前言:
在SQL语句中,对于表的增删改查围绕着这几种基本格式:增(create),删(delete),改(update),查(retrieve)。
对于表的操作,这里推荐一个MySQL的可视化工具:Navicat(Navicat 中国 | 支持 MySQL、Redis、MariaDB、MongoDB、SQL Server、SQLite、Oracle 和 PostgreSQL 的数据库管理)
新增:
单行数据 + 指定列插入:
insert into 表名(属性1,属性2...) values(值1,值2...);
多行数据 + 全列插入:
insert into 表名 values (值1,值2...),(值1,值2...),(值1,值2...)...(值1,值2...);
注:属性和值是按顺序一一对应,若类型对应不上则会报错!!!
演示:
我们先看学生的表结构(姓名,班级,语文成绩,数学成绩,英语成绩):

单行全列插入:
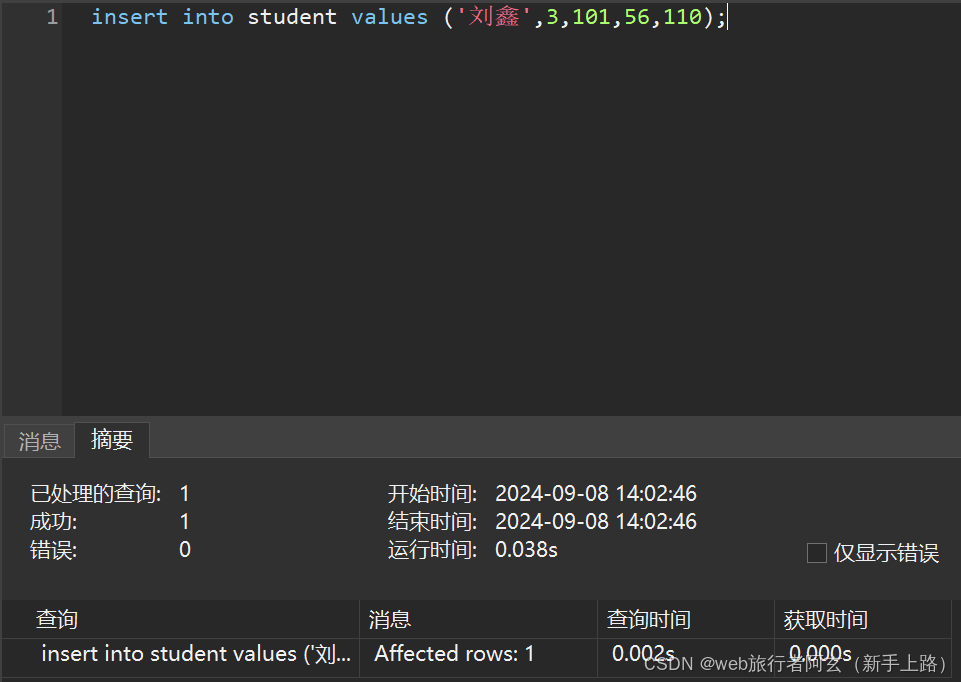
已显示插入成功,我们可以查看一下:

单行指定列插入:
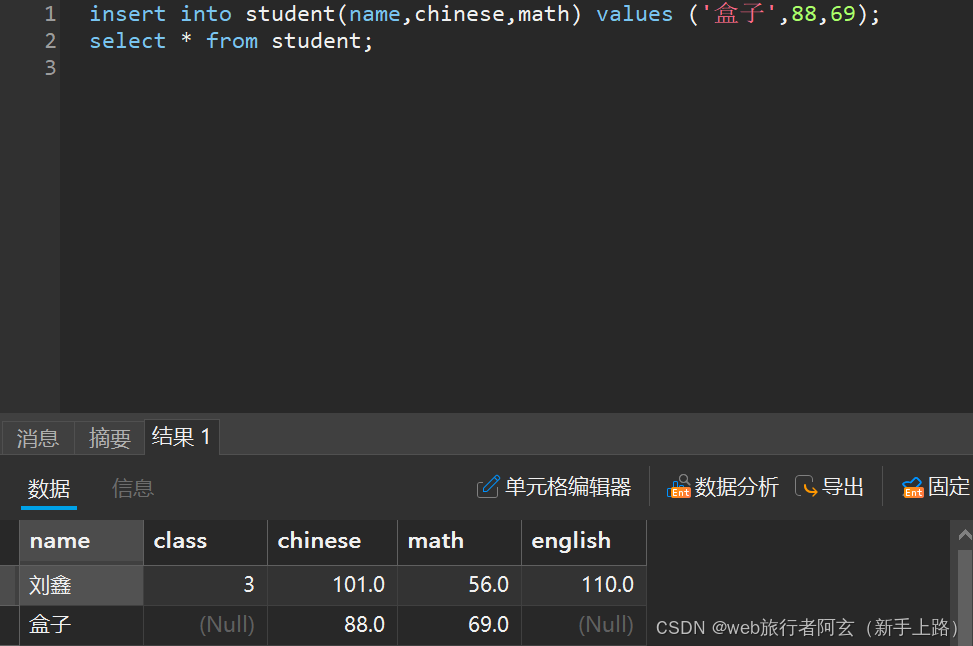
可以看到,指定列插入时,没有指定的列默认值为null,也可以指定值为null
多行全列插入:
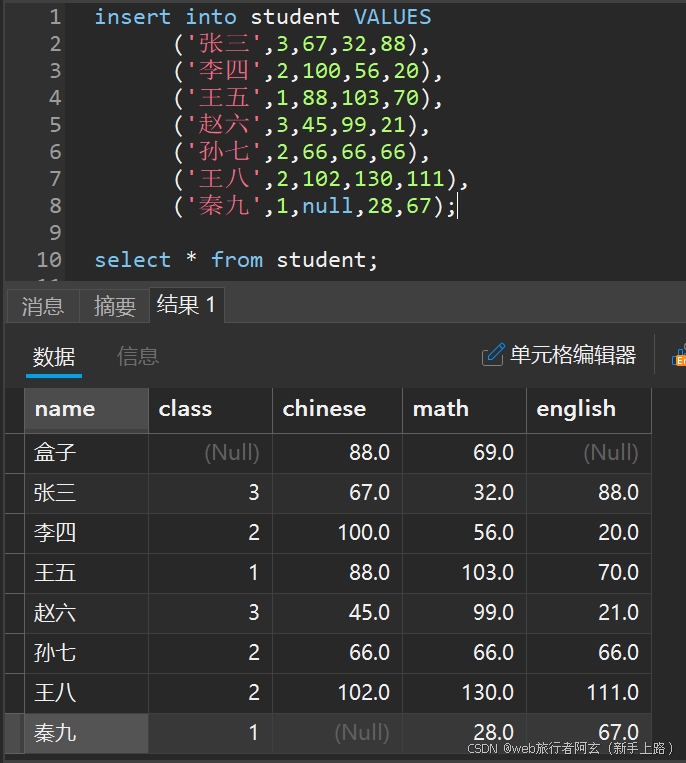
查询:
全列查询:
select * from 表名;
整张表都显示:
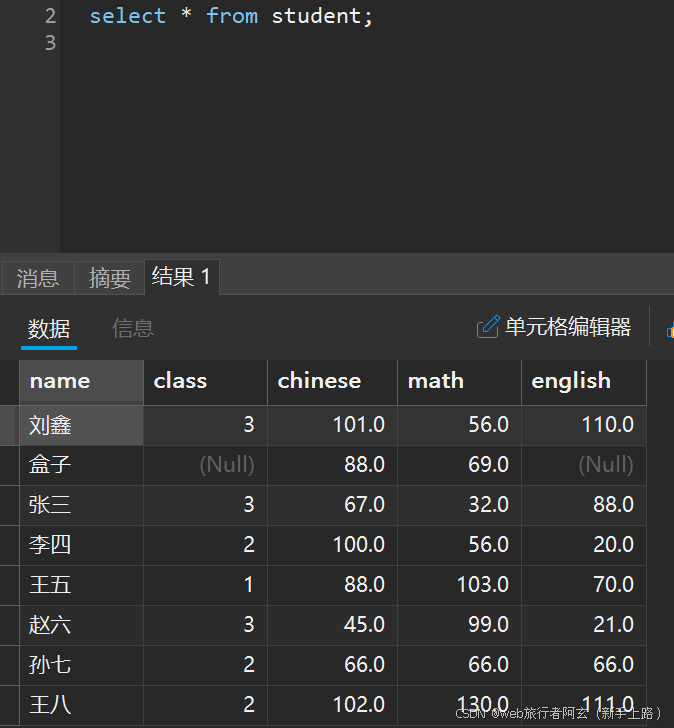
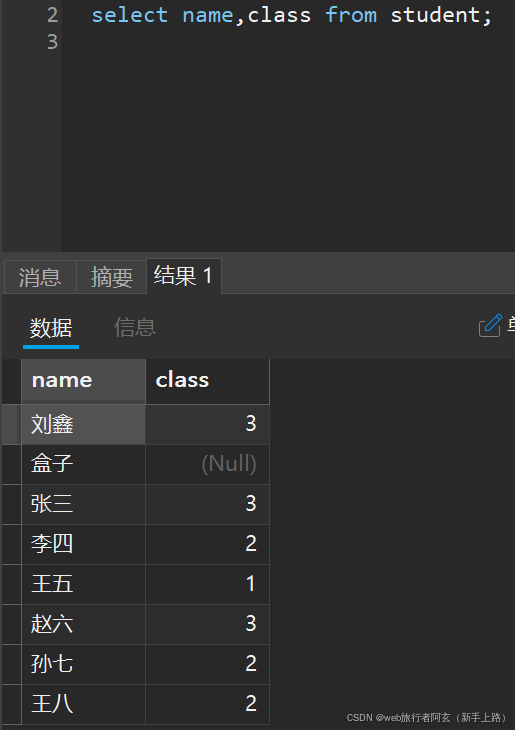
指定列查询:
select 属性1,属性2... from 表名;
表部分属性显示:
表达式:
可以计算出分数总数(属性/列根据行与行之间计算):

注意的是,null不参与表达式计算
别名:
select 属性/表达式 [as] '别名' from 表名;
如上图给chinese + math + English 取个别名:
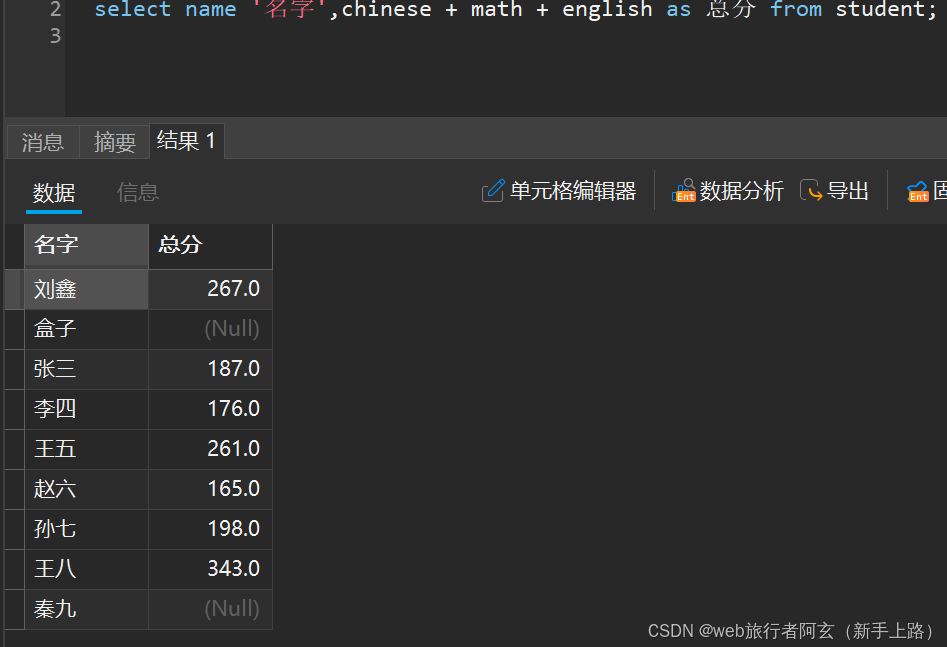
对于别名,as可以省略,单引号也可以省略(别名中有空格的情况下还是得用单引号括起来)
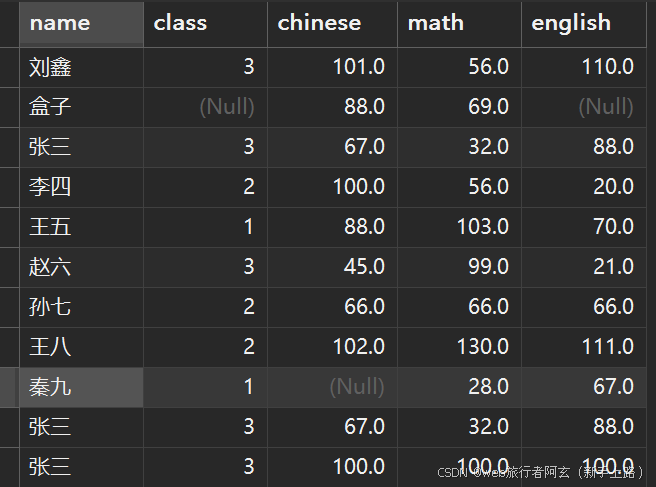
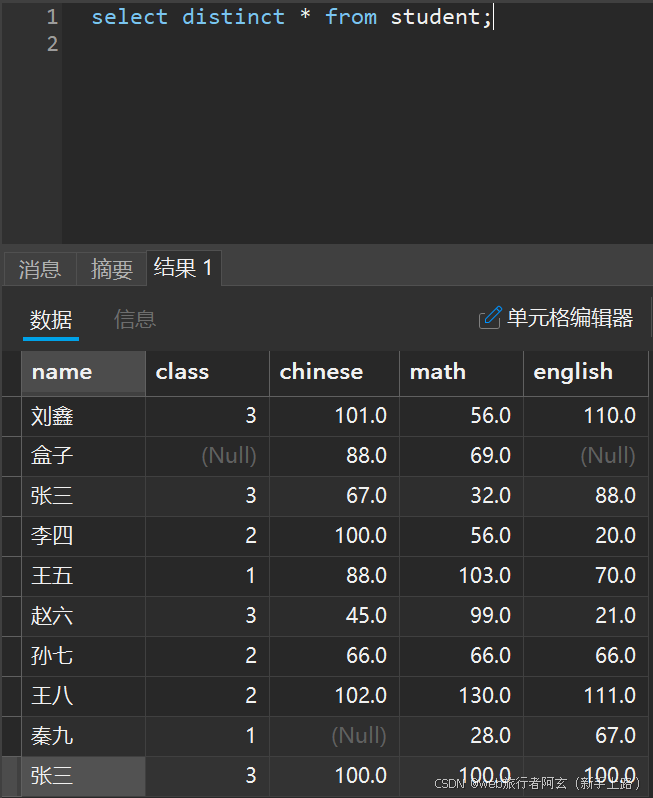
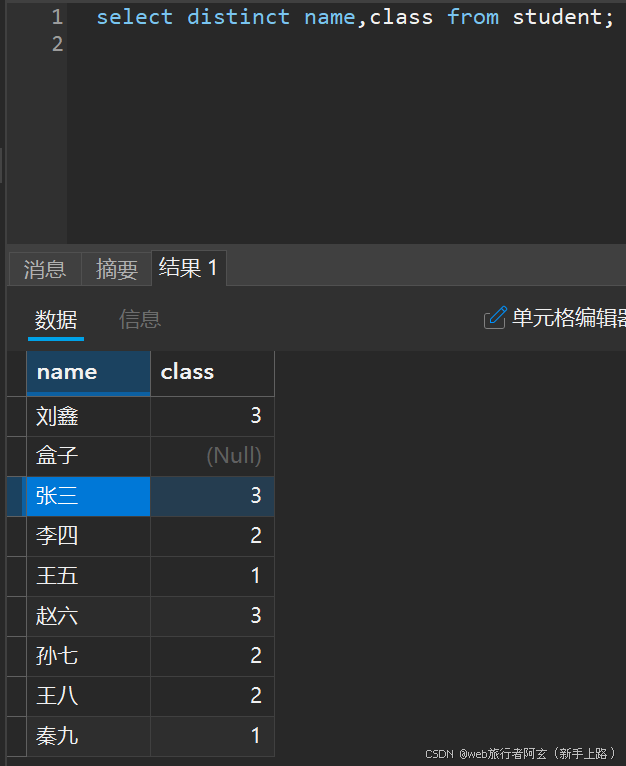
去重查询:
select DISTINCT 属性 from 表名;
查询出来的一列或多列相同才能被判定为相同数据,重复数据只保留一条数据。
去重前:
去重后:
排序:
select ... from 表名 ... order by 属性 [ ASC / DESC ];
排序分为升序(ASC)和降序(DESC),升序是指从小到大排,降序是指从大到小排,默认是升序。
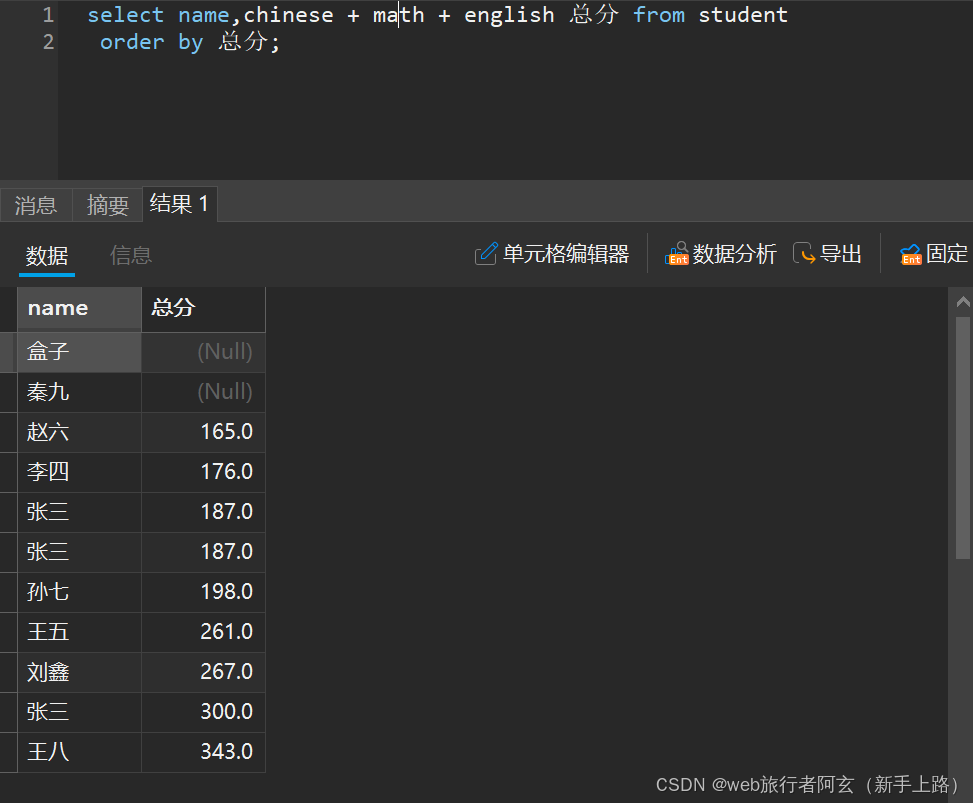
数据排序中,null会被认为是最小,默认排序就排在最小位。
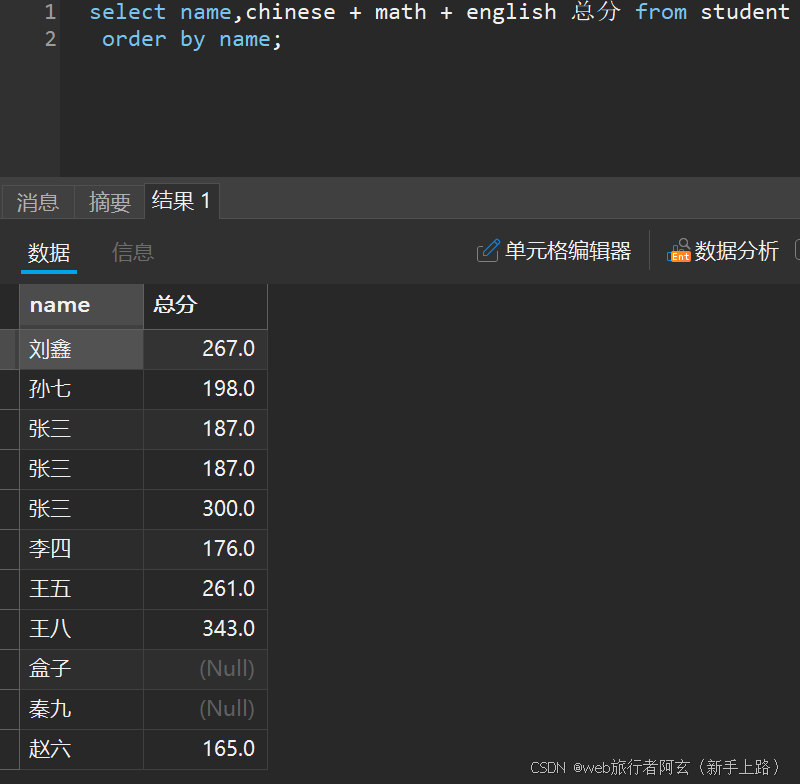
也可以按名字等其他类型排序:
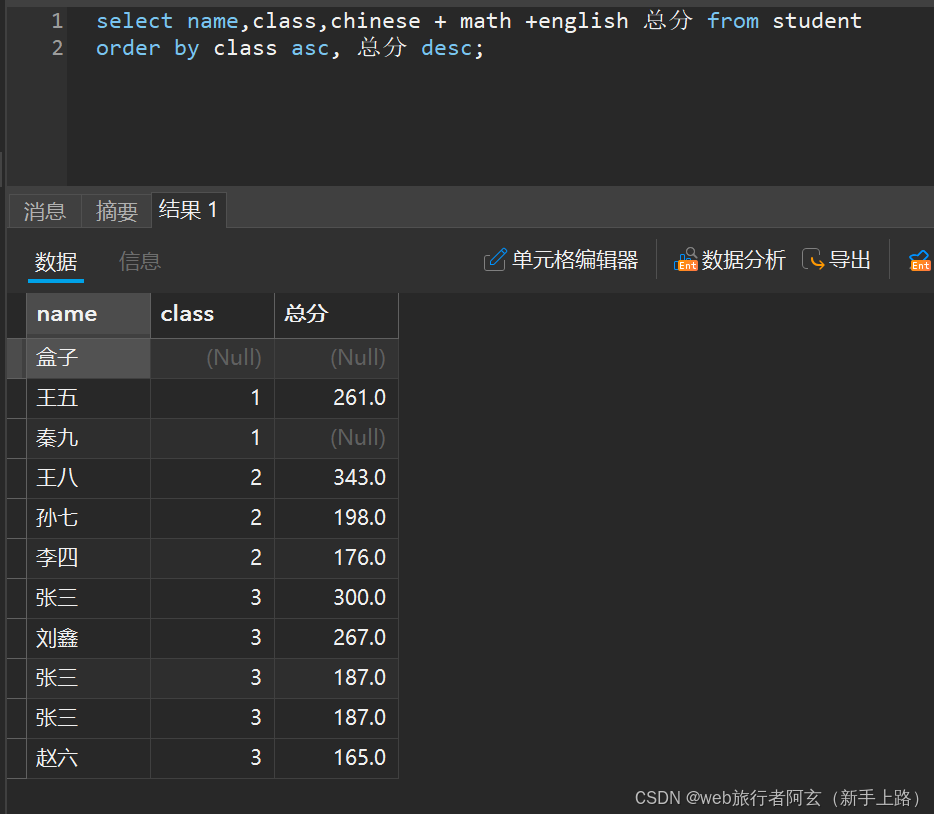
也可以排序多次,如在班级排序的情况下按总分从大到小排序:
条件查询:
select ... from 表名 ... where 列/表达式 条件符号 [order by...];
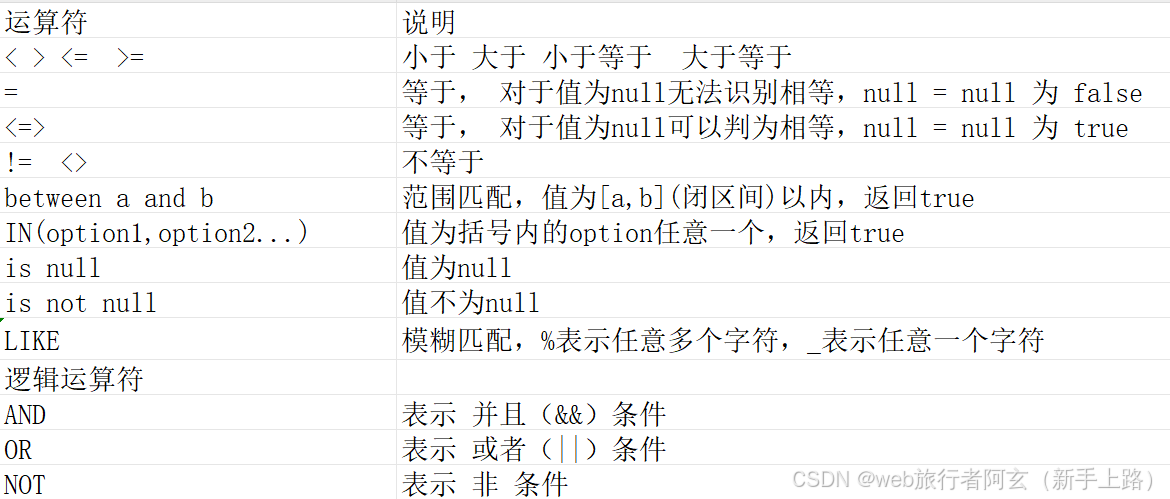
注:and的优先级比or高,所以同时使用俩个时最好使用括号来括起来。
增加条件限制来进行查询:
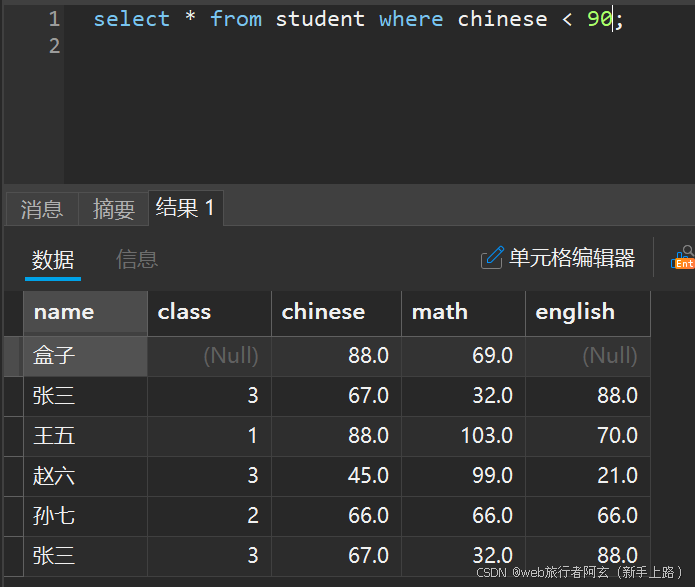
1.查询语文不及格的同学:
2.查询总分高于200的3班同学:
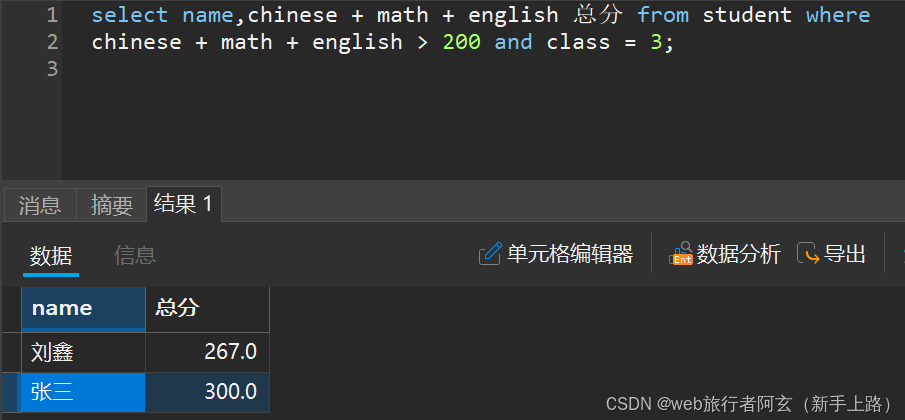
注:在使用别名时,对于条件查询中表达式必须完整,不能使用别名充当条件过滤!!!
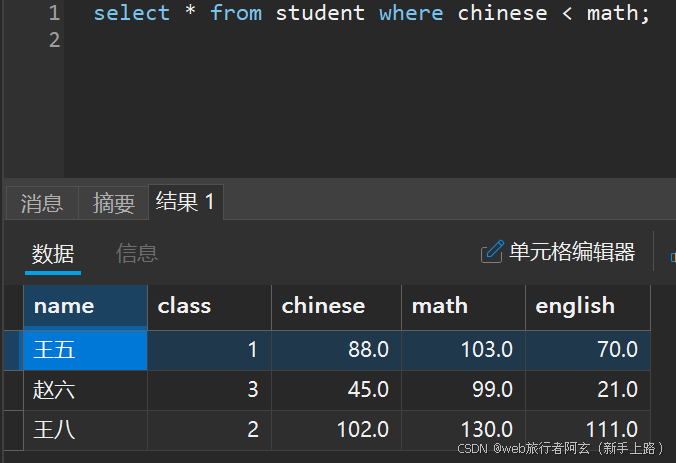
3.查询数学成绩比语文好的同学:
4.查询语文比英语好或者语文比数学好的总分高于100的同学:
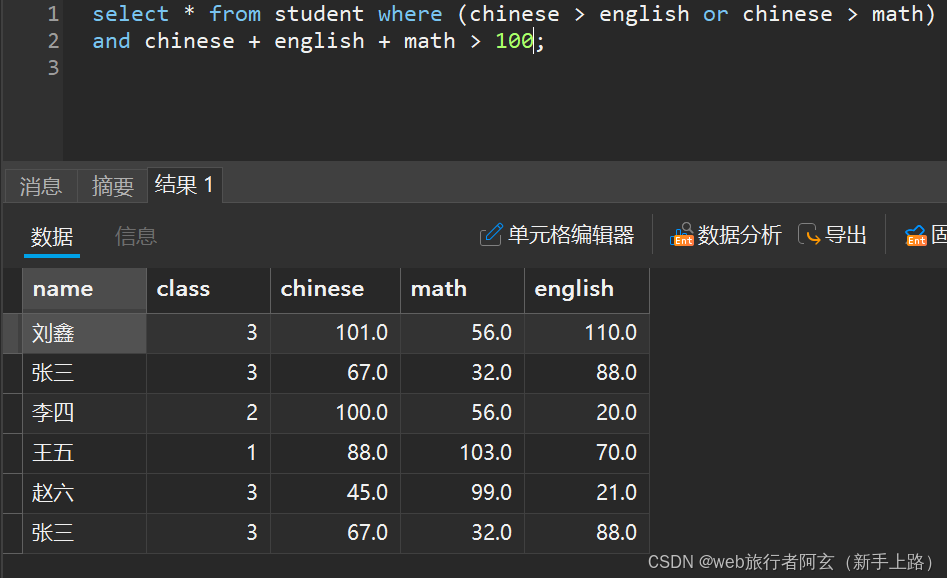
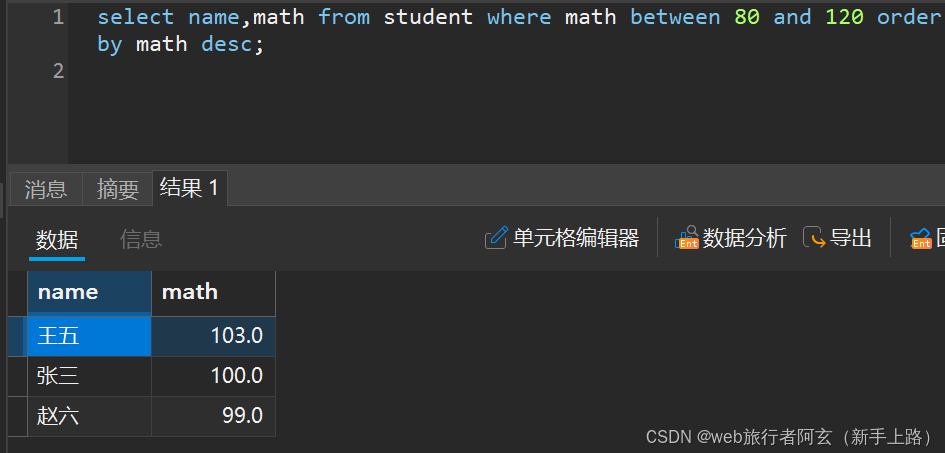
5.查询数学成绩在80~120分同学并且按高到低的顺序排列:
6.查询姓张的同学:
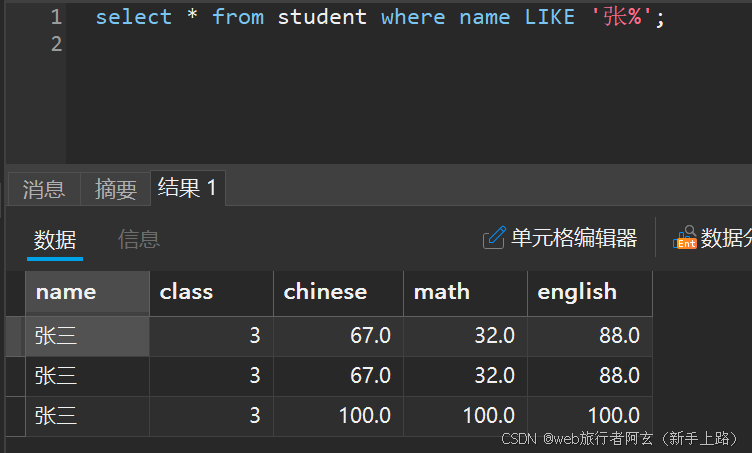
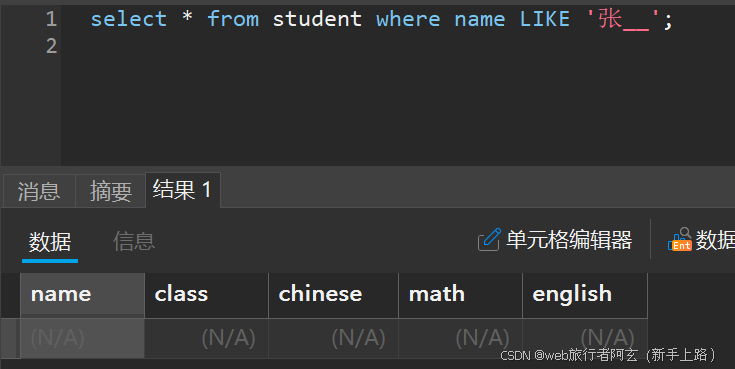
对于_符号而言,若是匹配一个是同样的结果,若是匹配俩个__就代表找到叫张xx的数据,则为空。
7.查询未知班级的同学:
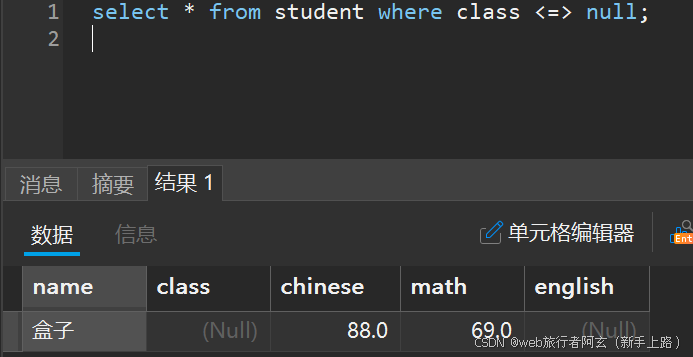
分页查询(起始下标为0):
select ... from 表名 [where...] [order by...] LIMIT n / LIMIT s , n;
表示从0开始,往后n条 / 从s开始,往后n条
select ... from 表名 [where...] [order by...] LIMIT n OFFSET s;
表示从每页n条记录,偏移量为s(从s开始,往后n条)
计算第x页的偏移量s公式:s =(x - 1) * n
所有表格:
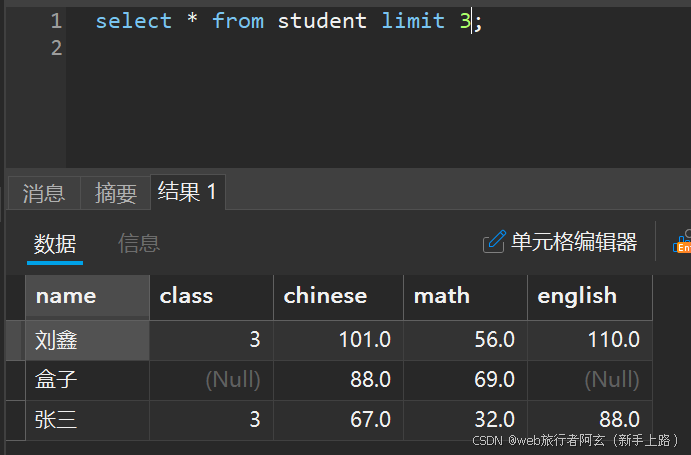
1.查询0开始往后3条的结果:
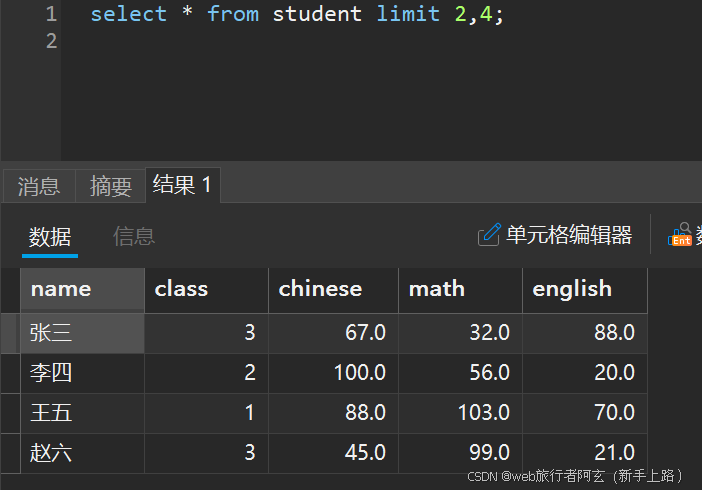
2.查询从2开始,往后n条的结果:
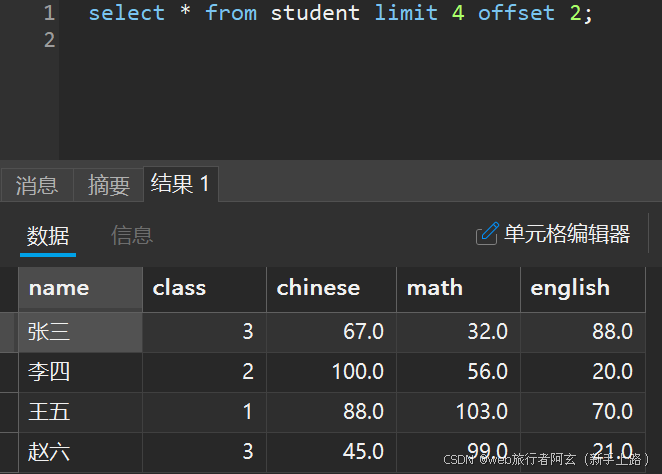
3.查询从偏移量2开始,共4条记录的结果:
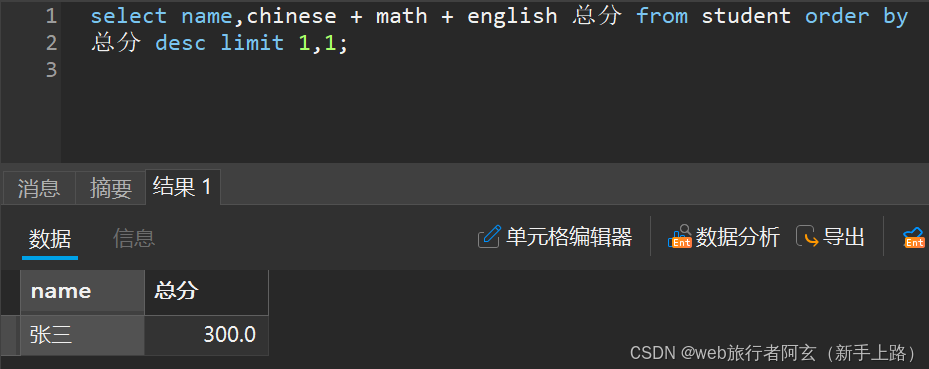
4.查询总分第二的同学:
修改:
单行或多行数据修改:
update 表名 set 列1 = 值1,列2 = 值2... [where...] [order by...];
注:修改时必须加上where条件,否则修改的是整张数据表的所有记录!!!
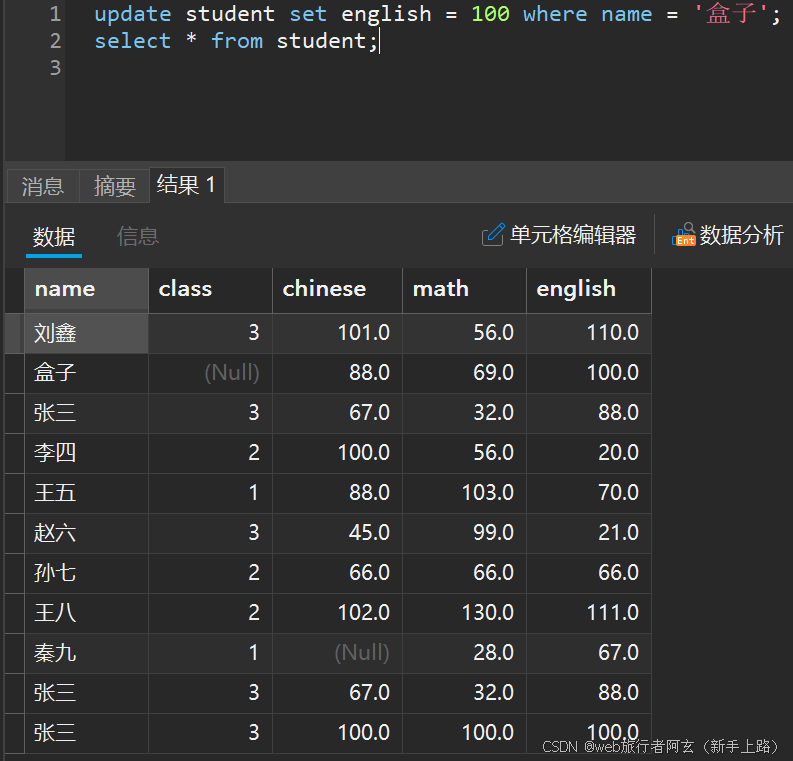
修改盒子的英语成绩为100:
删除:
delete from 表名 [where] [order by] [limit...]
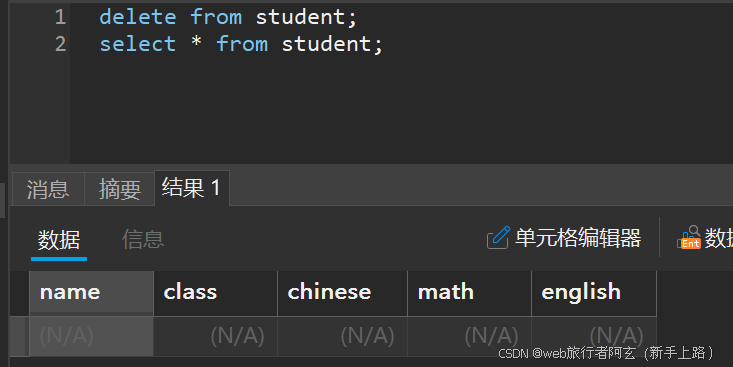
注:删除不加上where条件,删除的也是整个表的数据!!!
若没有where条件,则删除全部数据!
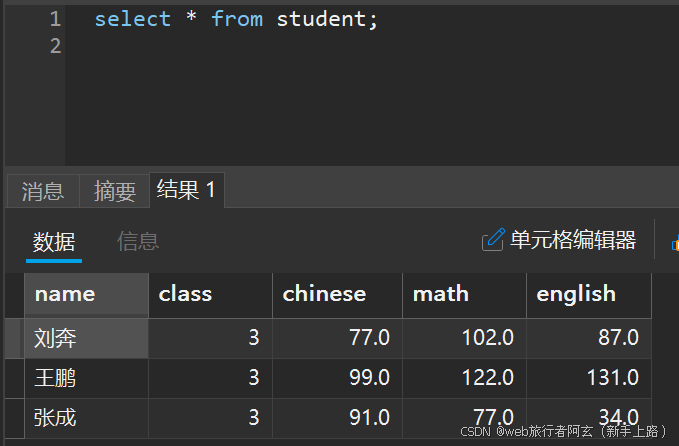
删除刘奔同学的记录:
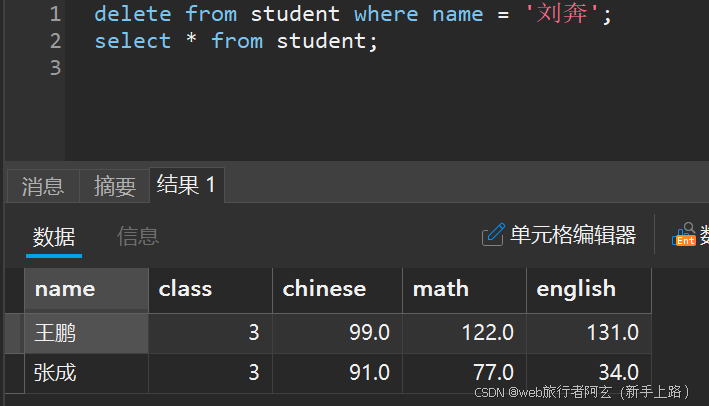
数据库约束:
约束类型
NOT NULL:非空约束,被指定not null的列不允许为空
UNIQUE:唯一约束,这个列里的值在表中是唯一的,不能重复
DEFAULT:默认约束,对于没填充的列指定该默认值
PRIMARY KEY:主键约束,NOT NULL 和 UNIQUE 的结合,且一张表只能有一个主键。若是用int类型相关的数据类型置为主键,则可以使用auto_increment关键字来实现自增(注:该自增是使用当前使用过的最大值+1的自增方式,不一定有序)
FOREIGN KEY:外键约束,一张表要与另外一张表的主键或唯一键来进行关联,则可以说这些表存在关键关系。
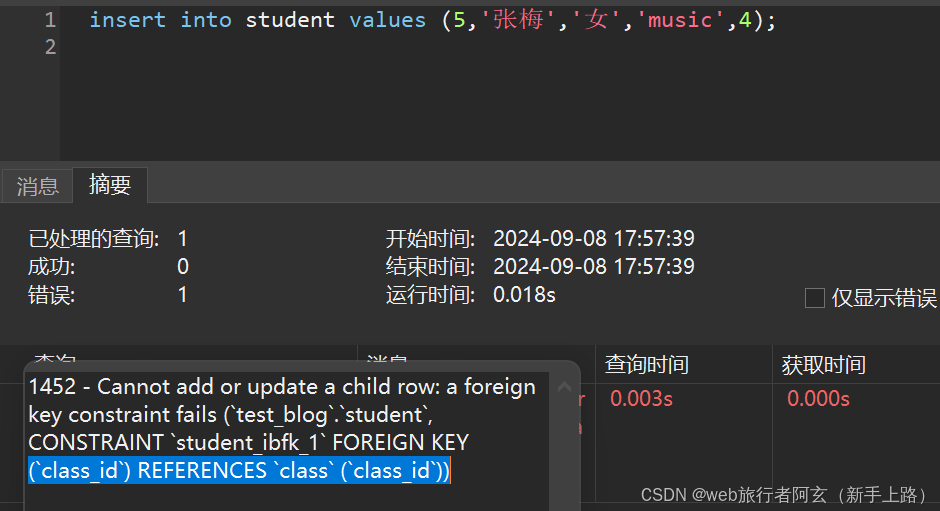
例:创建一个学生表和班级表,学生表和班级表之间有关联关系,且学生表中学生id为主键,名字默认值为‘无名氏’,性别不为空,兴趣唯一;班级表中设置班级id为主键。
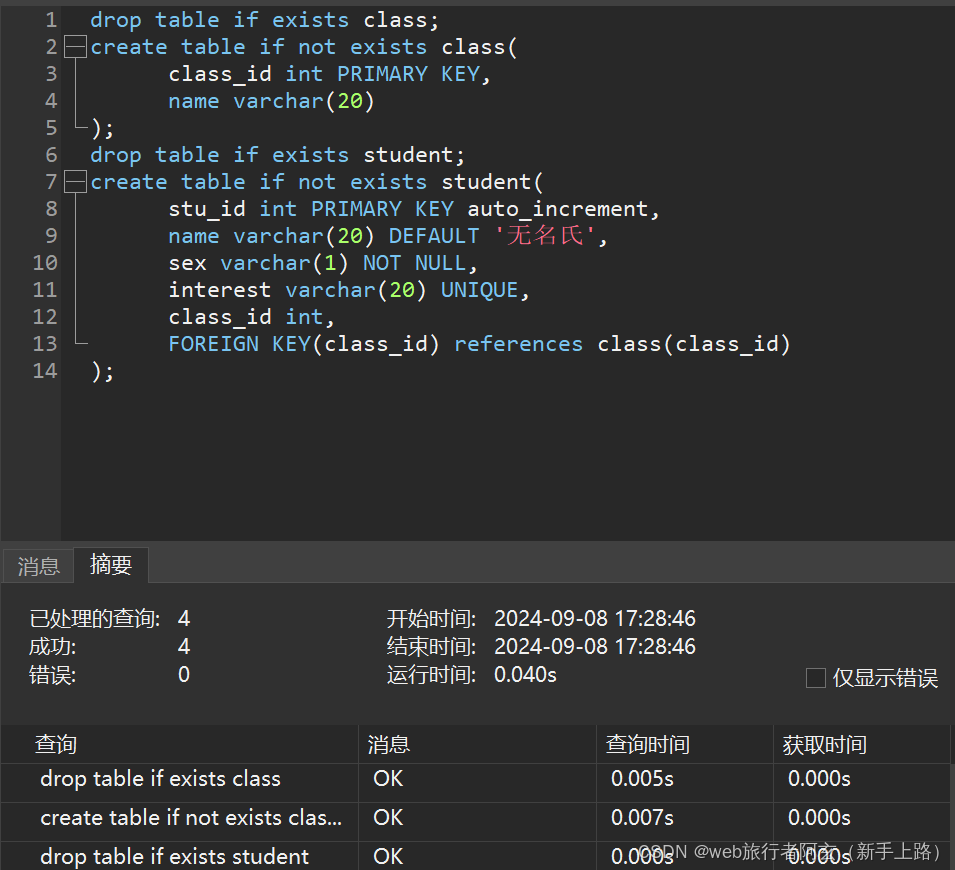
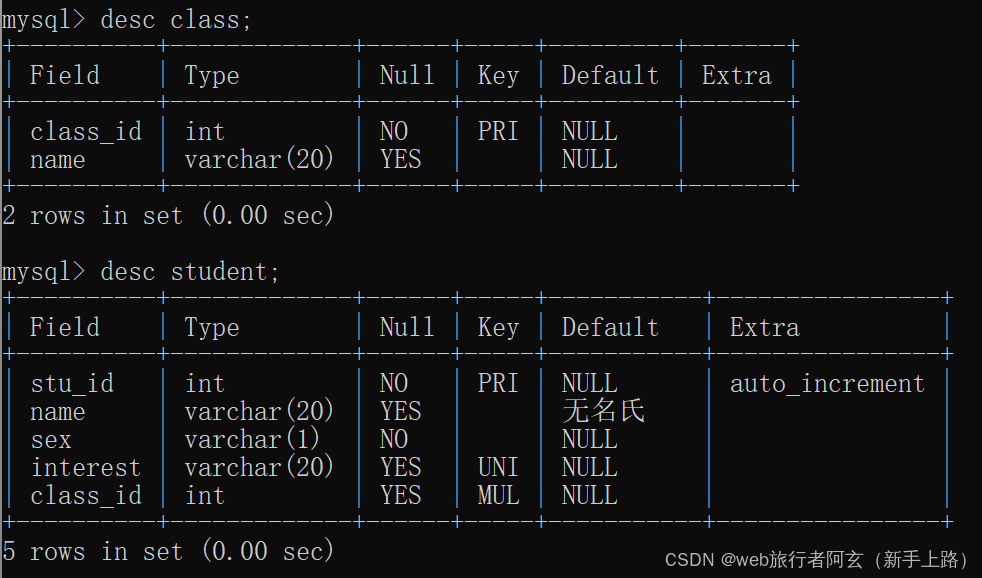
注:
一个表只能有一个主键,但是一个主键可以包含多个列,所以也称为复合主键: primary key(列1,列2...)
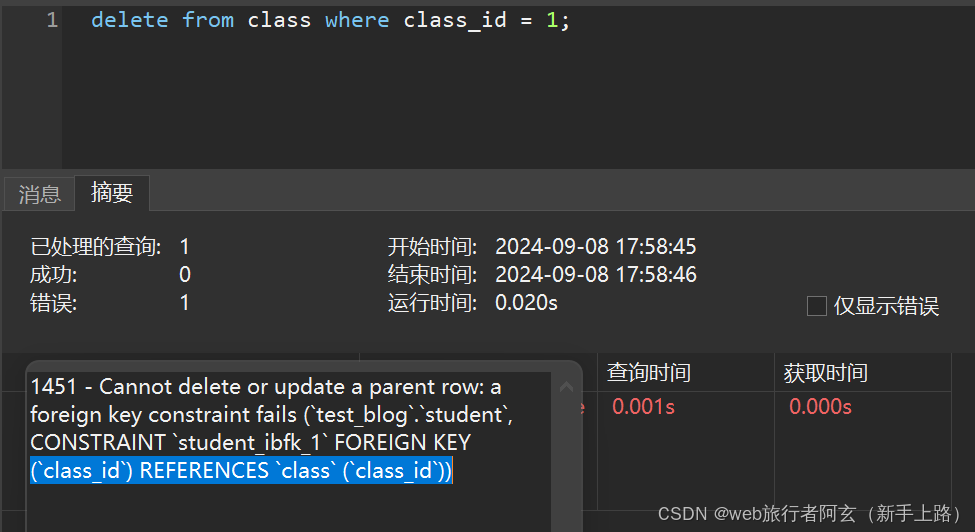
外键约束时,添加数据只能添加主表里对应列有的数据,不能添加没有的数据,另外,主表中存在的数据若是和此表相关联,也不可以删除!!!
如班级表里有:
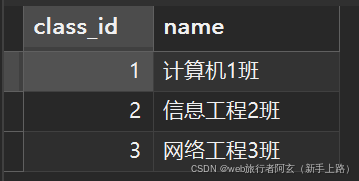
所以班级只能添加1,2,3班:

添加其他的会报错,删除班级也会报错:
表的设计理念:
设计表的时候,一定要满足三大范式:
第一范式:该表中的属性/字段不可再分,如:

第二范式:在第一范式的基础上,消除了部分函数依赖,比如一个表中存在复合主键,但是某些字段只对其中一个主键依赖,则可能会造成数据冗余,更新异常等情况:

比如上图:姓名,年龄,学分都之和其中之一个主键挂钩,只有成绩是和学号课程一起挂钩的,所以该图不符合第二范式
把他们拆开后就能符合:

第三范式:在第二范式的基础上,消除了非关键字段的传递依赖。

要想满足第三范式,可以把该表的俩个主体各分为俩张表:

除了三大范式,还要明确实体间的关系:
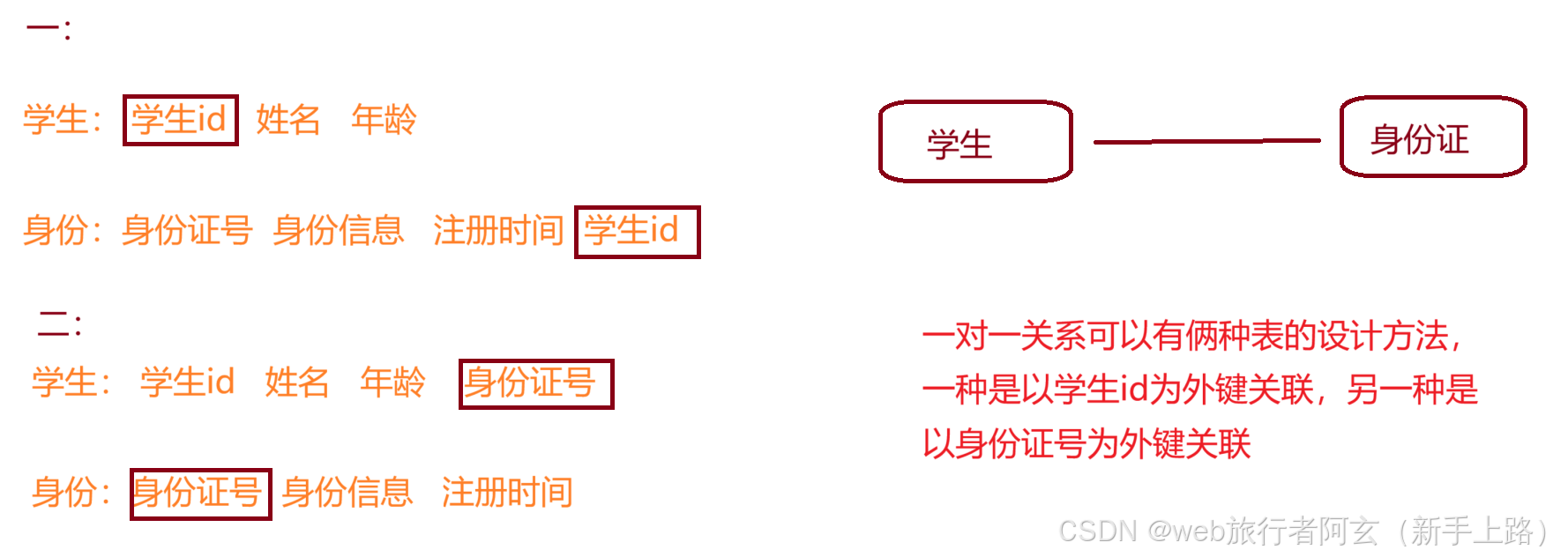
一对一关系:
一对多关系:

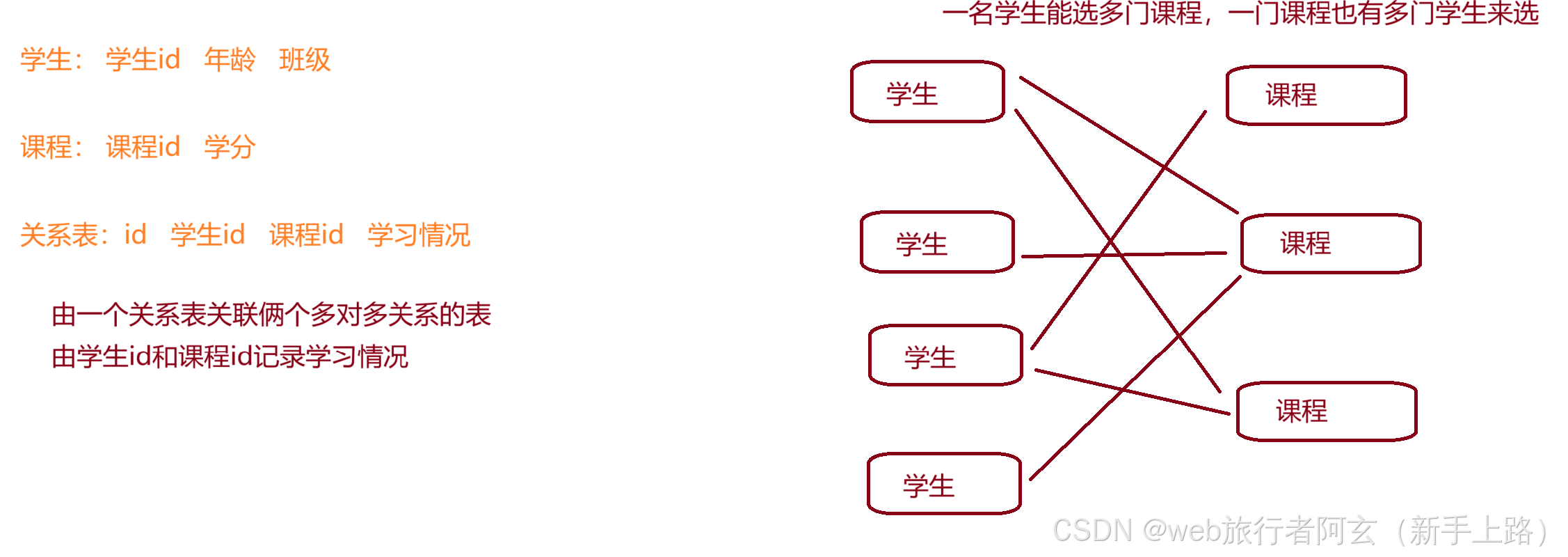
多对多关系:
进阶新增:
insert into 目标表名 [(指定列)] select...
该语法是创立一个新表,把查询结果全部放入到这个新表中
例:将班级表的数据放入class1中
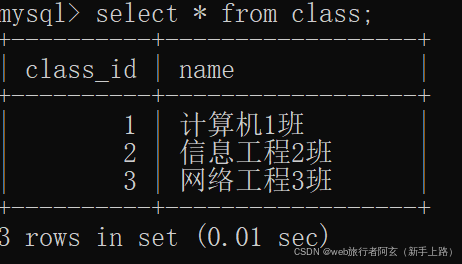

创建一个新表:
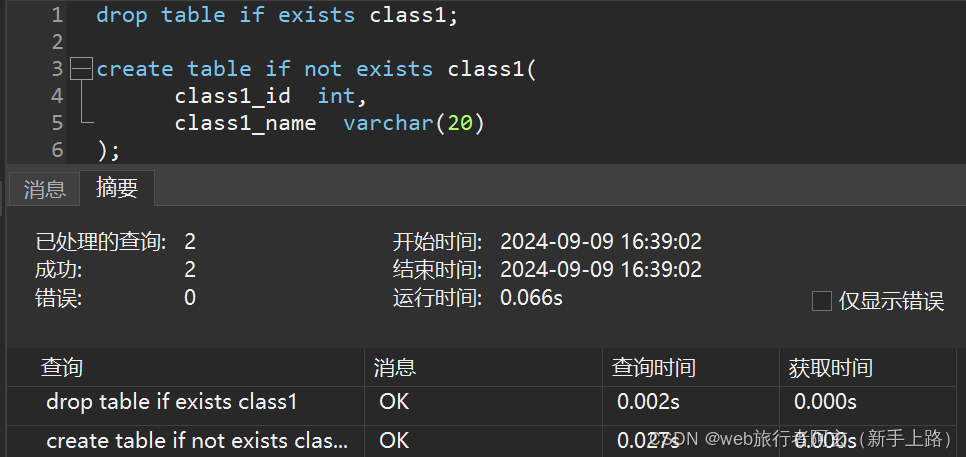
查询结果插入到新表中:
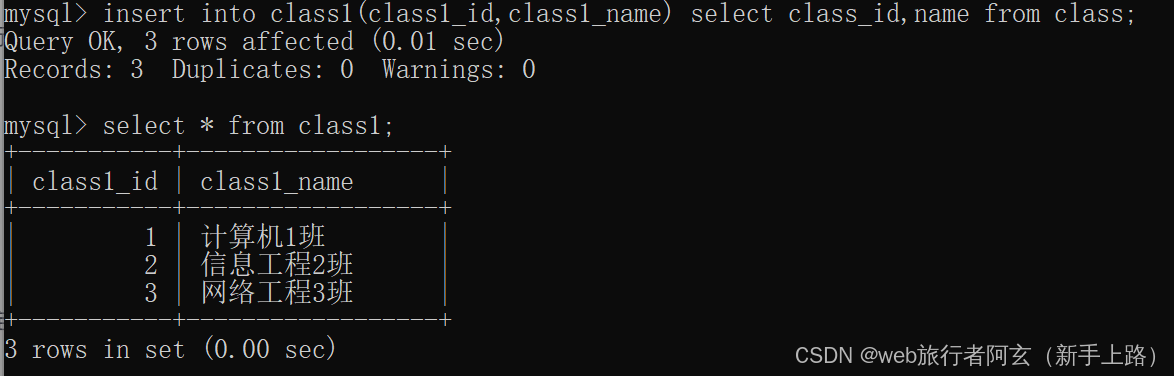
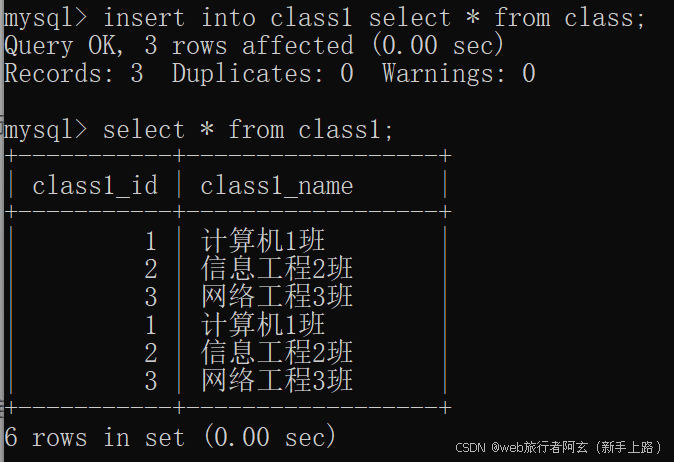
进阶查询:
聚合查询:
聚合查询就是进行行与行之间的计算(对于非数值类型不适用)
聚合函数:

注意的是,只有数值类型才可以进行sum,avg,max,min的计算,函数括号内可以包含表达式。
演示:
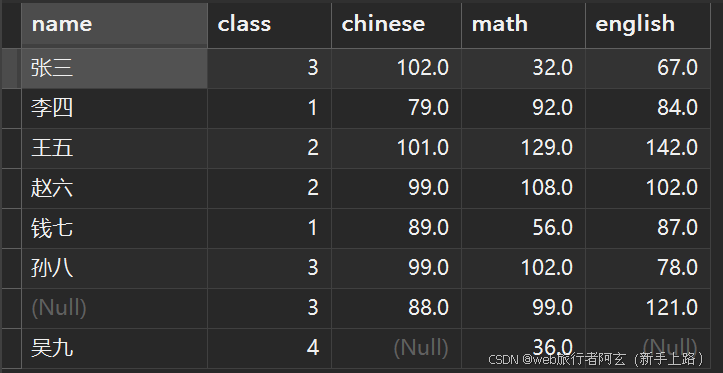
1.显示班级有多少名写名字的同学:
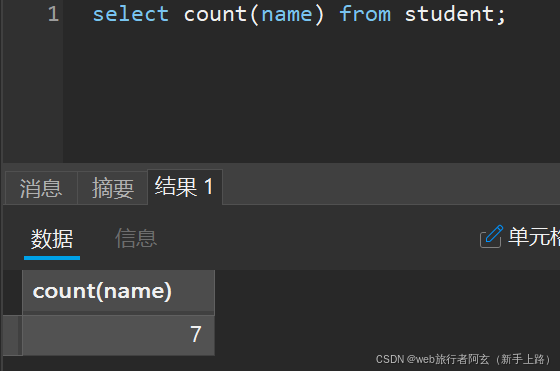
可以看到,null值不算入里面。
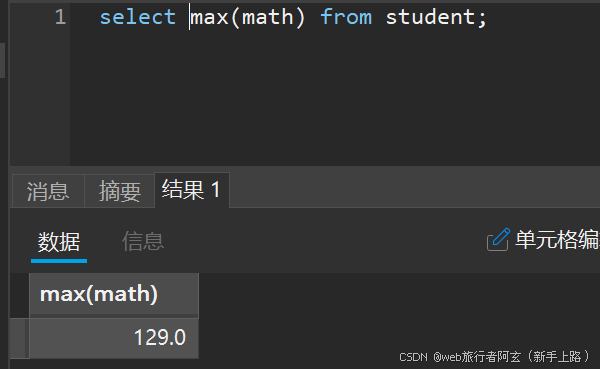
2.显示数学最高分:
3.显示一班四班语文总分:
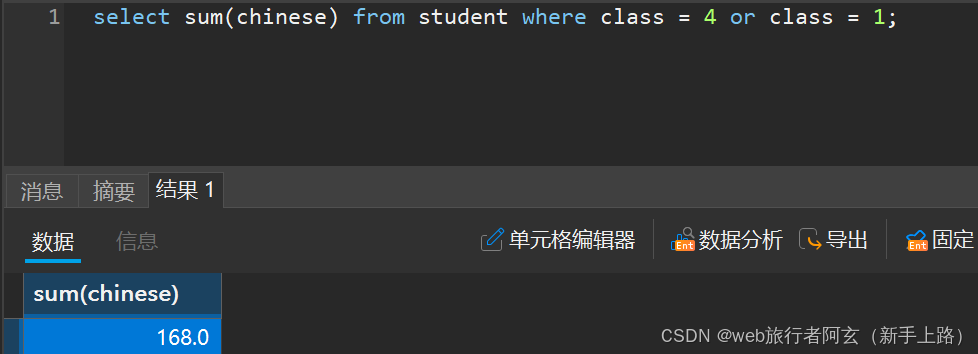
我们可以看到,null是不参与计算的
4.显示英语最低分:
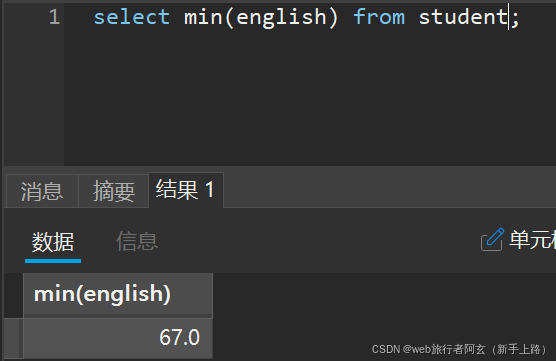
null值也不参与高低分的比较
5.显示年级平均总分:
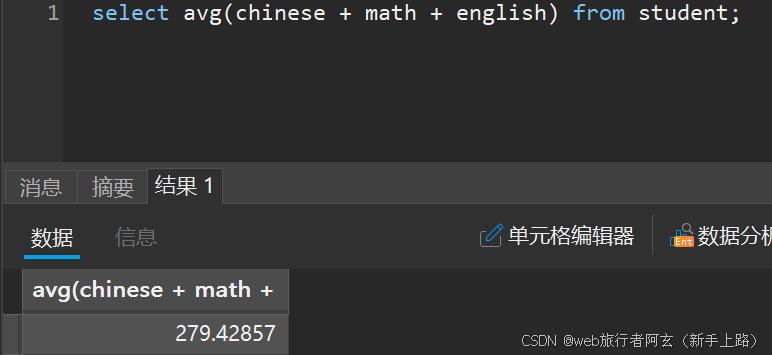
group by 子句:
select [需分组列名] ,[聚合函数] from 表名 [where] group by 分组列名 [order by] [limit...];
用于分组查询,对指定列进行分组查询。只有分组的列和在聚合函数里的列才能一起查询。
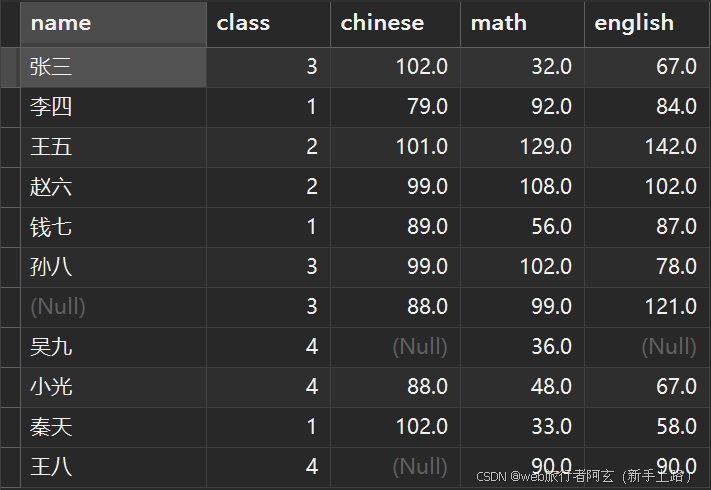
例:1.查看各个班的平均总分
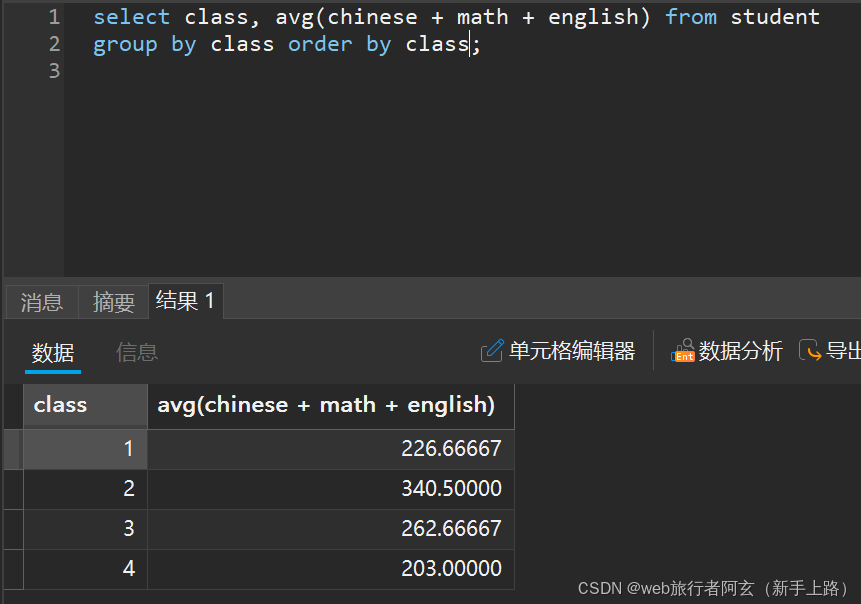
可以加上round(数据,小数位数)语法来省略小数点,也可以跟上order by和取别名。
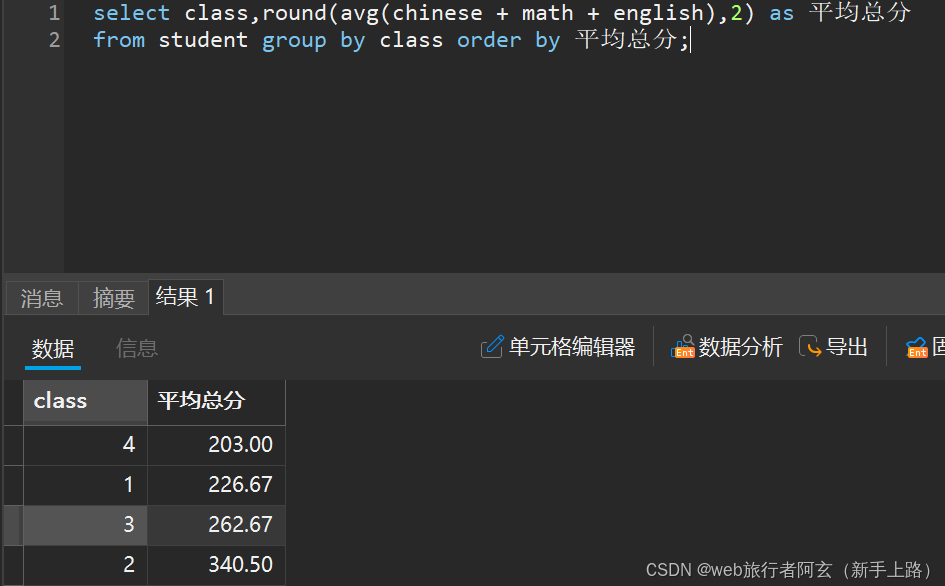
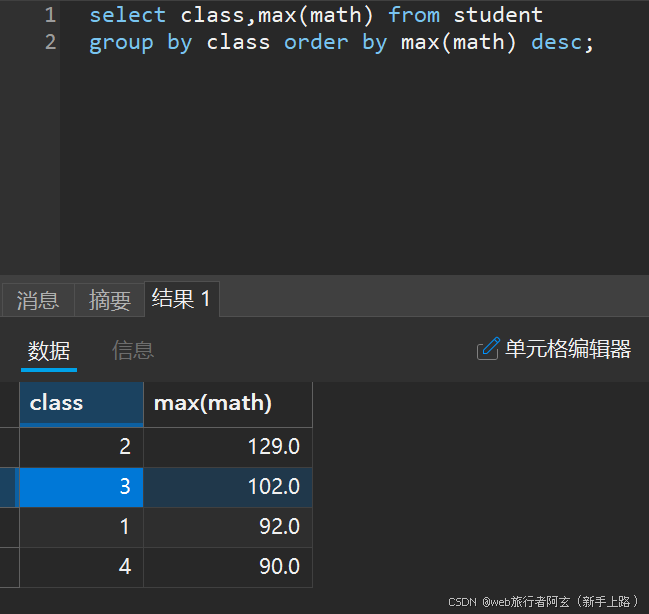
2.查看各个班的数学最高分
having:
select [需分组列名] ,[聚合函数] from 表名 [where] group by 分组列名 [having 条件][order by] [limit...];
group by语句进行分组完后,需要条件过滤时,不能使用where语句(分组完后行数缩减,where不适用),而是使用HAVING
例:1.查询平均总分高于300的班级
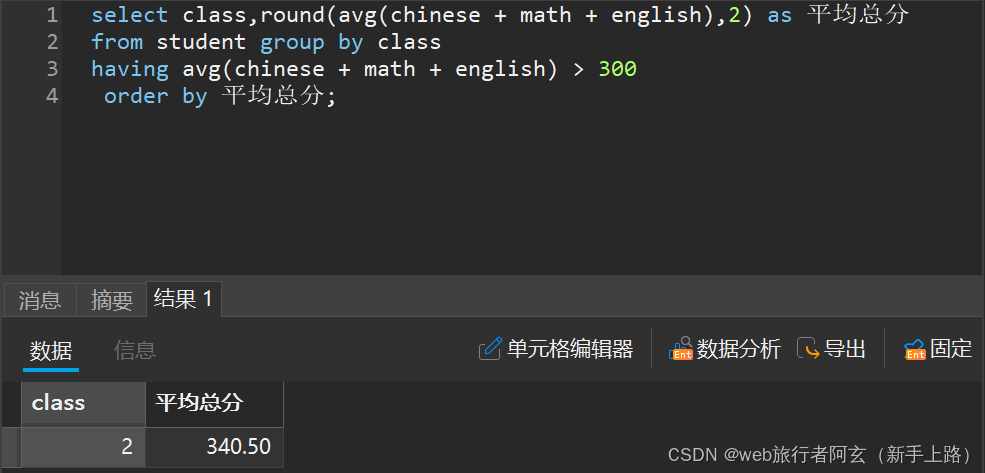
注意:having后面的条件中和where一样不能使用别名!!!
2.查询每个班姓王同学中数学高于80的最高分数
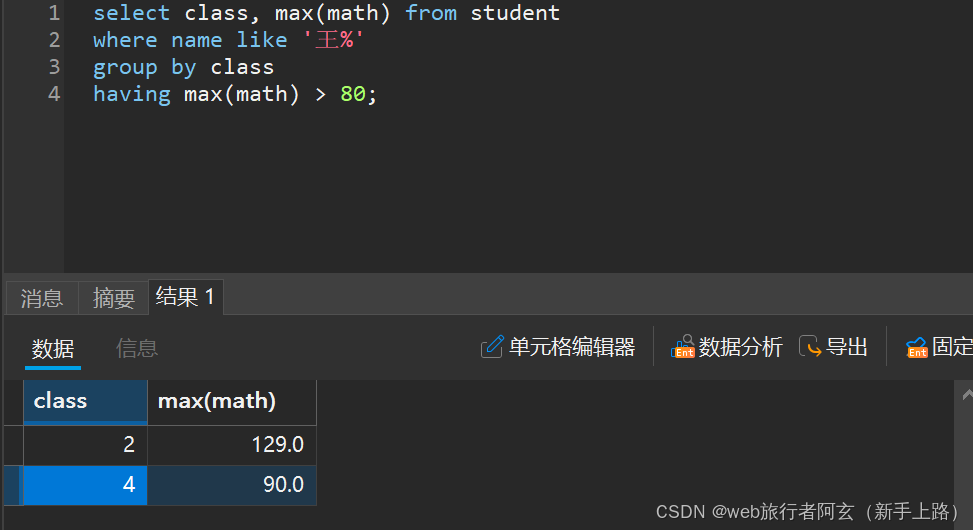
可以看到,where和having可以同时使用
联合查询:
概念:
联合查询,顾名思义就是联合多张表进行查询操作,然后取这些表的笛卡尔积,利用主键来筛选出联合后的表数据。
笛卡尔积:
笛卡尔积是集合论里的一个概念,描述了俩个或多个集合之间所有可能的序列对,也就是全排列:

俩张实验表(班级和学生表):
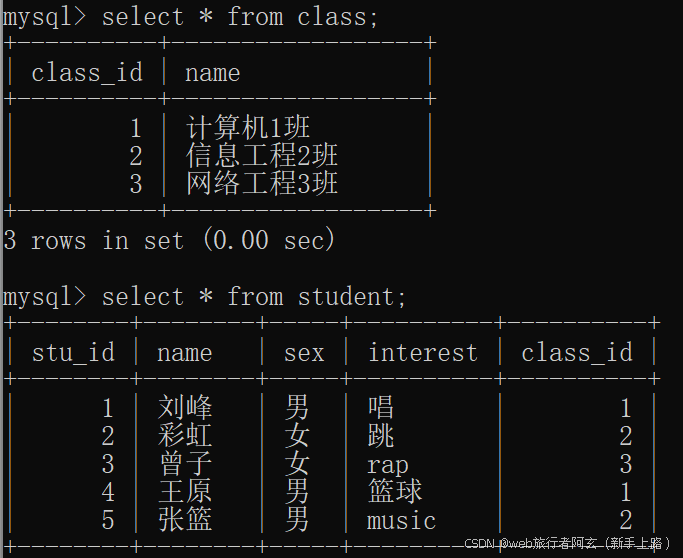
内连接:
联合俩张不一样的表的方式称为内连接
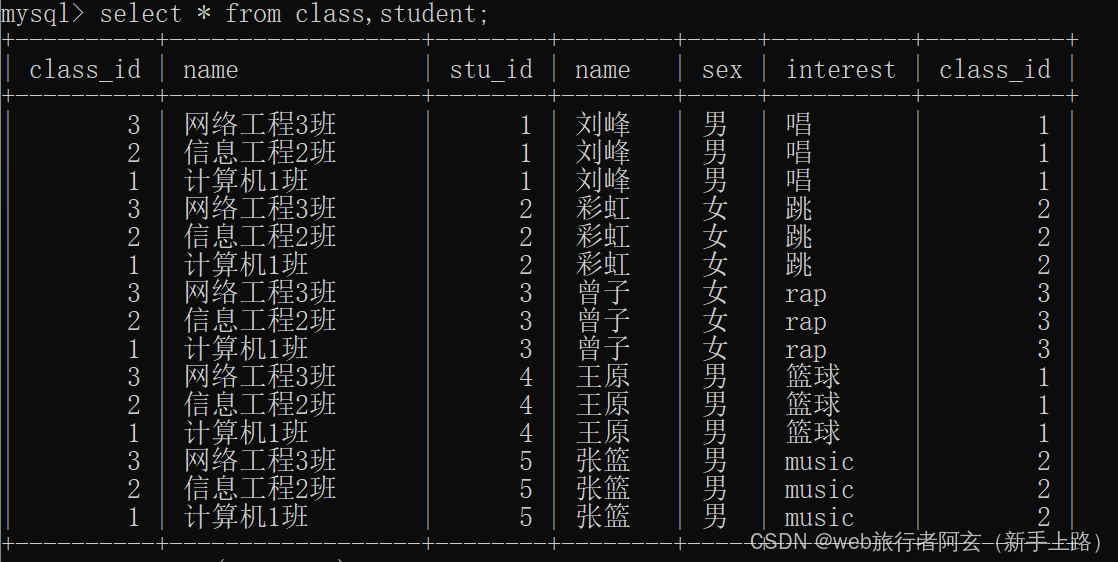
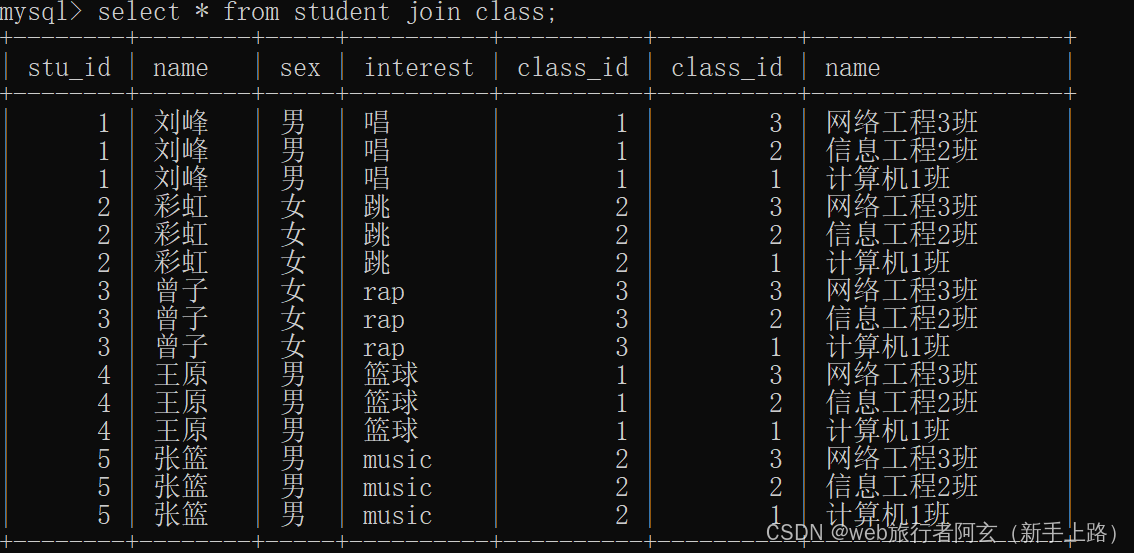
select 列名 from 表1,表2... where 连接条件 ...;
select 列名 from 表1 [inner]join 表2 on 连接条件...;
俩种方式都可以取笛卡尔积:
表连接查询的执行过程:
1.先计算连接的笛卡尔积
2.然后使用条件过滤掉无效数据
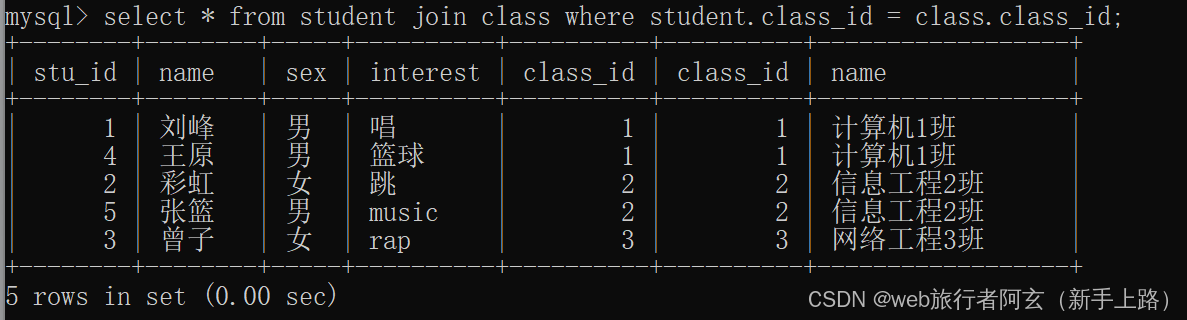
3.加入查询条件得到需要的结果行

4.精简列名(取别名)得到最终结果列

外连接:
以左(或右)表为基准,左(或右)表的数据全部显示,右(或左)表若是没数据则用null去填充
以左为基准:
select 列 from 表1 left join 表2 on 连接条件...;
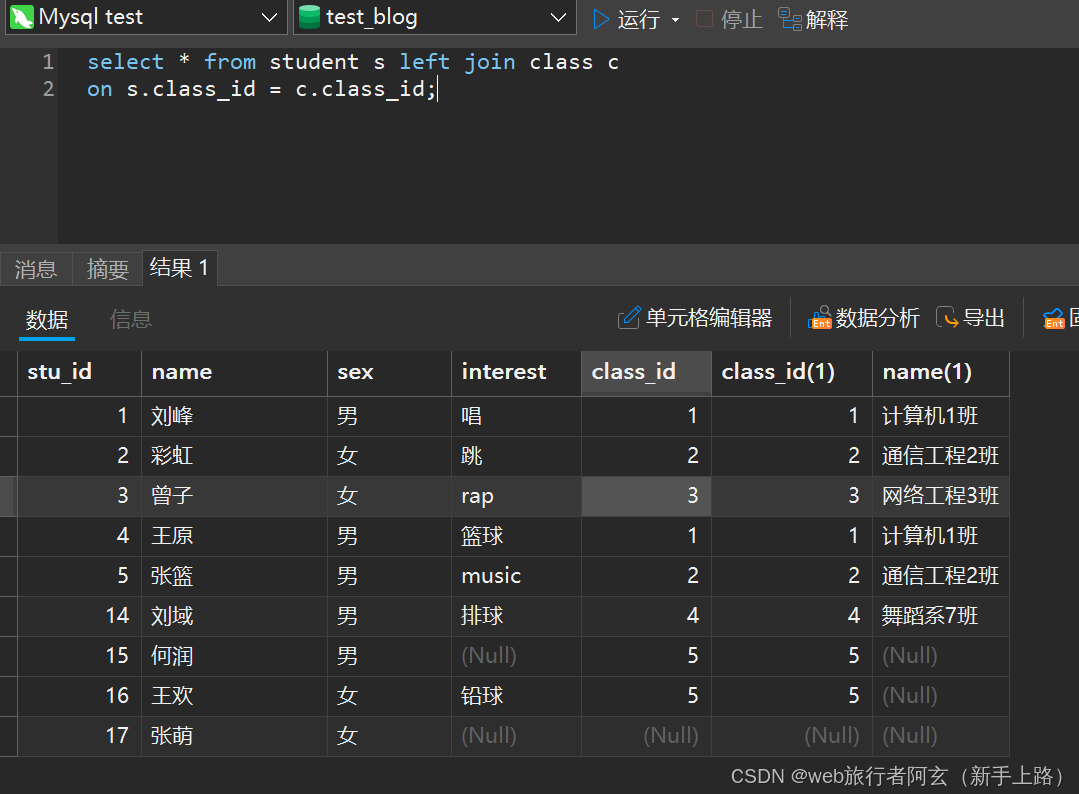
可以看到右表class表没有的数据用null填充
以右为基准:
select 列 from 表1 right join 表2 on 连接条件...;
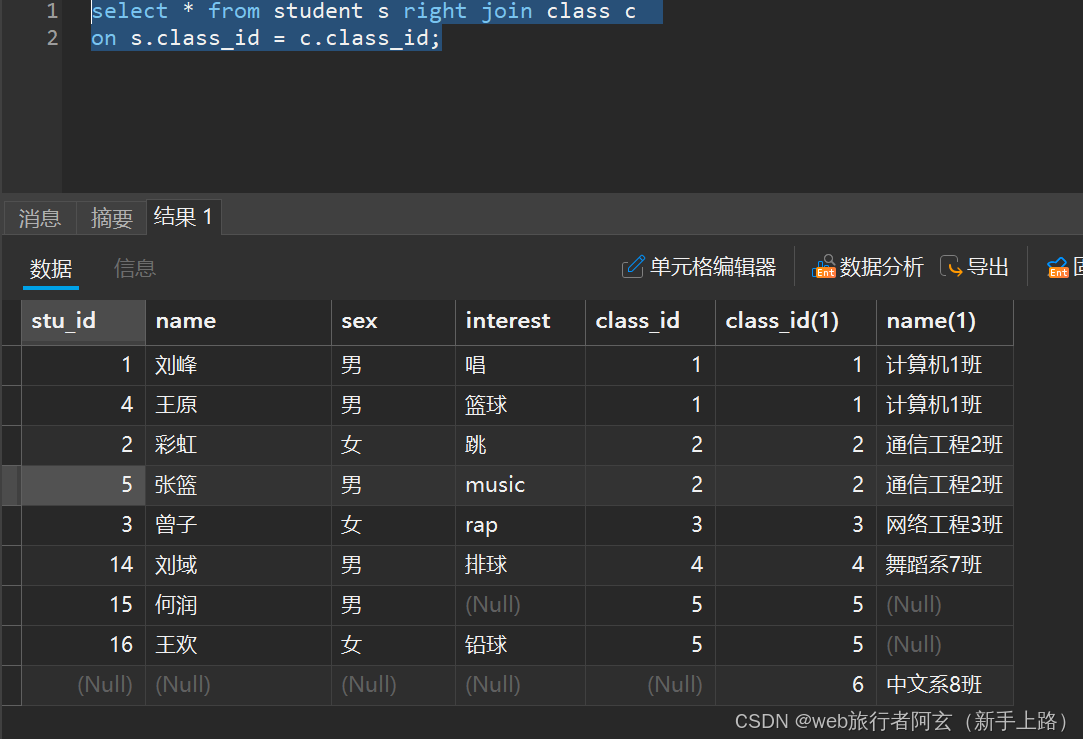
同理,以class为基准,student表没有的数据用null填充
自连接:
联合俩张一样的表的方式称为自连接
select 列名 from 表1 别名1 join 表2 别名2 on 连接条件...;
如有以下三个表,分别为学生表,科目表,成绩表:
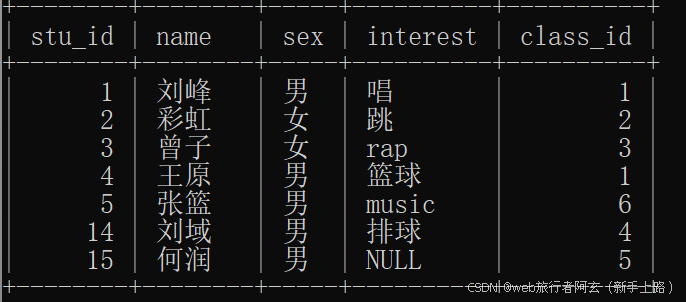

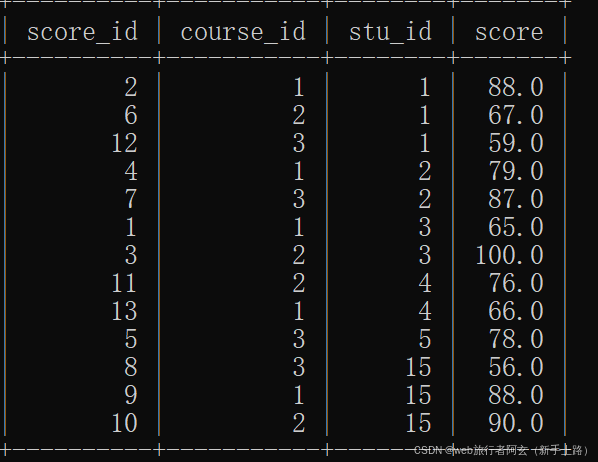
例:查询java语言大于计算机组成原理的成绩的记录
第一步,我们先连接三个表:
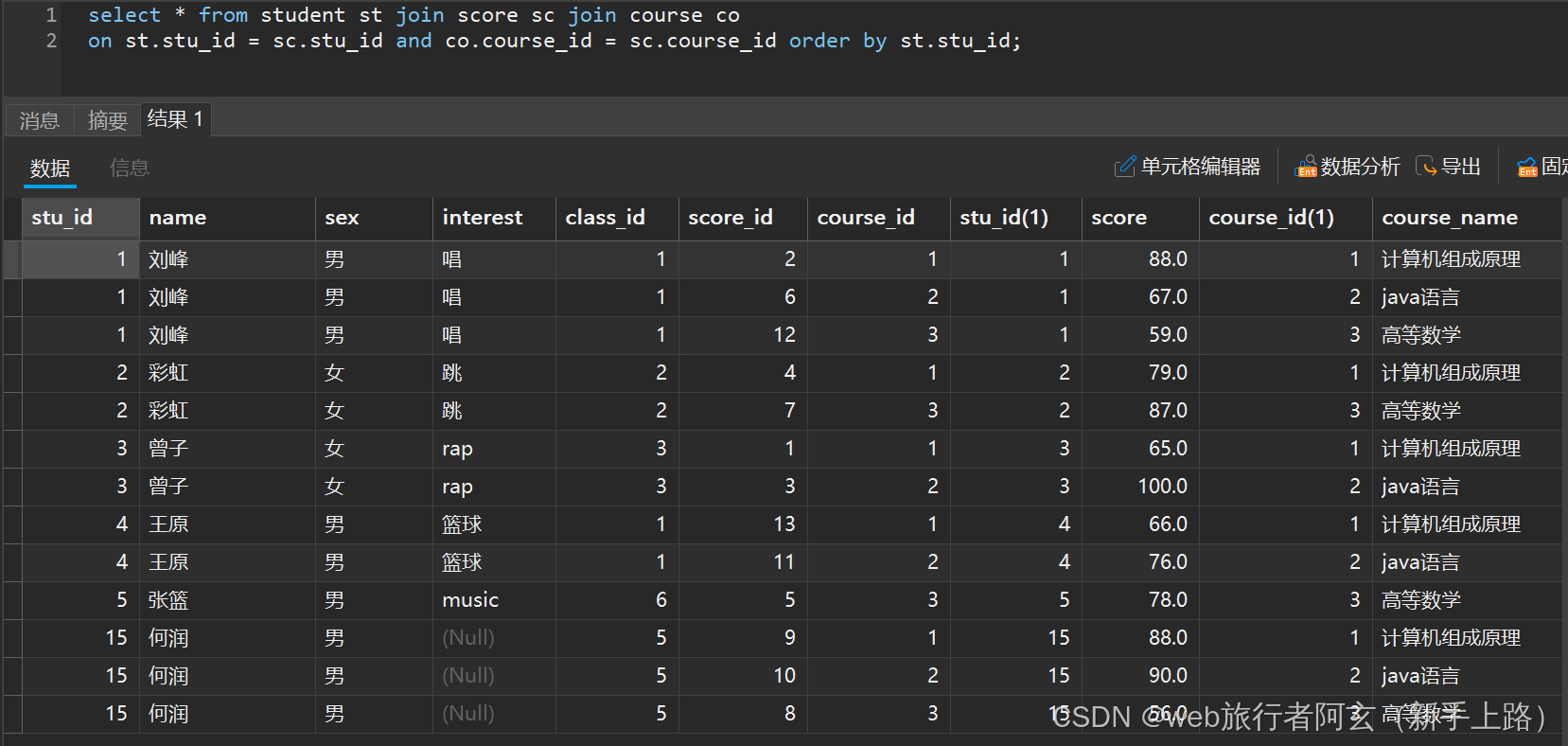
一般情况下,比较都是列与列进行比较的,但是行与行直接该如何比较呢?
先查询各科不一样的课程成绩取笛卡尔积(连接俩张成绩表,同一名学生不同成绩):
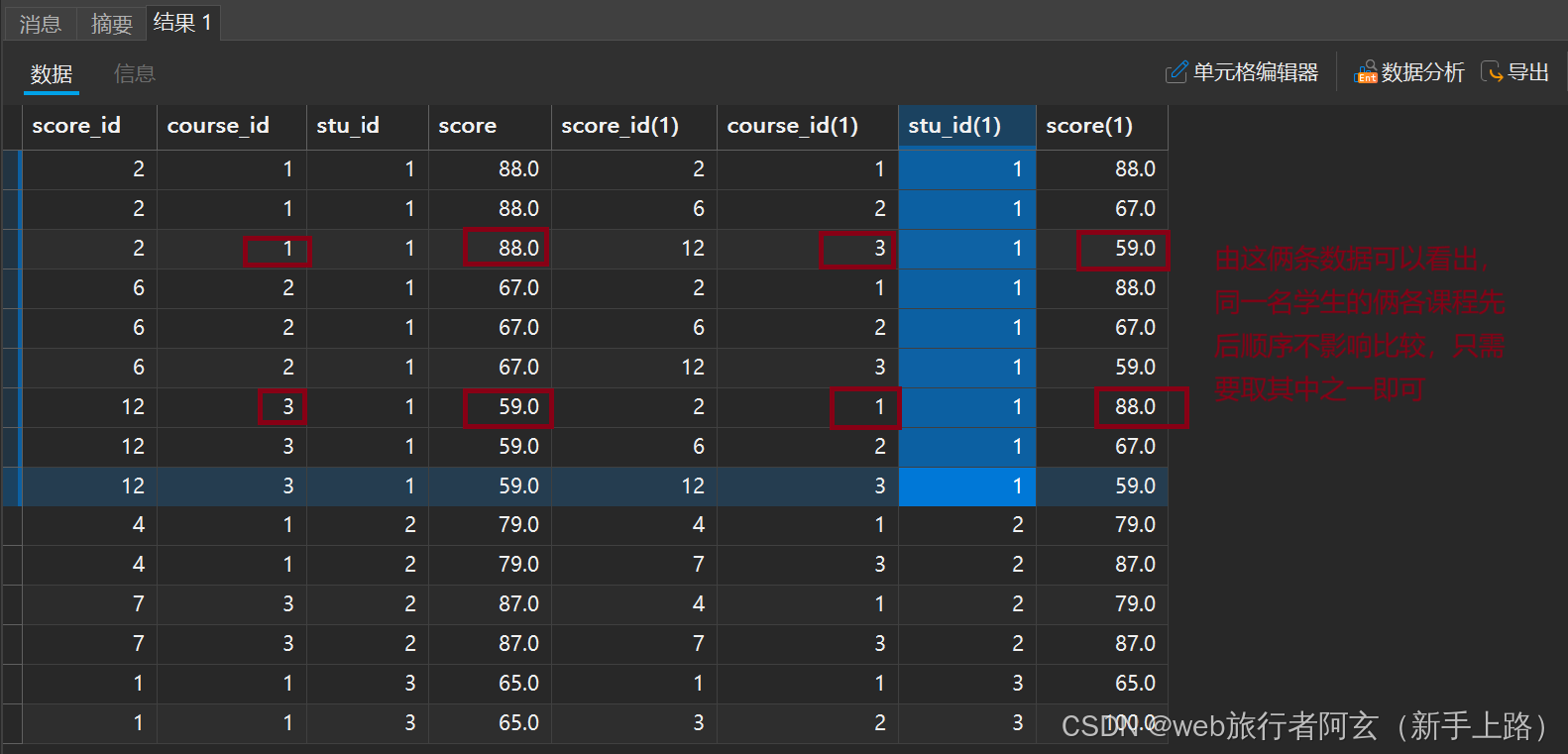
然后筛选出来java和高数的序列号,先后顺序不影响,取其一即可(取序列1和序列2):
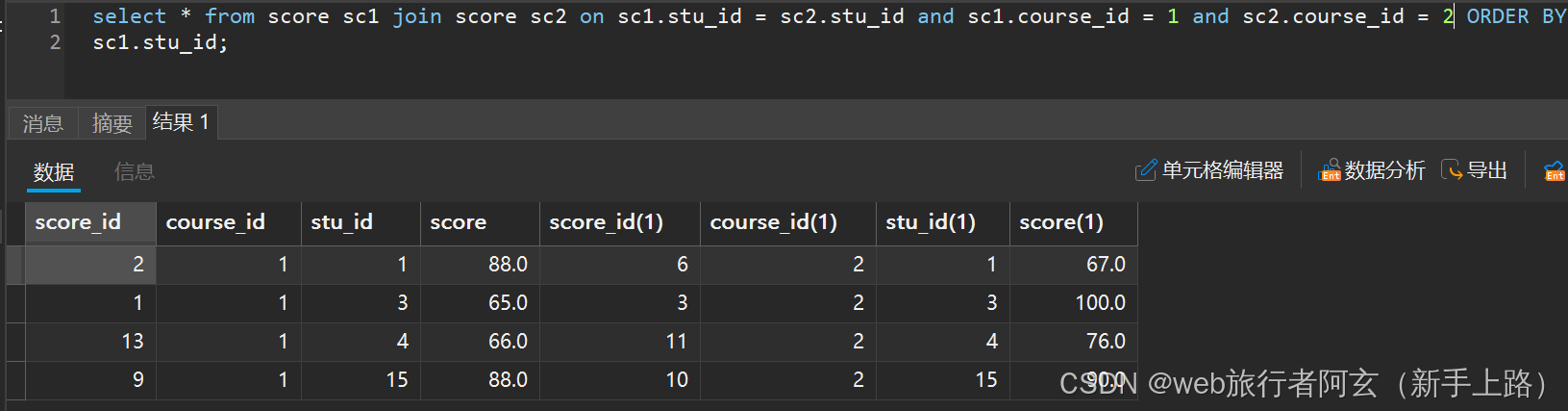
后面结合学生表,就可以进行列与列之间的比较了(课程表也需结合俩个,方便与成绩比较):
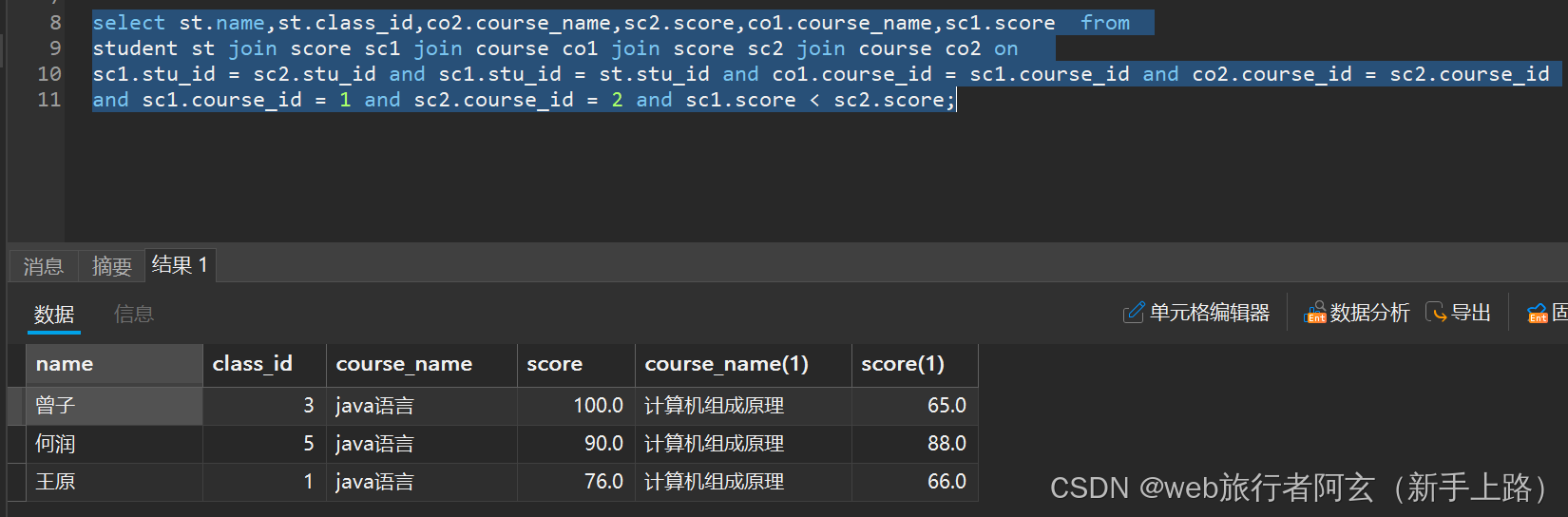
分类比较(简洁易懂):

例:
注意:若是俩表自连接的列名属性不一样,mysql是不会进行校验,所以结果可能会有问题。
自连接的时候要另外取别名,否则判别不出俩张相同表各自属性
子查询:
也称为嵌套查询,内层查询的查询结果作为外层查询的条件,把多条语句合并在一起。子查询可以无限嵌套,层数过多会影响效率。
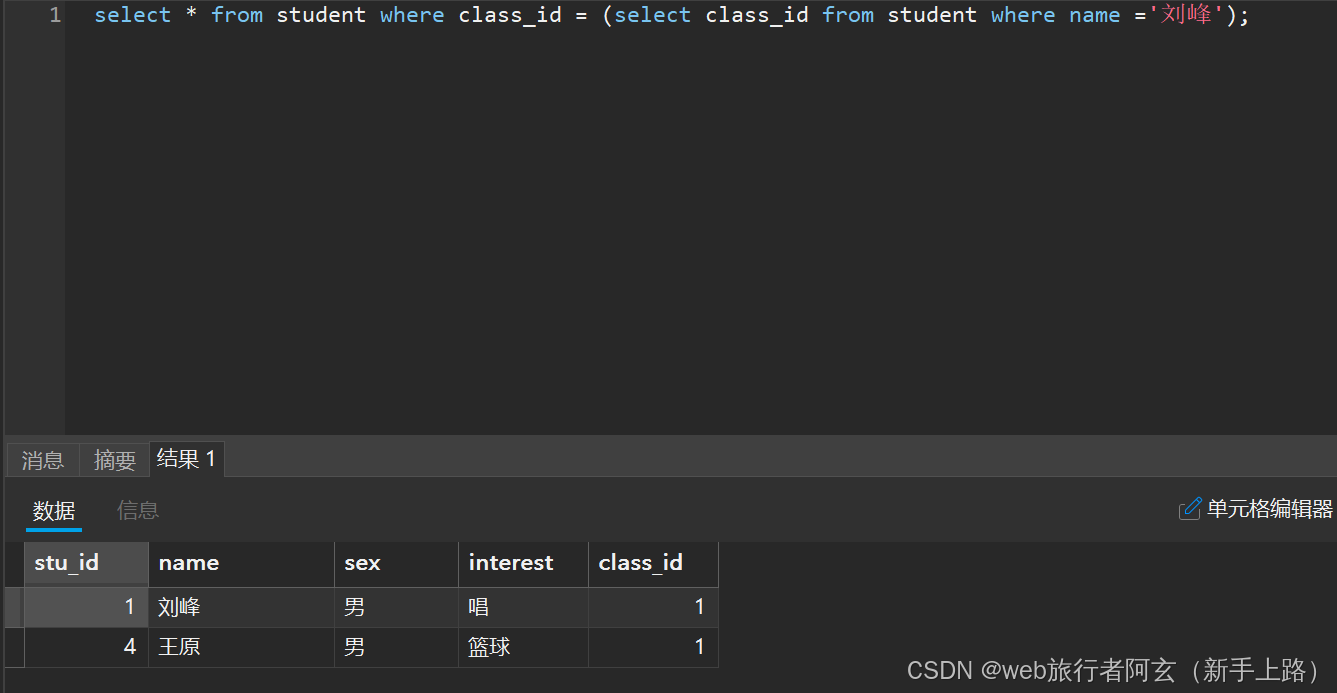
例:查询刘峰的同班同学:
合并查询:
合并多个select的执行结果
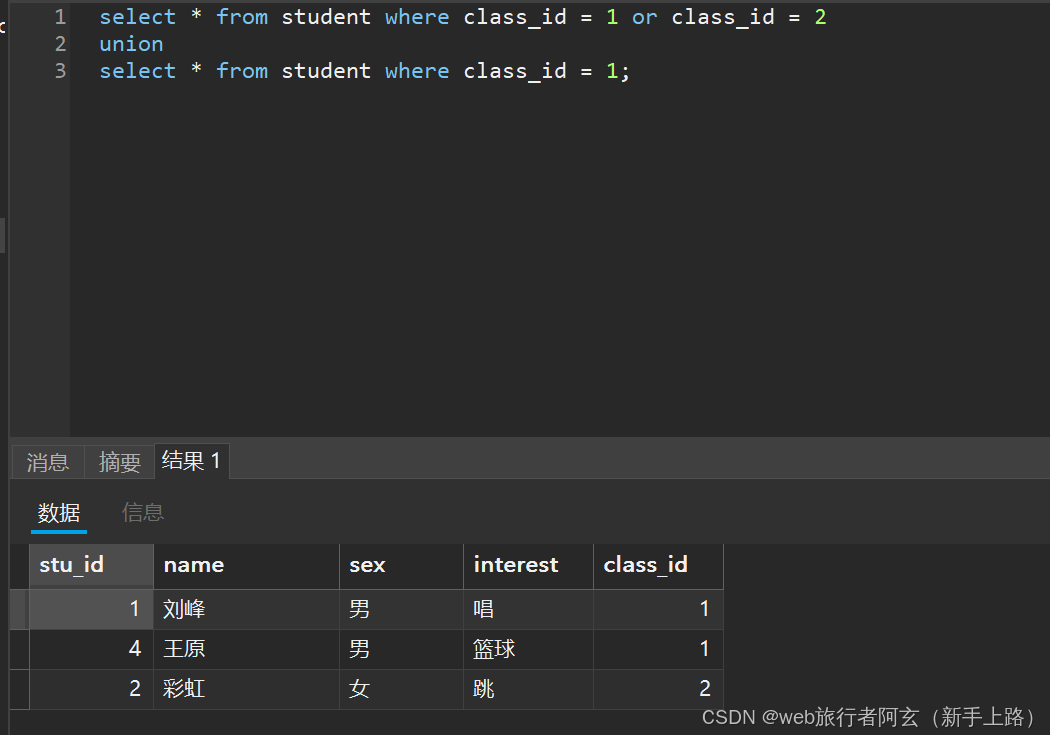
例:查询一班和二班的同学
union(会自动去掉结果集中的重复行):
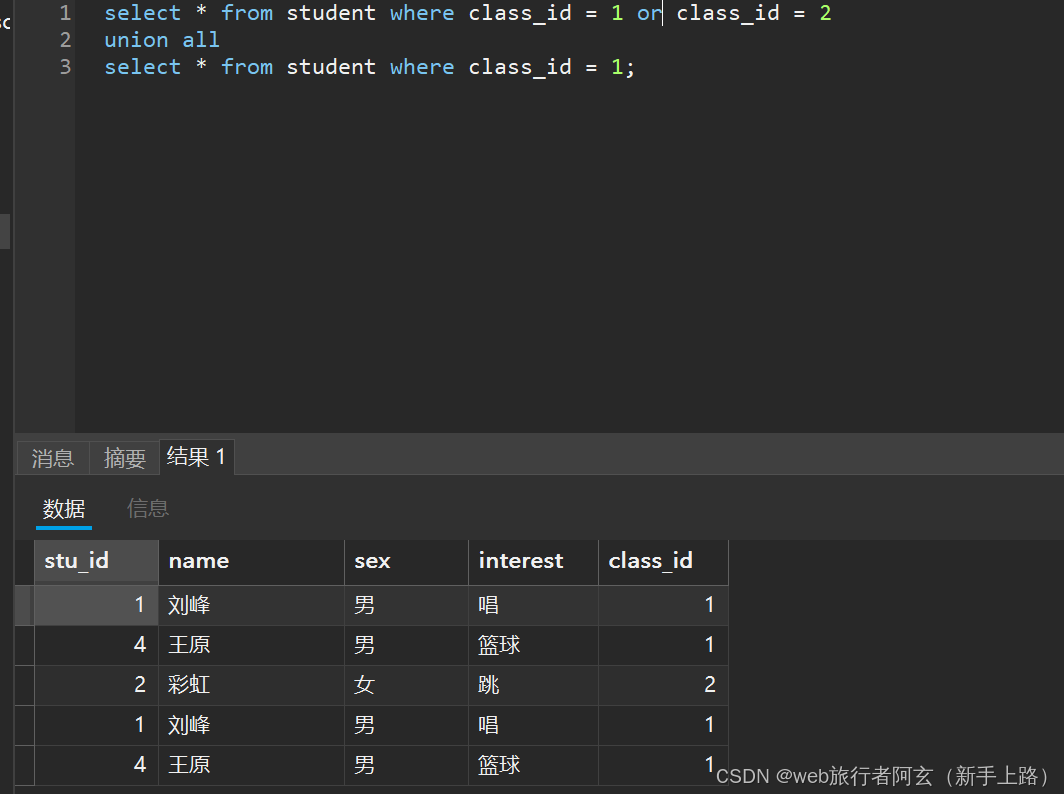
union all(不会去掉结果集中的重复行):
本次关于MySQL的基础使用就介绍到这里,后续还会有MySQL的进阶分享出来,制作不易,感谢大家的支持,谢谢!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » MySQL 表的增删改查

发表评论 取消回复