目录
3.3.1 系统运行情况的观测水平不足,面临故障时的反应速度差强人意
3.11 经典案例6 – 日志服务Logtail采集日志失败的问题定位
接上文
二、消息队列Kafka
2.1 消息队列 Kafka:企业级大数据消息通道
- 云消息队列 Kafka 版是阿里云提供的分布式、高吞吐、可扩展的消息队列服务
- 云消息队列 Kafka 版广泛用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,已成为大数据生态中不可或缺的部分
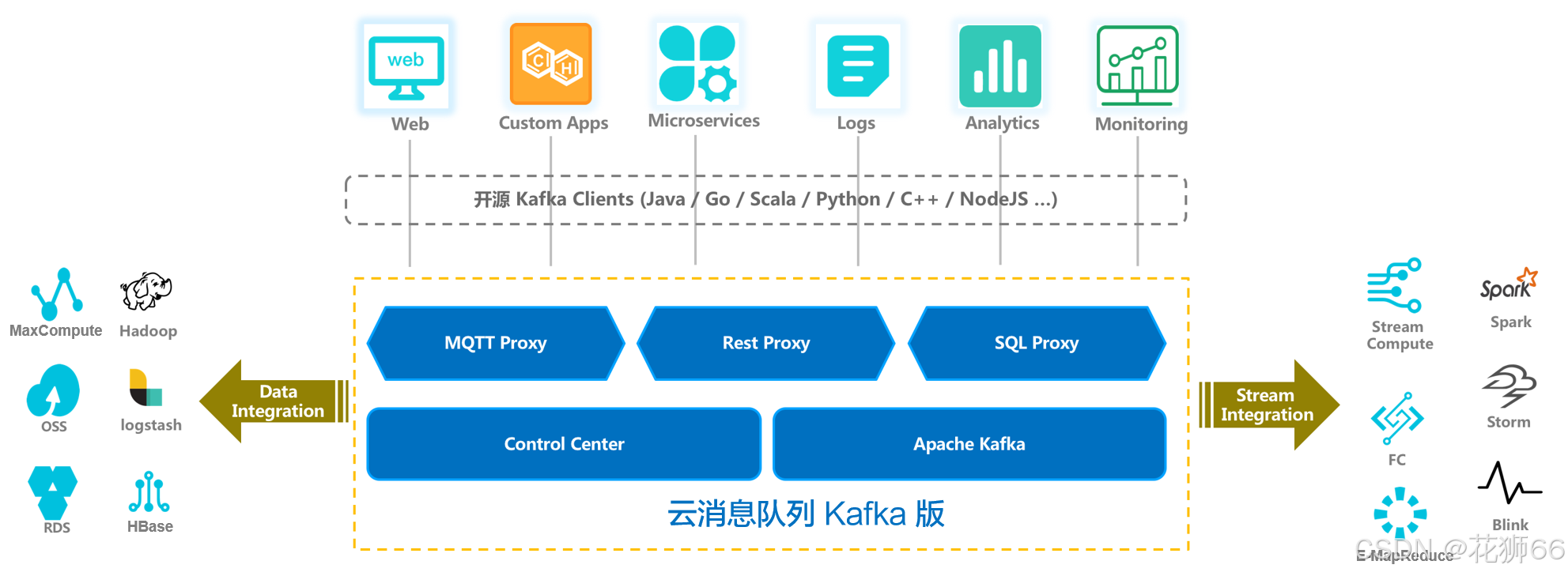
2.2 系统架构
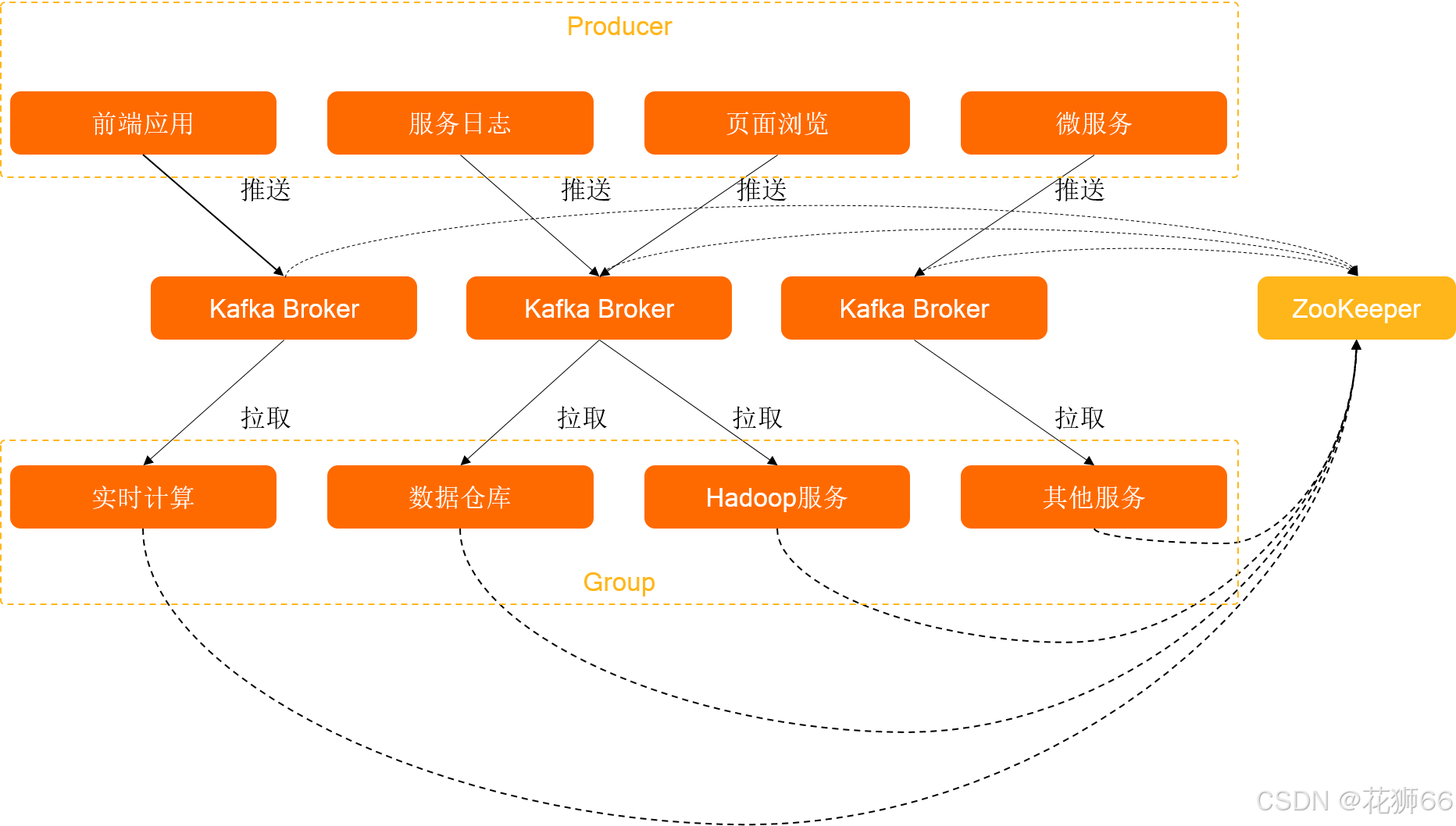
云消息队列 Kafka 版集群包括Producer、Kafka Broker、Group、ZooKeeper。
Producer
- 通过push模式向云消息队列 Kafka 版的Kafka Broker发送消息。发送的消息可以是网站的页面访问、服务器日志,也可以是CPU和内存相关的系统资源信息。
Kafka Broker
- 用于存储消息的服务器。Kafka Broker支持水平扩展。Kafka Broker节点的数量越多,云消息队列 Kafka 版集群的吞吐率越高。
Group
- 通过pull模式从云消息队列 Kafka 版Broker订阅并消费消息。
Zookeeper
- 管理集群的配置、选举leader分区,并且在Group发生变化时,进行负载均衡
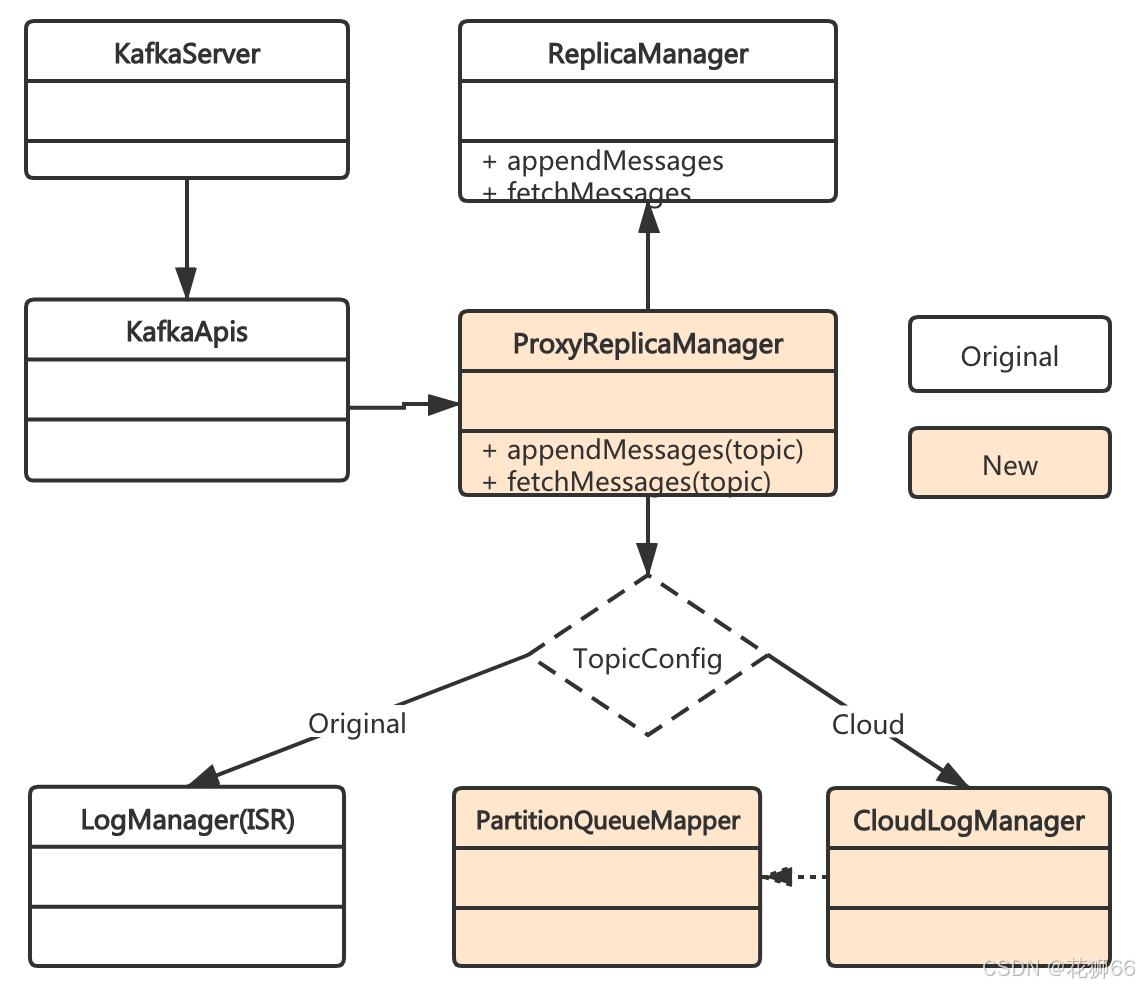
2.3 更稳定Kafka – 自研双引擎支持
用户痛点
- 开源劣势解决:开源bug、扩容等难点通过外围组件难以解决
- 兼容性担忧:优化后是否难以跟上新版本迭代,能否全兼容开源能力
- 支持粒度:业务维度细化到 Topic,优化后往往以实例级别进行支持
技术竞争力&价值
- 深度优化引擎提供:通过重写优化引擎彻底解决开源Kafka 的架构问题和深层bug
- 全面兼容开源、并支持快速迭代:通过原生引擎的支持,全面兼容0.10.x~2.2.x版本,更高版本可快速支持
- Topic级别支持兼容开源:支持优化引擎和原生引擎双支持,粒度细化到Topic
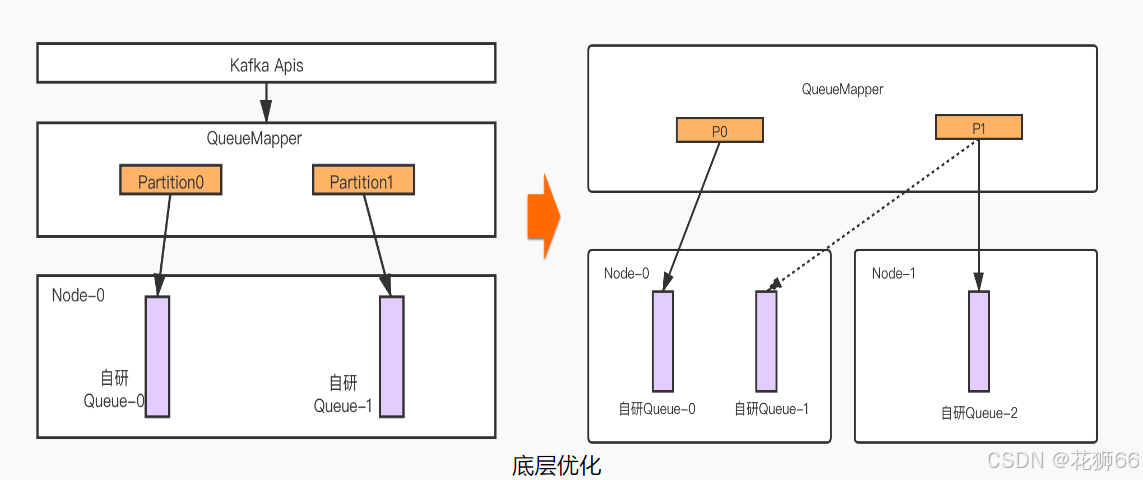
2.4 更高性能Kafka – 秒级分区扩容
用户需求:集群容量达到瓶颈时需要紧急扩容,同时不希望由于扩容引发可用性问题。
用户痛点
- 集群不可用:扩容和迁移分区时流量复制产生网络风暴,极端情况 90% 以上写失败 影响时间长
- 影响时间很长:均衡与数据量有关,可以从小时级别
技术竞争力&价值
- 秒级扩容:无论集群的数据量大小都可以保证在秒级别进行扩容
- 集群SLA保证:在扩容期间保证持续可写和可读
2.5 客户端报错及解决方案
| 报错信息 | 客户端语言类型 | 报错原因 | 解决方案 |
| TimeoutException | Java | 网络问题 客户端鉴权(sasl.mechanisms)失败 说明 该报错仅出现在云消息队列 Kafka 版的公网实例中。 | 确保servers配置正确。 通过telnet命令排除网络问题。 如果网络正常,请检查账号权限,确认鉴权正常。 说明:该方案仅适用于云消息队列 Kafka 版的公网实例。 |
| run out of brokers | Go | ||
| Authentication failed for user | Python | ||
| Leader is not available | 所有 | Topic初始化时会短暂报该错误。如果持续报错,可能是因为没有创建Topic。 | 检查Topic是否已经创建。 |
| leader is in election | |||
| array index out of bound exception | Java | Spring Cloud会按自己的格式解析消息内容。 | 参考如下两种解决方法: 推荐同时使用Spring Cloud发送和消费。 如果您使用其他方式发送,例如,调用原生Java客户端发送,通过Spring Cloud消费时,需要设置headerMode为raw,即禁用解析消息内容。具体信息,请参见Spring Cloud官网。 |
| No such configuration property: "sasl.mechanisms" | C++ 包装C++的客户端,例如,PHP、Node.js等。 | SASL和SSL模块未安装或安装异常。 | 参考如下命令安装SASL和SSL模块: 说明 此处以CentOS系统为例,其他系统请查阅相关官网或者第三方搜索引擎。 安装SSL:sudo yum install openssl openssl-devel 安装SASL:sudo yum install cyrus-sasl{,-plain} |
| No worthy mechs found | |||
| No KafkaClient Entry | Java | 未找到kafka_client_jaas.conf配置文件。 | 准备好kafka_client_jaas.conf文件,放在任意目录下,这里假设为/home/admin。Java的安全登录设置是系统性的,有如下两种设置方法: 设置系统变量: 通过设置JVM参数:-Djava.security.auth.login.config=/home/admin/kafka_client_jaas.conf 通过代码设置:System.setProperty("java.security.auth.login.config","/home/admin/kafka_client_jaas.conf") 配置系统文件:在${JAVA_HOME}/jre/lib/java.security中增加内容:login.config.url.1=file:/home/admin/kafka_client_jaas.conf |
| Error sending fetch request | Java | Consumer拉取消息失败报错,可能的原因如下: 网络问题 拉取消息超时 | 确保servers配置正确。 通过telnet命令排除网络问题。 如果网络正常,可能是拉取消息超时引起。可以尝试调整下列两个参数,限制单次拉取的消息量。 fetch.max.bytes:单次拉取操作,服务端返回的最大Bytes。 max.partition.fetch.bytes::单次拉取操作,服务端单个Partition返回的最大Bytes。 服务端流量限制,可以在云消息队列 Kafka 版控制台的实例详情页面查看相应内容。 VPC访问时查看峰值流量。 公网访问时查看公网流量。 |
| DisconnectException | |||
| CORRUPT_MESSAGE | 所有 | 如果是云存储引擎:客户端版本大于等于3.0时,自动开启幂等功能, 但云存储不支持幂等功能 如果是Local存储引擎:发送compact消息, 但未传递key值 | 如果是云储存引擎:在客户端设置enable.idempotence=false。 如果是Local存储引擎:消息添加key值。 |
三、云原生可观测体系
3.1 可观测性是系统稳定性保障的必要手段
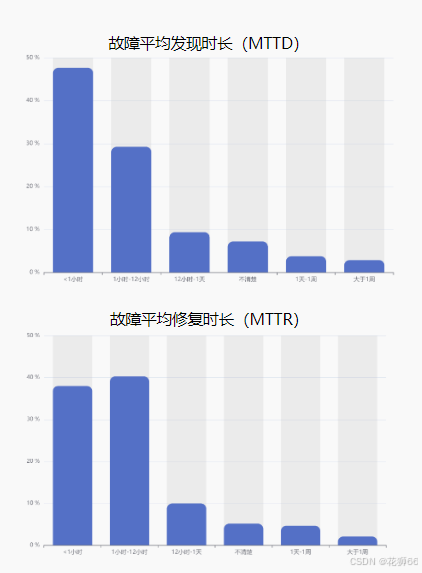
3.3.1 系统运行情况的观测水平不足,面临故障时的反应速度差强人意
《中国混沌工程调查报告(2021)》数据显示,仅不到一半的受访企业故障平均发现时长(MTTD)小于1小时;超过6成故障平均修复时长(MTTR)超过1小时,甚至有约20%的服务故障修复时间超过12小时。面对故障时无法及时发现、发现后无法及时定位修复,凸显了系统可观测性水平的不足。
3.1.2 及时有效地观测系统状态,可大大提高系统可用性
通过建设可观测性平台,高效全面的收集系统运行状态数据,在此基础上制定完善的告警策略,可大大提高系统故障时的响应速率,降低运维人员排查成本,提高系统可用性。
3.1.3 打造可观测性底座,赋能其他稳定性保障技术手段
- 利用可观测性技术所提供的海量系统运行数据,可以构建判断规则并训练模型,实现故障智能识别、根因分析、快速定位以及修复意见。
- 将可观测性技术与混沌工程、全链路压测等稳定性保障技术结合,构建智能巡检系统,从被动解决问题转为主动发现问题并预防问题,提前规避线上生产环境中的未知故障发生。
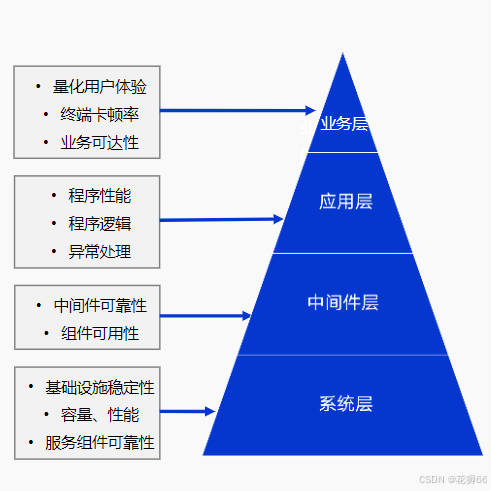
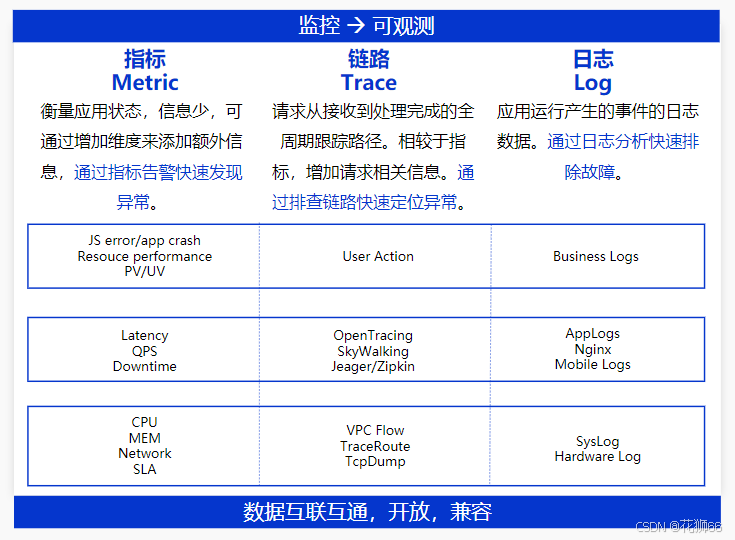
3.2 从监控到可观测:指标、链路、日志融合
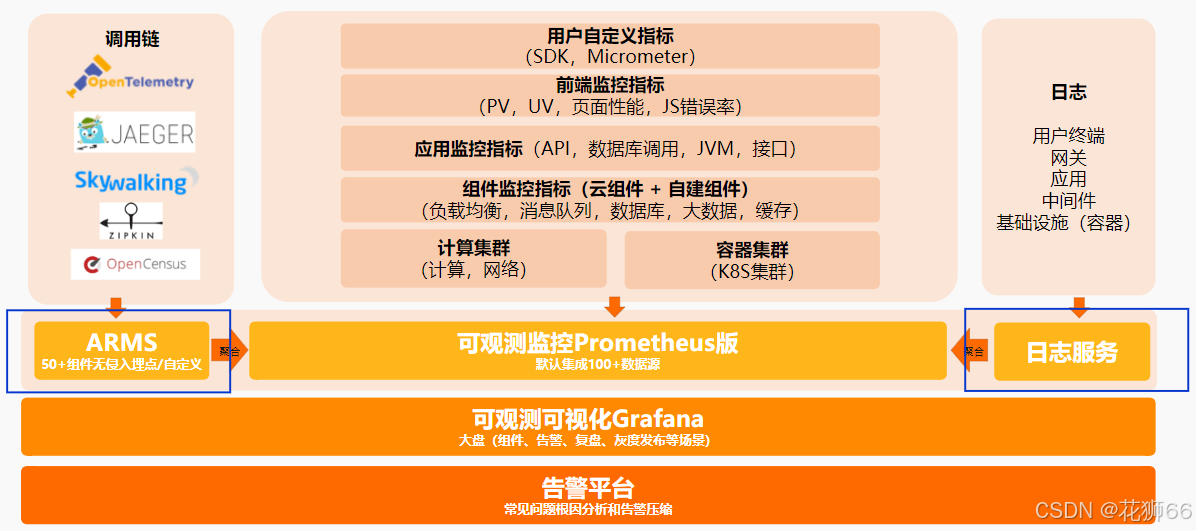
3.3 稳定性可观测方案架构图
基于Prometheus + Grafana + 链路追踪 + CLM 构建覆盖应用全栈的统一可观测平台,最懂云原生应用的“运维医生”。
3.4 可观测核心产品 – 日志服务

SLS 产品功能模块
1、开箱即用的应用:
- CloudLens 云产品可观测应用
- ITOps 开发运维应用
- SecOps 安全运维应用
- FinOps 成本分析应用
2、智能化的 Ops 平台工具:
- 智能巡检
- 智能告警
3、灵活的计算引擎:
- 索引查询/分析模式
- 扫描查询/分析模式
4、统一的可观测数据平台:
- 统一存储(热存/低频/归档,标准型/查询型)
- 数据处理与分析
5、多维的数据采集:
- 数据采集
- 数据加工
- 消费投递
3.5 可观测核心产品 – 应用实时监控服务ARMS
| 子产品 | 功能概述 | 常见场景 |
| 应用监控 | 面向分布式架构,监控Java应用,支持查看应用拓扑、接口调用、异常事务、慢事务等 | 压测前后的性能调优 应用运行情况的7×24小时监控和告警 |
| 前端监控 | 从页面打开速度、页面稳定性和外部服务调用成功率三个方面监测Web页面和小程序的健康度 | 用户报障快速排查 Web站点体验优化 |
| 用户体验监控 | 专注于对Web场景、App移动应用场景和小程序场景的监控,以用户体验为切入点,完整再现用户操作过程 | 用户报障快速排查 Web站点体验优化 |
| 可观测监控 Prometheus 版 | 对接开源Prometheus生态,支持类型丰富的组件监控,提供托管Prometheus服务 | 各类指标数据的采集、存储、展示 |
| 可观测可视化 Grafana 版 | 提供免运维和快速启动Grafana运行环境的能力,帮助用户高效分析与查看指标、日志和跟踪 | 运维监控统一大盘展现 多维度数据查询 |
| 应用监控 eBPF 版 | 针对Kubernetes集群的一站式可观测性产品,基于Kubernetes集群下的指标、应用链路、日志和事件,为IT开发运维人员提供整体的可观测性方案 | 无侵入监控Kubernetes集群 |
| 应用安全 | 基于RASP(Runtime Application Self-Protection)技术,应用安全可为应用在运行时提供强大的安全防护能力,并抵御绝大部分未知漏洞所利用的攻击手法 | 安全漏洞攻击防御 第三方组件安全风险梳理 |
| 云拨测 | 通过部署在全球各地的监测点,模拟真实用户从全球不同地区不同网络条件访问在线服务,持续对网络质量、网站性能、文件传输等场景进行可用性监测和性能监测 | 网络性能监控 业务可用性验证 |
| 可观测链路 OpenTelemetry 版 | 提供了完整的调用链路还原、调用请求量统计、链路拓扑、应用依赖分析等工具,可以帮助开发者快速分析和诊断分布式应用架构下的性能瓶颈,提高微服务时代下的开发诊断效率 | 多语言开发程序接入 分布式调用链查询和诊断 |
| 告警管理 | 提供了可靠的告警收敛、通知、自动升级以及其他功能,快速检测和修复业务告警 | 集成多种渠道的告警事件告警的人员管理及告警分派 |
3.6 经典案例1 -慢调用分析
1、通过监控或告警发现哪些接口出现慢响应问题。
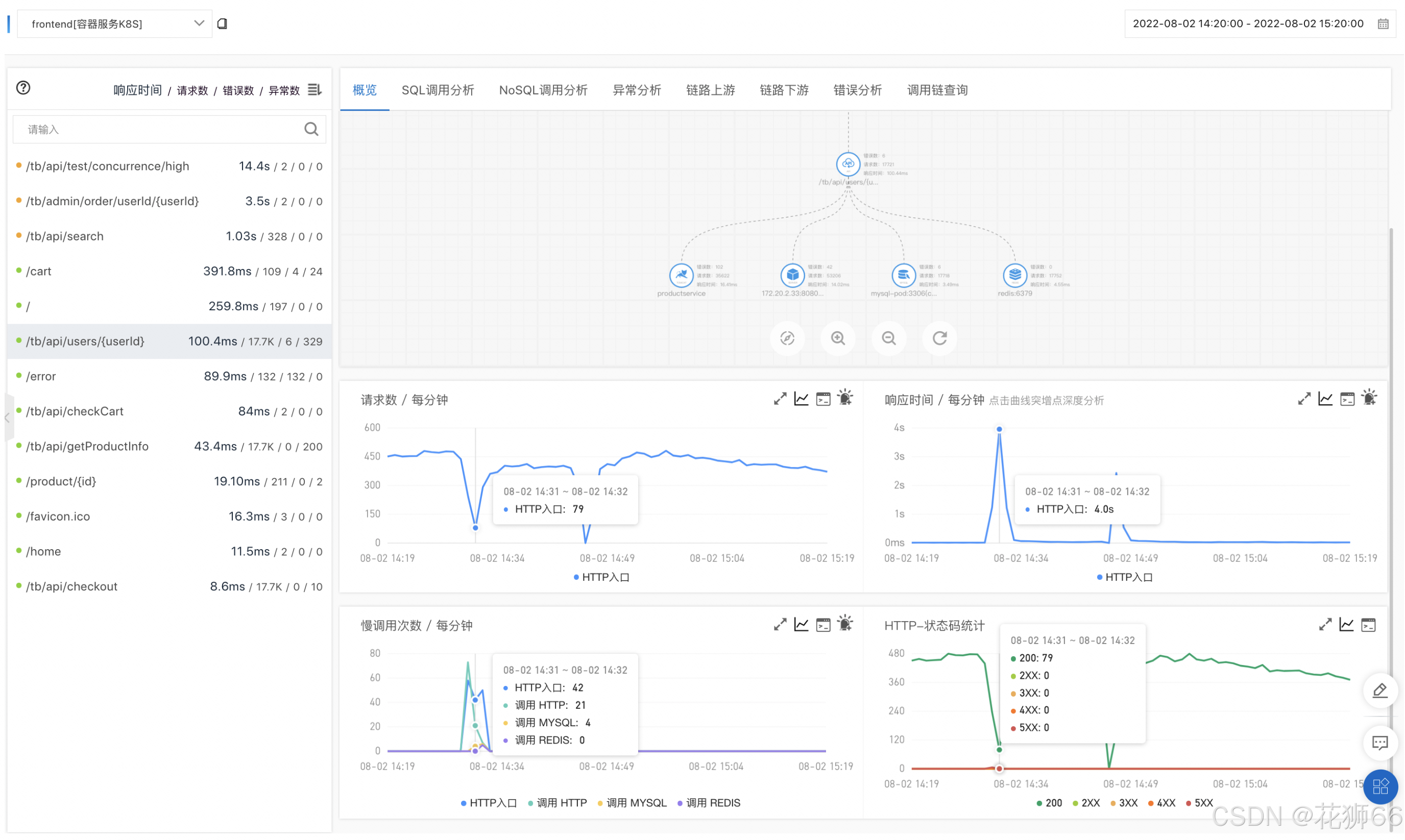
2、通过链路分析定位超过3s的慢调用分布,是否为单机问题。
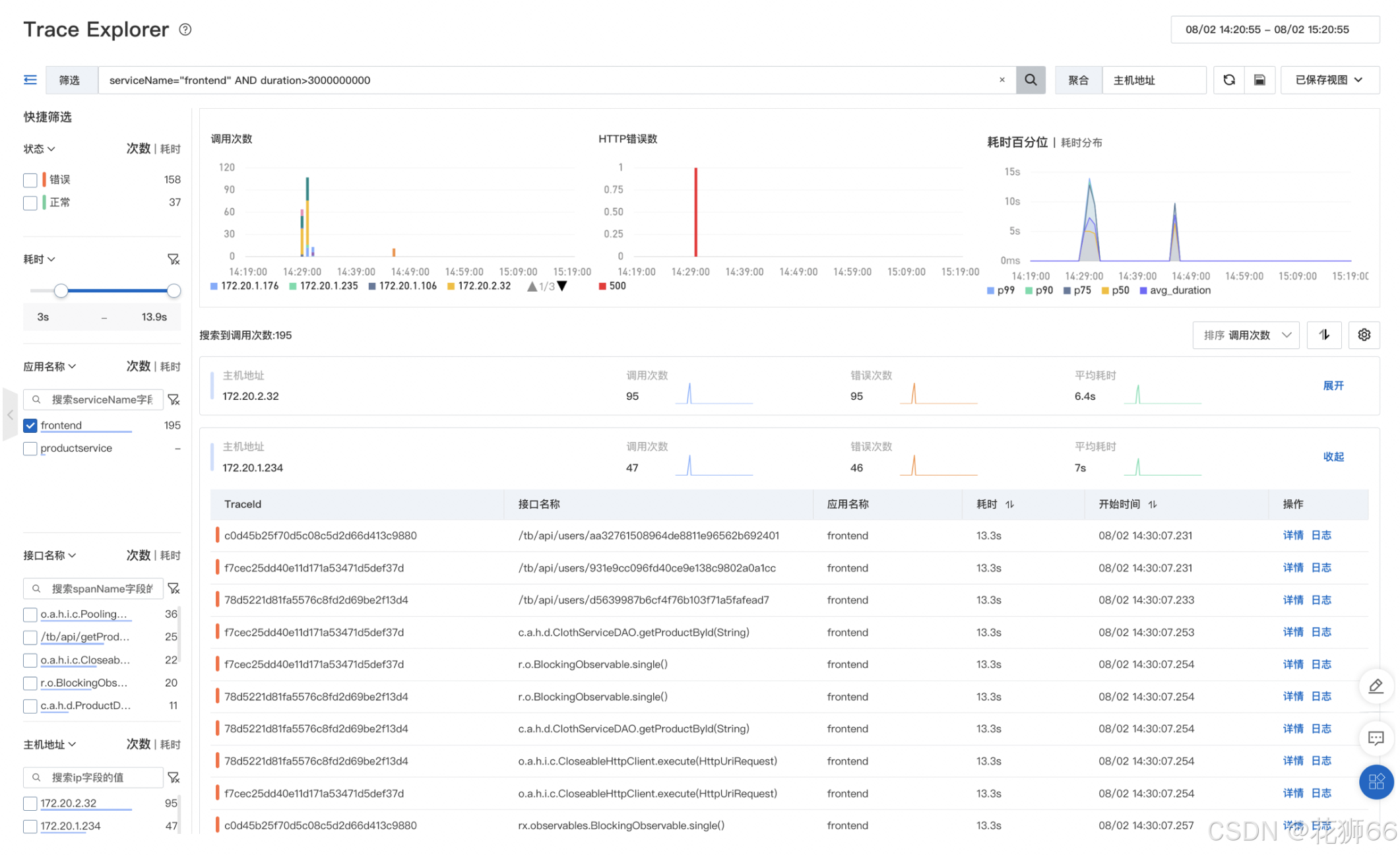
3、查看慢调用链路轨迹,初步定位关键路径与瓶颈点。
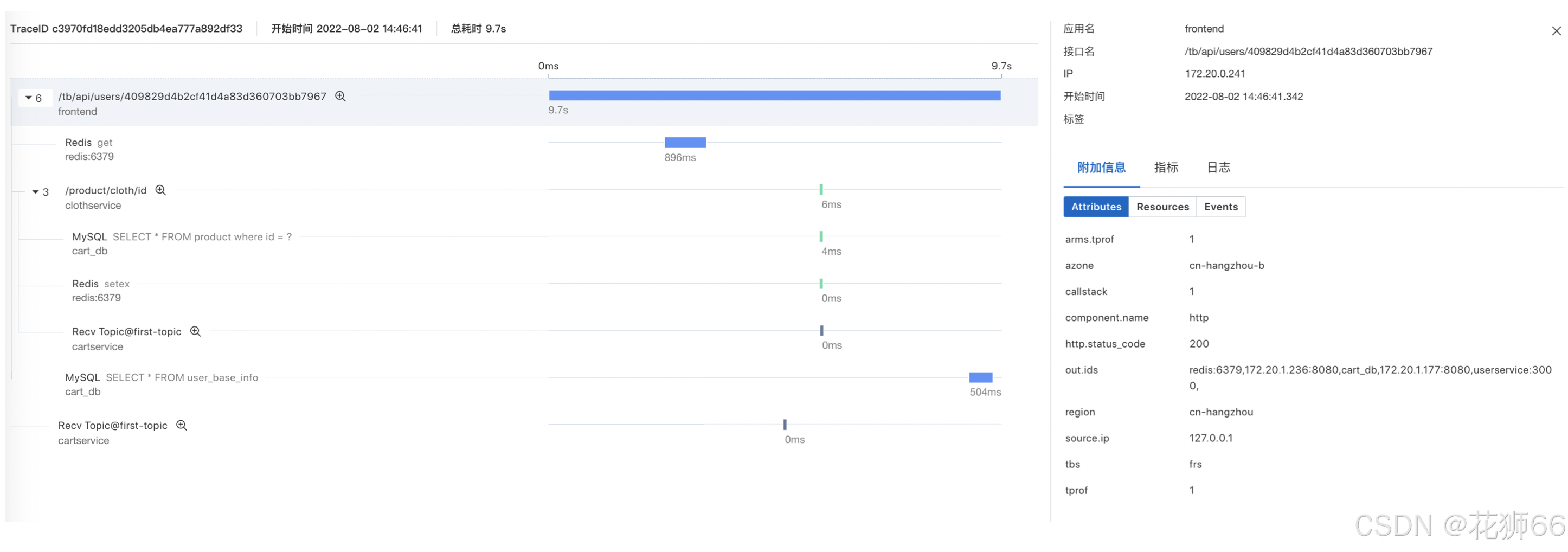
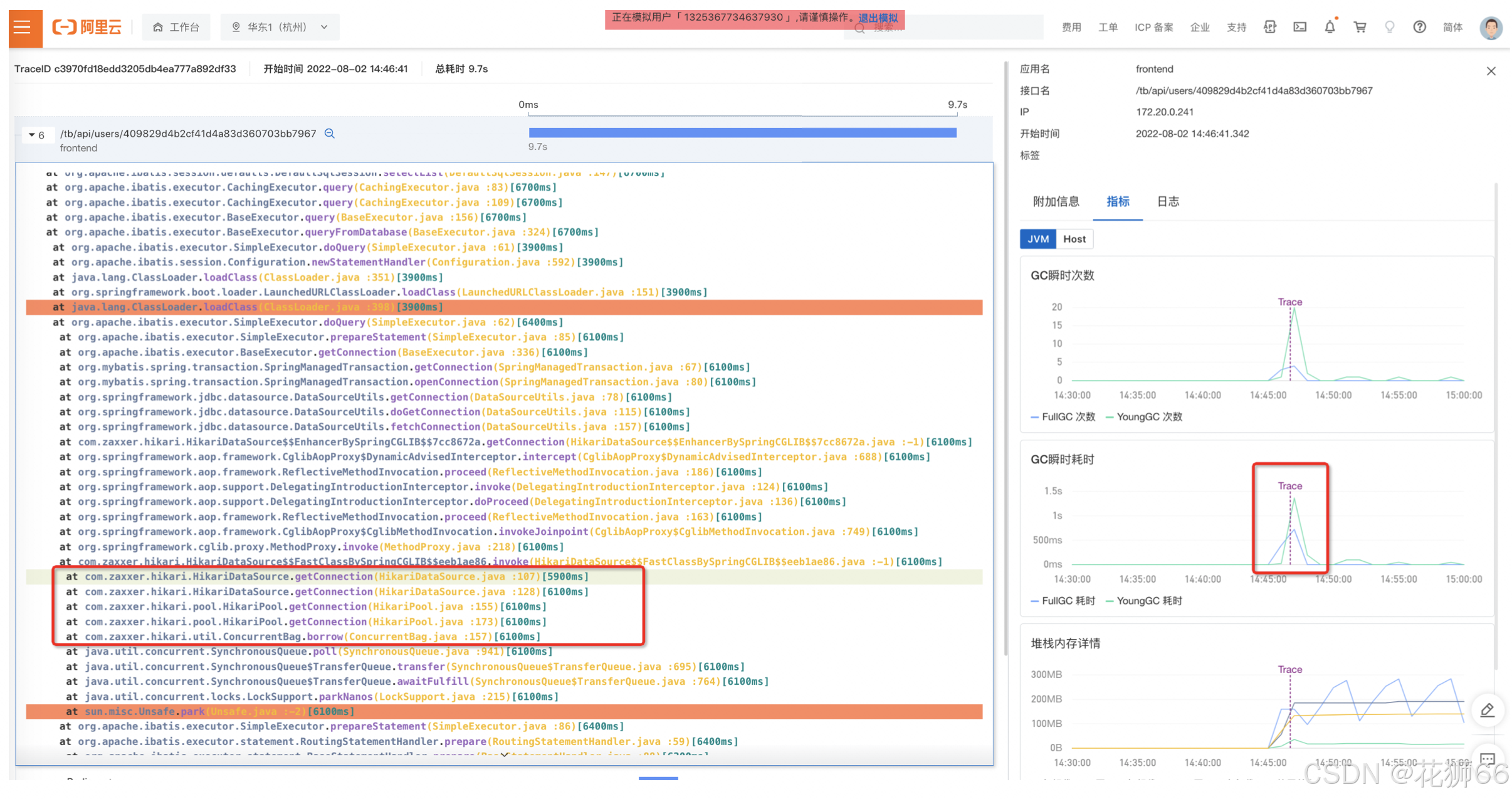
4、通过慢调用本地方法栈与关联 GC 指标等信息,定位慢调用根因: 有少量 FGC 现象,耗时主要消耗在 getConnection,数据库连接不足,需要调大连接数。
3.7 经典案例2 – 高CPU定位
1、通过 CPU 监控/告警 发现CPU异常飙升。
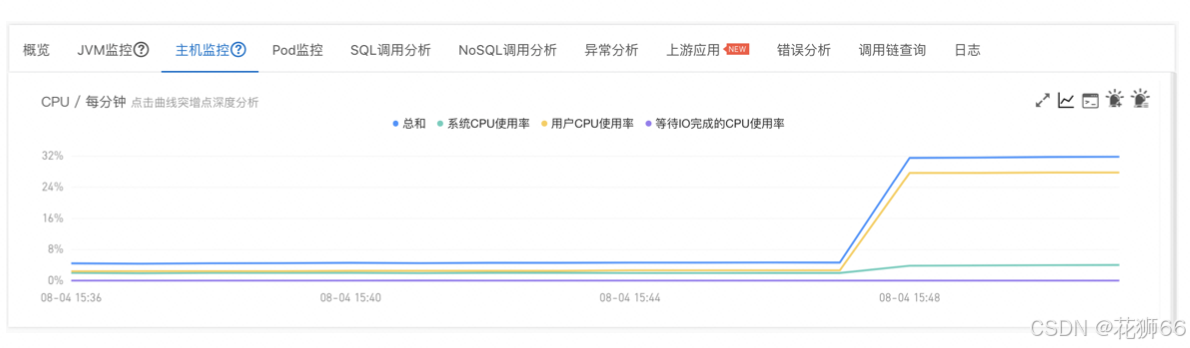
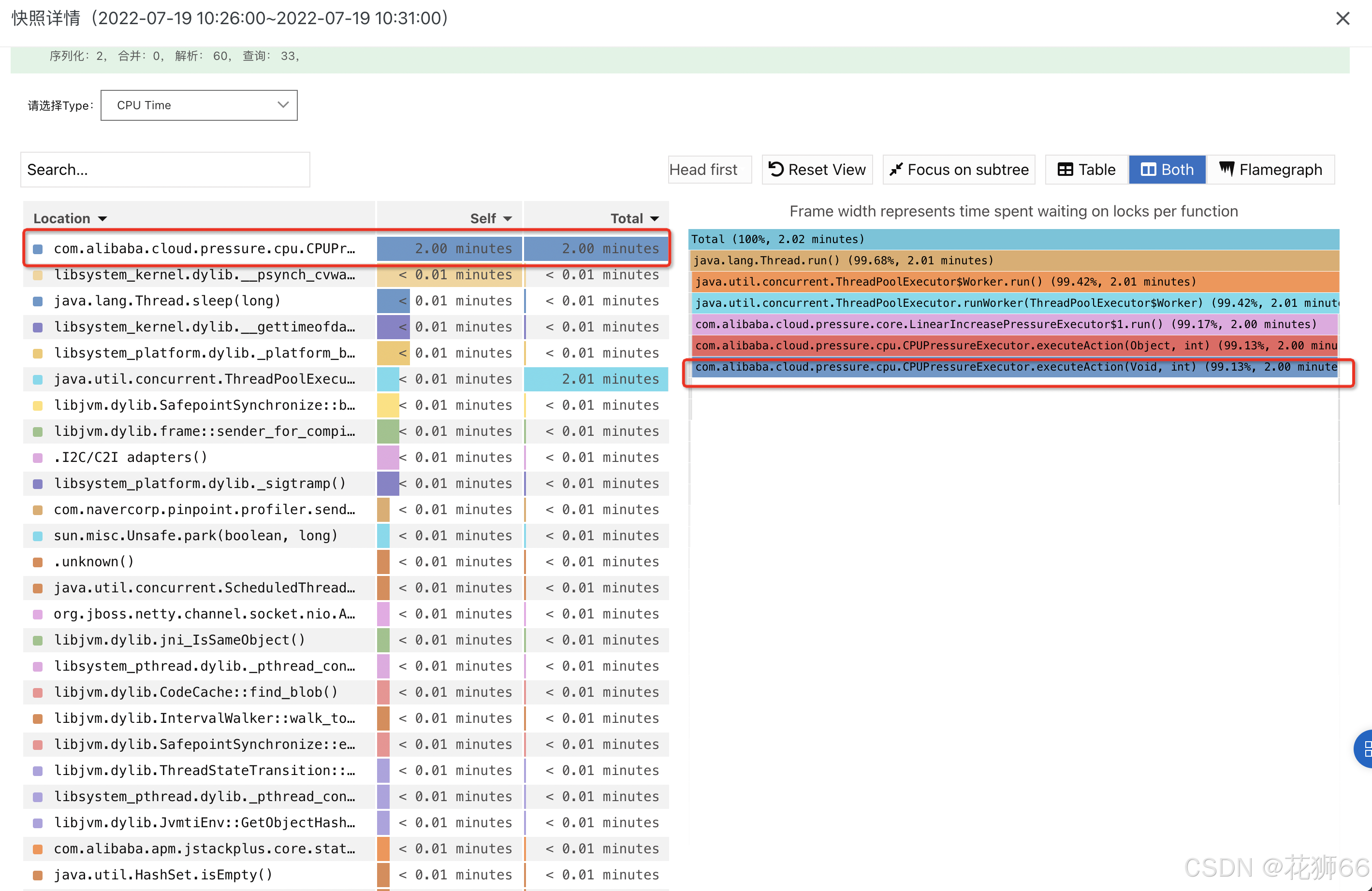
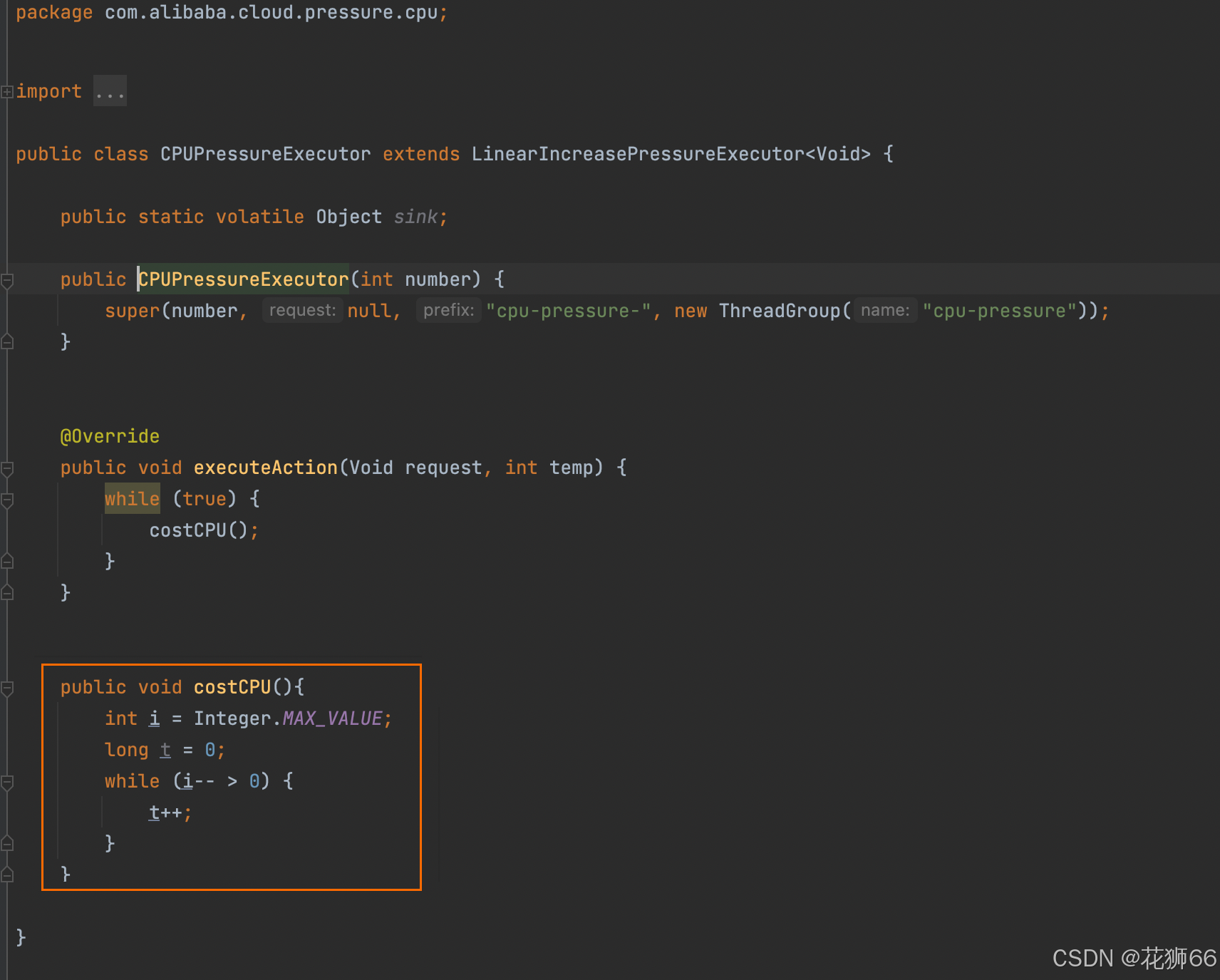
2、通过 ContinuousProfiling 分析相应时间段内的 CPU 占比火焰图, 定位消耗 CPU 99.7% 占比的方法是 CPUPressure.runBusiness()
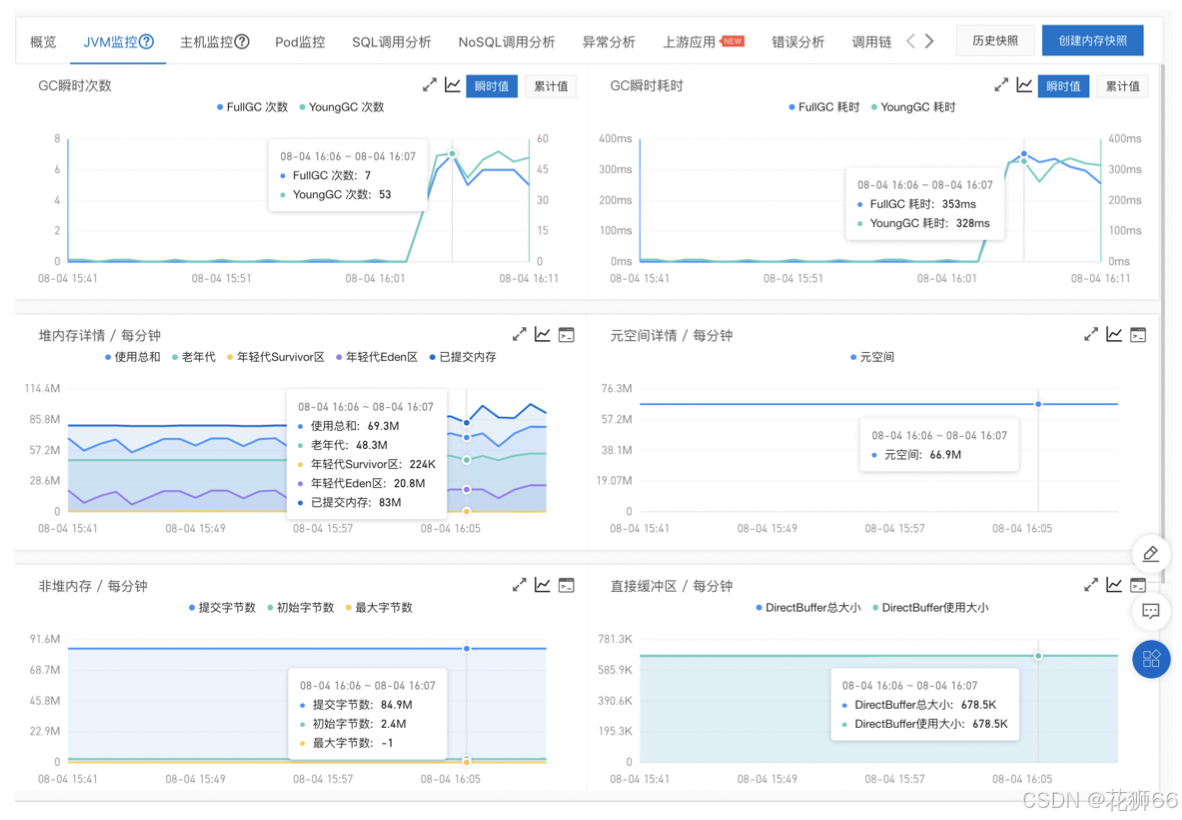
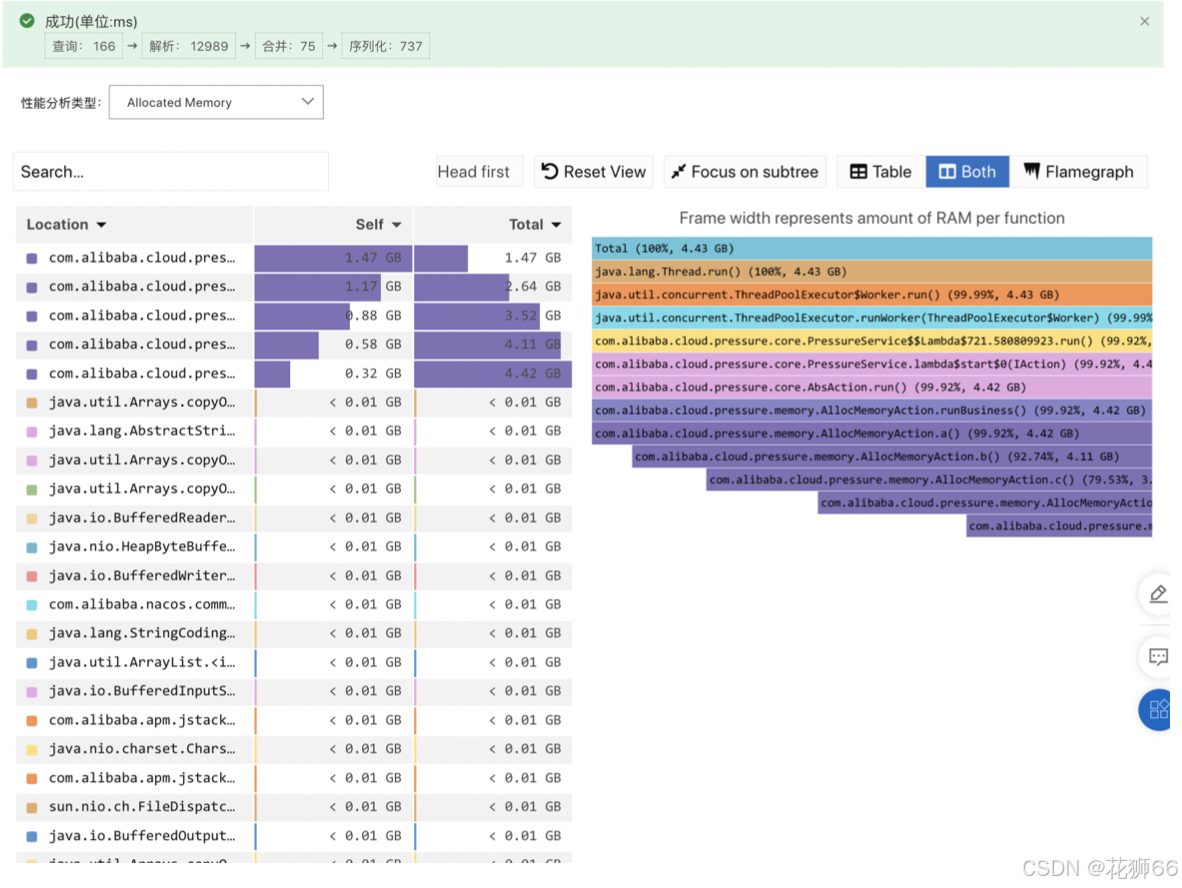
3.8 经典案例3 – 内存问题定位
1. 通过 JVM 监控/告警发现内存或 GC 异常, 分析新生代、老年代、Metaspace、DirectBuffer 等内存变化,未发现内存泄漏。
2、通过内存诊断分析一段时间的内存对象分配占比火焰图, 定位 99.92% 的内存是通过 AllocMemoryAction.runBusiness() 方法消耗的
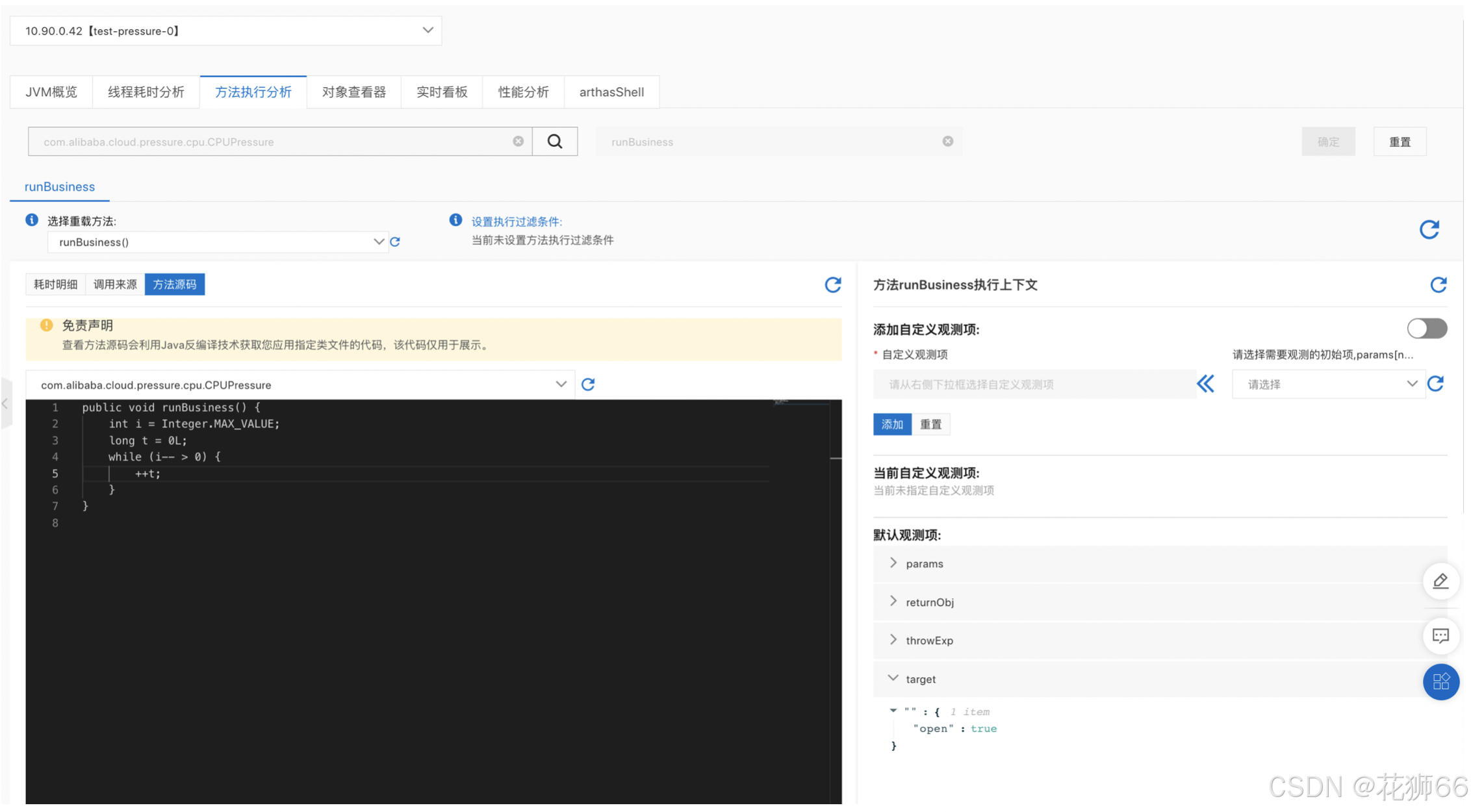
3.9 经典案例4 – 运行态疑难问题定位
通过 Arthas 白屏化查看在线代码运行情况,支持源码反编译、出入参拦截、方法栈耗时追踪、对象内存值查询等。快速定位本地调试与在线运行不一致等问题。
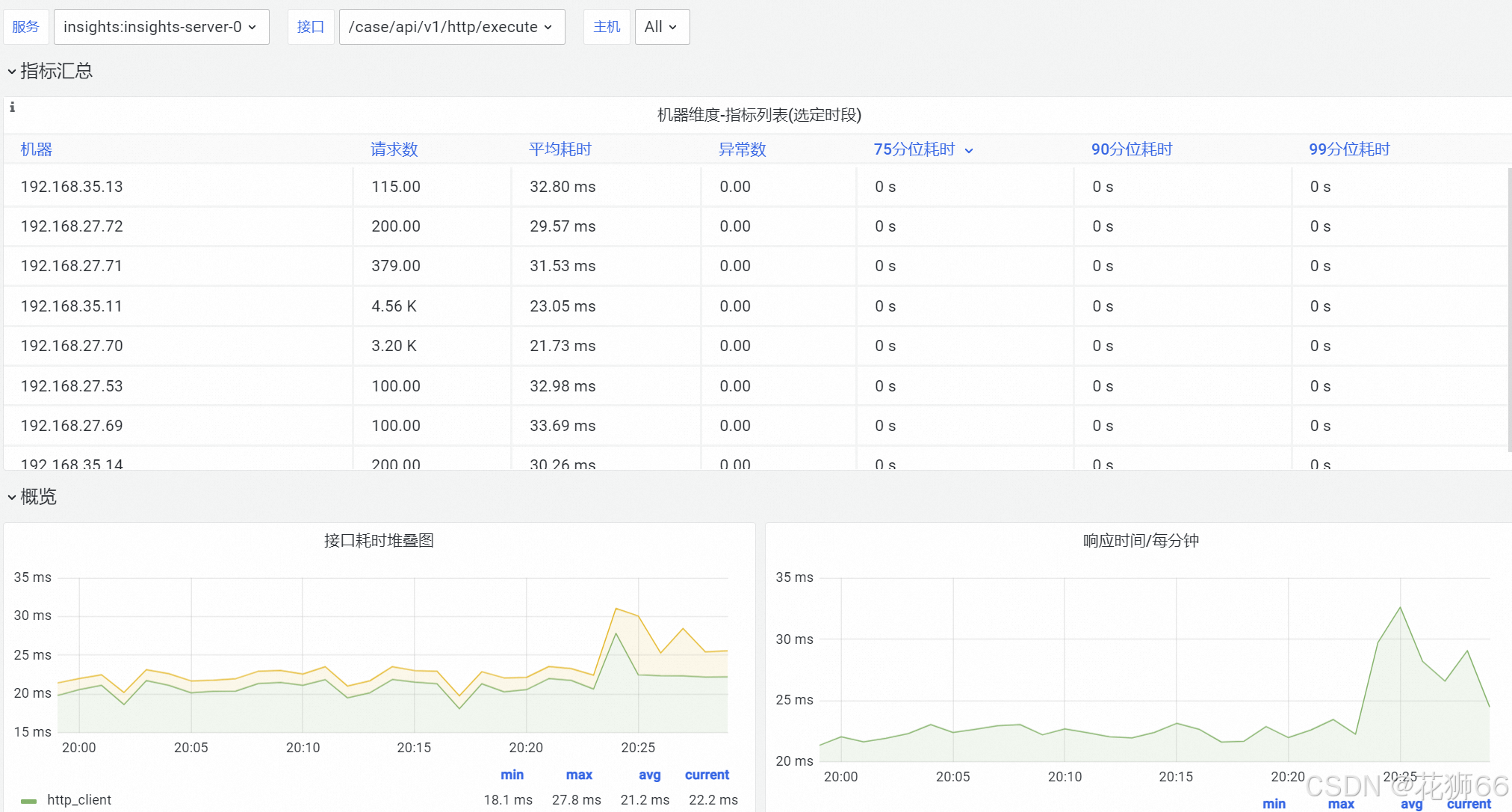
3.10 经典案例5 – 自定义大盘
1、来自Metrics和Logging的可观测数据,都在经过聚合计算后,汇入到了可观测监控Prometheus版,在Grafana中可以直接使用预置的大盘。
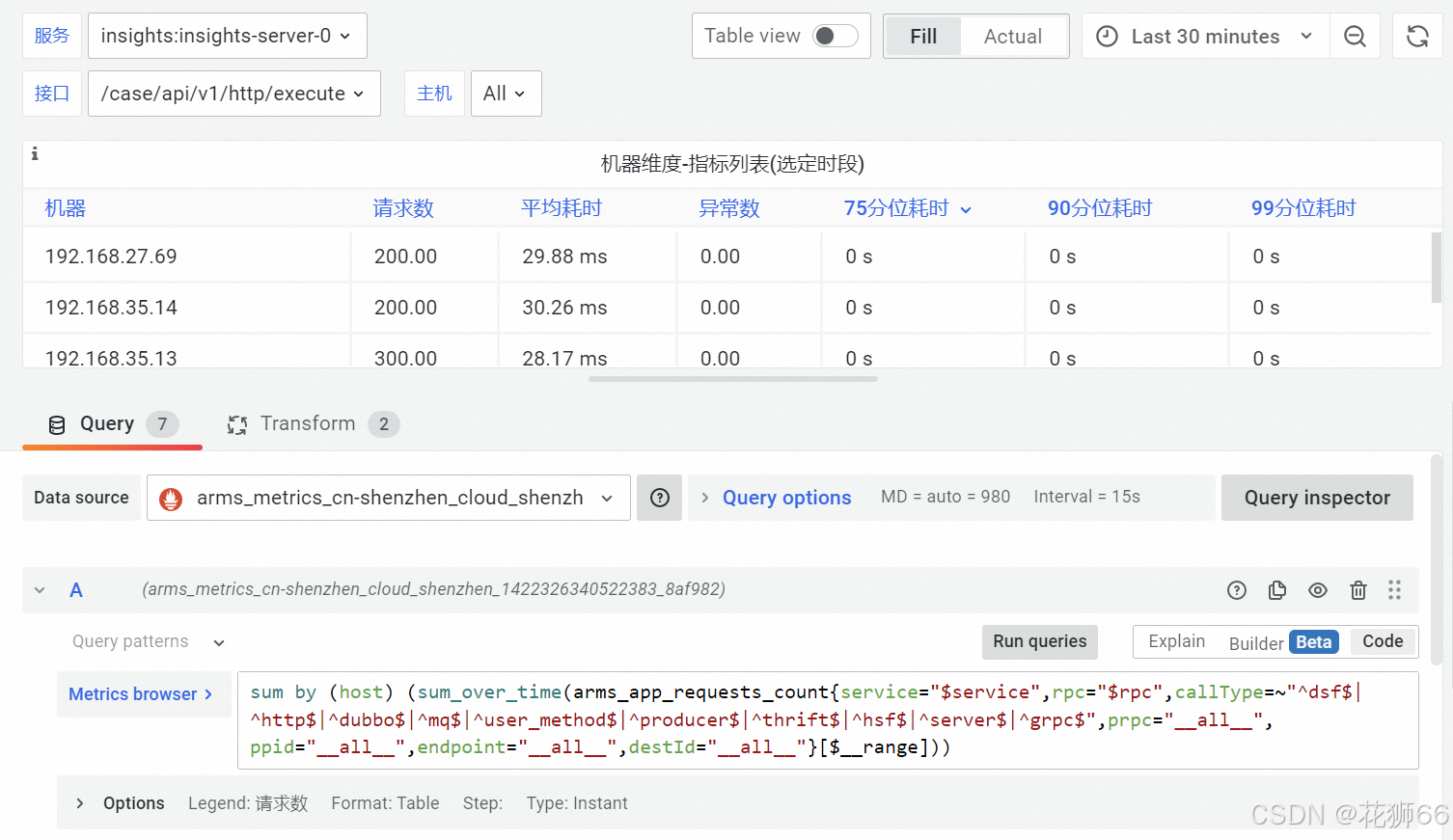
2、基于Grafana标准对大盘进行定制

3.11 经典案例6 – 日志服务Logtail采集日志失败的问题定位
使用Logtail采集日志后,如果预览页面为空或查询页面无数据,可以根据以下步骤进行排查:
1、确认日志文件是否有更新
- 如果下发Logtail配置后,日志文件无更新,则Logtail不会采集该文件
- 如果下发Logtail配置后,日志文件有更新,请执行下一步
2. 确认机器组心跳是否正常
- 如果心跳为FAIL,请参见如何排查Logtail机器组问题_日志服务(SLS)-阿里云帮助中心进行排查
- 如果心跳为OK,请执行下一步
3. 确认是否已创建Logtail配置
- 请务必确保Logtail配置中设置的日志路径与目标服务器上的日志文件匹配
4. 确认Logtail采集配置是否已应用到机器组
- 如果未应用到机器组,请参见在控制台上查看并配置机器组_日志服务(SLS)-阿里云帮助中心完成操作
- 如果已应用到机器组,请执行下一步
5. 查看采集错误
- 查看错误信息。具体操作,请参见如何查看Logtail采集错误信息_日志服务(SLS)-阿里云帮助中心
- 查看Logtail日志。查看路径见右表
- 确认是否存在用量超限。如果有大日志量或者大文件量的采集需求,可能需要修改Logtail的启动参数,以达到更高的日志采集吞吐量
总结
1、阿里云的消息队列Kafka版提供了高吞吐、可扩展的消息队列服务,适用于日志收集、监控数据聚合、流式数据处理等多种大数据场景。
2、系统架构包括Producer、Kafka Broker、Consumer Group和Zookeeper,具备双引擎支持以提升稳定性和兼容性,并支持秒级分区扩容以增强性能。
3、通过构建云原生可观测体系,利用日志服务SLS和应用实时监控服务ARMS等工具,实现了对系统运行状态的全面监控和智能分析,从而提高了系统的稳定性和故障响应效率。
4、这些工具和服务不仅提供了统一的数据存储、处理与分析能力,还支持多维度的数据采集和智能告警,有助于快速定位和解决诸如慢调用、高CPU使用率、内存问题等运行时难题。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 云计算之云原生(下)

发表评论 取消回复