stream简介
Stream: A sequence of elements supporting sequential and parallel aggregate operations
stream为sequential即单线程串行操作,parallelStream支持并行操作,本文只讨论sequential的stream。
stream常用操作
@Data
static class Course {
private Long number;
private LocalDateTime beginTime;
private List<Long> studentIds;
}
public void streamOperations(List<Course> courses) {
// 映射并去重
List<Long> courseNumbers = courses.stream()
.filter(Objects::nonNull)
.map(Course::getNumber)
.distinct()
.collect(Collectors.toList());
// 先按开始时间排序后按number排序
List<Course> sortedCourses = courses.stream()
.sorted(Comparator.comparing(Course::getBeginTime).thenComparing(Course::getNumber))
.collect(Collectors.toList());
// 根据number组成map, 如果有相同的number会抛异常
Map<Long, Course> num2Lesson1 = courses.stream().collect(Collectors.toMap(Course::getNumber, Function.identity()));
// 根据number组成map, 如果有相同的number会执行降级逻辑
Map<Long, Course> num2Lesson2 = courses.stream().collect(Collectors.toMap(Course::getNumber, Function.identity(), (v1, v2) -> v1));
// 根据number聚合
Map<Long, List<Course>> num2Lessons = courses.stream()
.filter(Objects::nonNull)
.collect(Collectors.groupingBy(Course::getNumber));
// 根据number聚合某个字段
Map<Long, List<LocalDateTime>> number2BeginTimes = courses.stream()
.filter(Objects::nonNull)
.collect(Collectors.groupingBy(Course::getNumber,
Collectors.mapping(Course::getBeginTime, Collectors.toList())));
// 根据number找到number下最大beginTime的Course
Map<Long, Optional<Course>> number2MaxBeginTimeCourse = courses.stream()
.filter(r -> Objects.nonNull(r.getBeginTime()))
.collect(Collectors.groupingBy(Course::getNumber, Collectors.maxBy(Comparator.comparing(Course::getBeginTime))));
// 获取course下所有的studentId
List<Long> allStudentIds = courses.stream()
.map(Course::getStudentIds)
.flatMap(Collection::stream)
.distinct()
.collect(Collectors.toList());
}
stream原理
基本原理
list.stream()
.filter(Objects::nonNull)
.map(World::toString)
.distinct()
.collect(Collectors.toList());
以上面的处理为例,分别经过了过滤->映射->去重->聚合三个操作,在stream内部会通过一个链表将这三个操作联系起来,一个操作被称为一个stage(或pipeline),每个stage会指向上下游的stage和sourceStage(即哨兵头节点),如下图所示:
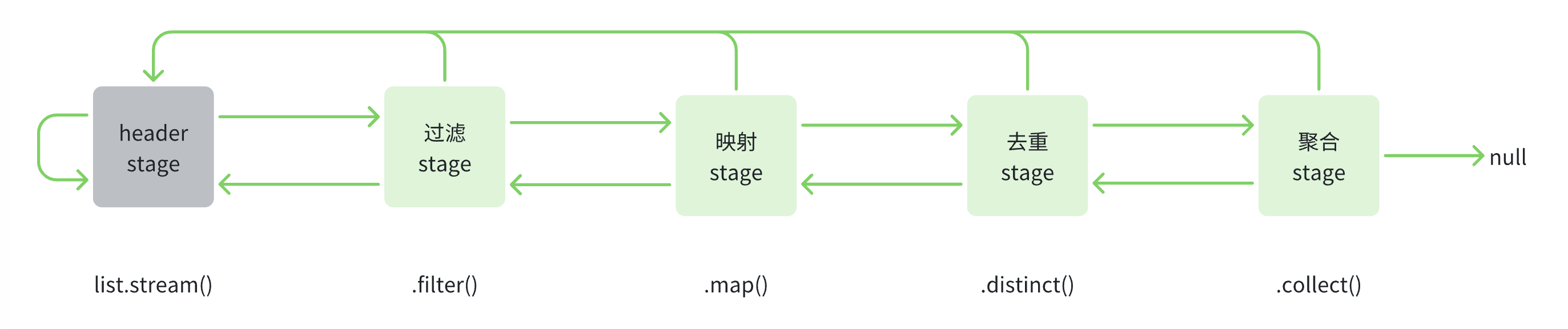
对应的在AbstractPipeline类中有三个字段分别引用链表上下游节点和链表的哨兵头节点:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
// Backlink to the head of the pipeline chain (self if this is the source stage).
private final AbstractPipeline sourceStage;
// The "upstream" pipeline, or null if this is the source stage.
private final AbstractPipeline previousStage;
// The next stage in the pipeline, or null if this is the last stage. Effectively final at the point of linking to the next pipeline.
private AbstractPipeline nextStage;
...
}
stage可分为3类(可以在各个Reference类中找到下面3个内部类):
- Header: 哨兵头节点,用户无需感知
- StatelessOp: 无状态stage,如过滤
- StatefulOp: 有状态stage,如聚合
对应的在ReferencePipeline中有3个内部类:
abstract class ReferencePipeline<P_IN, P_OUT>
extends AbstractPipeline<P_IN, P_OUT, Stream<P_OUT>>
implements Stream<P_OUT> {
static class Head<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {...}
abstract static class StatelessOp<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {...}
abstract static class StatefulOp<E_IN, E_OUT> extends ReferencePipeline<E_IN, E_OUT> {...}
...
}
以上提到的三种名词:
pipeline,stage,op都是指代链表里的一个操作节点,即pipeline==stage==op,类似一个生物学人具有多个社会学身份。
再来看看代码实现,其uml类图如下:
Java对BaseStream接口的实现是 AbstractPipeline,BaseStream可分为基于引用类型和基于基础类型,其中基于引用类型实现为ReferencePipleline,基于数值基础类型分别有实现LongPipleline、IntPipleline、DoublePipleline。
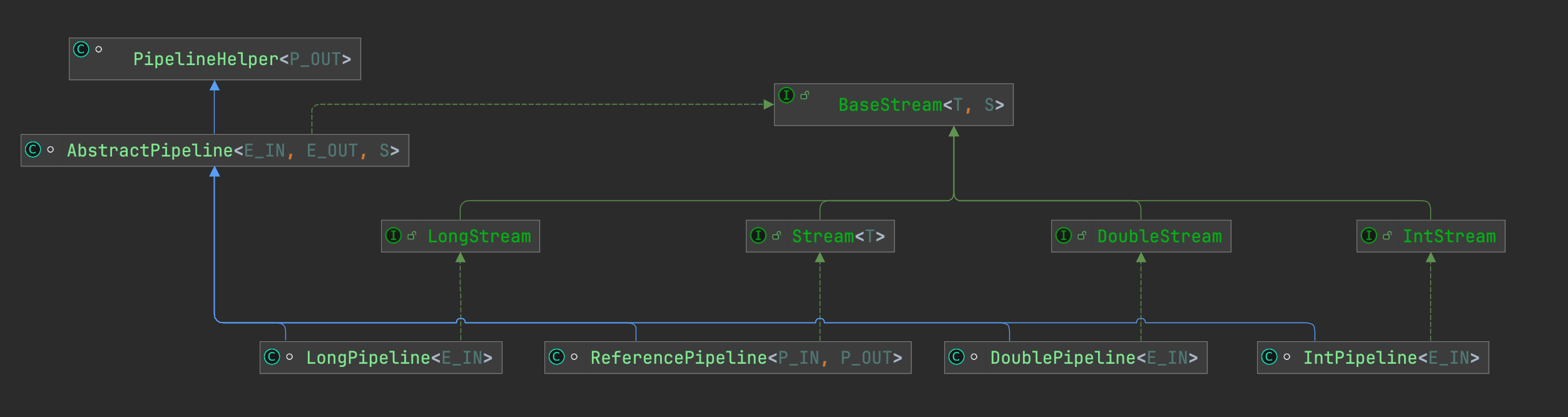
pipeline中封装了stream source或intermediate operations,一个pipeline代表一次操作,比如过滤、去重等,当 pipeline 被引用时则称为stage,多个stage可以通过Fluent Api组装起来实现流式处理,组装的过程即是构建一个链表的过程。
当我们调用一个集合的stream()方法时,会调用StreamSupport#stream方法构造一个header pipeline:
public interface Collection<E> extends Iterable<E> {
...
default Stream<E> stream() {
// 传入Collection自定义个Spliterator,返回一个 header pipeline
return StreamSupport.stream(spliterator(), false);
}
...
// Collection自定义的Spliterator
default Spliterator<E> spliterator() {
return Spliterators.spliterator(this, 0);
}
...
}
public final class StreamSupport {
...
// 生成 header pipeline
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
...
}
java.util.Spliterator
两个问题:
Spliterator是干嘛的?stream为什么需要Spliterator?
An object for traversing and partitioning elements of a source.
可以看到Spliterator支持对数据进行遍历和分割,对应的在接口中有tryAdvance + forEachRemaining用于遍历,有trySplit支持分割。
trySplit方法返回的是Spliterator,所以Spliterator是一种类似细胞分裂的方式执行,对一个ArrayList进行分割:
List<Integer> list = new ArrayList<>();
for (int i = 1; i <= 5; i++) {
list.add(i);
}
Spliterator<Integer> sourceSpliterator = list.spliterator();
Assertions.assertEquals(5, sourceSpliterator.estimateSize());
// 执行一次,输出1,剩下2345四个元素可分割和遍历
sourceSpliterator.tryAdvance(i -> Assertions.assertEquals(1, i));
Assertions.assertEquals(4, sourceSpliterator.estimateSize());
Spliterator<Integer> subSpliterator1 = sourceSpliterator.trySplit();
// 2 3
Assertions.assertEquals(2, sourceSpliterator.estimateSize());
// 4 5
Assertions.assertEquals(2, subSpliterator1.estimateSize());
List<Integer> list2 = new ArrayList<>();
list2.add(1);
// 只有一个元素时进行split,此时spliterator1==null
Spliterator<Integer> spliterator1 = list2.spliterator().trySplit();
Assertions.assertNull(spliterator1);
Spliterator只对未遍历过的元素(未被tryAdvance执行到且未执行forEachRemaining)执行trySplit,如果没有trySplit返回null, 同样stream流只运行执行一次。
同时Spliterator有以下特性,可以包含多个:
- ORDERED: 遍历和分割保证顺序
- DISTINCT: 非重复
- SORTED: 遍历和分割时以一种顺序执行,通过getComparator方法提供自定义比较器
- SIZED:
estimateSize放回返回固定值 - SUBSIZED: trySplit之后所有的Spliterator同时支持SIZED和SUBSIZED特性
- IMMUTABLE: 遍历和分割的对象不能有结构变更
- CONCURRENT: 支持多线程安全遍历和分割
所有特性以bitset的方式记录在一个int类型值中,通过characteristics方法获取。
那么为什么stream要用Spliterator呢?
Spliterator是并行流(Parallel Stream)背后的关键机制。当调用集合的parallelStream()方法时,该方法内部会创建一个Spliterator来遍历和分割集合中的元素。然后,Java的并行框架(如ForkJoinPool)会利用这些Spliterator来分配任务给多个线程,以实现并行处理。
java.util.stream.Sink
stream的操作都在该接口中实现
An extension of Consumer used to conduct values through the stages of a stream pipeline,
with additional methods to manage size information, control flow, etc.
通常使用内部抽象类ChainedReference构建一个Sink链,ChainedReference 中指向链条的下一个Sink。
stream支持多元素操作如sorted和单元素操作如map,如何组合这两种操作呢?stream即是通过Sink接口实现。
Sink包含三个主要接口:
interface Sink<T> extends Consumer<T> {
// 调用该接口表示stage开始接收数据,size表示要接受的数据个数,-1表示未知或无限制
default void begin(long size) {}
// 调用该接口表示stage数据接受完毕,当需要操作所有数据时,可在这里操作,比如sorted就在这里做排序
default void end() {}
// 调用该接口表示stage开始操作单个数据
default void accept(int value)
...
}
注意以上接口都是default,如果子接口(如
TerminalSink)没实现表示默认不做操作。
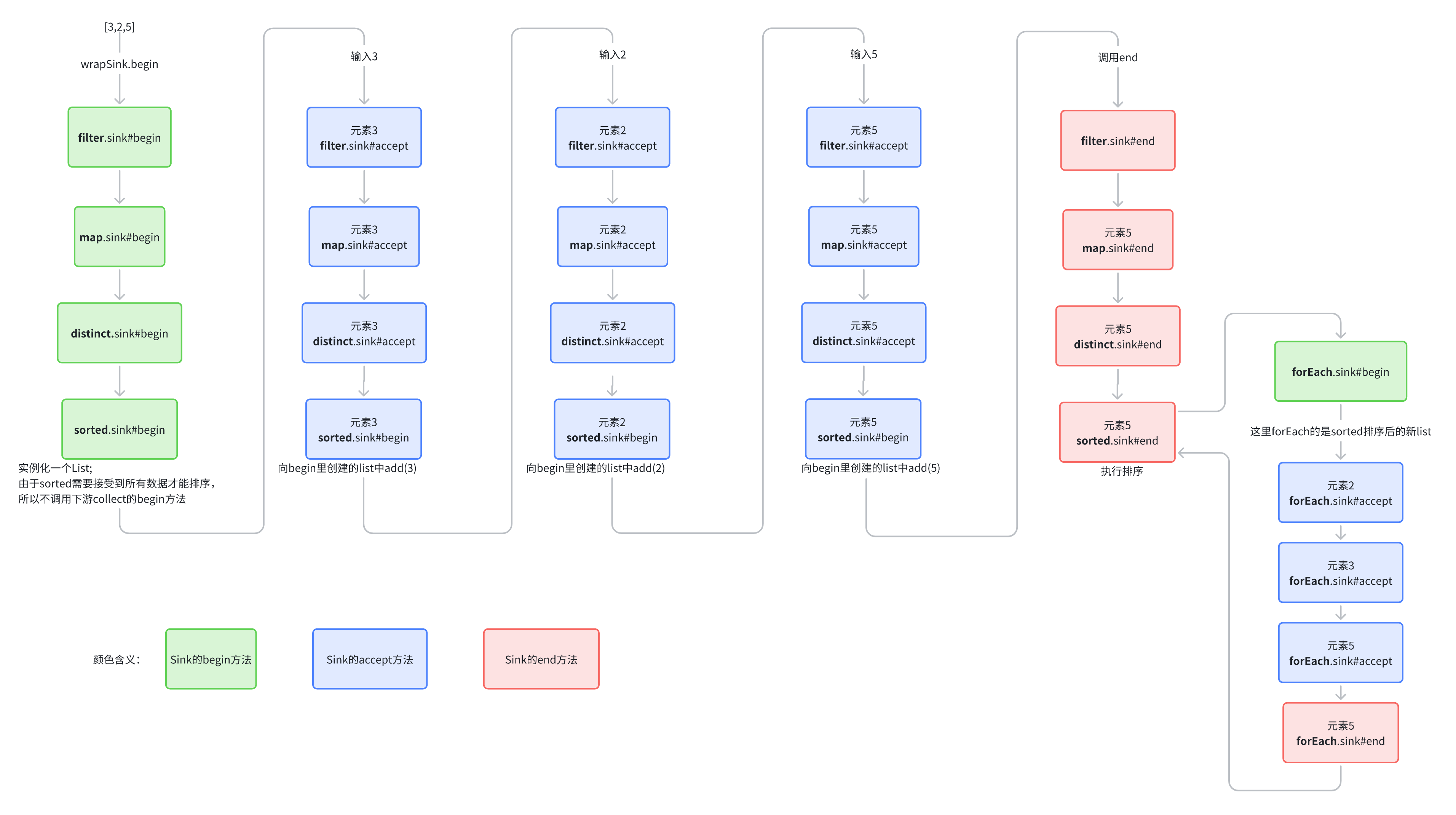
以以下stream流为例:
list = [3,2,5]
list.stream()
.filter(Objects::nonNull)
.map(i -> i + "hello")
.distinct()
.sorted()
.forEach(System.out::println);
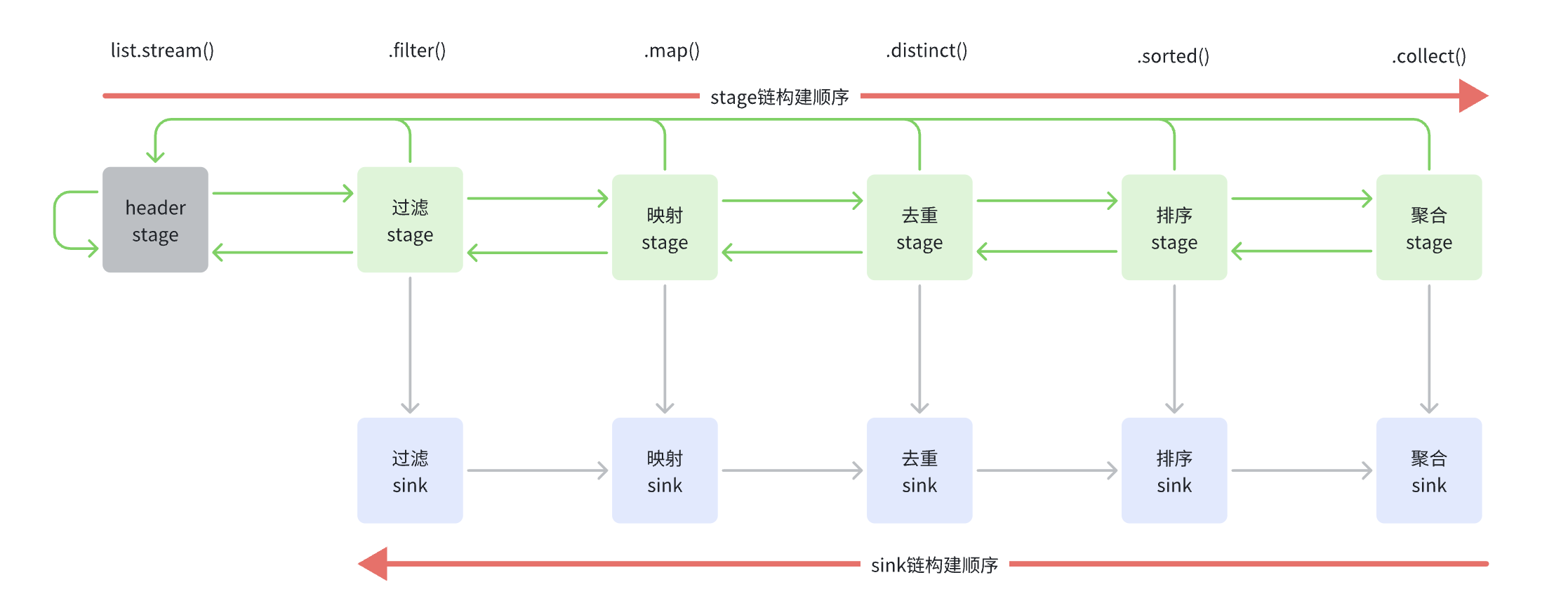
当我们调用list.stream.filter.map.distinct.sorted.collect时,
会首先正向构建一个stage操作双向链表,即filter <-> map <-> distinct <-> sorted <-> collect
最后在链接TerminalOp类型的stage时(这里是collect)会调用AbstractPipeline#wrapSink方法构建Sink单向链表,Sink单向链表的指向顺序也是filter -> map -> distinct -> sorted -> collect,但其构建顺序是反向的,即collect -> sorted -> distinct -> map -> filter,如下图所示:
代码如下:
abstract class AbstractPipeline<E_IN, E_OUT, S extends BaseStream<E_OUT, S>>
extends PipelineHelper<E_OUT> implements BaseStream<E_OUT, S> {
...
// .stream()执行时表示中间操作stage的个数
// .parallelStream()执行时表示前面有状态的中间操作个数,因为有状态依赖的必须sequential执行
private int depth;
@Override
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this;
p.depth > 0;
// 前面的stage
p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
...
}
来模拟[3,2,5]作为输入时的stream流程:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Java stream使用与执行原理

发表评论 取消回复