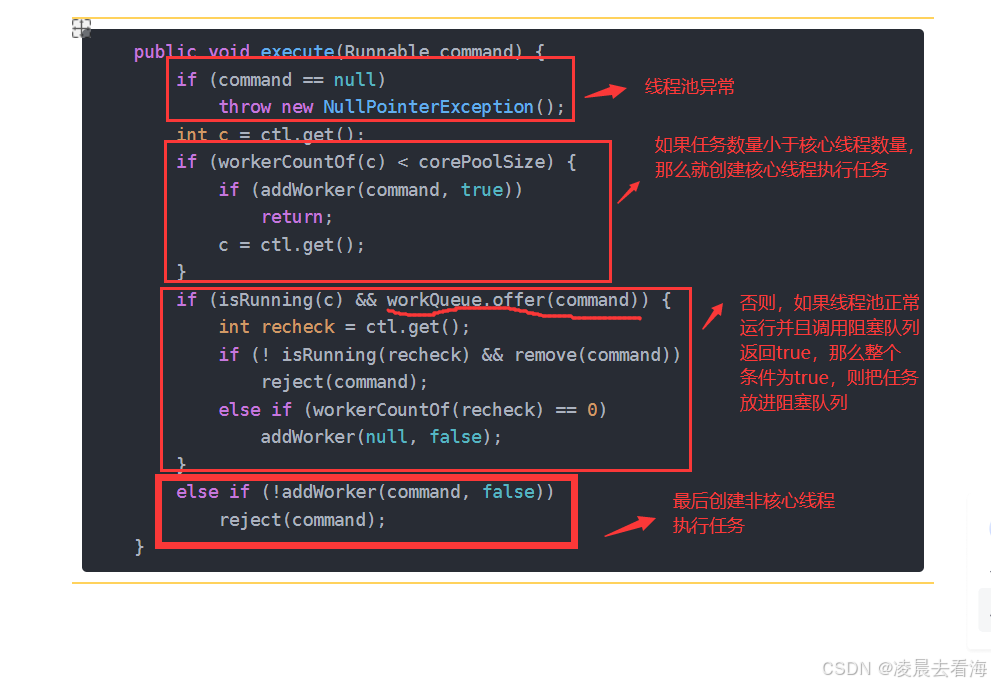
从上面的源码可以看见,在第三步的时候,它的判断如果为true,就会把任务放进阻塞队列,然后第四步才是创建非核心线程执行任务。
我们现在是想要先创建非核心线程直接执行任务,而不是先让任务进入阻塞队列,那么我们可以在第三步的判断条件中,然后的条件为false,那么它就不会进入阻塞队列,而是直接跳到下一步,创建非核心线程去执行任务。
那么我们只能重写workQueue.offer()方法了。
我们继承阻塞队列这个类,然后重写里面的offer方法,直接让他返回false:
package com.feisi.threadPool;
import java.sql.Array;
import java.util.Collection;
import java.util.concurrent.ArrayBlockingQueue;
public class TaskQueue<R extends Runnable> extends ArrayBlockingQueue<Runnable> {
public TaskQueue(int capacity) {
super(capacity);
}
public TaskQueue(int capacity, boolean fair) {
super(capacity, fair);
}
public TaskQueue(int capacity, boolean fair, Collection<? extends Runnable> c) {
super(capacity, fair, c);
}
@Override
public boolean offer(Runnable runnable) {
// 重写方法,直接返回false
return false ;
}
}
然后我们把线程池的阻塞队列换成我们自己的:

看运行结果:
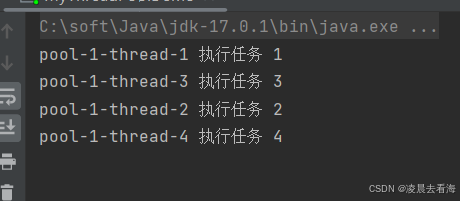
原先四个任务,前面三个有三个核心线程执行,后面一个在阻塞队列等待,直到核心线程执行完再去执行它,但是现在不一样了,任务4直接由非核心线程4去执行了。
三 线程池改造(二)
上面这个问题是解决了,我们加快了任务的执行速度,无需去等待核心线程执行完毕,就可以直接创建非核心线程去执行任务。
但是现在有一个问题,就是你直接返回false,相当于来一个任务,只要没超出最大线程数限制,你就直接给他创建一个非核心线程去执行,这样线程数多了容易影响性能,比如你来了四个任务,前三个由核心线程去执行,而第四个你就直接创建非核心线程了,那如果前面的核心线程已经执行完了呢?那是不是可以不需要创建非核心线程了,直接由空闲的核心线程去执行就行了,这样就可以大大减少线程的创建了。
所以我们应该再做一个判断,如果任务总数小于核心线程数,那么就由核心线程执行,如果大于核心线程数,那么就创建新的非核心线程去执行。
package com.feisi.threadPool;
import java.sql.Array;
import java.util.Collection;
import java.util.concurrent.ArrayBlockingQueue;
public class MyTaskQueue<R extends Runnable> extends ArrayBlockingQueue<Runnable> {
private EagerThreadPoolExecutor threadPoolExecutor;
public MyTaskQueue(int capacity) {
super(capacity);
}
public MyTaskQueue(int capacity, boolean fair) {
super(capacity, fair);
}
public MyTaskQueue(int capacity, boolean fair, Collection<? extends Runnable> c) {
super(capacity, fair, c);
}
public void setThreadPoolExecutor(EagerThreadPoolExecutor threadPoolExecutor) {
this.threadPoolExecutor = threadPoolExecutor;
}
@Override
public boolean offer(Runnable runnable) {
//1.获取当前线程池的线程数量
int currentPoolSize = threadPoolExecutor.getPoolSize();
//如果当前任务数量小于核心线程数, 让核心线程数来执行
// 有核心线程在空闲
if(threadPoolExecutor.getSubmittedTaskCount() < threadPoolExecutor.getCorePoolSize()){
// System.out.println("111");
//让核心线程数来执行
return super.offer(runnable);
}
//如果当前线程池线程数量 < 最大线程池而且说明核心线程没有空闲那么就创建非核心线程执行。
if(currentPoolSize < threadPoolExecutor.getMaximumPoolSize() ){
return false;
}
//把任务存储到队列中
return super.offer(runnable);
}
}
还需要重写ThreadPollExector类的executor方法,来记录当前线程中需要处理的任务数:
package com.feisi.threadPool;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
/**
* 快速消费线程池
*/
public class EagerThreadPoolExecutor extends ThreadPoolExecutor {
public EagerThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue);
}
public EagerThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory);
}
public EagerThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, handler);
}
public EagerThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
private AtomicInteger submittedTaskCount = new AtomicInteger(0);
//提供公开获取submittedTaskCount值
public int getSubmittedTaskCount(){
return submittedTaskCount.get();
}
@Override
public void execute(Runnable command) {
// System.out.println("进来了..");
//任务数 + 1
submittedTaskCount.incrementAndGet();
try{
Thread.sleep(500);
super.execute(command);
}catch (Exception e){ //拒绝
//任务数-1
submittedTaskCount.decrementAndGet();
}
}
//表示任务执行完成的回调方法
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
//任务数-1
submittedTaskCount.decrementAndGet();
}
}
运行结果:
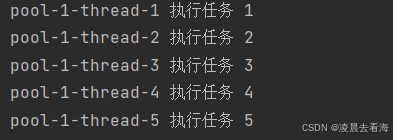
可以看见,后面的线程也是由核心线程执行的,而没有去创建非核心线程,因为核心线程是空闲的,就不需要再去创建非核心线程了。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 线程池原理及改造

发表评论 取消回复