1 K邻近分类法
该算法将要分类的对象与训练集中已知类标记的所有对象进行对比,并由k近邻对指派到哪个类进行投票。该方法的弊端是:与k-means聚类算法一样,需要预先设定k值,k值得选择会影响分类得性能,而且这种方法要求将整个训练集存储起来,当训练集非常大,搜索会较慢。
将定义得类对象添加到knn.py文件中。
class KnnClassifier(object):
def __init__(self,labels,samples):
self.labels = labels
self.samples = samples
def classify(self,point,k=3):
dist = array([L2dist(point,s) for s in self.samples])
ndx = dist.argsort()
votes = {}
for i in range(k):
label = self.labels[ndx[i]]
votes.setdefault(label,0)
votes[label] += 1
return max(votes)
def L2dist(p1,p2):
return sqrt( sum( (p1-p2)**2) )
def L1dist(v1,v2):
return sum(abs(v1-v2))
使用KNN方法,没有必要存储并将训练数据作为参数来传递。
1.1 一个简单的二维示例
使用如下代码生成4给二维数据集文件,其中points_normal.pkl和points_ring.pkl用于训练,points_normal_test.pkl和points_ring_test.pkl用于测试。
from numpy.random import randn
import pickle
from pylab import *
n=200
class_1 = 0.6 * randn(n,2)
class_2 = 1.2 * randn(n,2) + array([5,1])
labels = hstack((ones(n),-ones(n)))
# 用Pickle 模块保存
with open('points_normal_test.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
# 正态分布,并使数据成环绕状分布
class_1 = 0.6 * randn(n,2)
r = 0.8 * randn(n,1) + 5
angle = 2*pi * randn(n,1)
class_2 = hstack((r*cos(angle),r*sin(angle)))
labels = hstack((ones(n),-ones(n)))
# 用Pickle 保存
with open('points_ring_test.pkl', 'wb') as f:
pickle.dump(class_1,f)
pickle.dump(class_2,f)
pickle.dump(labels,f)
使用Pickle模块来创建一个KNN分类器模型
from numpy.random import randn
import pickle
from pylab import *
from PCV.tools import imtools
from PCV.classifiers import knn
from matplotlib import pyplot
with open('points_normal.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
model = knn.KnnClassifier(labels, vstack((class_1, class_2)))
with open('points_normal_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 在测试数据集的第一个数据点上进行测试
print (model.classify(class_1[0]))
def classify(x,y,model=model):
return array([model.classify([xx,yy]) for (xx,yy) in zip(x,y)])
# 绘制分类边界
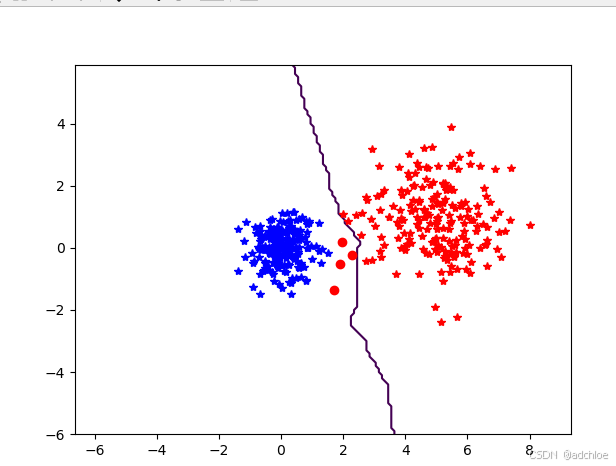
imtools.plot_2D_boundary([-6,6,-6,6],[class_1,class_2],classify,[1,-1])
show()
不同颜色代表类标记,正确分类的点用星号表示,分类错误的点用圆点标记,曲线是分类器的决策边界。
1.2 用稠密SIFT作为图像特征
对图像进行分类,需要一个特征向量来表示一幅图像,这里用稠密SIFT特征向量。
在整幅图像上用一个规则的网格应用SIFT描述子可以得到稠密SIFT的表示形式。将以下代码添加到dsift.py文件中
from PCV.localdescriptors import sift
def process_image_dsift(imagename,resultname,size=20,steps=10,force_orientation=False,resize=None):
im = Image.open(imagename).convert('L')
if resize!=None:
im = im.resize(resize)
m,n = im.size
if imagename[-3:] != 'pgm':
#create a pgm file
im.save('tmp.pgm')
imagename = 'tmp.pgm'
# create frames and save to temporary file
scale = size/3.0
x,y = meshgrid(range(steps,m,steps),range(steps,n,steps))
xx,yy = x.flatten(),y.flatten()
frame = array([xx,yy,scale*ones(xx.shape[0]),zeros(xx.shape[0])])
savetxt('tmp.frame',frame.T,fmt='%03.3f')
if force_orientation:
cmmd = str("sift "+imagename+" --output="+resultname+
" --read-frames=tmp.frame --orientations")
else:
cmmd = str("sift "+imagename+" --output="+resultname+
" --read-frames=tmp.frame")
os.system(cmmd)
print('processed', imagename, 'to', resultname)
利用下面的代码计算稠密SIFT描述子,并且可视化它们的位置:
from PCV.localdescriptors import dsift
from PCV.localdescriptors import sift
from matplotlib import pyplot
from pylab import *
from PIL import Image
dsift.process_image_dsift('empire.jpg', 'empire.sift', 90, 40, True)
l, d = sift.read_features_from_file('empire.sift')
im = array(Image.open('empire.jpg'))
sift.plot_features(im, l, True)
show()

1.3 图像分类:手势识别
该应用使用稠密SIFT描述子来表示手势图像,建立一个简单的手势识别系统。
通过下列代码获取每幅图像的稠密SIFT特征:
from PCV.localdescriptors import dsift
from PCV.localdescriptors import sift
from matplotlib import pyplot
from pylab import *
from PIL import Image
from PCV.tools.imtools import get_imlist
imlist = get_imlist(r'C:\Users\23232\Desktop\data\gesture\fig8-3')
for filename in imlist:
featfile = filename[:-3]+'dsift'
dsift.process_image_dsift(filename,featfile,10,5,resize=(50,50))
通过下列代码绘制出带有描述子的图像
from PCV.localdescriptors import dsift
from PCV.localdescriptors import sift
from matplotlib import pyplot
from pylab import *
from PIL import Image
from PCV.tools.imtools import get_imlist
import os
imlist = ['C:/Users/23232/Desktop/data/gesture/fig8-3/A-uniform01.ppm','C:/Users/23232/Desktop/data/gesture/fig8-3/B-uniform01.ppm'
,'C:/Users/23232/Desktop/data/gesture/fig8-3/c-uniform01.ppm','C:/Users/23232/Desktop/data/gesture/fig8-3/Five-uniform01.ppm',
'C:/Users/23232/Desktop/data/gesture/fig8-3/Point-uniform01.ppm','C:/Users/23232/Desktop/data/gesture/fig8-3/V-uniform01.ppm']
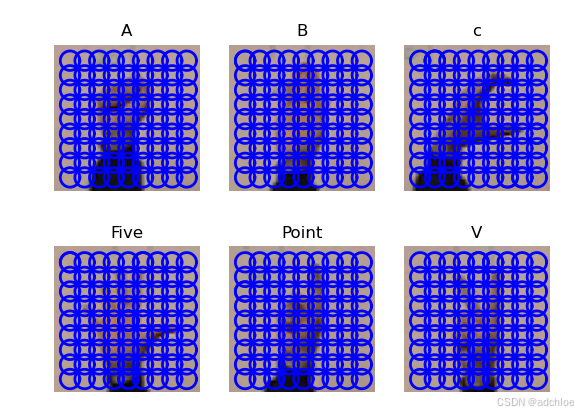
figure()
for i, im in enumerate(imlist):
print(im)
dsift.process_image_dsift(im, im[:-3] + 'dsift', 10, 5, True, resize=(50, 50))
l, d = sift.read_features_from_file(im[:-3] + 'dsift')
dirpath, filename = os.path.split(im)
im = array(Image.open(im).resize((50, 50)))
titlename = filename[:-14]
subplot(2, 3, i + 1)
sift.plot_features(im, l, True)
title(titlename)
show()
打印出标记以及相应的混淆矩阵:
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
def get_imagelist(path):
return [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.ppm')]
def read_gesture_features_labels(path):
featlist = [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.dsift')]
features = []
for featfile in featlist:
l, d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = array(features)
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features, array(labels)
def print_confusion(res, labels, classnames):
n = len(classnames)
class_ind = dict([(classnames[i], i) for i in range(n)])
confuse = zeros((n, n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]], class_ind[test_labels[i]]] += 1
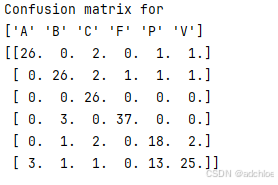
print('Confusion matrix for')
print(classnames)
print(confuse)
filelist_train = get_imagelist('C:/Users/23232/Desktop/data/gesture/train')
filelist_test = get_imagelist('C:/Users/23232/Desktop/data/gesture/test')
imlist = filelist_train + filelist_test
for filename in imlist:
featfile = filename[:-3] + 'dsift'
dsift.process_image_dsift(filename, featfile, 10, 5, resize=(50, 50))
features, labels = read_gesture_features_labels('C:/Users/23232/Desktop/data/gesture/train/')
test_features, test_labels = read_gesture_features_labels('C:/Users/23232/Desktop/data/gesture/test/')
classnames = unique(labels)
k = 1
knn_classifier = knn.KnnClassifier(labels, features)
res = array([knn_classifier.classify(test_features[i], k) for i in
range(len(test_labels))])
acc = sum(1.0 * (res == test_labels)) / len(test_labels)
print('Accuracy:', acc)
print_confusion(res, test_labels, classnames)
2 贝叶斯分类器
另一个分类器是贝叶斯分类器,该分类器是基于贝叶斯条件概率定理的概率分类器,假设特征是彼此独立不相关的。该分类器的优势是一旦学习了这个模型,就没有必要存储训练数据了,只需存储模型的参数。
该分类器是通过将各个特征的条件概率相乘得到一个类的总概率,然后选取概率最高的那个类构造出来。
将BayesClassifier类添加到文件bayes.py中:
class BayesClassifier(object):
def __init__(self):
""" 使用训练数据初始化分类器 """
self.labels = [] # 类标签
self.mean = [] # 类均值
self.var = [] # 类方差
self.n = 0 # 类别数
def train(self,data,labels=None):
""" 在数据 data(n×dim 的数组列表)上训练,标记labels是可选的,默认为0…n-1 """
if labels==None:
labels = range(len(data))
self.labels = labels
self.n = len(labels)
for c in data:
self.mean.append(mean(c,axis=0))
self.var.append(var(c,axis=0))
def classify(self,points):
""" 通过计算得出的每一类的概率对数据点进行分类,并返回最可能的标记"""
# 计算每一类的概率
est_prob = array([gauss(m,v,points) for m,v in zip(self.mean,self.var)])
# 获取具有最高概率的索引,该索引会给出类标签
ndx = est_prob.argmax(axis=0)
est_labels = array([self.labels[n] for n in ndx])
return est_labels, est_prob
该模型每一类由两个变量,类均值和协方差。train()方法获取特征数组列表来计算每个特征数组的均值和协方差。
接下来将该贝叶斯分类器用于上一节的二维数据
import pickle
from matplotlib import pyplot as plt
from PCV.classifiers import bayes
import numpy as np
from PCV.tools import imtools
with open(r'points_normal.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 训练贝叶斯分类器
bc = bayes.BayesClassifier()
bc.train([class_1, class_2], [1, -1])
# 用 Pickle 模块载入测试数据
with open(r'points_normal_test.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
print(bc.classify(class_1[:10])[0])
# 绘制这些二维数据点及决策边界
def classify(x, y, bc=bc):
points = np.vstack((x, y))
return bc.classify(points.T)[0]
imtools.plot_2D_boundary([-6, 6, -6, 6], [class_1, class_2], classify, [1, -1])
plt.show()
该例中,决策边界是一个椭圆,类似于二维高斯函数的等值线,正确分类的点用星号表示,错误分类的点用圆点表示。
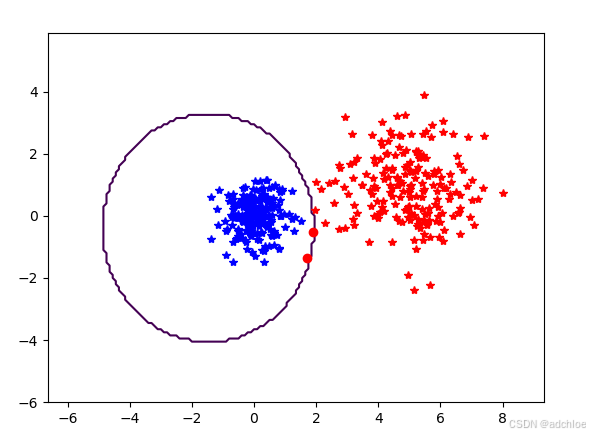
用PCA降维
由于稠密SIFT描述子的特征向量十分庞大,在用数据拟合模型前进行降维处理是一个好想法。
import pickle
from matplotlib import pyplot as plt
from PCV.classifiers import bayes
import numpy as np
from PCV.tools import imtools
from PCV.tools import pca
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
def print_confusion(res, labels, classnames):
n = len(classnames)
class_ind = dict([(classnames[i], i) for i in range(n)])
confuse = zeros((n, n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]], class_ind[test_labels[i]]] += 1
print('Confusion matrix for')
print(classnames)
print(confuse)
def read_gesture_features_labels(path):
# 对所有以 .dsift 为后缀的文件创建一个列表
featlist = [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.dsift')]
# 读取特征
features = []
for featfile in featlist:
l, d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = np.array(features)
# 创建标记
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features, np.array(labels)
def get_imagelist(path):
return [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.ppm')]
filelist_train = get_imagelist('C:/Users/23232/Desktop/data/gesture/train')
filelist_test = get_imagelist('C:/Users/23232/Desktop/data/gesture/test')
for filename in filelist_train:
featfile = filename[:-3] + 'dsift'
dsift.process_image_dsift(filename, featfile, 10, 5, resize=(50, 50))
for filename in filelist_test:
featfile = filename[:-3] + 'dsift'
dsift.process_image_dsift(filename, featfile, 10, 5, resize=(50, 50))
features, labels = read_gesture_features_labels('C:/Users/23232/Desktop/data/gesture/train/')
test_features, test_labels = read_gesture_features_labels('C:/Users/23232/Desktop/data/gesture/test/')
classnames = unique(labels)
V, S, m = pca.pca(features)
# 保持最重要的成分
V = V[:50]
features = array([dot(V, f - m) for f in features])
test_features = array([dot(V, f - m) for f in test_features])
# 测试贝叶斯分类器
bc = bayes.BayesClassifier()
blist = [features[where(labels == c)[0]] for c in classnames]
bc.train(blist, classnames)
res = bc.classify(test_features)[0]
acc = sum(1.0*(res==test_labels)) / len(test_labels)
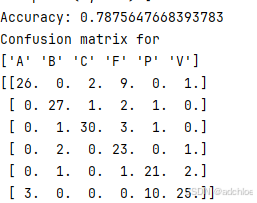
print ('Accuracy:', acc)
print_confusion(res,test_labels,classnames)
得到准确率约为78.5%,分类效果不如K邻近分类器,分类结果会睡着PCAW维度选取的不同发生变化。
3 支持向量机
SVM是强大的分类器,可以在很多分类问题中给出现有水准很高的分类结果。最简单的SVM在高维空间中寻找到一个最优线性分类面,来将两类数据分开。决策函数为
f
(
x
)
=
w
∗
x
−
b
f(x)=w*x-b
f(x)=w∗x−b
其中
w
w
w是常规的超平面,
b
b
b是偏移量常数。该决策函数的常规解是训练集上某些特征向量的线性组合:
w
=
∑
i
a
i
y
i
x
i
w=\sum_ia_iy_ix_i
w=∑iaiyixi
决策函数可以写为:
f
(
x
)
=
∑
i
a
i
y
i
x
i
∗
x
−
b
f(x)=\sum_ia_iy_ix_i*x-b
f(x)=∑iaiyixi∗x−b,
i
i
i是从训练集中选出的部分样本,选择的样本称为支持向量机。
SVM优势是可以使用核函数,核函数能将特征向量映射到另外一个不同维度的空间中。
线性是最简单的情况,即在特征空间中的超平面是线性的,
K
(
x
i
,
x
)
=
x
i
⋅
x
K(x_i,x)=x_i\cdot x
K(xi,x)=xi⋅x,
多项式用次数为
d
d
d的多项式对特征进行映射,
K
(
x
i
,
x
)
=
(
γ
x
i
⋅
x
+
r
)
d
K( x_i, x) = ( \gamma x_i\cdot x+ r) ^d
K(xi,x)=(γxi⋅x+r)d,
γ
>
0
\gamma > 0
γ>0,
径向基函数,通常指数函数是一种极其有效的选择,
K
(
x
i
,
x
)
=
e
(
¬
γ
∥
x
i
−
x
∥
2
)
K( x_i, x) = \mathrm{e} ^{( \neg \gamma \| \mathbf{x} _i- \mathbf{x} \| ^2) }
K(xi,x)=e(¬γ∥xi−x∥2),
γ
>
0
;
\gamma > 0;
γ>0;
Sigmoid 函数,一个更光滑的超平面替代方案,
K
(
x
i
,
x
)
=
tanh
(
γ
x
i
⋅
x
+
r
)
K(x_i,x)=\tanh(\gamma x_i\cdot x+r)
K(xi,x)=tanh(γxi⋅x+r)。
3.1 使用LibSVM
LibSVM为Python提供了良好的接口。
使用如下代码载入在前面KNN范例分类中用到的数据点,用径向基函数训练一个SVM分类器:
import pickle
from matplotlib import pyplot as plt
from PCV.classifiers import bayes
import numpy as np
from PCV.tools import imtools
from PCV.tools import pca
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
import pickle
from PCV.libsvm.libsvm.svmutil import *
from PCV.tools import imtools
# 用Pickle 载入二维样本点
with open('points_normal.pkl', 'rb') as f:
class_1 = pickle.load(f)
class_2 = pickle.load(f)
labels = pickle.load(f)
# 转换成列表,便于使用libSVM
class_1 = map(list,class_1)
class_2 = map(list,class_2)
labels = list(labels)
samples = list(class_1)+list(class_2) # 连接两个列表
# 创建SVM
prob = svm_problem(labels,samples)
param = svm_parameter('-t 2')
# 在数据上训练SVM
m = svm_train(prob,param)
#在训练数据上分类效果如何?
res = svm_predict(labels,samples,m)
显示训练数据中分类的正确率为100%,400个数据点全部分类正确。

3.2 再论手势识别
LibSVM可以自动处理多个类,只需要对数据进行格式化,使得输入和输出匹配LibSVM的要求,下面代码载入训练数据测试数据,并训练一个线性SVM分类器:
import pickle
from matplotlib import pyplot as plt
from PCV.classifiers import bayes
import numpy as np
from PCV.tools import imtools
from PCV.tools import pca
from PCV.localdescriptors import dsift
import os
from PCV.localdescriptors import sift
from pylab import *
from PCV.classifiers import knn
from PCV.libsvm.libsvm.svmutil import *
def print_confusion(res, labels, classnames):
n = len(classnames)
class_ind = dict([(classnames[i], i) for i in range(n)])
confuse = zeros((n, n))
for i in range(len(test_labels)):
confuse[class_ind[res[i]], class_ind[test_labels[i]]] += 1
print('Confusion matrix for')
print(classnames)
print(confuse)
def read_gesture_features_labels(path):
# 对所有以 .dsift 为后缀的文件创建一个列表
featlist = [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.dsift')]
# 读取特征
features = []
for featfile in featlist:
l, d = sift.read_features_from_file(featfile)
features.append(d.flatten())
features = np.array(features)
# 创建标记
labels = [featfile.split('/')[-1][0] for featfile in featlist]
return features, np.array(labels)
def get_imagelist(path):
return [os.path.join(path, f) for f in os.listdir(path) if f.endswith('.ppm')]
def convert_labels(labels, transl):
# 如果 labels 是一个数字数组,则需要将其转换成原始标签
if isinstance(labels[0], int):
return [transl[i] for i in labels]
# 否则,如果 labels 是原始标签,则需要将其转换成数字标签
else:
return [transl[label] for label in labels]
filelist_train = get_imagelist('C:/Users/23232/Desktop/data/gesture/train')
filelist_test = get_imagelist('C:/Users/23232/Desktop/data/gesture/test')
for filename in filelist_train:
featfile = filename[:-3] + 'dsift'
dsift.process_image_dsift(filename, featfile, 10, 5, resize=(50, 50))
for filename in filelist_test:
featfile = filename[:-3] + 'dsift'
dsift.process_image_dsift(filename, featfile, 10, 5, resize=(50, 50))
features, labels = read_gesture_features_labels('C:/Users/23232/Desktop/data/gesture/train/')
test_features, test_labels = read_gesture_features_labels('C:/Users/23232/Desktop/data/gesture/test/')
classnames = unique(labels)
features = list(map(list, features))
test_features = list(map(list, test_features))
# 为标记创建转换函数
transl = {}
for i, c in enumerate(classnames):
transl[c], transl[i] = i, c
# 创建 SVM
prob = svm_problem(convert_labels(labels, transl), features)
param = svm_parameter('-t 0')
m = svm_train(prob, param)
# 在训练数据上分类效果如何
res = svm_predict(convert_labels(labels, transl), features, m)
# 测试 SVM
res = svm_predict(convert_labels(test_labels, transl), test_features, m)[0]
res = convert_labels(res, transl)
acc = sum(1.0 * (res == test_labels)) / len(test_labels)
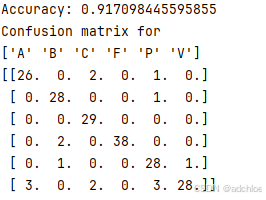
print('Accuracy:', acc)
print_confusion(res, test_labels, classnames)
分类结果如上图,准确率到达了91.7%
4 光学字符识别
OCR(光学字符识别)是理解手写或机写文本图像的处理过程。一个常见的例子是通过扫描文件来提取文本。
4.1 训练分类器
4.2 选取特征
首先确定选取怎样的特征向量来表示每一个单元格李图像。下列代码返回一个拉成一组数组后的灰度值特征向量。
def compute_feature(im):
""" 对一个 ocr 图像块返回一个特征向量"""
# 调整大小,并去除边界
norm_im = imresize(im,(30,30))
norm_im = norm_im[3:-3,3:-3]
return norm_im.flatten()
compute_feature()函数用到了imtools模块中的尺寸调整函数imresize(),以此减少特征向量长度。
使用如下函数来读取训练数据
from PCV.tools.imtools import imresize
from PIL import Image
def load_ocr_data(path):
imlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
#
labels = [int(imfile.split('/')[-1][0]) for imfile in imlist]
features = []
for imname in imlist:
im = array(Image.open(imname).convert('L'))
features.append(compute_feature(im))
return array(features),labels
上述代码将每一个JPEG文件的文件名中的第一个字母提取出来做类标记,并且这
些标记被作为整型数据存储在lables列表里;用上面的函数计算出的特征向量存储
在一个数组里。
4.3 多类支持向量机
得到了训练数据后,接下来学习一个分类器,使用多嘞支持向量机。
from PCV.libsvm.libsvm.svmutil import *
from PCV.tools.imtools import imresize
from PIL import Image
def compute_feature(im):
""" 对一个 ocr 图像块返回一个特征向量"""
# 调整大小,并去除边界
norm_im = imresize(im,(30,30))
norm_im = norm_im[3:-3,3:-3]
return norm_im.flatten()
def load_ocr_data(path):
imlist = [os.path.join(path,f) for f in os.listdir(path) if f.endswith('.jpg')]
#
labels = [int(imfile.split('/')[-1][0]) for imfile in imlist]
features = []
for imname in imlist:
im = array(Image.open(imname).convert('L'))
features.append(compute_feature(im))
return array(features),labels
features,labels = load_ocr_data('C:/Users/23232/Desktop/data/sudoku_images/sudoku_images/ocr_data/training/')
# 测试数据
test_features,test_labels = load_ocr_data('C:/Users/23232/Desktop/data/sudoku_images/sudoku_images/ocr_data/testing/')
# 训练一个线性SVM分类器
features = list(map(list,features))
test_features =list( map(list,test_features))
prob = svm_problem(labels,features)
param = svm_parameter('-t 0')
m = svm_train(prob,param)
# 在训练数据上分类效果如何
res = svm_predict(labels,features,m)
# 在测试集上表现如何
res = svm_predict(test_labels,test_features,m)
训练集上的图像都被完美分准确了,测试集上的识别性能也有99%作用。

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python计算机视觉编程——第8章 图像内容分类

发表评论 取消回复