跟着顶刊学习数据分析。本期参考文献《Trends in Dietary Vitamin A Intake Among US Adults by Race and Ethnicity, 2003-2018》,来源于JAMA,IF=63.1。
该文研究:2003-2018年美国成年人按种族和民族划分的膳食维生素A摄入量趋势
方法学:

该项研究使用的主要方法:Gamma广义线性回归模型用于估计黑人和西班牙裔参与者与白人参与者之间的平均维生素A摄入量差异。同时调整混杂因素并使用加权数据。
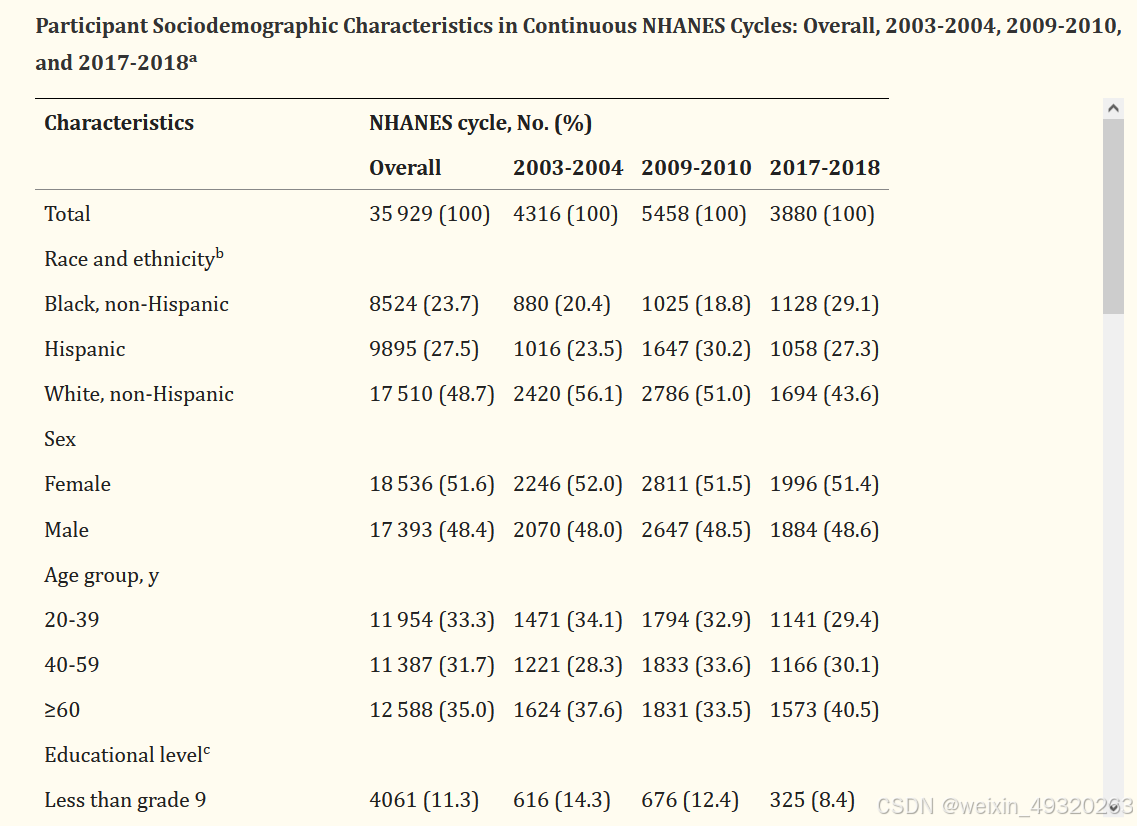
表:统计描述人口特征,未使用统计分析比较差异
图
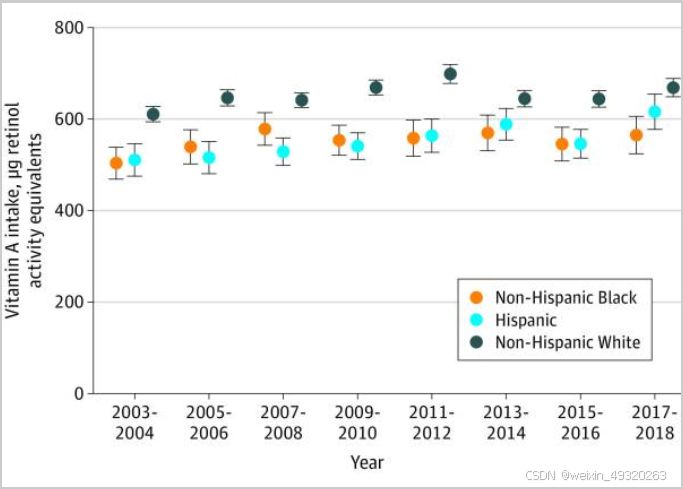
这幅图涉及统计分析比较策略。(1)Gamma广义线性回归模型,评估同一种族人膳食维生素A的摄取趋势。(2)不同种族的比较,方差分析,对比是否有差异。
R语言实现Gamma广义线性模型:
# 假设 data 是你的数据框,其中包含列 y 和 x
# 这里我们生成一些模拟数据作为示例
set.seed(123) # 为了可重复性
x <- rnorm(100)
y <- rgamma(100, shape = exp(1 + 0.5*x), scale = 0.5) # 生成Gamma分布数据
data <- data.frame(x, y)
# 拟合Gamma广义线性模型
model <- glm(y ~ x, family = Gamma) # 通常Gamma分布的链接函数是log
# 查看模型摘要
summary(model)
# 进行预测
predictions <- predict(model, newdata = data, type = "response")
# 打印部分预测结果
head(predictions)
# 可视化拟合效果
plot(y ~ x, data = data, main = "Gamma GLM Fit", xlab = "x", ylab = "y")
lines(sort(x), predictions[order(x)], col = "red")结果解读:
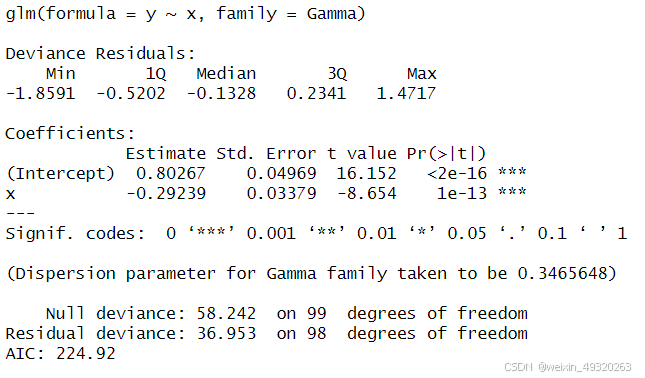
- 模型调用:
glm(formula = y ~ x, family = Gamma)表示使用了Gamma分布的广义线性模型来拟合y作为响应变量,x作为解释变量。
- 偏差残差:
- 这些残差是模型拟合后观察值与预测值之间的差异。它们被标准化以反映模型拟合的好坏。这里的范围从-1.8591到1.4717,说明模型在大多数点上都有较好的拟合,但也有一些较大的残差。
- 系数:
(Intercept)的估计值为0.80267,标准误差为0.04969,t值为16.152,对应的p值小于2e-16,表明截距项在统计上是高度显著的。x的估计值为-0.29239,标准误差为0.03379,t值为-8.654,对应的p值小于1e-13,表明x对y有显著的负向影响。
- 显著性代码:
- 在系数表下方,
***表示p值小于0.001,表明该系数在统计上高度显著。
- 在系数表下方,
- 分散参数:
- 对于Gamma分布,分散参数(Dispersion parameter)估计为0.3465648。在理想情况下,对于Gamma分布,这个值应该接近1,但这里小于1,可能意味着模型在某种程度上过度拟合了数据,或者数据的变异性小于Gamma分布通常假设的变异性。
- 偏差统计:
Null deviance(空模型偏差)为58.242,基于99个自由度。这表示如果没有x变量,仅使用截距项时,模型的偏差。Residual deviance(残差偏差)为36.953,基于98个自由度。这表示在加入x变量后,模型的偏差减少了,说明x对y有解释作用。
- AIC:
- 赤池信息量准则(AIC)为224.92,用于比较不同模型的拟合优度。AIC值越小,模型拟合通常认为越好。
- Fisher评分迭代次数:
- 模型通过5次迭代达到收敛,这是算法寻找最佳参数估计值的迭代次数。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » R语言数据整理和分析(1)

发表评论 取消回复