文章目录
1. redis的string数据结构
参考链接:https://mp.weixin.qq.com/s/srkd73bS2n3mjIADLVg72A
redis 的 string 数据结构是 redis 中最基本的数据类型,它可以存储任何形式的数据,最大可以存储 512MB 的字符串。string 类型可以存储文本、数字和二进制数据等。
具有以下特性:
- 简单性:String 是最简单的类型,可以用来存储简单的键值对。
- 多样性:可以存储任意类型的数据,包括文本、数字、甚至是序列化后的对象。
- 原子性:对 String 的操作是原子性的,即在并发情况下操作串的安全性。
以下是一些与 String 相关的常用 Redis 命令:
- SET key value:设置指定 key 的值。
- GET key:获取指定 key 的值。
- DEL key:删除指定 key。
- EXISTS key:检查指定 key 是否存在。
- INCR key:将 key 的值加 1。
- DECR key:将 key 的值减 1。
- MSET key1 value1 key2 value2 …:同时设置多个 key-value 对。
- MGET key1 key2 …:同时获取多个 key 的值。
- SETEX key seconds value:设置 key 的值,同时设置过期时间(以秒为单位)。
xxxxxx:6379> SET person:1 '{"name": "Alice", "age": 30, "city": "New York"}'
OK
xxxxxx:6379> get person:1
"{\"name\": \"Alice\", \"age\": 30, \"city\": \"New York\"}"
xxxxxx:6379> exists person:1
(integer) 1
xxxxxx:6379> exists person:2
(integer) 0
xxxxxx:6379> set art:122 0
OK
xxxxxx:6379> incr art:122
(integer) 1
xxxxxx:6379> get art:122
"1"
xxxxxx:6379> decr art:122
(integer) 0
xxxxxx:6379> get art:122
"0"
xxxxxx:6379> mget person:1 art:122
1) "{\"name\": \"Alice\", \"age\": 30, \"city\": \"New York\"}"
2) "0"
xxxxxx:6379> SETEX config:site 600 '{"theme": "dark", "language": "en"}'
OK
xxxxxx:6379> mget person:1 art:122 config:site
1) "{\"name\": \"Alice\", \"age\": 30, \"city\": \"New York\"}"
2) "0"
3) "{\"theme\": \"dark\", \"language\": \"en\"}"
2. 常见的业务场景
2.1 缓存功能
string类型常用于缓存经常访问的数据,如数据库查询结果、网页内容等,以提高访问速度和降低数据库的压力。一般多是用于读多写少的场景。比如,商品的价格,描述等信息,用户的资料等信息。
案例讲解
背景
在商品系统中,商品的详细信息如描述、价格、库存等数据通常不会频繁变动,但会被频繁查询。每次用户访问商品详情时,都直接从数据库查询这些信息会导致不必要的数据库负载。
优势
- 快速数据访问:Redis作为内存数据库,提供极速的读写能力,大幅降低数据访问延迟,提升用户体验。
- 减轻数据库压力:缓存频繁访问的静态数据,显著减少数据库查询,从而保护数据库资源,延长数据库寿命。
- 高并发支持:Redis设计用于高并发环境,能够处理大量用户同时访问,保证系统在流量高峰时的稳定性。
- 灵活的缓存策略:易于实现缓存数据的更新和失效,结合适当的缓存过期和数据同步机制,确保数据的实时性和一致性。
解决方案
使用Redis String类型来缓存商品的静态信息。当商品信息更新时,相应的缓存也更新或失效。
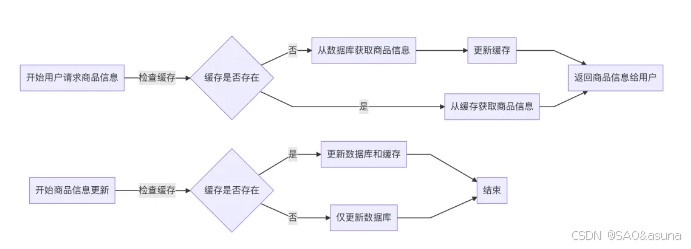
代码实现
package main
import (
"context"
"encoding/json"
"github.com/go-redis/redis/v8"
)
var (
rdb *redis.Client // 为了表现代码的完整性,这里省略了初始化代码
ctx context.Context // 为了表现代码的完整性,这里省略了初始化代码
)
// generateProductCacheKey generates the cache key for the product.
func generateProductCacheKey(productID string) string {
return "product:" + productID
}
// cacheProductInfo caches the product information in Redis.
func cacheProductInfo(productID string, productInfo map[string]interface{}) {
cacheKey := generateProductCacheKey(productID)
// 序列化商品信息为JSON格式
productJSON, _ := json.Marshal(productInfo)
// 将序列化后的商品信息存储到Redis===> set product:apple {"name":"apple","price":100, "description":"a nice apple"}
rdb.Set(ctx, cacheKey, string(productJSON), 0) // 0表示永不过期,实际使用时可以设置过期时间
}
// getProductInfoFromCache gets the product information from Redis.
func getProductInfoFromCache(productID string) (map[string]interface{}, error) {
cacheKey := generateProductCacheKey(productID)
// 从Redis获取商品信息
productJSON, err := rdb.Get(ctx, cacheKey).Result() // get product:apple
if err != nil {
return nil, err
}
if len(productJSON) == 0 {
// 未在缓存中找到商品信息, 需要从数据库中获取, 同时更新缓存
return nil, nil
}
// 反序列化JSON格式的商品信息
var productInfo map[string]interface{}
err = json.Unmarshal([]byte(productJSON), &productInfo)
if err != nil {
return nil, err
}
return productInfo, nil
}
func updateProductInfoAndCache(productID string, newProductInfo map[string]interface{}) {
// 更新数据库中的商品信息
// 更新Redis缓存中的商品信息
cacheProductInfo(productID, newProductInfo)
}
在日常实践中,感觉这里还是会有一点小问题:
- 如果是在商品信息插入,对于一个新商品可能缓存肯定是不存在的,如果某一个商城大量上新新产品,这个时候如果流量大量进来,是否会造成缓存击穿的情况?因此对于这种插入情况多基本没更新的时候,上面的流程可能有点问题。
- 在用户查询商品信息的时候,如果存在大量缓存失败的情况,也会导致数据库崩溃的情况,所以在日常实践中,如果在redis中查询不到,那可以直接返回。因此在写入的时候需要双写;且要异步数据同步。定义一个定时任务,每隔一段时间将数据库的信息增量同步到redis,一天全量同步一次。商品信息插入的时候双写。
package main
import (
"context"
"encoding/json"
"fmt"
"github.com/go-redis/redis/v8"
)
var (
rdb *redis.Client // 为了表现代码的完整性,这里省略了初始化代码
ctx context.Context // 为了表现代码的完整性,这里省略了初始化代码
)
// generateProductCacheKey generates the cache key for the product.
func generateProductCacheKey(productID string) string {
return "product:" + productID
}
// cacheProductInfo caches the product information in Redis.
func cacheProductInfo(productID string, productInfo map[string]interface{}) {
cacheKey := generateProductCacheKey(productID)
// 序列化商品信息为JSON格式
productJSON, _ := json.Marshal(productInfo)
// 将序列化后的商品信息存储到Redis===> set product:apple {"name":"apple","price":100, "description":"a nice apple"}
rdb.Set(ctx, cacheKey, string(productJSON), 0) // 0表示永不过期,实际使用时可以设置过期时间
}
// getProductInfoFromCache gets the product information from Redis.
func getProductInfoFromCache(productID string) (map[string]interface{}, error) {
cacheKey := generateProductCacheKey(productID)
// 从Redis获取商品信息
productJSON, err := rdb.Get(ctx, cacheKey).Result() // get product:apple
if err != nil {
return nil, err
}
// 反序列化JSON格式的商品信息
var productInfo map[string]interface{}
err = json.Unmarshal([]byte(productJSON), &productInfo)
if err != nil {
return nil, err
}
return productInfo, nil
}
func updateProductInfoAndCache(productID string, newProductInfo map[string]interface{}) {
// 三个步骤如果有任何一个步骤失败,都需要回滚
// 更新数据库中的商品信息
// 更新Redis缓存中的商品信息
cacheProductInfo(productID, newProductInfo)
// 查一遍缓存,确保缓存中的商品信息已经更新
info, err := getProductInfoFromCache(productID)
if err != nil {
// 处理错误
}
// 处理info
fmt.Printf("product info: %v\n", info)
}
// 补充一个定时任务,可以使用crontab, 方便管理也可以使用airflow等工具
2.2 计数器
利用INCR和DECR命令,String类型可以作为计数器使用,适用于统计如网页访问量、商品库存数量等 。
案例讲解
背景
对于文章的浏览量的统计,每篇博客文章都有一个唯一的标识符(例如,文章ID)。每次文章被访问时,文章ID对应的浏览次数在Redis中递增。可以定期将浏览次数同步到数据库,用于历史数据分析。
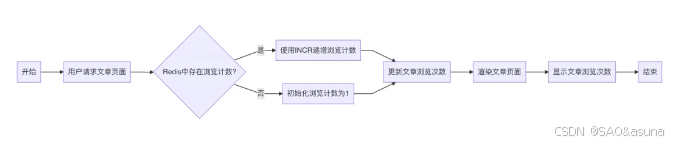
优势
- 实时性:能够实时更新和获取文章的浏览次数。
- 高性能:Redis的原子操作保证了高并发场景下的计数准确性。
解决方案
通过Redis实现对博客文章浏览次数的原子性递增和检索,以优化数据库访问并实时更新文章的浏览统计信息。
代码实现
package main
import (
"context"
"errors"
"fmt"
"github.com/go-redis/redis/v8"
"log"
"strconv"
)
var (
rdb *redis.Client // 为了表现代码的完整性,这里省略了初始化代码
ctx context.Context // 为了表现代码的完整性,这里省略了初始化代码
)
// recordArticleView 记录文章浏览次数
func recordArticleView(articleID string) {
res, err := rdb.Incr(ctx, articleID).Result()
if err != nil {
// 如果发生错误,记录错误日志
log.Printf("Error incrementing view count for article %s: %v", articleID, err)
return
}
// 可选:记录浏览次数到日志或进行其他业务处理
fmt.Printf("Article %s has been viewed %d times\n", articleID, res)
}
// getArticleViewCount 从Redis获取文章的浏览次数
func getArticleViewCount(articleID string) (int, error) {
// 从Redis获取文章的浏览次数
viewCount, err := rdb.Get(ctx, articleID).Result()
if err != nil {
if errors.Is(err, redis.Nil) {
// 如果文章ID在Redis中不存在,可以认为浏览次数为0
return 0, nil
} else {
// 如果发生错误,记录错误日志
log.Printf("Error getting view count for article %s: %v", articleID, err)
return 0, err
}
}
// 将浏览次数从字符串转换为整数
count, err := strconv.Atoi(viewCount)
if err != nil {
log.Printf("Error converting view count to integer for article %s: %v", articleID, err)
return 0, err
}
return count, nil
}
// renderArticlePage 渲染文章页面,并显示浏览次数
func renderArticlePage(articleID string) {
// 在渲染文章页面之前,记录浏览次数
recordArticleView(articleID)
// 获取文章浏览次数
viewCount, err := getArticleViewCount(articleID)
if err != nil {
// 处理错误,例如设置浏览次数为0或跳过错误
viewCount = 0
}
log.Printf("Rendering article %s with view count %d\n", articleID, viewCount)
}
2.3 分布式锁
分布式锁:通过SETNX命令(仅当键不存在时设置值),String类型可以实现分布式锁,保证在分布式系统中的互斥访问 。
案例讲解
背景
在分布式系统中,如电商的秒杀活动或库存管理,需要确保同一时间只有一个进程或线程可以修改共享资源,以避免数据不一致的问题。

优势
- 互斥性:确保同一时间只有一个进程可以访问共享资源,防止数据竞争和冲突。
- 高可用性:分布式锁能够在节点故障或网络分区的情况下仍能正常工作,具备自动故障转移和恢复的能力。
- 可重入性:支持同一个进程或线程多次获取同一个锁,避免死锁的发生。
- 性能开销:相比于其他分布式协调服务,基于Redis的分布式锁实现简单且性能开销较小。
解决方案
使用Redis的SETNX命令实现分布式锁的获取和释放,通过Lua脚本确保释放锁时的原子性,并在执行业务逻辑前尝试获取锁,业务逻辑执行完毕后确保释放锁,从而保证在分布式系统中对共享资源的安全访问。
代码实现
package main
import (
"context"
"github.com/go-redis/redis/v8"
"log"
"strconv"
"time"
)
var (
rdb *redis.Client // 为了表现代码的完整性,这里省略了初始化代码
ctx context.Context // 为了表现代码的完整性,这里省略了初始化代码
)
// 尝试获取分布式锁
func tryGetDistributedLock(lockKey string, val string, expireTime int) bool {
// 使用SET命令结合NX和PX参数尝试获取锁
// NX表示如果key不存在则可以设置成功
// PX指定锁的超时时间(毫秒)
// 这里的val是一个随机值,用于在释放锁时验证锁是否属于当前进程
result, err := rdb.SetNX(ctx, lockKey, val, time.Duration(expireTime)*time.Millisecond).Result()
if err != nil {
// 记录错误,例如:日志记录
log.Printf("Error trying to get distributed lock for key %s: %v", lockKey, err)
return false
}
// 如果result为1,则表示获取锁成功,result为0表示锁已被其他进程持有
return result
}
// 释放分布式锁, 这里的val是一个随机值,用于在释放锁时验证锁是否属于当前进程
func releaseDistributedLock(lockKey string, val string) {
// 使用Lua脚本来确保释放锁的操作是原子性的
script := `
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
`
// 执行Lua脚本
result, err := rdb.Eval(ctx, script, []string{lockKey}, val).Result()
if err != nil {
// 记录错误
log.Printf("Error releasing distributed lock for key %s: %v", lockKey, err)
}
// 如果result为1,则表示锁被成功释放,如果为0,则表示锁可能已经释放或不属于当前进程
if result == int64(0) {
log.Printf("Failed to release the lock, it might have been released by others or expired")
}
}
// 执行业务逻辑,使用分布式锁来保证业务逻辑的原子性
func executeBusinessLogic(lockKey string) {
val := generateRandomValue() // 生成一个随机值,作为锁的值
if tryGetDistributedLock(lockKey, val, 30000) { // 尝试获取锁,30秒超时
defer releaseDistributedLock(lockKey, val) // 无论业务逻辑是否成功执行,都释放锁
// 执行具体的业务逻辑
// ...
} else {
// 未能获取锁,处理重试逻辑或返回错误
// ...
}
}
// generateRandomValue 生成一个随机值作为锁的唯一标识
func generateRandomValue() string {
return strconv.FormatInt(time.Now().UnixNano(), 10)
}
2.4 限流
限流:使用EXPIRE命令,结合INCR操作,可以实现API的限流功能,防止系统被过度访问
案例讲解
背景
一个在线视频平台提供了一个API,用于获取视频的元数据。在高流量事件(如新电影发布)期间,这个API可能会收到大量并发请求,这可能导致后端服务压力过大,甚至崩溃。
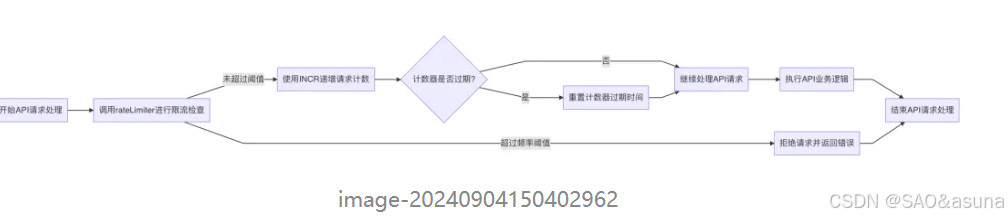
优势
- 稳定性保障:通过限流,可以防止系统在高负载下崩溃,确保核心服务的稳定性。
- 服务公平性:限流可以保证不同用户和客户端在高并发环境下公平地使用服务。
- 防止滥用:限制API的调用频率,可以防止恶意用户或爬虫对服务进行滥用。
解决方案
- 请求计数:每次API请求时,使用INCR命令对特定的key进行递增操作。
- 设置过期时间:使用EXPIRE命令为计数key设置一个过期时间,过期时间取决于限流的时间窗口(例如1秒)。
- 检查请求频率:如果请求计数超过设定的阈值(例如每秒100次),则拒绝新的请求或进行排队。
代码实现
package main
import (
"context"
"github.com/go-redis/redis/v8"
"log"
"time"
)
var (
rdb *redis.Client // 为了表现代码的完整性,这里省略了初始化代码
ctx context.Context // 为了表现代码的完整性,这里省略了初始化代码
)
// 伪代码:API限流器
func rateLimiter(apiKey string, threshold int, timeWindow int) bool {
currentCount, err := rdb.Incr(ctx, apiKey).Result()
if err != nil {
log.Printf("Error incrementing API key %s: %v", apiKey, err)
return false
}
// 如果当前计数超过阈值,则拒绝请求
if int(currentCount) > threshold {
return false
}
// 重置计数器的过期时间
_, err = rdb.Expire(ctx, apiKey, time.Duration(timeWindow)).Result()
if err != nil {
log.Printf("Error resetting expire time for API key %s: %v", apiKey, err)
return false
}
return true
}
// 在API处理函数中调用限流器
func handleAPIRequest(apiKey string) {
if rateLimiter(apiKey, 100, 1) { // 限流阈值设为100,时间窗口为1秒
// 处理API请求
} else {
// 限流,返回错误或提示信息
}
}
2.5 共享session
在多服务器的Web应用中,用户在不同的服务器上请求时能够保持登录状态,实现会话共享。
案例讲解
背景
考虑一个大型电商平台,它使用多个服务器来处理用户请求以提高可用性和伸缩性。当用户登录后,其会话信息(session)需要在所有服务器间共享,以确保无论用户请求到达哪个服务器,都能识别其登录状态。
优势
- 用户体验:用户在任何服务器上都能保持登录状态,无需重复登录。
- 系统可靠性:集中管理session减少了因服务器故障导致用户登录状态丢失的风险。
- 伸缩性:易于扩展系统以支持更多服务器,session管理不受影响。
解决方案
使用Redis的String类型来集中存储和管理用户session信息。
- 存储Session:当用户登录成功后,将用户的唯一标识(如session ID)和用户信息序列化后存储在Redis中。
- 验证Session:每次用户请求时,通过请求中的session ID从Redis获取session信息,验证用户状态。
- 更新Session:用户活动时,更新Redis中存储的session信息,以保持其活跃状态。
- 过期策略:设置session信息在Redis中的过期时间,当用户长时间不活动时自动使session失效。
代码实现
package main
import (
"context"
"encoding/json"
"github.com/go-redis/redis/v8"
"strconv"
"time"
)
var (
rdb *redis.Client // 为了表现代码的完整性,这里省略了初始化代码
ctx context.Context // 为了表现代码的完整性,这里省略了初始化代码
)
// 伪代码:用户登录并存储session
func userLogin(username string, password string) (string, error) {
// 验证用户名和密码
// 创建session ID
sessionID := generateSessionID()
// 序列化用户信息
userInfo := map[string]string{"username": username}
serializedInfo, err := json.Marshal(userInfo)
if err != nil {
// 处理错误
return "", err
}
// 存储session信息到Redis,设置过期时间
err = rdb.Set(ctx, sessionID, string(serializedInfo), time.Duration(30)*time.Minute).Err()
if err != nil {
// 处理错误
return "", err
}
return sessionID, nil
}
// 伪代码:从请求中获取并验证session
func validateSession(sessionID string) (map[string]string, error) {
// 从Redis获取session信息
serializedInfo, err := rdb.Get(ctx, sessionID).Result()
if err != nil {
// 处理错误或session不存在
return nil, err
}
// 反序列化用户信息
var userInfo map[string]string
err = json.Unmarshal([]byte(serializedInfo), &userInfo)
if err != nil {
// 处理错误
return nil, err
}
return userInfo, nil
}
// 伪代码:生成新的session ID
func generateSessionID() string {
return strconv.FormatInt(time.Now().UnixNano(), 36)
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » redis基本数据结构-string

发表评论 取消回复