1.引言
在高性能计算和大规模并行任务处理中,GPU已经成为不可或缺的加速器。为了充分发挥GPU的计算能力,通过合理分配CPU核与GPU的绑定来优化CPU和GPU的关系至关重要。我们将探讨socket和NUMA(非统一内存访问)的概念,并讨论如何基于这些硬件架构实现CPU和GPU核心绑定,以保证最佳的系统性能。
2.Socket概念
2.1什么是SocKet
Socket 通常指的是主板上用于安装物理 CPU 的插槽。每个 Socket 对应一个物理 CPU,通常包含多个核心(Core)和一个或多个缓存层次结构(如L1、L2、L3缓存)。在多 Socket 系统中(例如,双路或四路服务器),每个 Socket 上安装的物理 CPU 通过高速互联总线(如 Intel 的 QPI 或 AMD 的 Infinity Fabric)相互连接。
2.2多 Socket系统的特点
在多Socket系统中,各个 Socket 上的CPU可以分别访问自己本地的内存,同时也能够访问其他 Socket 的内存。这种内存访问模式引出了NUMA的概念,旨在优化内存访问的效率。
3.NUMA(非统一内存访问)架构
3.1什么是 NUMA
NUMA 是 Non-Uniform Memory Access 的缩写,即非统一内存访问。与传统的统一内存访问(UMA)不同,在NUMA 架构中,系统内存被划分成多个区域,每个区域与特定的 CPU(Socket)紧密关联。CPU 访问自己 Socket对应的内存(本地内存)速度更快,而访问其他 Socket 对应的内存(远程内存)则会产生较高的延迟。
3.2NUMA 节点和内存访问延迟
在 NUMA 系统中,每个 Socket 及其直接连接的内存组成一个 NUMA 节点。同一 NUMA 节点内的内存访问速度较快,而跨节点的内存访问会因为需要经过额外的总线传输而导致更高的延迟。因此,优化内存和 CPU 的亲和性,使任务尽量在对应的 NUMA 节点内运行,是性能优化的重要一环。
4.CPU和GPU物理关系
4.1GPU的硬件架构
GPU 通常通过 PCIe(Peripheral Component Interconnect Express)总线与 CPU 通信。在多Socket系统中,GPU通常只连接到某一个 Socket(及其对应的NUMA节点)上,而不跨 Socket 连接。这意味着在实际运行时,GPU 与连接的那个 Socket 上的 CPU 核心和内存具有更高的带宽和更低的延迟。
4.2CPU 和 GPU 亲和性
CPU 和 GPU 之间的通信主要依赖于数据的传输。数据从 CPU 传递到 GPU,再从 GPU 传递回 CPU,过程中涉及到的内存访问操作对性能影响巨大。如果 GPU 绑定的 CPU 核心位于与其相同的 NUMA 节点上,那么数据传输的延迟将显著降低。因此,绑定 CPU 核心与 GPU 的关系是提升性能的关键
5.基于亲和性的GPU与CPU核心绑定策略
在使用Docker容器化部署应用时,实现 GPU 与 CPU 的亲和性绑定是提高容器内计算任务性能的关键。通过 Docker 的CPU 和 GPU 资源控制功能,可以精确地控制容器使用的 CPU 核,并将这些 CPU 核与 GPU 进行绑定。
5.1容器中的CPU和GPU资源分配
Docker容器允许精确控制分配给容器的 CPU 和 GPU 资源。通过指定容器使用的 CPU 核和 GPU 设备,可以实现容器内任务的亲和性绑定,优化计算性能。
- Docker CPU 设置
在Docker中,可以通过以下参数控制容器使用的CPU资源:
--cpuset-cpus: 指定容器可以使用的物理CPU核。例如,--cpuset-cpus="0-3"表示容器只能使用 CPU 0到3的核。
--cpu-shares: 控制容器的CPU使用权重,但不会限制具体使用的核。
--cpus: 限制容器可以使用的CPU核的总量(以虚拟核为单位)。
- Docker GPU 设置
GPU设备绑定可以使用以下Docker参数来实现:
--gpus: 指定容器可以访问的 GPU。例如,--gpus ' "device=0"表示将 GPU 0分配给该容器。
5.2如何在Docker中实现GPU和CPU核心绑定
要在 Docker 容器中实现 GPU 与 CPU 核的绑定,可以结合使用上述 CPU 和 GPU 设置。下面是一个具体的示例,说明如何在启动 Docker 容器时绑定特定的 CPU 核和 GPU :
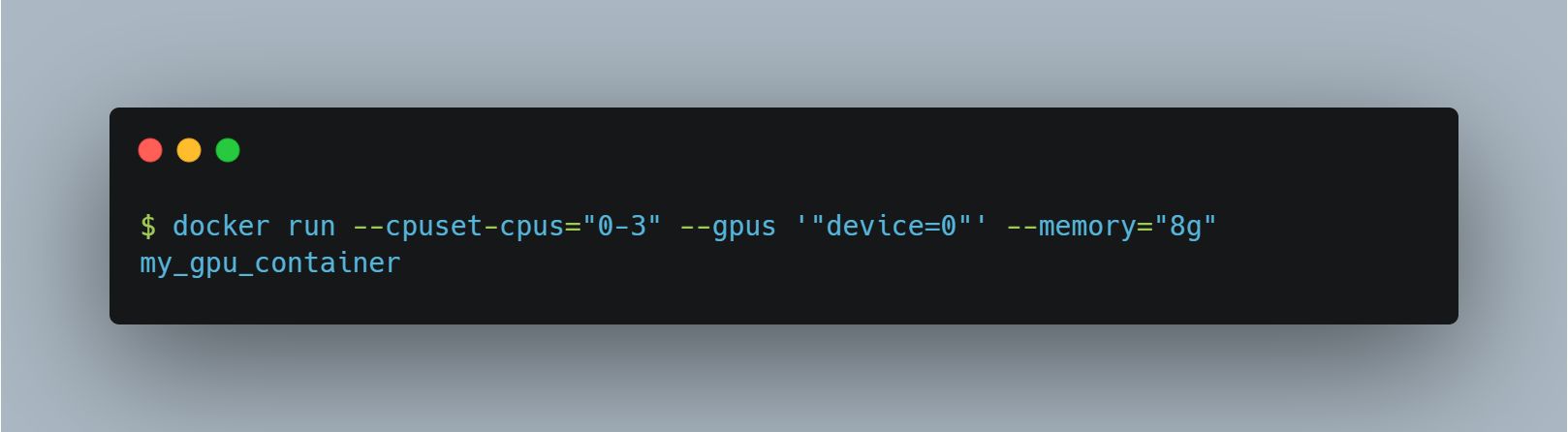
在这个命令中:
--cpuset-cpus="0-3":将容器绑定到CPU 0到3的核上,这些核应该与GPU 0在同一个NUMA节点上。
--gpus '"device=0"':将GPU 0分配给容器。
--memory="8g":限制容器使用的内存为8GB,可以确保内存分配也与CPU/GPU亲和。
5.3如何实现最优绑核
为了确保在容器中实现GPU与CPU核绑定的最佳性能,首先需要先确定一下机器上的物理拓扑结构,可以在有 GPU 设备的机器中输入 nvidia-smi topo -m 进行查看:
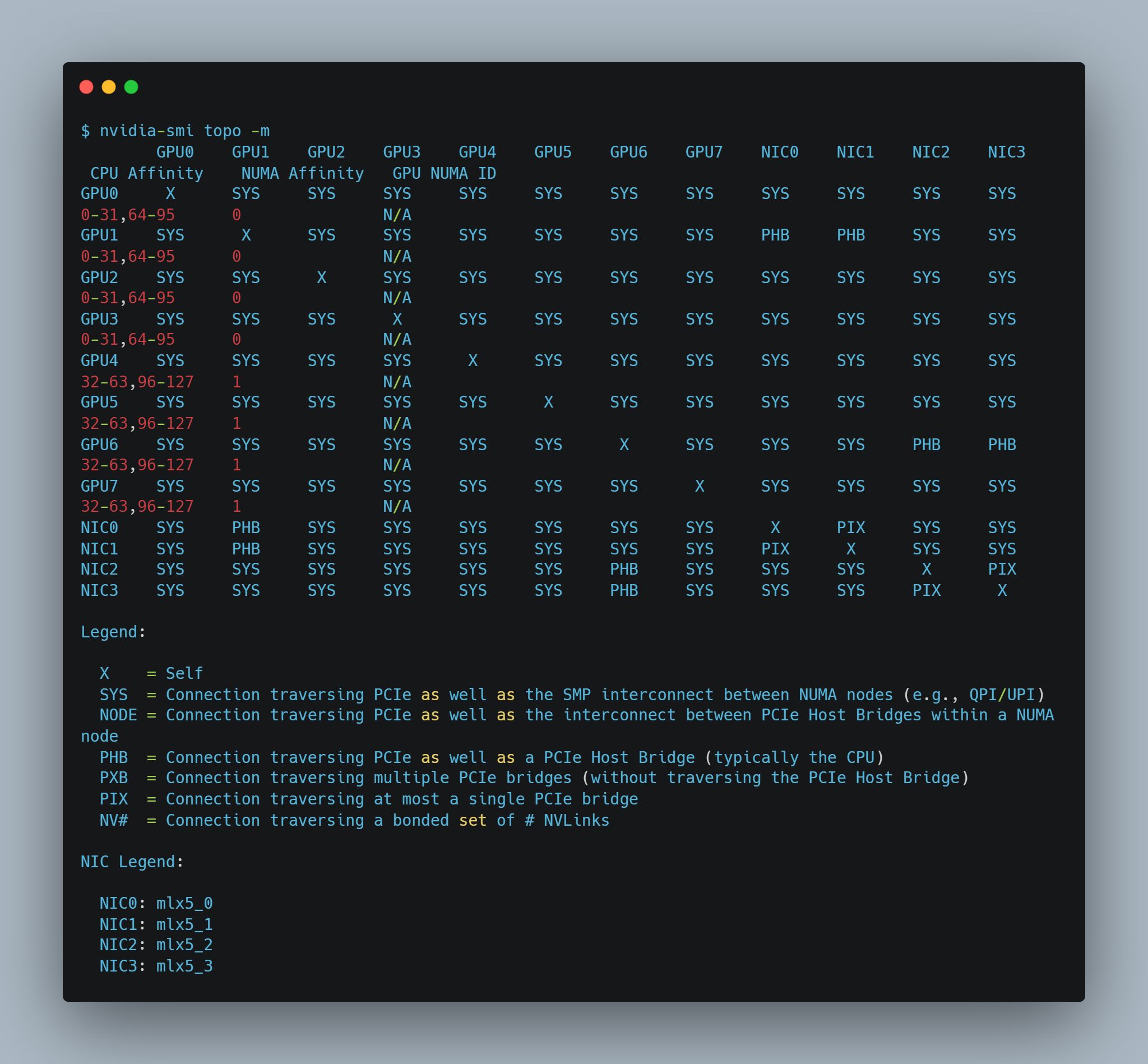
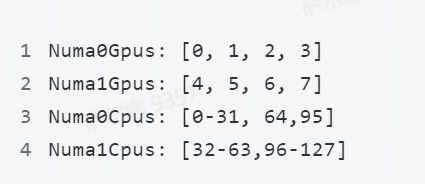
从上图可以得到以下信息,这台机器有两个 NUMA, NUMA 0 上有 4 个 GPU, 64 个 CPU,将以上数据整理一下, 得出以下信息:
最基础的绑核就是使用每个 GPU 时选择具有亲和性的 CPU 核心使用,当出现多卡需求时则需要根据 NUMA 进行筛选,当需求为 1 - 4 卡时还需要知道机器上已经使用的资源,请求的资源,才可以判定是否满足最佳亲和性绑定和同一 NUMA 下通信,以下是一个伪代码表示:
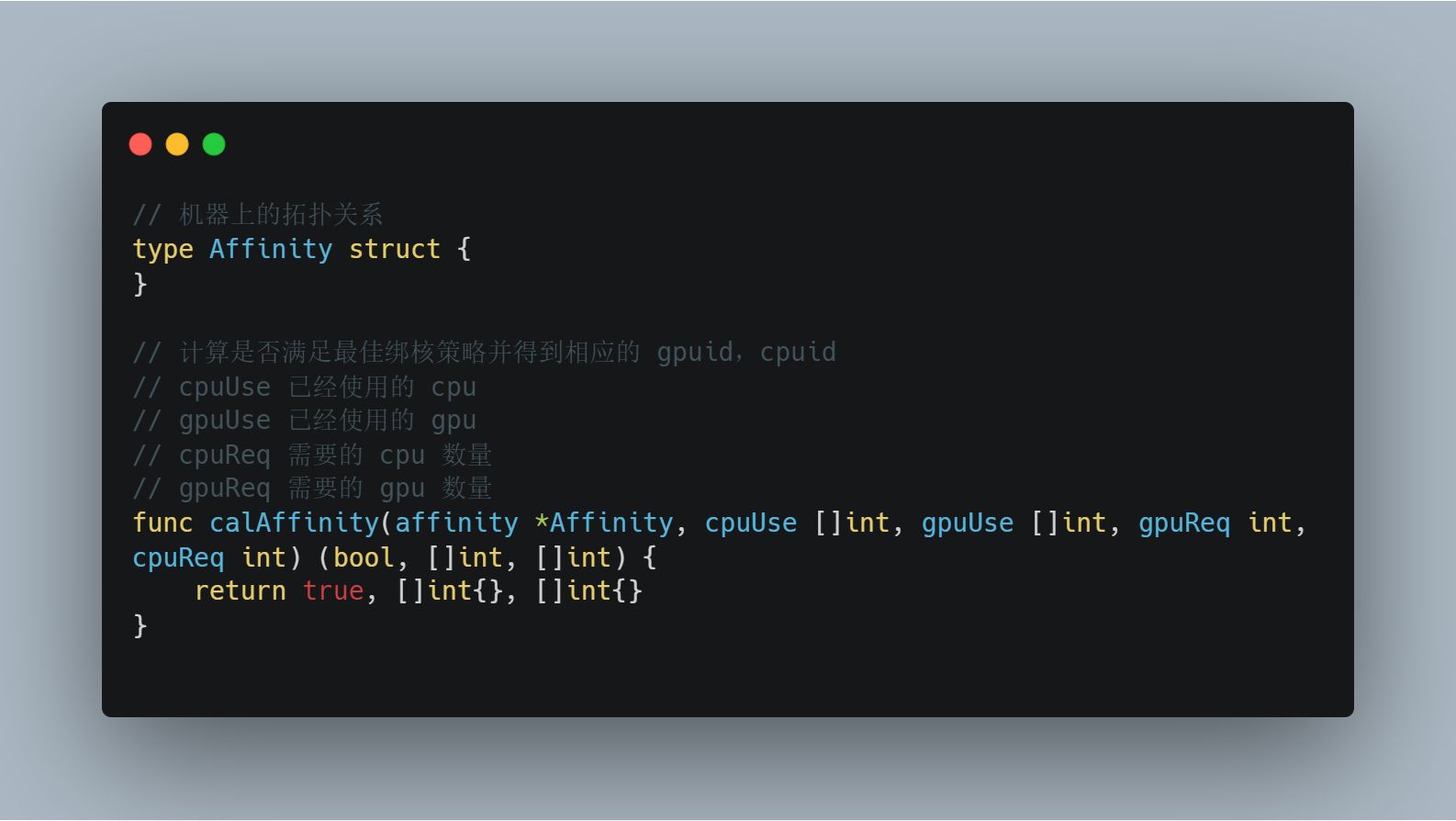
基于此方法可以判断节点是否满足最佳绑核需求,当有若干个节点存在时则可以根据此方法对节点进行相应的评级选择最合适的节点。
派欧算力云基于 Docker 自研了面向下一代 AI 计算的容器引擎,通过动态调节算法,实时感知底层硬件的使用情况,并进行了全链路的优化。用户无需关注 NUMA 的技术细节,便可以无感享受到最强大的计算性能。
用户也可以在控制台中进行 NUMA 更高级的设置。
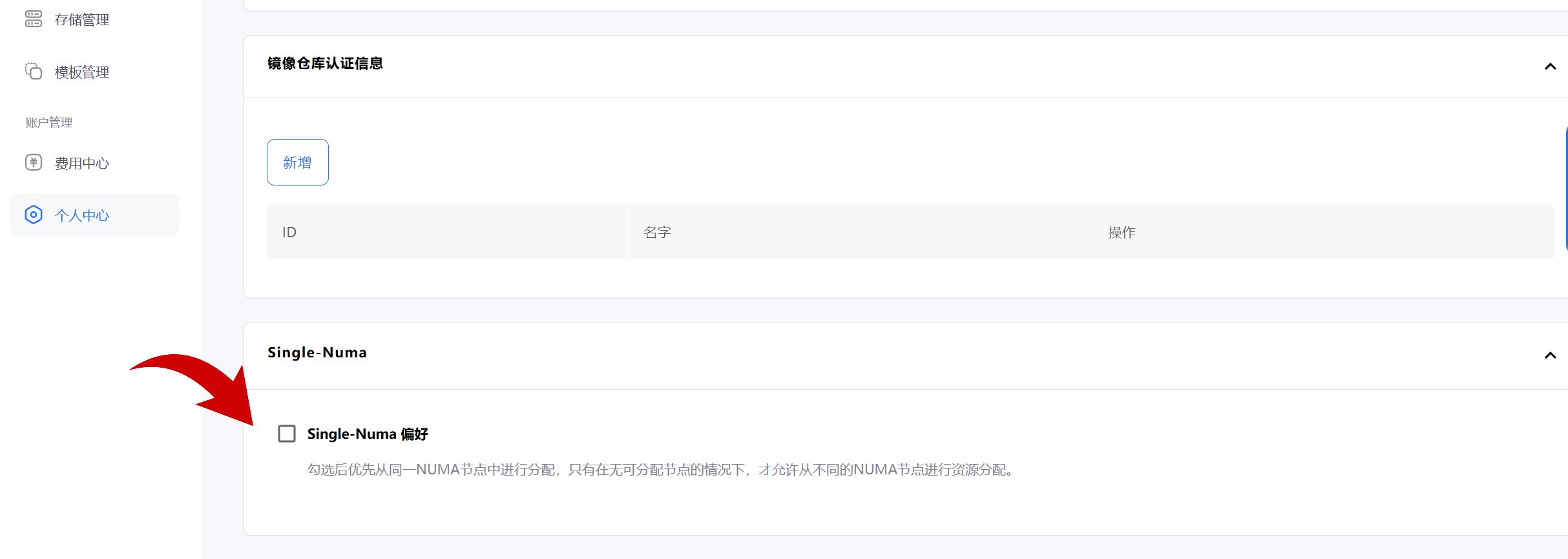
如果你对如何实施 GPU 容器绑核策略感兴趣,可以访问我们的网站,欢迎大家在评论区分享你们的经验和想法,让我们一起探索更多的技术创新!
派欧算力云 秉承提供高性价比算力服务的宗旨,推出了 GPU 弹性算力产品,通过提供多样化的 GPU 、优化的性能以及充足的算力资源,为新一代生成式人工智能、云端渲染、机器学习和加速计算等领域提供高性价比的算力支持。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于亲和性的 GPU 容器绑核策略 Copy

发表评论 取消回复