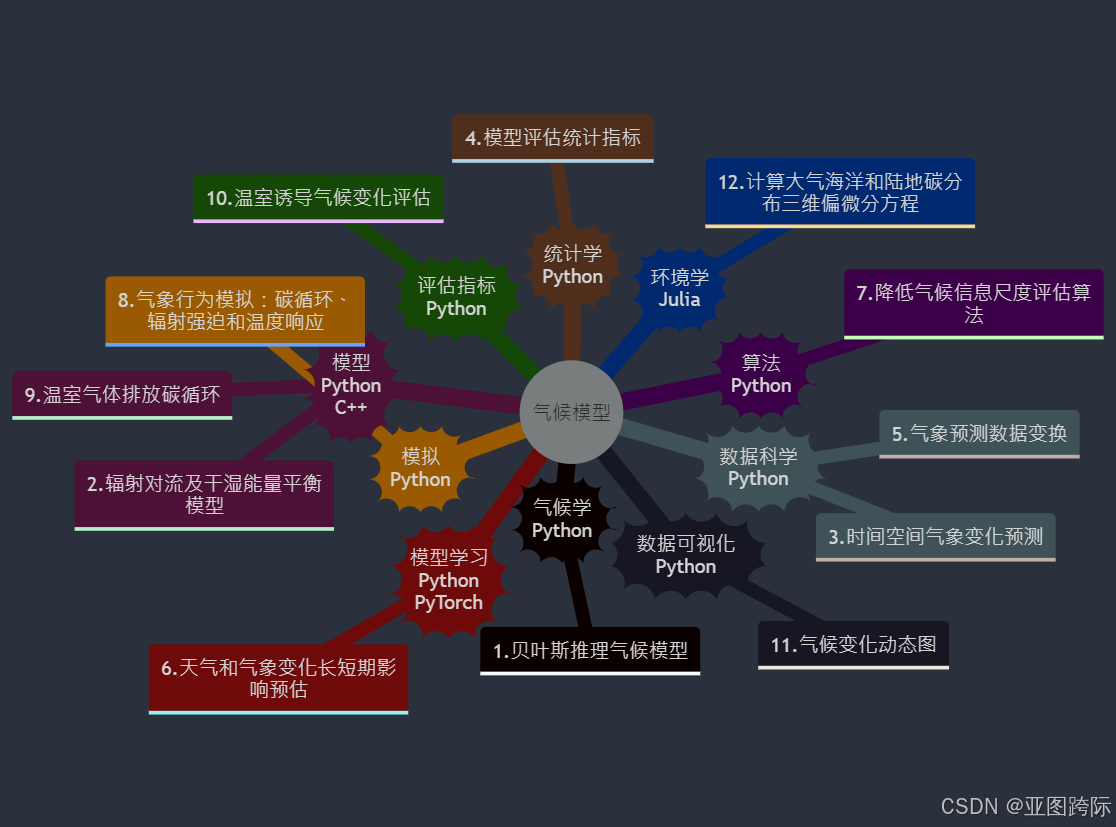
要点
- 贝叶斯推理气候模型
- 辐射对流及干湿能量平衡模型
- 时间空间气象变化预测
- 模型评估统计指标
- 气象预测数据变换
- 天气和气象变化长短期影响预估
- 降低气候信息尺度评估算法
- 气象行为模拟:碳循环、辐射强迫和温度响应
- 温室气体排放碳循环
- 温室诱导气候变化评估
- 气候变化动态图
- 计算大气海洋和陆地碳分布三维偏微分方程
Python气候数据
气候变化是指温度和天气模式的长期变化。由于太阳活动的变化或大型火山喷发,这种变化可能是自然的。但自 1800 年代以来,人类活动一直是气候变化的主要驱动因素,这主要是由于煤炭、石油和天然气等化石燃料的燃烧。
燃烧化石燃料会产生温室气体排放,这些气体就像包裹地球的毯子一样,捕获了太阳的热量并提高了温度。造成气候变化的主要温室气体包括二氧化碳和甲烷。例如,这些气体来自使用汽油驾驶汽车或使用煤炭为建筑物供暖。清理土地和砍伐森林也会释放二氧化碳。农业、石油和天然气作业是甲烷排放的主要来源。能源、工业、交通、建筑、农业和土地利用是造成温室气体的主要部门。
接下来,我将使用Python分析气候数据:
第一步是将数据集导入到 Pandas DataFrame 中。气候数据通常以 CSV 文件形式提供,也可以从在线存储库和 API 下载。
import pandas as pd
nyc_temp = pd.read_csv('nyc_temp.csv')
DataFrame 将包含日期、平均温度、最低温度等列。我们可以使用 nyc_temp.head()检查初始行,并使用 nyc_temp.info() 获取摘要统计信息。为了处理大型气候数据集,我们可能只需要从完整数据中提取某些区域或日期范围。 Pandas 提供了灵活的选项来处理这个问题:
nyc_temp_90s = pd.read_csv('nyc_temp.csv', parse_dates=['date'], index_col='date', usecols=[0,3], squeeze=True, decimal=',',
nrows=3652, skiprows=3653, names=['temp'])
nyc_temp_00s = pd.read_csv('nyc_temp.csv', parse_dates=['date'], index_col='date', usecols=[0,3], squeeze=True, decimal=',',
skiprows=7305, names=['temp'])
在这里,我们使用 parse_dates、index_col、usecols、squeeze、decimal、nrows、skiprows 等参数来有效提取分析所需的数据子集。
气候数据通常是按日期索引的时间序列数据。 Pandas 具有处理 DatetimeIndex 格式的时间序列数据的内置功能。读取 CSV 数据时的 parse_dates 和 index_col 参数可以将“日期”列指定为 Pandas DataFrame 索引。这会将日期转换为 Pandas DatetimeIndex:
import pandas as pd
climate_data = pd.read_csv('climate_data.csv', parse_dates=['date'], index_col='date')
print(climate_data.index)
# DatetimeIndex(['1990-01-01', '1990-01-02', '1990-01-03', ...,
# '2000-12-30'], dtype='datetime64[ns]', name='date', length=4017)
使用 DatetimeIndex,我们可以轻松地根据日期选择或过滤行以进行时间序列分析:
jan1990 = climate_data['1990-01']
fall_temp = climate_data[climate_data.index.month.isin([9,10,11])]
Pandas 扩展了时间序列数据的日期时间功能,包括日期偏移、频率转换、移动窗口操作等。这些在气候数据分析中非常有用。例如,一个常见的任务是将时间序列数据从每日频率重新采样到每月频率以进行趋势分析:
monthly_max = climate_data['Temperature'].resample('M').max()
滚动窗口操作有助于分析随时间推移的平滑趋势:
yearly_avg = climate_data['Temperature'].rolling(window=365).mean()
计算异常情况
crutem = pd.read_csv('CRU4.csv', parse_dates=['date'], index_col='date')
crutem_annual = crutem.resample('Y').mean()
baseline = crutem_annual['1961':'1990'].mean(axis=0)
anomalies = crutem_annual - baseline
print(anomalies.head())
输出与 1961-1990 基线期相比的年度全球温度异常:
date
1850 -0.405038
1851 -0.305846
1852 -0.564415
1853 -0.467172
1854 -0.573538
可视化气候趋势
import matplotlib.pyplot as plt
温度的基本时间序列线图:
nyc_temp['temp'].plot()
plt.title('NYC Temperatures')
plt.xlabel('Year')
plt.ylabel('Temperature (F)')
plt.show()
之前计算的异常可以绘制为折线图:
anomalies.plot()
plt.title('Global Temperature Anomalies')
plt.xlabel('Year')
plt.ylabel('Anomaly (Celsius)')
plt.show()
Seaborn 的时间序列图提供了更多自定义选项:
import seaborn as sns
sns.set()
ax = sns.lineplot(data=anomalies)
ax.set_title('Global Temperature Anomalies')
亚图跨际
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python和C++气候模型算法模型气候学模拟和统计学数据可视化及指标评估

发表评论 取消回复