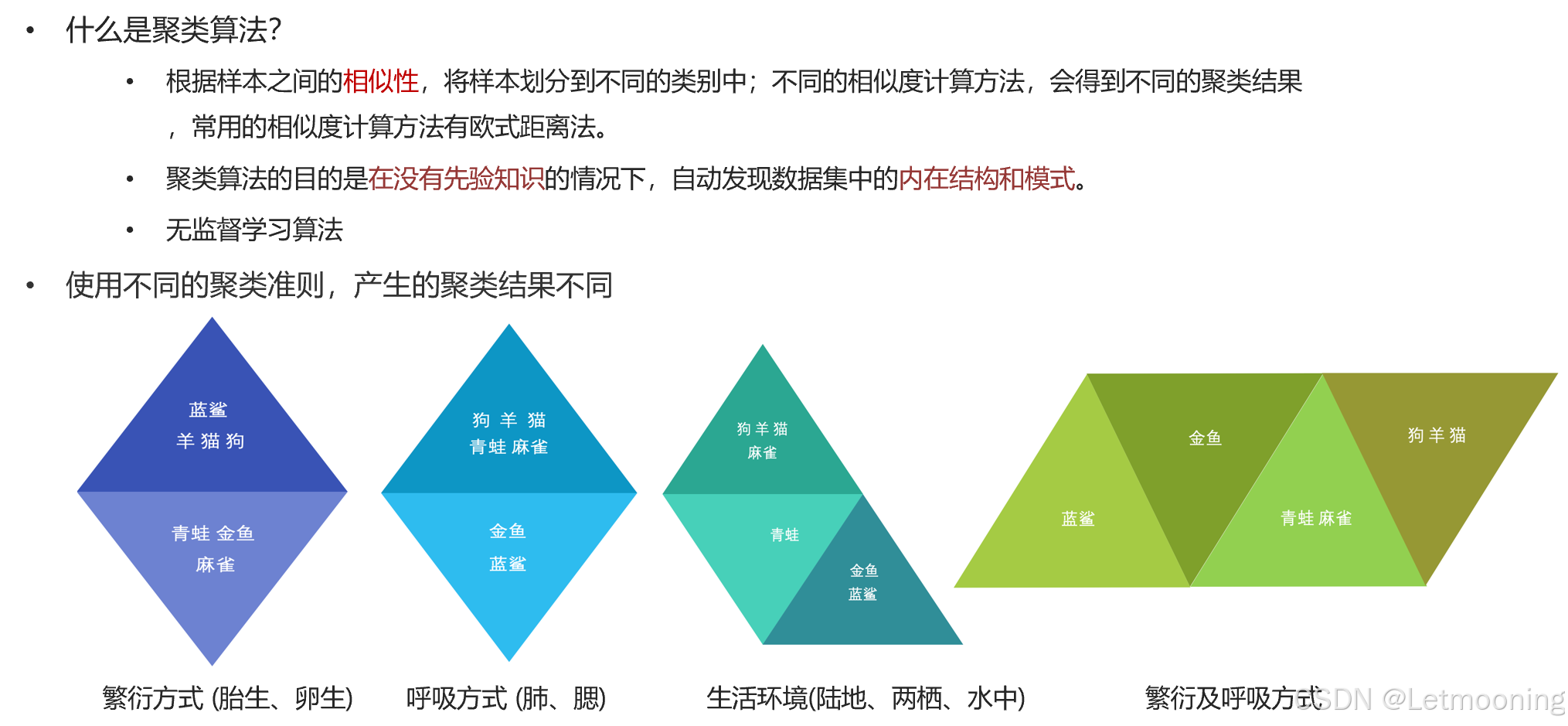
1 聚类算法简介
# 导包
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
# 构建数据
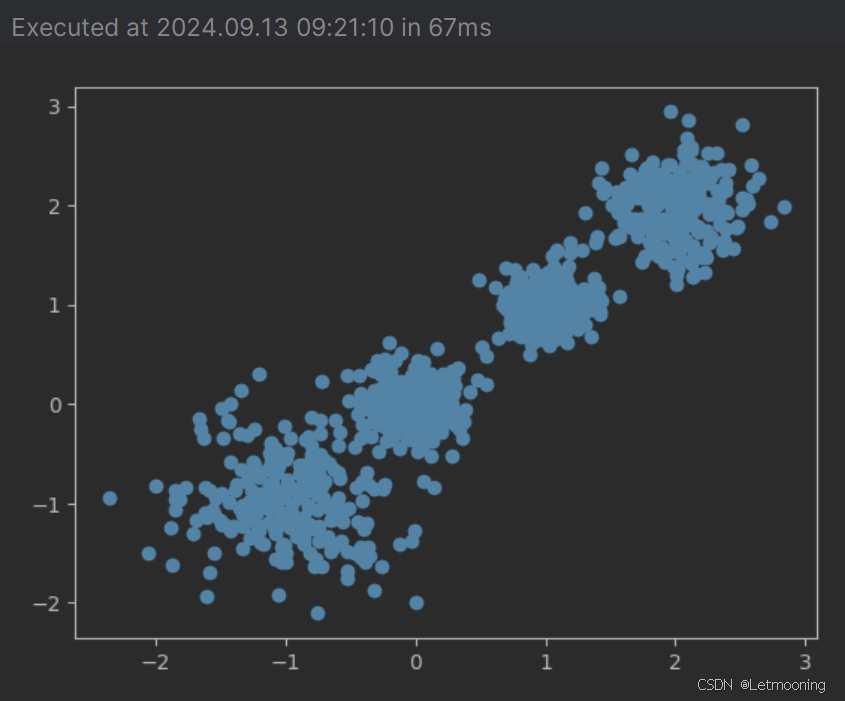
x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.3],random_state=22)
plt.scatter(x[:,0],x[:,1])
plt.show()
# 聚类
model=KMeans(n_clusters=3,random_state=22)
model.fit(x)
y_pred=model.predict(x)
# 可视化
plt.scatter(x[:,0],x[:,1],c=y_pred)
plt.show()
# 评估
print(calinski_harabasz_score(x,y_pred))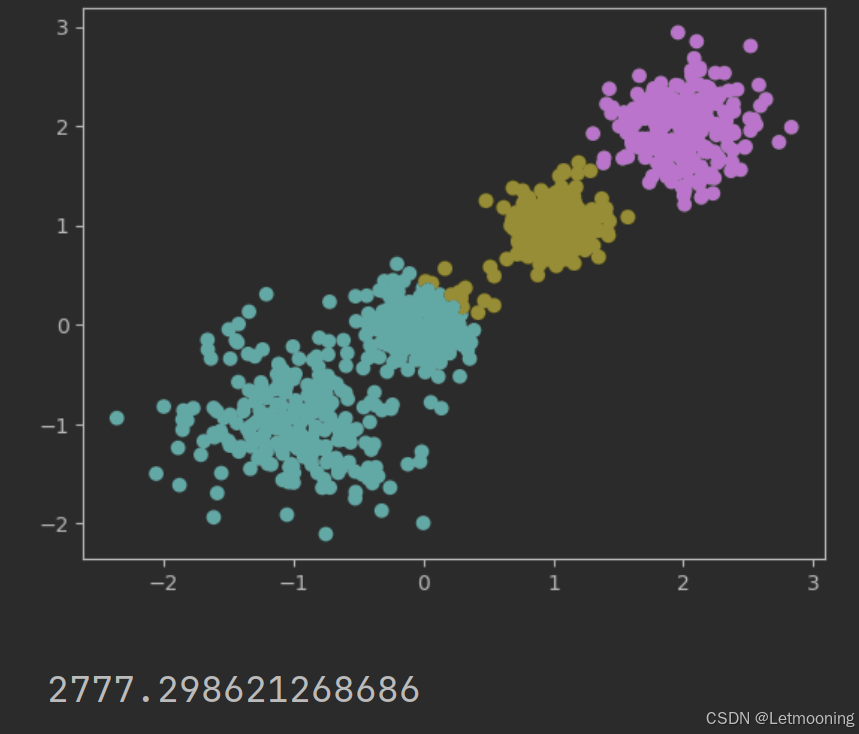
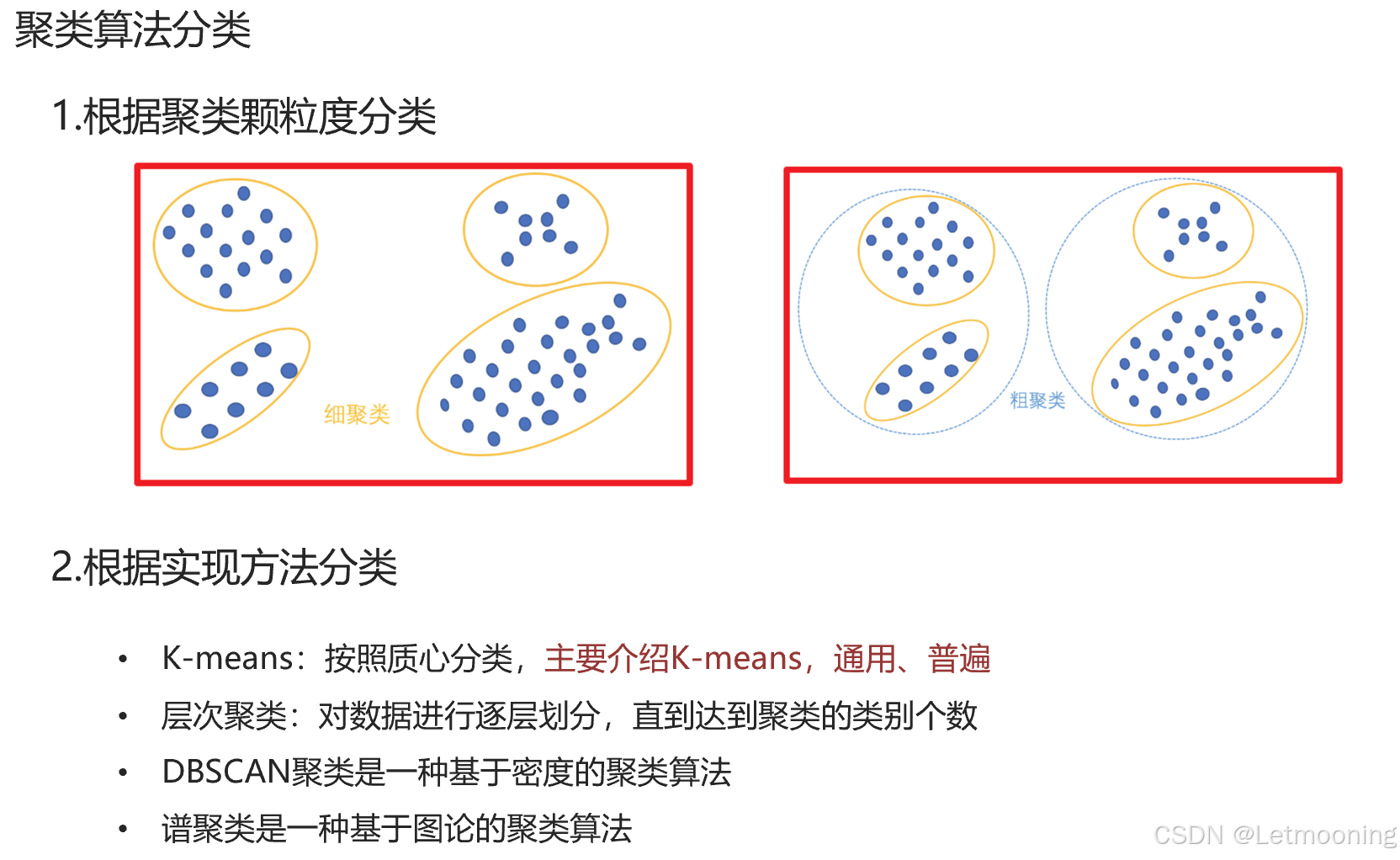
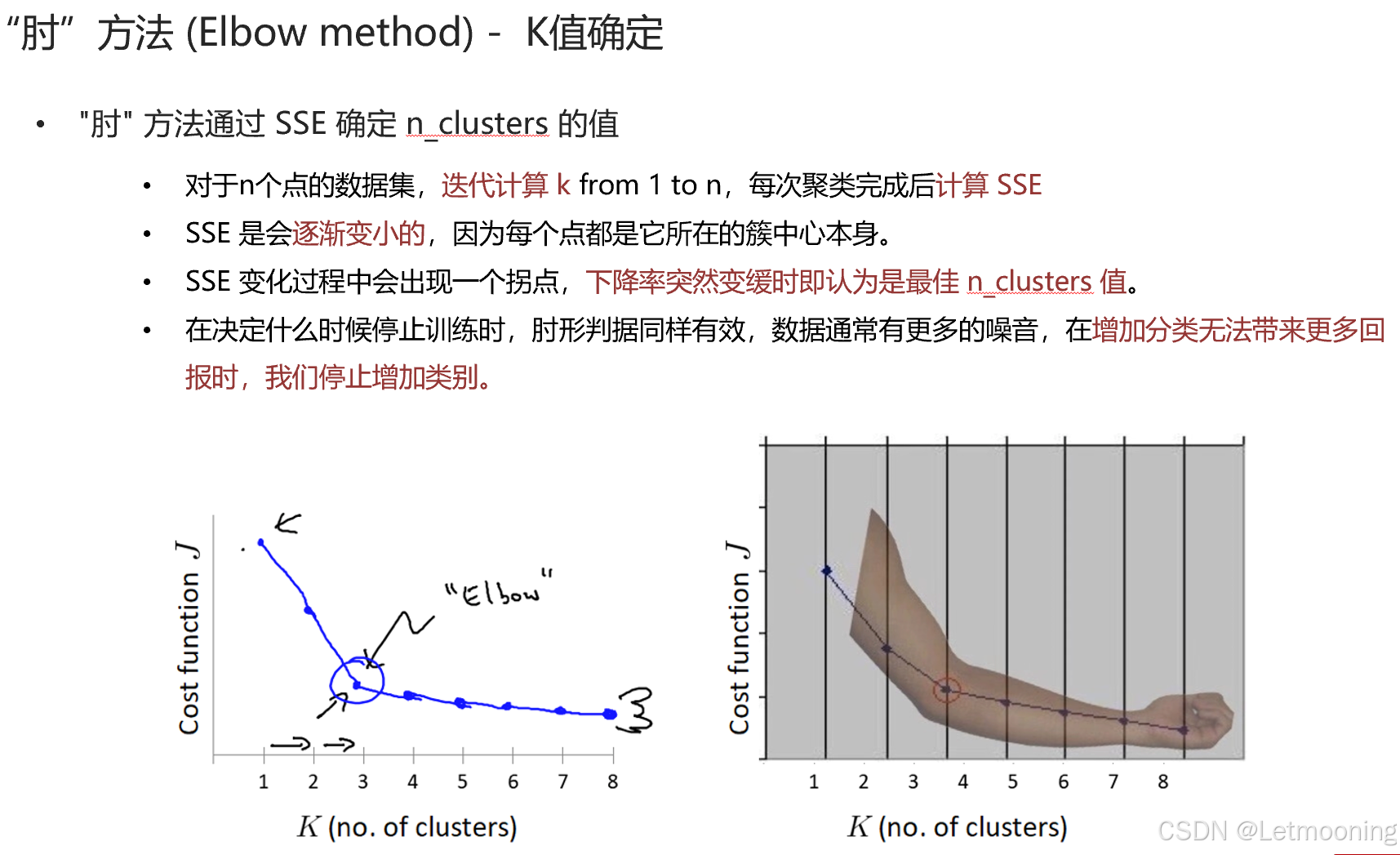
2 KMeans实现流程

3 模型评估方法
3.1 SSE聚类评估指标

import os
os.environ['OMP_NUM_THREADS'] = '1'
# 导包
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score
# 构建数据
x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.3],random_state=22)
sse=[]
# 计算不同K值下的SSE,来获取K值
for k in range(1,51):
km=KMeans(n_clusters=k,max_iter=100,random_state=22)
km.fit(x)
sse.append(km.inertia_)
plt.plot(range(1,51),sse)
plt.grid()
plt.show()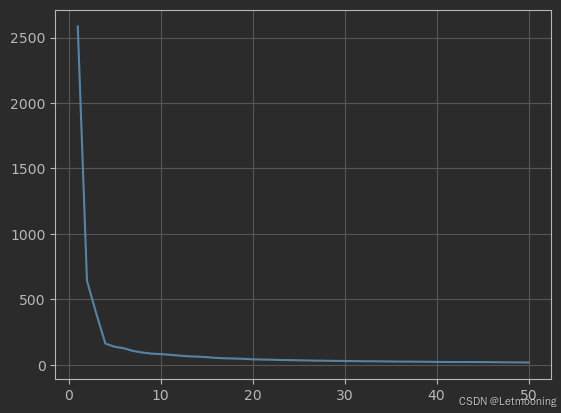
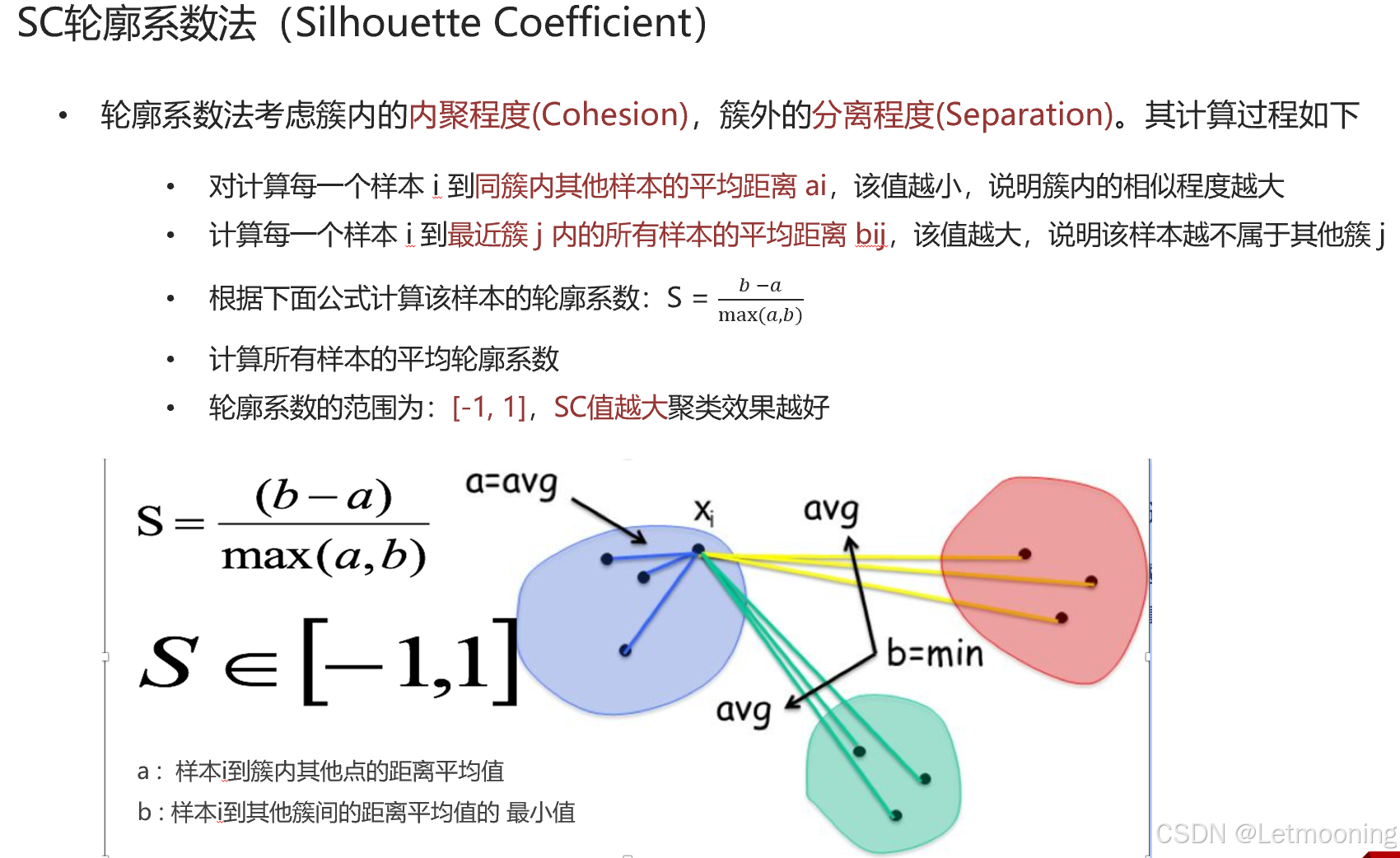
3.2 SC聚类评估指标
# 计算SC系数
import os
os.environ['OMP_NUM_THREADS'] = '1'
# 导包
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score,silhouette_score
# 构建数据
x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.3],random_state=22)
sc=[]
# 计算不同K值下的SC
for k in range(2,51):
km=KMeans(n_clusters=k,max_iter=100,random_state=22)
y_pred=km.fit_predict(x)
sc_=silhouette_score(x,y_pred)
sc.append(sc_)
plt.plot(range(2,51),sc)
plt.grid()
plt.show()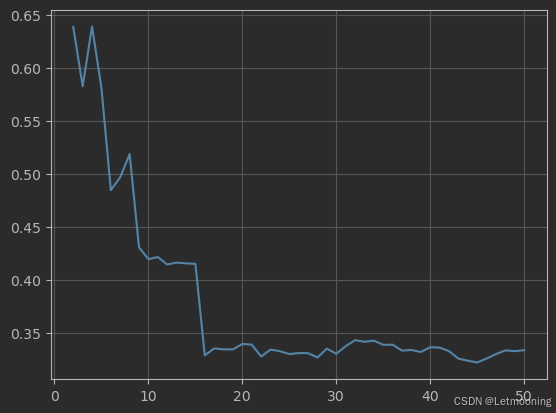
3.3 CH聚类评估指标

# 计算CH系数
import os
os.environ['OMP_NUM_THREADS'] = '1'
# 导包
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import calinski_harabasz_score,silhouette_score
# 构建数据
x,y=make_blobs(n_samples=1000,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.3],random_state=22)
ch=[]
# 计算不同K值下的CH
for k in range(2,51):
km=KMeans(n_clusters=k,max_iter=100,random_state=22)
y_pred=km.fit_predict(x)
ch_=calinski_harabasz_score(x,y_pred)
ch.append(ch_)
plt.plot(range(2,51),ch)
plt.grid()
plt.show()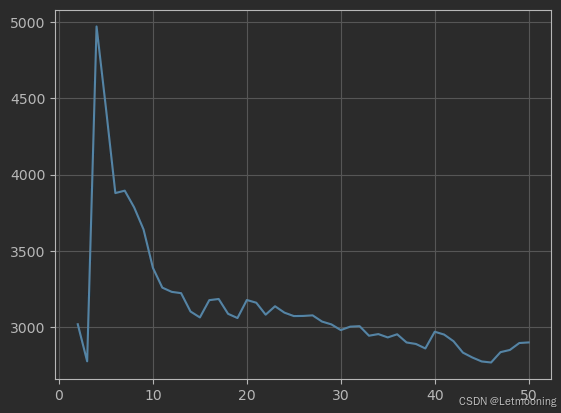
4 顾客数据聚类分析
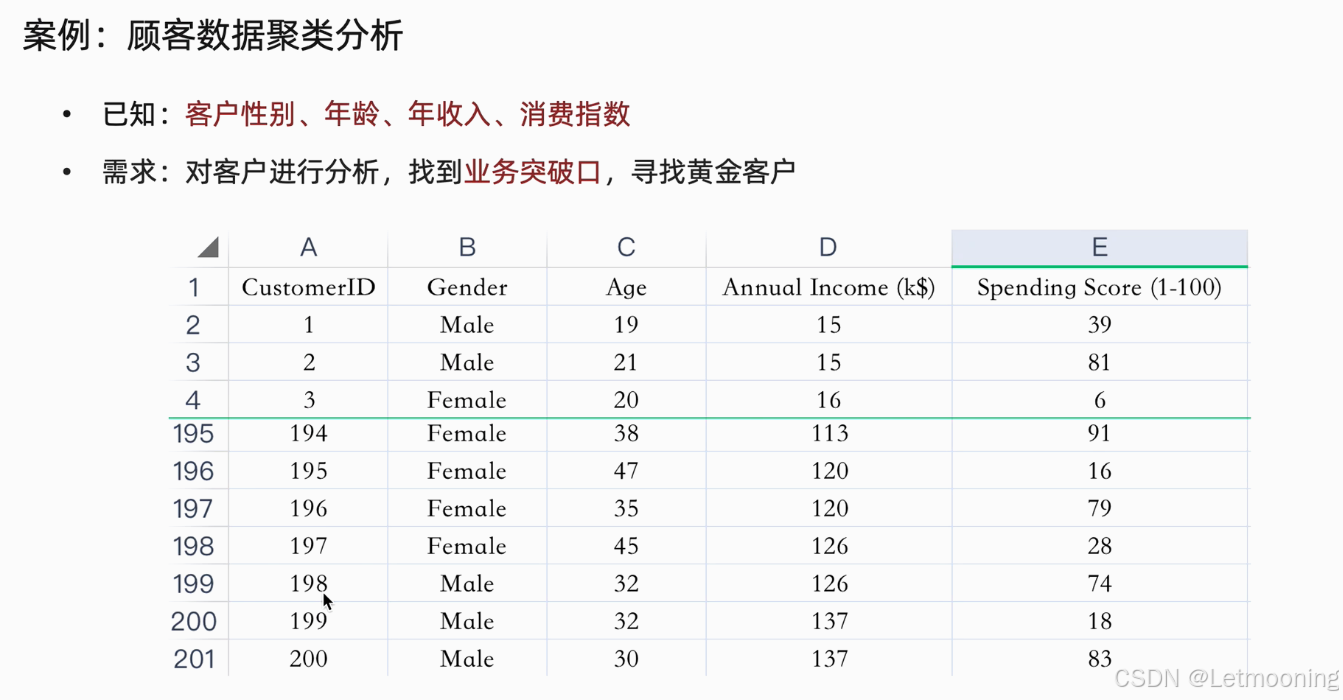
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score,calinski_harabasz_score
import matplotlib.pyplot as plt
# 读数据
data_df=pd.read_csv('data/customers.csv')
# 计算K值
x=data_df.iloc[:,[3,4]]
sse=[]
sc=[]
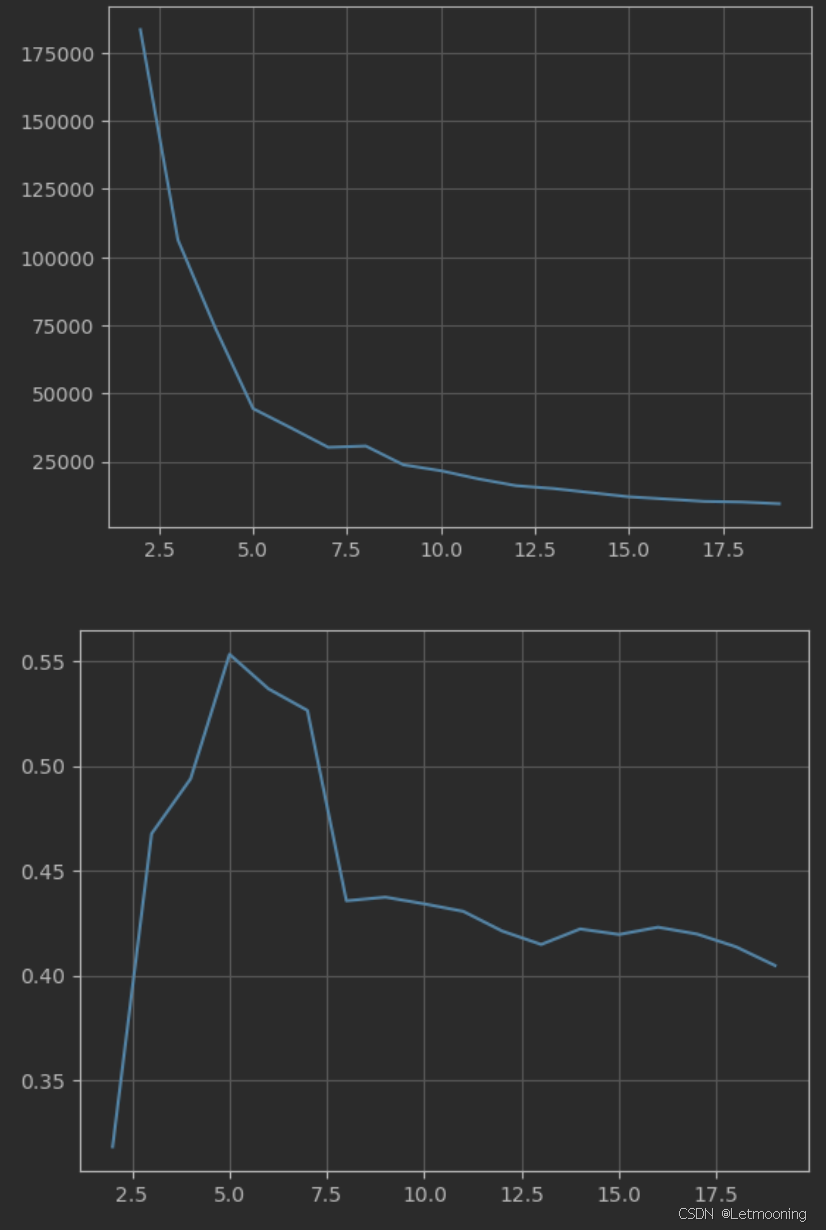
for i in range(2,20):
km=KMeans(n_clusters=i,max_iter=100,random_state=22)
y_pred=km.fit_predict(x)
sse.append(km.inertia_)
sc.append(silhouette_score(x,y_pred))
plt.plot(range(2,20),sse)
plt.grid()
plt.show()
plt.plot(range(2,20),sc)
plt.grid()
plt.show()
import pandas as pd
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
data_df=pd.read_csv('data/customers.csv')
x=data_df.iloc[:,[3,4]]
# 模型训练
km=KMeans(n_clusters=5)
y_kmeans=km.fit_predict(x)
# 可视化
plt.scatter(x.values[y_kmeans==0,0],x.values[y_kmeans==0,1])
plt.scatter(x.values[y_kmeans==1,0],x.values[y_kmeans==1,1])
plt.scatter(x.values[y_kmeans==2,0],x.values[y_kmeans==2,1])
plt.scatter(x.values[y_kmeans==3,0],x.values[y_kmeans==3,1])
plt.scatter(x.values[y_kmeans==4,0],x.values[y_kmeans==4,1])
plt.scatter(km.cluster_centers_[:,0],km.cluster_centers_[:,1])
plt.show()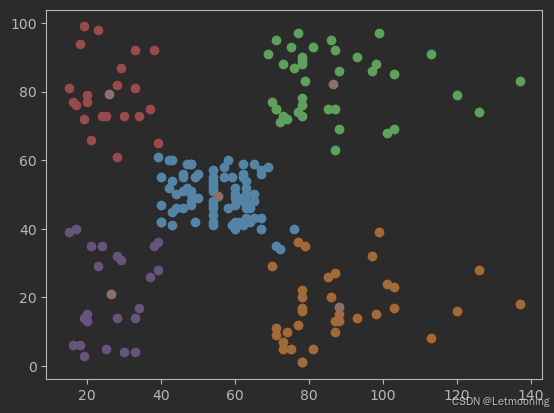
import seaborn as sns
# 设置图形风格
sns.set(style='whitegrid')
# 绘制聚类结果
plt.figure(figsize=(8,6))
plt.scatter(x.values[:,0],x.values[:,1],c=y_kmeans,s=50,cmap='viridis')
# 绘制聚类中心
plt.scatter(km.cluster_centers_[:,0],km.cluster_centers_[:,1],c='red',s=200,alpha=0.75,marker='X',label='Centers')
plt.title('KMeans Clustering Visualization')
plt.xlabel('Age')
plt.ylabel('Spending Score(1-100)')
plt.legend()
plt.show()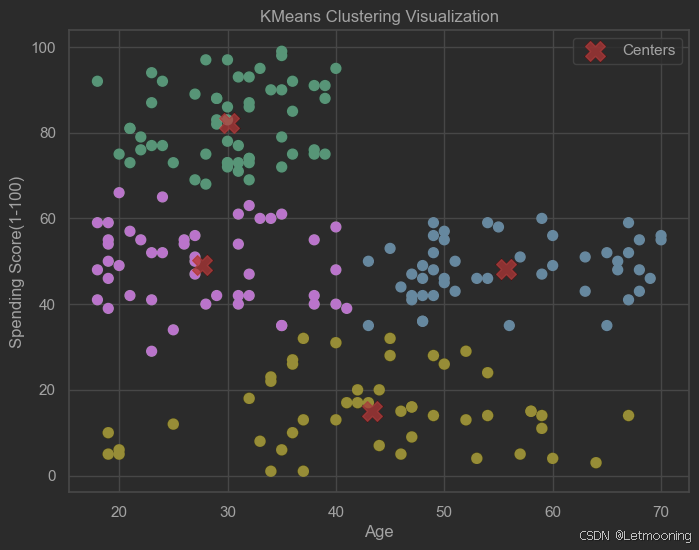
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [机器学习]聚类算法

发表评论 取消回复