1,本文介绍
SCConv(空间和通道重构卷积)是一种高效的卷积模块,旨在优化卷积神经网络(CNN)的性能,通过减少空间和通道的冗余来降低计算资源的消耗。该模块由两个核心组件构成:
-
空间重构单元(SRU):通过分离和重构的方式,SRU 有效减少空间冗余。
-
通道重构单元(CRU):利用分割-变换-融合策略,CRU 旨在降低通道冗余
关于SCConv的详细介绍可以看论文:SCConv: Spatial and Channel Reconstruction Convolution for Feature Redundancy (thecvf.com)
本文将讲解如何将SCConv融合进yolov8
话不多说,上代码!
2, 将SCConv融合进yolov8
2.1 步骤一
找到如下的目录'ultralytics/nn/modules',然后在这个目录下创建一个SCConv.py文件,文件名字可以根据你自己的习惯起,然后将SCConv的核心代码复制进去.
import torch
import torch.nn.functional as F
import torch.nn as nn
from .conv import Conv
__all__ = ['C2f_SCConv']
class GroupBatchnorm2d(nn.Module):
def __init__(self, c_num: int,
group_num: int = 16,
eps: float = 1e-10
):
super(GroupBatchnorm2d, self).__init__()
assert c_num >= group_num
self.group_num = group_num
self.weight = nn.Parameter(torch.randn(c_num, 1, 1))
self.bias = nn.Parameter(torch.zeros(c_num, 1, 1))
self.eps = eps
def forward(self, x):
N, C, H, W = x.size()
x = x.view(N, self.group_num, -1)
mean = x.mean(dim=2, keepdim=True)
std = x.std(dim=2, keepdim=True)
x = (x - mean) / (std + self.eps)
x = x.view(N, C, H, W)
return x * self.weight + self.bias
class SRU(nn.Module):
def __init__(self,
oup_channels: int,
group_num: int = 16,
gate_treshold: float = 0.5,
torch_gn: bool = True
):
super().__init__()
self.gn = nn.GroupNorm(num_channels=oup_channels, num_groups=group_num) if torch_gn else GroupBatchnorm2d(
c_num=oup_channels, group_num=group_num)
self.gate_treshold = gate_treshold
self.sigomid = nn.Sigmoid()
def forward(self, x):
gn_x = self.gn(x)
w_gamma = self.gn.weight / sum(self.gn.weight)
w_gamma = w_gamma.view(1, -1, 1, 1)
reweigts = self.sigomid(gn_x * w_gamma)
# Gate
w1 = torch.where(reweigts > self.gate_treshold, torch.ones_like(reweigts), reweigts) # 大于门限值的设为1,否则保留原值
w2 = torch.where(reweigts > self.gate_treshold, torch.zeros_like(reweigts), reweigts) # 大于门限值的设为0,否则保留原值
x_1 = w1 * x
x_2 = w2 * x
y = self.reconstruct(x_1, x_2)
return y
def reconstruct(self, x_1, x_2):
x_11, x_12 = torch.split(x_1, x_1.size(1) // 2, dim=1)
x_21, x_22 = torch.split(x_2, x_2.size(1) // 2, dim=1)
return torch.cat([x_11 + x_22, x_12 + x_21], dim=1)
class CRU(nn.Module):
'''
alpha: 0<alpha<1
'''
def __init__(self,
op_channel: int,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.up_channel = up_channel = int(alpha * op_channel)
self.low_channel = low_channel = op_channel - up_channel
self.squeeze1 = nn.Conv2d(up_channel, up_channel // squeeze_radio, kernel_size=1, bias=False)
self.squeeze2 = nn.Conv2d(low_channel, low_channel // squeeze_radio, kernel_size=1, bias=False)
# up
self.GWC = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=group_kernel_size, stride=1,
padding=group_kernel_size // 2, groups=group_size)
self.PWC1 = nn.Conv2d(up_channel // squeeze_radio, op_channel, kernel_size=1, bias=False)
# low
self.PWC2 = nn.Conv2d(low_channel // squeeze_radio, op_channel - low_channel // squeeze_radio, kernel_size=1,
bias=False)
self.advavg = nn.AdaptiveAvgPool2d(1)
def forward(self, x):
# Split
up, low = torch.split(x, [self.up_channel, self.low_channel], dim=1)
up, low = self.squeeze1(up), self.squeeze2(low)
# Transform
Y1 = self.GWC(up) + self.PWC1(up)
Y2 = torch.cat([self.PWC2(low), low], dim=1)
# Fuse
out = torch.cat([Y1, Y2], dim=1)
out = F.softmax(self.advavg(out), dim=1) * out
out1, out2 = torch.split(out, out.size(1) // 2, dim=1)
return out1 + out2
class ScConv(nn.Module):
def __init__(self,
op_channel: int,
group_num: int = 4,
gate_treshold: float = 0.5,
alpha: float = 1 / 2,
squeeze_radio: int = 2,
group_size: int = 2,
group_kernel_size: int = 3,
):
super().__init__()
self.SRU = SRU(op_channel,
group_num=group_num,
gate_treshold=gate_treshold)
self.CRU = CRU(op_channel,
alpha=alpha,
squeeze_radio=squeeze_radio,
group_size=group_size,
group_kernel_size=group_kernel_size)
def forward(self, x):
x = self.SRU(x)
x = self.CRU(x)
return x
class SCConv_yolov8(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=1, stride=1, g=1, dilation=1):
super().__init__()
self.conv = Conv(in_channels, out_channels, k=1)
self.RFAConv = ScConv(out_channels)
self.bn = nn.BatchNorm2d(out_channels)
self.gelu = nn.GELU()
def forward(self, x):
x = self.conv(x)
x = self.RFAConv(x)
x = self.gelu(self.bn(x))
return x
class Bottleneck_SCConv(nn.Module):
"""Standard bottleneck."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5):
"""Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and
expansion.
"""
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, k[0], 1)
self.cv2 = SCConv_yolov8(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
"""'forward()' applies the YOLO FPN to input data."""
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C2f_SCConv(nn.Module):
"""Faster Implementation of CSP Bottleneck with 2 convolutions."""
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
"""Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups,
expansion.
"""
super().__init__()
self.c = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2)
self.m = nn.ModuleList(Bottleneck_SCConv(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n))
def forward(self, x):
"""Forward pass through C2f layer."""
x = self.cv1(x)
x = x.chunk(2, 1)
y = list(x)
# y = list(self.cv1(x).chunk(2, 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))
def forward_split(self, x):
"""Forward pass using split() instead of chunk()."""
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in self.m)
return self.cv2(torch.cat(y, 1))2.2 步骤二
在task.py导入我们的模块
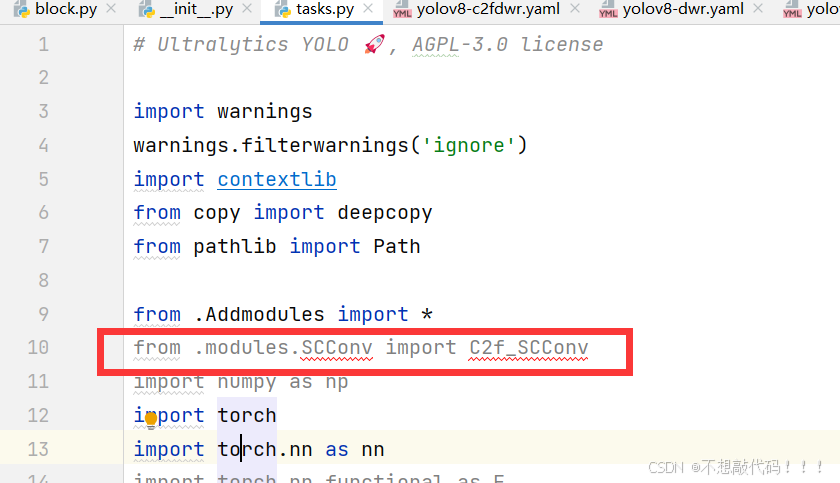
from .modules.SCConv import C2f_SCConv2.3 步骤三
在task.py的parse_model方法里面注册我们的模块
这里需要注意在两个位置进行添加,不要漏了
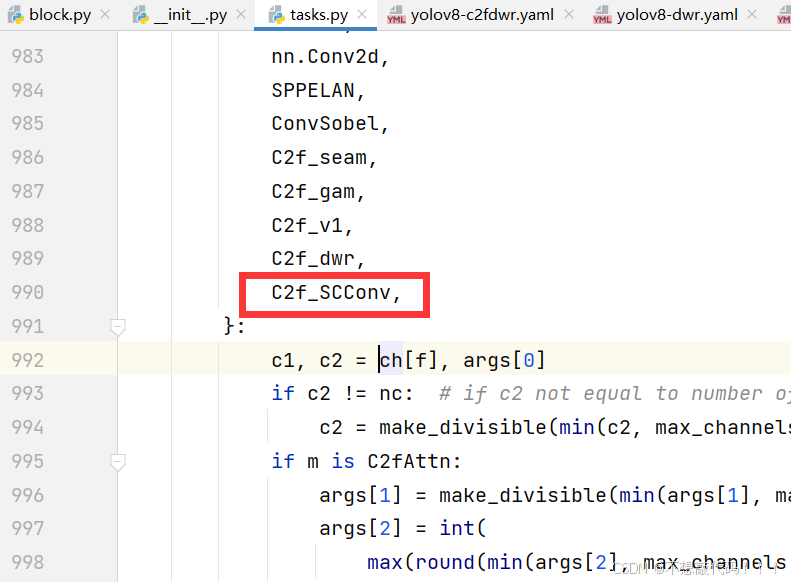
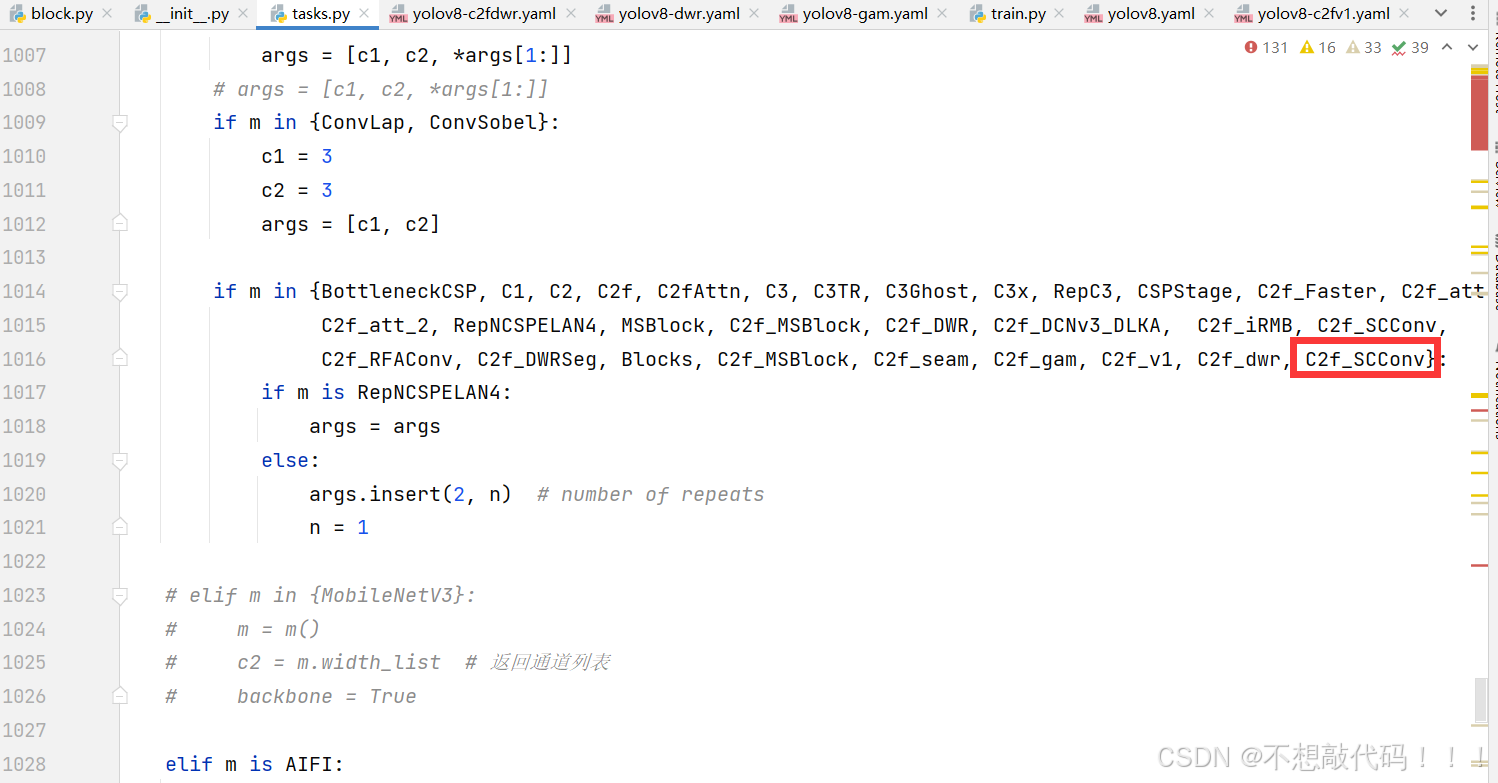
到此注册成功,复制后面的yaml文件直接运行即可
yaml文件
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_SCConv, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_SCConv, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_SCConv, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)# 关于SCConv的使用,可以直接做卷积使用,也可以放在c2f或者bottleneck中做融合
不知不觉已经看完了哦,动动小手留个点赞吧--_--
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 爆改YOLOv8|利用SCConv改进yolov8-即轻量又涨点

发表评论 取消回复