1. 项目背景
本文基于kaggle平台相关竞赛项目,具体连接如下:
Time Series Forecasting With SARIMAX
基本信息如内容说明、数据集、已提交代码、当前得分排名以及比赛规则等,如图【1】所示,可以认真阅读。
2. 数据读取
使用python得pandas包进行csv文件读取
# read train data
df = pd.read_csv("/kaggle/input/daily-climate-time-series-data/DailyDelhiClimateTrain.csv",
parse_dates=['date'], # change to date time format
index_col="date")
df
2.1 数据信息图形化观测
定义图表模板,对不同维度的数据进行图形化分析。
# Get the 'xgridoff' template
grid_template = pio.templates['xgridoff']
grid_template.layout.font.color = 'black' # Light gray font color
# Adjust gridline color and width
grid_template.layout.xaxis.gridcolor = 'rgba(0, 0, 0, 0.3)' # Light gray with transparency
grid_template.layout.yaxis.gridcolor = 'rgba(0, 0, 0, 0.3)' # Light gray with transparency
grid_template.layout.xaxis.gridwidth = 1 # Set gridline width
grid_template.layout.yaxis.gridwidth = 1 # Set gridline width
# Update Plotly templates with template
pio.templates['ts_template'] = grid_template
# plot mean temperature, humidity, wind_speed, meanpressure for watch
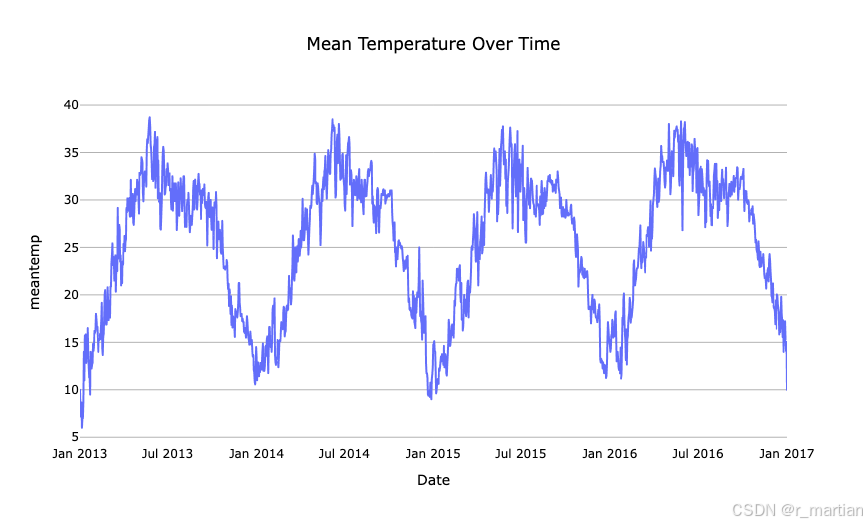
fig_meantemp = px.line(df, x=df.index, y='meantemp', title='Mean Temperature Over Time')
fig_meantemp.update_layout(template='ts_template', title_x=0.5, xaxis_title="Date")
fig_meantemp.show()
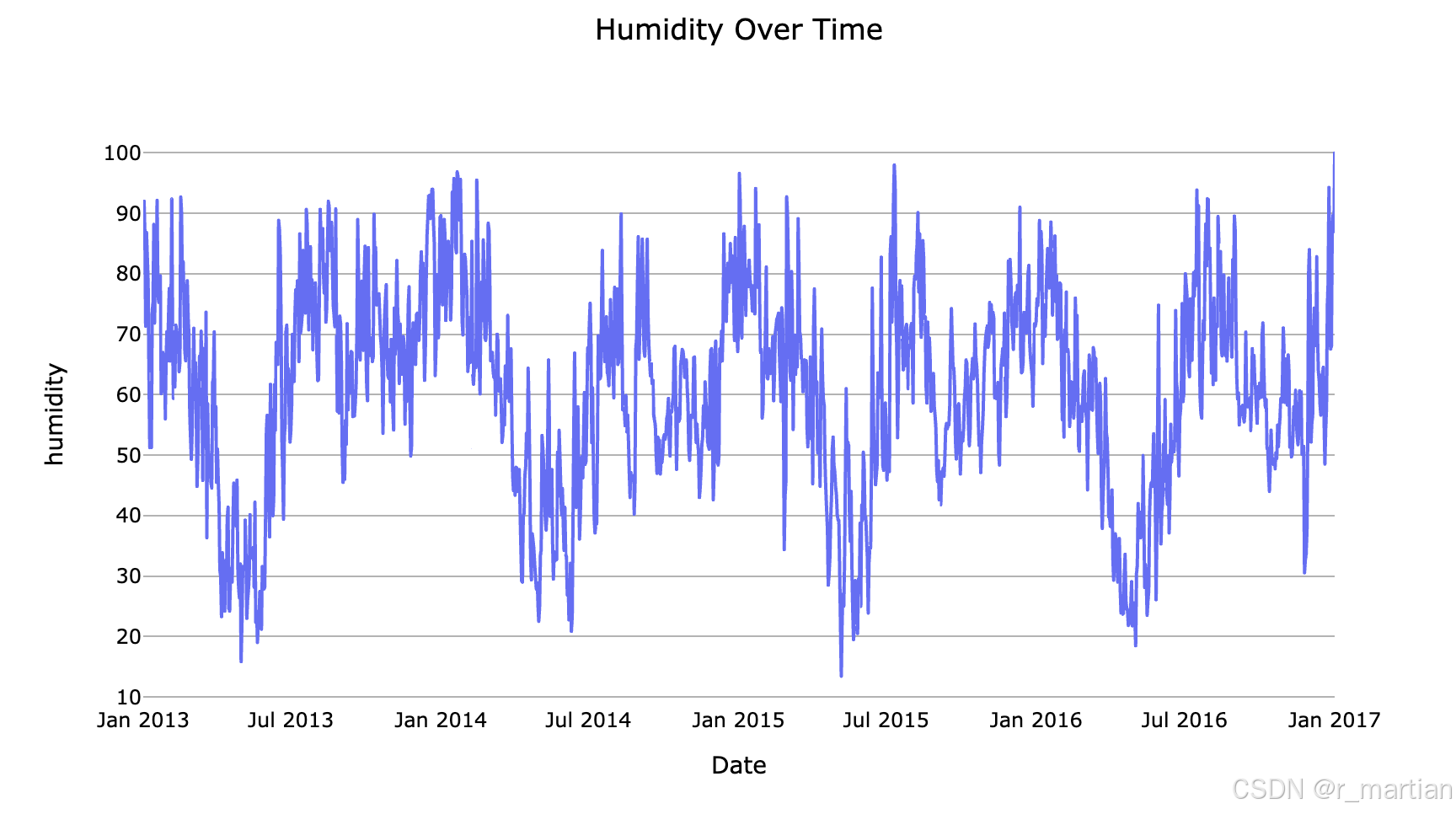
fig_humidity = px.line(df, x=df.index, y='humidity', title='Humidity Over Time')
fig_humidity.update_layout(template='ts_template', title_x=0.5, xaxis_title="Date")
fig_humidity.show()
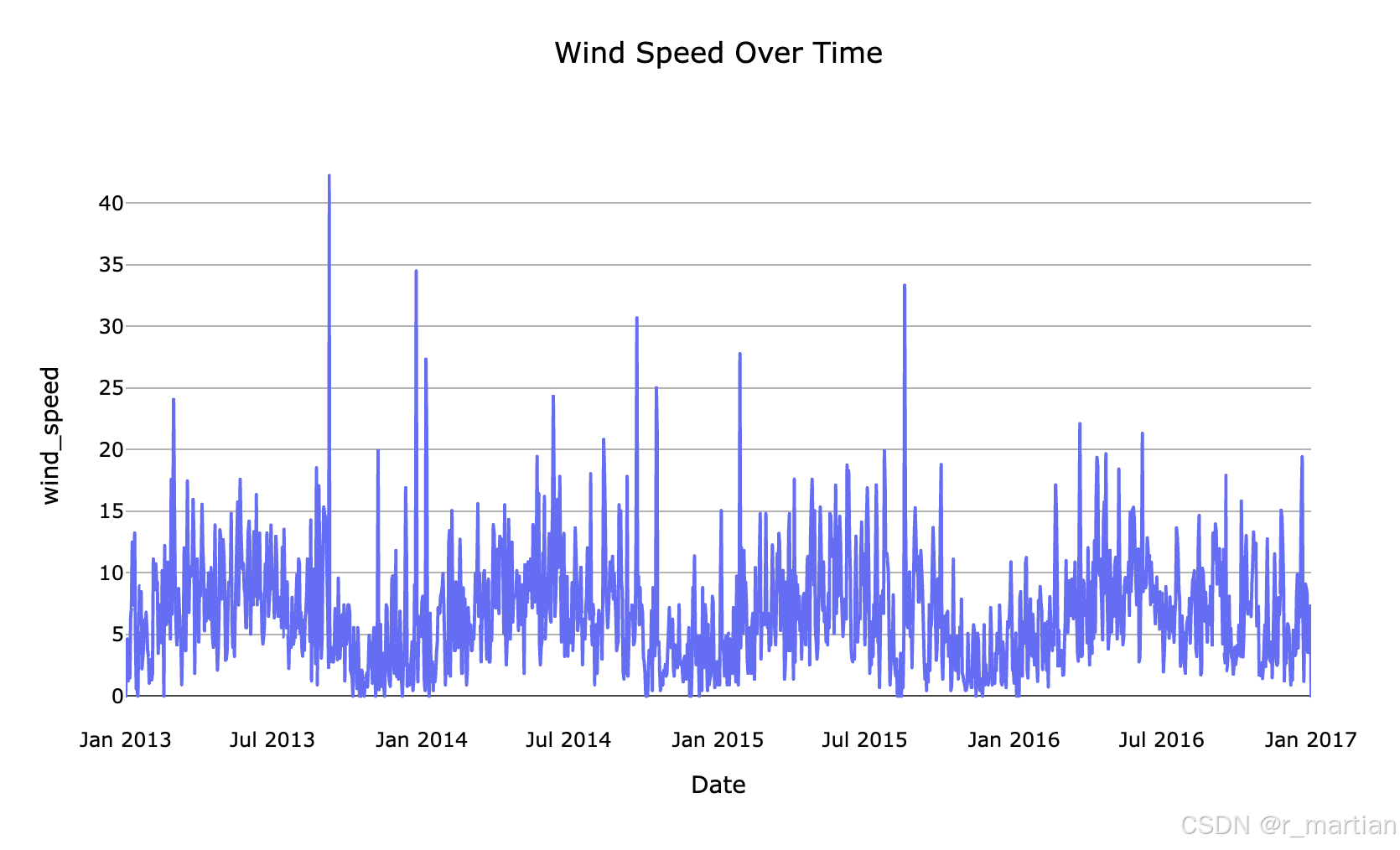
fig_wind_speed = px.line(df, x=df.index, y='wind_speed', title='Wind Speed Over Time')
fig_wind_speed.update_layout(template='ts_template', title_x=0.5, xaxis_title="Date")
fig_wind_speed.show()
fig_meanpressure = px.line(df, x=df.index, y='meanpressure', title='Mean Pressure Over Time')
fig_meanpressure.update_layout(template='ts_template', title_x=0.5, xaxis_title="Date")
fig_meanpressure.show()
可以从图中看到平均温度,湿度,风速,气压等数据波形图,也可以宏观的看到数据的趋势信息,为后续进一步学习做初步探索。
2.3 数据分量
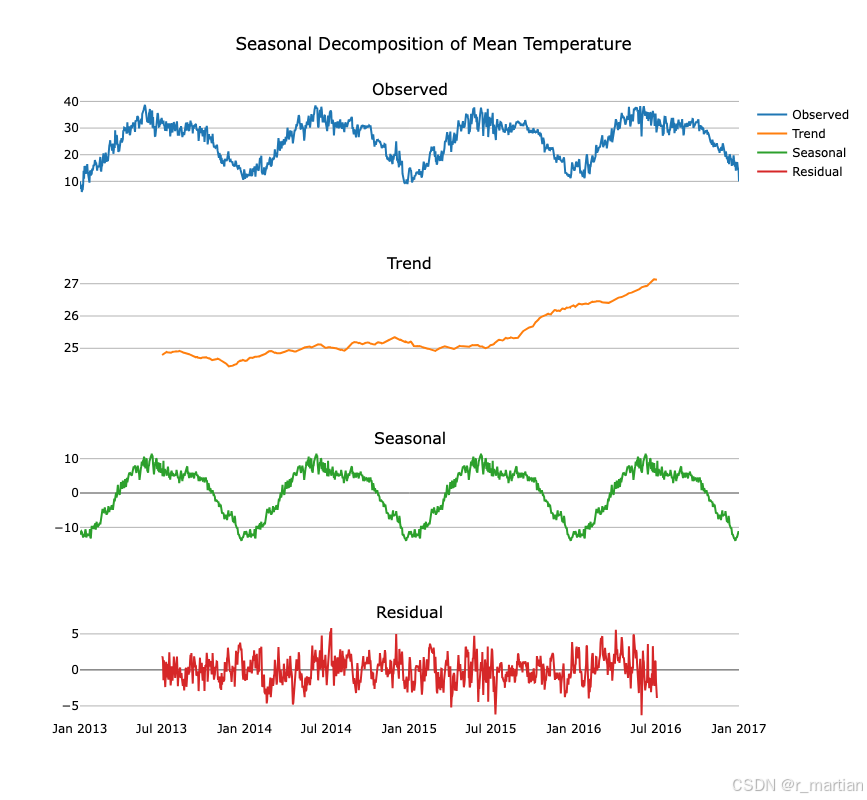
针对预测数据项平均温度,我们可以分解平均温度数据,进一步分析数据形态、特征。seasonal_decompose函数返回的是trend、seasonal和residual分别表示趋势、季节性和残留三部分的数据,observed代表原始序列。
from statsmodels.tsa.seasonal import seasonal_decompose
import plotly.subplots as sp
# Perform seasonal decomposition
result = seasonal_decompose(df['meantemp'], model='additive', period=365)
# Plot the decomposed components
fig = sp.make_subplots(rows=4, cols=1, shared_xaxes=True,
subplot_titles=['Observed', 'Trend', 'Seasonal', 'Residual'])
fig.add_trace(go.Scatter(x=df.index, y=result.observed, mode='lines', name='Observed'), row=1, col=1)
fig.add_trace(go.Scatter(x=df.index, y=result.trend, mode='lines', name='Trend'), row=2, col=1)
fig.add_trace(go.Scatter(x=df.index, y=result.seasonal, mode='lines', name='Seasonal'), row=3, col=1)
fig.add_trace(go.Scatter(x=df.index, y=result.resid, mode='lines', name='Residual'), row=4, col=1)
fig.update_layout(template= 'ts_template',height=800, title='Seasonal Decomposition of Mean Temperature')
fig.show()
从图中可以看出,平均温度数据具有很强的季节性,趋势是逐渐升高的,但是受噪音影响有限。
2.4 特征选取
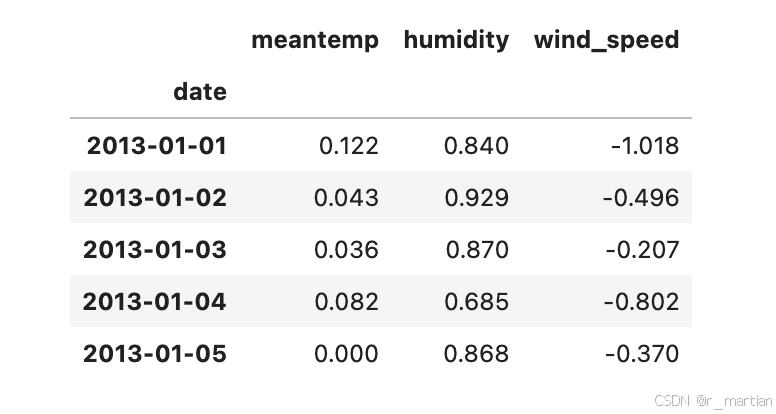
基于以上数据形态观测和分析,我们可以大致选定数据中的部分特征作为影响平均温度的因素(特征信息),这里就选定湿度和风速作为特征信息进行训练和预测。
df = df[['meantemp', 'humidity', 'wind_speed']]
df.head()
2.5 归一化
from sklearn.preprocessing import RobustScaler, MinMaxScaler
robust_scaler = RobustScaler() # scaler for wind_speed
minmax_scaler = MinMaxScaler() # scaler for humidity
target_transformer = MinMaxScaler() # scaler for target (meantemp)
dl_train['wind_speed'] = robust_scaler.fit_transform(dl_train[['wind_speed']]) # robust for wind_speed
dl_train['humidity'] = minmax_scaler.fit_transform(dl_train[['humidity']]) # minmax for humidity
dl_train['meantemp'] = target_transformer.fit_transform(dl_train[['meantemp']]) # target
dl_test['wind_speed'] = robust_scaler.transform(dl_test[['wind_speed']])
dl_test['humidity'] = minmax_scaler.transform(dl_test[['humidity']])
dl_test['meantemp'] = target_transformer.transform(dl_test[['meantemp']])
display(dl_train.head())
3. 序列稳定性验证
import statsmodels.api as sm
from statsmodels.tsa.stattools import adfuller, kpss
def check_stationarity(series):
print(f'\n___________________Checking Stationarity for: {series.name}___________________\n')
# ADF Test
adf_test = adfuller(series.values)
print('ADF Test:\n')
print('ADF Statistic: %f' % adf_test[0])
print('p-value: %f' % adf_test[1])
print('Critical Values:')
for key, value in adf_test[4].items():
print('\t%s: %.3f' % (key, value))
if (adf_test[1] <= 0.05) & (adf_test[4]['5%'] > adf_test[0]):
print("\u001b[32mSeries is Stationary (ADF Test)\u001b[0m")
else:
print("\x1b[31mSeries is Non-stationary (ADF Test)\x1b[0m")
print('\n' + '-'*50 + '\n')
# KPSS Test
kpss_test = kpss(series.values, regression='c', nlags='auto')
print('KPSS Test:\n')
print('KPSS Statistic: %f' % kpss_test[0])
print('p-value: %f' % kpss_test[1])
print('Critical Values:')
for key, value in kpss_test[3].items():
print('\t%s: %.3f' % (key, value))
if kpss_test[1] > 0.05:
print("\u001b[32mSeries is Stationary (KPSS Test)\u001b[0m")
else:
print("\x1b[31mSeries is Non-stationary (KPSS Test)\x1b[0m")
那么我们就可以针对选取的特征进行稳定性分析。
# Check initial stationarity for each feature
check_stationarity(df['meantemp'])
check_stationarity(df['humidity'])
check_stationarity(df['wind_speed'])
___________________Checking Stationarity for: meantemp___________________
ADF Test:
ADF Statistic: -2.021069
p-value: 0.277412
Critical Values:
1%: -3.435
5%: -2.864
10%: -2.568
Series is Non-stationary (ADF Test)
--------------------------------------------------
KPSS Test:
KPSS Statistic: 0.187864
p-value: 0.100000
Critical Values:
10%: 0.347
5%: 0.463
2.5%: 0.574
1%: 0.739
Series is Stationary (KPSS Test)
___________________Checking Stationarity for: humidity___________________
ADF Test:
ADF Statistic: -3.675577
p-value: 0.004470
Critical Values:
1%: -3.435
5%: -2.864
10%: -2.568
Series is Stationary (ADF Test)
--------------------------------------------------
KPSS Test:
KPSS Statistic: 0.091737
p-value: 0.100000
Critical Values:
10%: 0.347
5%: 0.463
2.5%: 0.574
1%: 0.739
Series is Stationary (KPSS Test)
___________________Checking Stationarity for: wind_speed___________________
ADF Test:
ADF Statistic: -3.838097
p-value: 0.002541
Critical Values:
1%: -3.435
5%: -2.864
10%: -2.568
Series is Stationary (ADF Test)
--------------------------------------------------
KPSS Test:
KPSS Statistic: 0.137734
p-value: 0.100000
Critical Values:
10%: 0.347
5%: 0.463
2.5%: 0.574
1%: 0.739
Series is Stationary (KPSS Test)
可以看到平均温度是不稳定的,那么就需要进行差分处理。具体什么是差分及差分阶数请自行查阅。
# 1st degree differencing
df['meantemp_diff'] = df['meantemp'].diff().fillna(0) # diff() default is 1st degree differencing
check_stationarity(df['meantemp_diff']);
___________________Checking Stationarity for: meantemp_diff___________________
ADF Test:
ADF Statistic: -16.294070
p-value: 0.000000
Critical Values:
1%: -3.435
5%: -2.864
10%: -2.568
Series is Stationary (ADF Test)
--------------------------------------------------
KPSS Test:
KPSS Statistic: 0.189493
p-value: 0.100000
Critical Values:
10%: 0.347
5%: 0.463
2.5%: 0.574
1%: 0.739
Series is Stationary (KPSS Test)
3. 模型训练和预测
# Split the data into training and testing sets
train_size = int(len(df) * 0.8)
train, test = df.iloc[:train_size], df.iloc[train_size:]
# SARIMAX
from statsmodels.tsa.statespace.sarimax import SARIMAX
from sklearn.metrics import mean_squared_error, r2_score, mean_absolute_error
# Define the SARIMA model parameters
order = (1, 1, 6) # Non-seasonal order (p, d, q)
seasonal_order = (1, 1, 1, 7) # Seasonal order (P, D, Q, S)
# Fit the SARIMA model
sarima_model = SARIMAX(endog=train['meantemp'], exog=train[['humidity', 'wind_speed']],
order=order, seasonal_order=seasonal_order)
sarima_model_fit = sarima_model.fit()
# Make predictions
sarima_pred = sarima_model_fit.predict(start=test.index[0], end=test.index[-1],
exog=test[['humidity', 'wind_speed']])
# Calculate error
mse = mean_squared_error(test['meantemp'], sarima_pred)
r2 = r2_score(test['meantemp'], sarima_pred)
print('Test MSE:', mse)
print('Test R²: %.3f' % r2)
# Plot the results
plt.figure(figsize=(10, 5))
plt.plot(test.index, test['meantemp'], label='Actual')
plt.plot(test.index, sarima_pred, color='red', label='SARIMA Forecast')
plt.xlabel('Date')
plt.ylabel('Meantemp')
plt.title('SARIMA Forecast')
plt.legend()
plt.show()
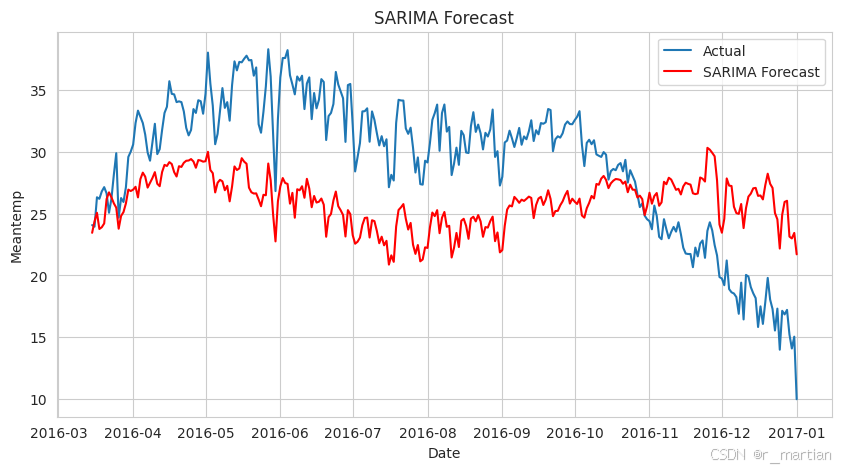
如上图所示,可以看到实际数据和预测数据的曲线图,从图中可以看到,预测值与实际值之间存在较大gap,这就说明模型泛化能力不好,对未来数据不能很好的预测。这就需要我们对模型参数进行调整,以期达到更好的效果。当然有些是受限于模型本身的局限性,始终无法对数据做出合理预测,那就需要我们寻找其他的模型,比如RNN、CNN、LSTM等更强大的深度学习模型来进行训练和预测。
参考文档
如有侵权,烦请联系删除
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 时序预测SARIMAX模型

发表评论 取消回复