在 9 月 3 日,Gru.ai 在 SWE-Bench-Verified 评估最新发布的数据中以 45.2% 的高分排名第一。SWE-Bench-Verified 是 OpenAI 联合 SWE 发布测试集,旨在更可靠的评估 AI 解决实际软件问题的能力。该测试集经由人工验证打标,被认为是评估 AI 软件工程能力的最权威标准。
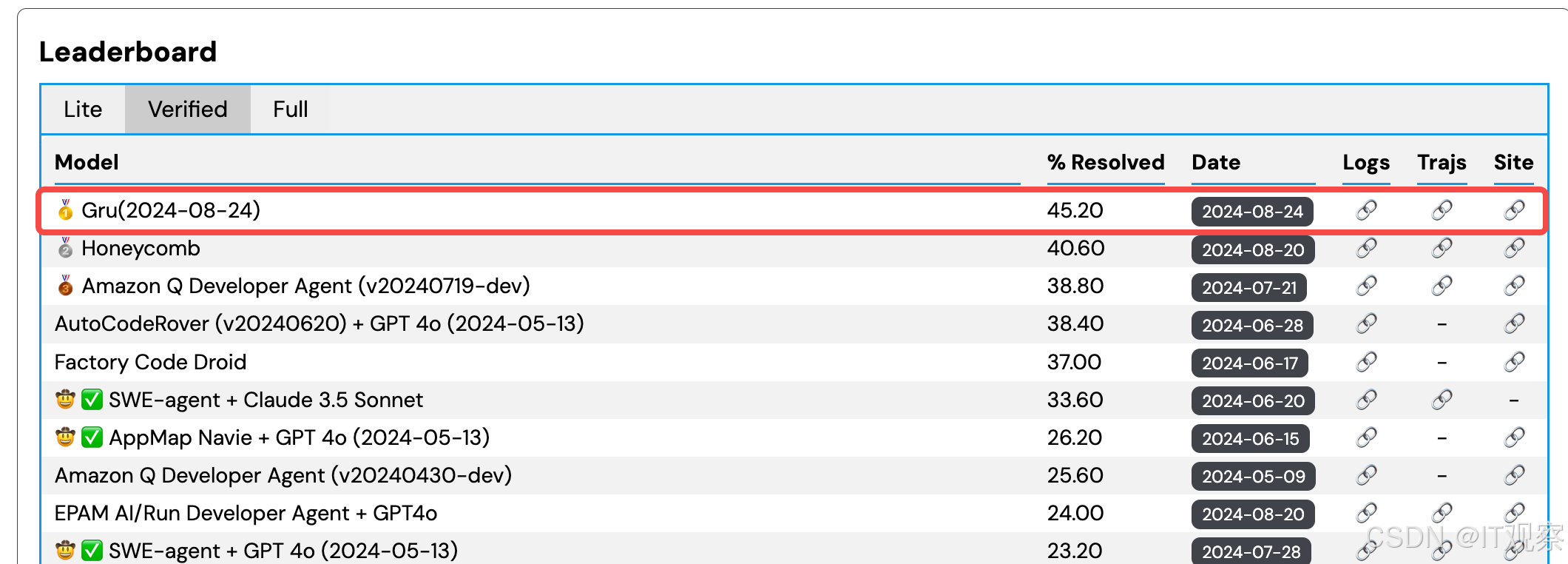
本次参评登顶的 Coding Agent 是来自 Gru.ai 的 Bug Fix Gru。根据 Gru 团队的博客,他们提供给 Bug Fix Gru 完整的运行环境及丰富的开发工具,这是获取高分的基础,而工作流程,多模态支持,Rag 能力的添加都有效提高了得分。值得关注的是,Gru 团队着重提到了他们有一个评估流程来评估任何改动带来的影响。
Gru.ai 是一家提供软件工程 Agent(智能体)的公司,提供四种 Agent:
Assistant Gru:帮助用户解决独立的技术问题,该产品可直接在网站注册使用。
Test Gru:基于用户代码补全单测的 Agent,目前该产品仅面相企业开放。
Bug Fix Gru:基于 Github Issue,直接提交 Patch,目前该产品仅面向企业开放。
Babel Gru:基于技术文档生成软件,目前该产品仍处于实验室阶段。
Gru 在今年一月披露了一笔 550 万美金的融资,投资方为云九资本和峰瑞资本。在 2023 年到 2024 年两年间,国际上大量的资金涌入代码 Agent 领域,如 Devin、Cosine.sh、Factory、Codium.ai 等,但国内针对软件工程领域 AI 的投资仍然较少。Gru 团队拥有丰富的软件工程和 AI 实践经验,CEO 张海龙曾是开源中国及 Coding.net 创始人。
随着资金和大公司的视线逐步从大模型转向上层应用,AI 行业的主要进步方向已经开始转向处理复杂精密的任务,而非简单的生成文本内容。而 Gru.ai 的成功登顶,标志着国人团队在 Agent 领域的工程技术能力处于第一梯队。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » OpenAI 联合 SWE 发布 AI 软件工程能力测试集,Gru.ai 荣登榜首

发表评论 取消回复