目录
2.2.4 可以打开客户机验证一下,访问192.168.234.130:9200
2.2.6查看集群状态信息,访问192.168.234.130:9200/_cluster/state?pretty
2.2.8使用浏览器进行访问192.168.234.130:9100
一、ELK概述
ELK平台是一套完整的日志集中处理解决方案,将 ElasticSearch、Logstash 和 Kiabana 三个开源工具 配合使用, 完成更强大的用户对日志的查询、排序、统计需求。
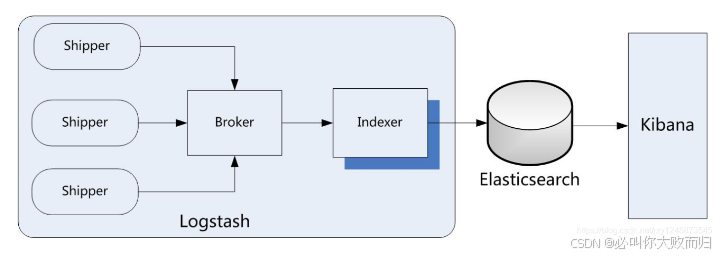
ELK 是 Elasticsearch、Logstash、Kibana 的缩写,这三个工具组合在一起,用于数据收集、存储、 搜索和可视化分析。它们的角色如下:
Elasticsearch:核心搜索和分析引擎,负责存储数据并提供快速的全文搜索和分析功能。
Logstash:数据收集和处理管道,能够从各种来源(如日志文件、数据库)收集数据,并进行过 滤和转换,然后将其发送到Elasticsearch。
Kibana:数据可视化工具,提供图形界面来展示和分析存储在Elasticsearch中的数据,支持创建 各种图表和仪表板。
框架图如下:
1.1 为什么要使用ELK日志分析系统
通常来说,日志被分散的存储在各自的不同的设备上,如果说需要管理上百台机器,那么就需要使用传统的方法依次登录这上百台机器进行日志的查阅,这样会使得工作效率即繁琐且效率低下。所以就引出了把日志集中化的管理方法。
下面是传统日志服务器的优点和缺点
- 优点:提高安全性,集中存放日志
- 缺点:因为是集中存放日志,所以说对日志的分析是比较困难的
由上得知传统日志服务器的缺点就是不方便工作人员进行日志的统计、检索,那么一般工作人员会使用grep、awk和wc等linux命令进行统计和检索,但是对于更高要求的查询、排序、统计,再加上庞大的机器数量,再让工作人员使用这种方法就显得力不从心了。
而ELK日志分析系统就完美的解决了上面的问题。它是一个开源、实时的日志分析系统。
官方网站是: https://www.elastic.co/products
1.2 ELK日志的分类
- 系统日志
- 应用程序日志
- 安全日志
1.3 ELK日志分析系统的分类
ELK日志分析系统是由三个完全开源的软件组合而成:Elasticsearch,logstash,kibana
1.3.1Elasticsearch:
Elasticsearch是一个开源的分布式搜索引擎, 特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。 它是基于Lucene的搜索服务器,提供了一个分布式多用户能力的全文搜索引擎。java开发,并且作为apache许可条款下的开放源码发布, 是第二流行的企业搜索引擎。设计用于云计算中,能够达到实时搜索,稳定、可靠、快速、安装使用方便。
1.3.2核心功能
- 全文搜索:它能够对文本数据进行快速的搜索
- 实时数据分析:支持实时的数据分析与查询,适合用于日志分析,监控数据的实时处理的场景
- 分布式架构:基于分布式架构设计,支持跨集群的数据储存与检索,使其在拓展性和性能上有很大的优势
- RESTful API:支持多种接口。
1.3.3架构与组件
- 集群:一个集群就是由一个或者多个点组织在一起,他们共同持有整个的数据,并且一起提供索引和搜索功能。集群中会有一个节点作为主节点,这个主节点可以通过选举产生,并且提供跨节点的联合索引和搜索的功能。
- 节点:节点就是一台单一的服务器,他是集群的一部分,进行存储数据并且参与集群的索引和搜索功能。和集群相同,节点也是通过名称来进行标识。
- 索引:一个索引就是一个拥有相似特征的文档的集合。在一个集群中,一个索引由一个名字来进行标识。索引相当于关系数据库里的库。索引对应着库,类型对应着表,文档对应着数据
- 类型:在一个索引中,用户可以定义一种或者多种类型,一个类型是你的索引的一个逻辑上的分类分区,其语义会完全由用户来定义。通常来说,会为具有一组共同字段的文档定义一个类型。例如:买裤子,搜索会出现牛仔裤,休闲裤。
- 文档:一个文档是一个可以被索引的基础信息单元。一个文档在物理上位于一个索引中,实际上一个文档必须在一个索引内被索引或给这个文档分配一个类型
- 分片:在实际情况中,索引储存的数据可能超过单个节点的硬件限制,为了解决这个问题,elasticsearch提供将索引分成多个分片的功能,当在创建索引的时候,可以自定义想要分片的数量,每一个分片就是一个全功能的独立的索引,可以位于集群中的任何节点上。
- 副本:分布式分片的机制和搜索请求的文档如何汇总完全是由elasticsearch控制的,这些对于用户而言是透明的。为了防止网络问题和其他的各种问题在任何时候不清自来,一些用户建议要有一个故障切换机制,来应对任何故障而导致的分片或者借鉴的不可用
总的来说,每个索引可以被分成多个分片,一个索引也可以被复制0次(即没有复制)或者多次,一旦复制了,每个索引就有了主分片 (即作为复制源的原来的分片) 和复制分片 (即主分片的拷贝) 的分别。 (也就是 说只要索引被复制了一次,那么就会产生主分片和复制分片也就是两个分片)
分片和副本的数量可以在索引创建的时候指定,在索引创建之后,用户可以在任何时候动态的改变副本的数量,但是之后用户无法改变分片的数量。
默认情况下,Elasticsearch中的每个索引都被分片成5个主分片和1个副本,这意味着,如果用户的集群中至少有两个节点,那么你的索引将会有5个主分片和另外5个副本分片还有一个索引的完全拷贝,这样的化每个索引总共就有10个分片
1.4logstash
logstash是一个完全开源的工具,他可以对你的日志进行收集,过滤并且将其进行存储。他是由JRuby语言编写,基于消息(message-based)的简单架构,并且运行在java虚拟机上(即JVM),不同于分离的代理段(agent)或者主机端(server),LogStash可以配置单一的代理段(agent)于其他开源软件结合,来实现不同的功能。
logstash的原理很简单:
- collect:数据输入
- enrich:数据加工,例如:过滤,改写等
- transport:数据输出
1.5kibana
Kiabna是一个完全开源的工具,它可以为Logstash和Elasticsearch提供可视化的web界面。 并且可以帮助用户进行汇总、分析和搜索重要的数据日志。使用Kibana,可以通过各种图表进行高级数据分析以及展示。它让海量数据更容易理解,操作简单,基于浏览器的用户界面可以快速创建仪表盘(dashboard,一种图表)实时显示Elasticsearch查询动态。设置Kibana非常简单,无需编写代码,几分钟之内就可以完成Kibana的安装并且启动Elasticsearch索引监测。
Kibana主要功能:
数据可视化:
- 支持多种图表类型,如折线图、柱状图、饼图、热图等,用户可以根据需要选择合适的可视化形式。
- 可以创建仪表板,集成多个可视化组件,方便用户查看和分析数据。
实时数据分析:
- Kibana 能够实时更新数据,用户可以在仪表板上实时监控数据变化,适用于需要快速响应的场景。
强大的搜索功能:
- 利用 Elasticsearch 的强大搜索能力,用户可以进行复杂的查询和过滤,以便深入分析数据。
- 支持布尔逻辑查询、范围查询和聚合查询等多种查询方式。
时间序列分析:
- 支持对时间序列数据的可视化,用户可以轻松分析数据随时间的变化趋势,适合监控日志、指标等数据。
地理空间数据可视化:
- 能够处理地理信息,用户可以通过地图可视化地理分布的数据,适合地理分析和位置相关的数据展示。
监控和警报:
- Kibana 可以与 Elastic Stack 的其他组件结合,设定监控和警报规则,帮助用户及时发现异常情况。
报告和分享:
- 用户可以生成可共享的报告,方便与团队成员或其他利益相关者分享数据分析结果。
用户管理和安全性:
- 支持用户权限管理,确保数据的安全性和隐私性,可以根据角色控制用户访问的权限。
1.6ELK的工作原理
(1)在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上, 在日志服务器上部署 Logstash。
(2)Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
(3)Elasticsearch 对格式化后的数据进行索引和存储。
(4)Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
二、部署ELK日志分析系统
2.1实验环境
| 配置与名称 | ip | 服务 |
| node1节点 | 192.168.234.130 | elasticsearch:端口9200 elasticsearch-head插件:端口9100 kibana 日志分析平台:端口5601 |
| node2节点 | 192.168.234.140 | elasticsearch:端口9200 logstash-日志采集 |
2.2实验步骤
2.2.1node1
[root@localhost ~]# hostnamectl set-hostname node1
[root@localhost ~]# bash
[root@node1 ~]# systemctl stop firewalld
[root@node1 ~]# setenforce 0
[root@node1 ~]#
[root@node1 ~]# echo '192.168.234.130 node1' >> /etc/hosts
[root@node1 ~]# echo '192.168.234.140 node2' >> /etc/hosts
[root@node1 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.234.130 node1
192.168.234.140 node2
[root@node1 ~]#
[root@node1 ~]#
[root@node1 ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
2.2.2node2
[root@localhost ~]# hostnamectl set-hostname node1
[root@localhost ~]# bash
[root@node1 ~]#
[root@node1 ~]#
[root@node1 ~]# hostnamectl set-hostname node2
[root@node1 ~]# bash
[root@node2 ~]# echo '192.168.234.130 node1' >> /etc/hosts
[root@node2 ~]# echo '192.168.234.140 node2' >> /etc/hosts
[root@node2 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.234.130 node1
192.168.234.140 node2
[root@node2 ~]#
[root@node2 ~]#
[root@node2 ~]# java -version
openjdk version "1.8.0_131"
OpenJDK Runtime Environment (build 1.8.0_131-b12)
OpenJDK 64-Bit Server VM (build 25.131-b12, mixed mode)
2.2.3安装elasticsearch(两个节点都操作)
[root@node1 opt]# ls
boost_1_59_0.tar.gz mysql-5.7.17 nginx-1.22.0 redis-5.0.7
elasticsearch-6.6.1.rpm mysql-5.7.17.tar.gz nginx-1.22.0.tar_(1).gz rh
[root@node1 opt]#
[root@node1 opt]#
[root@node1 opt]# rpm -ivh elasticsearch-6.6.1.rpm
warning: elasticsearch-6.6.1.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ################################# [100%]
Creating elasticsearch group... OK
Creating elasticsearch user... OK
Updating / installing...
1:elasticsearch-0:6.6.1-1 ################################# [100%]
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using systemd
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
### You can start elasticsearch service by executing
sudo systemctl start elasticsearch.service
Created elasticsearch keystore in /etc/elasticsearch
[root@node1 opt]#
[root@node1 opt]#
[root@node1 opt]# systemctl daemon-re
daemon-reexec daemon-reload
[root@node1 opt]# systemctl daemon-re
daemon-reexec daemon-reload
[root@node1 opt]# systemctl daemon-reload
[root@node1 opt]# systemctl enable elasticsearch.service
Created symlink from /etc/systemd/system/multi-user.target.wants/elasticsearch.service to /usr/lib/systemd/system/elasticsearch.service.
[root@node1 opt]# cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml_bak
[root@node1 opt]# vim /etc/elasticsearch/elasticsearch.yml
****************************************************************
16 #
17 cluster.name: my-elk-cluster #集群名称
18 #
。。。。。。
22 #
23 node.name: node1 #节点服务器名称,node2写node2即可
24 #
。。。。。。
32 #
33 path.data: /data/elk_data #数据存放路径
34 #
。。。。。。
36 #
37 path.logs: /var/log/elasticsearch/ #日志存放路径
38 #
。。。。。。
42 #
43 bootstrap.memory_lock: false #在启动时不锁定内存
44 #
。。。。。。
54 #
55 network.host: 0.0.0.0 #提供服务绑定的ip地址,0.0.0.0表示所有地址
56 #
。。。。。。
58 #
59 http.port: 9200 #侦听端口
60 #
。。。。。。
67 #
68 discovery.zen.ping.unicast.hosts: ["node1", "node2"] #集群发现通过单播传输实现
69 #
保存退出
************************************************************
[root@node1 opt]# mkdir -p /data/elk_data
[root@node1 opt]#
[root@node1 opt]# chown elasticsearch.elasticsearch /data/elk_data/
[root@node1 opt]#
[root@node1 opt]#
[root@node1 opt]# systemctl start elasticsearch.service
[root@node1 opt]# netstat -anpt |grep 9200
tcp6 0 0 :::9200 :::* LISTEN 3352/java2.2.4 可以打开客户机验证一下,访问192.168.234.130:9200
2.2.5查看集群的健康状态,显示status:'green'则节点健康运行,访问:192.168.234.130:9200/_cluster/health?pretty
2.2.6查看集群状态信息,访问192.168.234.130:9200/_cluster/state?pretty
2.2.7
因为以上的查看方式不方便,所以可以考虑安装elasticsearch-head插件,方便管集群
这里只在node1上面操作
可以先等node1安装完这个插件之后,node2在安装,安装时过程较长,node2可以先做上面的步骤
—————————————————————————————————扩展———————————————————————————————————
elasticsearch在5.0版本之后,elasticsearch-head插件需要作为独立服务进行安装
需要使用npm安装,并且需要提前安装node和phantomjs
node:基于chrome V8引擎和javascript运行环境
phantomjs:基于webkit的javascriptAPI。这个可以理解为一个隐形的浏览器,可以做到webkit浏览器的作用
————————————————————————————————————————————————————————————————————————
******(1)编译安装node,需要四十分钟左右
[root@node1 ~]# ll (上传node和phantomjs的软件包)
总用量 122152
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
-rw-r--r-- 1 root root 30334692 3月 30 23:13 node-v8.2.1.tar.gz
-rw-r--r-- 1 root root 23415665 3月 30 23:13 phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 ~]# tar xf node-v8.2.1.tar.gz
[root@node1 ~]# cd node-v8.2.1
[root@node1 node-v8.2.1]# ./configure && make && make install (时间较长,大约半小时左右)
******(2)安装phantomjs
[root@node1 ~]# ll
总用量 122156
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
drwxr-xr-x 10 502 games 4096 3月 30 23:45 node-v8.2.1
-rw-r--r-- 1 root root 30334692 3月 30 23:13 node-v8.2.1.tar.gz
-rw-r--r-- 1 root root 23415665 3月 30 23:13 phantomjs-2.1.1-linux-x86_64.tar.bz2
[root@node1 ~]# tar xf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/src/
[root@node1 ~]# cp /usr/src/phantomjs-2.1.1-linux-x86_64/bin/phantomjs /usr/local/bin/
******(3)安装elasticsearch-head
[root@node1 ~]# tar xf elasticsearch-head.tar.gz -C /usr/src/ (解压)
[root@node1 ~]# cd /usr/src/elasticsearch-head/
[root@node1 elasticsearch-head]# npm install (使用npm安装)
npm WARN optional SKIPPING OPTIONAL DEPENDENCY: fsevents@^1.0.0 (node_modules/karma/node_modules/chokidar/node_modules/fsevents):
npm WARN network SKIPPING OPTIONAL DEPENDENCY: request to https://registry.npmjs.org/fsevents failed, reason: getaddrinfo ENOTFOUND registry.npmjs.org registry.npmjs.org:443
npm WARN elasticsearch-head@0.0.0 license should be a valid SPDX license expression
up to date in 2.707s
[root@node1 elasticsearch-head]# cd
******(4)修改elasticsearch主配置文件
[root@node1 ~]# vim /etc/elasticsearch/elasticsearch.yml
。。。。。。
末尾添加
http.cors.enabled: true #开启跨域访问支持,默认为false,所以需要改成true
http.cors.allow-origin: "*" #跨域访问允许所有的域名地址
保存退出
[root@node1 ~]# systemctl restart elasticsearch (重启服务)
******(5)启动elasticsearch-head服务
————————————————————注意!!!!—————————————————
此操作必须在解压的目录下启动,进程会读取目录中的gruntfile.js文件,否则可能会失败
监听端口为:9100
————————————————————————————————————————————————
[root@node1 ~]# cd /usr/src/elasticsearch-head/ (进入解压目录)
[root@node1 elasticsearch-head]# ll Gruntfile.js (查看指定文件)
-rw-r--r-- 1 root root 2231 7月 27 2017 Gruntfile.js
[root@node1 elasticsearch-head]# npm start & (挂到后台启动)
[1] 61130
[root@node1 elasticsearch-head]#
> elasticsearch-head@0.0.0 start /usr/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
[root@node1 elasticsearch-head]# netstat -anpt | grep 9100 (检查是否成功启动)
tcp 0 0 0.0.0.0:9100 0.0.0.0:* LISTEN 61140/grunt
[root@node1 elasticsearch-head]# netstat -anpt | grep 9200
tcp6 0 0 :::9200 :::* LISTEN 1154/java
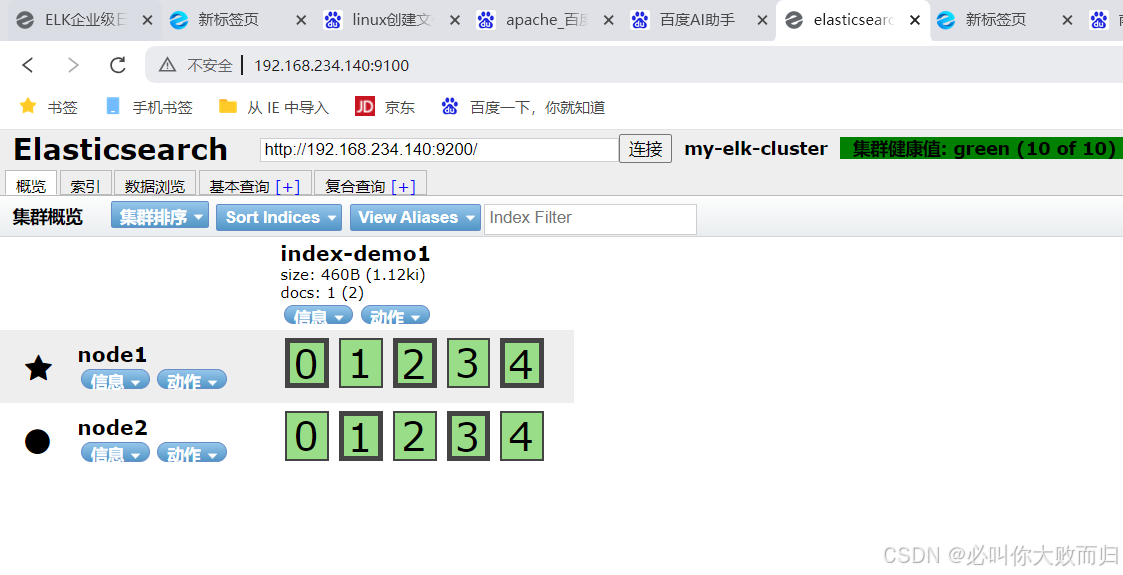
2.2.8使用浏览器进行访问192.168.234.130:9100
然后在展示的页面的最上面输入9192.168.234.130:9200
2.2.9部署logstash
logstash命令选项:
-f 通过这个命令可以指定logstash的配置文件,根据配置文件来配置logstash
-e 后面跟着字符串,该字符串可以被当作logstash的配置,如果是""则默认使用stdin作为输入,stdout作为输出
-t 测试配置文件是否正确,然后退出
******(1)安装logstash,安装这个需要java环境,之前两台node已经装过了
[root@node2 ~]# ll (上传logstash的rpm包)
总用量 161612
-rw-------. 1 root root 1264 1月 12 18:27 anaconda-ks.cfg
-rw-r--r-- 1 root root 33396354 3月 30 22:08 elasticsearch-5.5.0.rpm
-rw-r--r-- 1 root root 37926436 3月 30 22:08 elasticsearch-head.tar.gz
-rw-r--r-- 1 root root 94158545 3月 30 23:17 logstash-5.5.1.rpm
[root@node2 ~]# rpm -ivh logstash-5.5.1.rpm (使用rpm安装)
警告:logstash-5.5.1.rpm: 头V4 RSA/SHA512 Signature, 密钥 ID d88e42b4: NOKEY
准备中... ################################# [100%]
正在升级/安装...
1:logstash-1:5.5.1-1 ################################# [100%]
Using provided startup.options file: /etc/logstash/startup.options
OpenJDK 64-Bit Server VM warning: If the number of processors is expected to increase from one, then you should configure the number of parallel GC threads appropriately using -XX:ParallelGCThreads=N
Successfully created system startup script for Logstash
[root@node2 ~]# systemctl start logstash.service (开启服务)
[root@node2 ~]# ln -s /usr/share/logstash/bin/logstash /usr/local/bin/ (添加软连接,优化命令执行路径)
******(2)输入采用标准输入,输出采用标准输出
[root@node2 ~]# logstash -e 'input{stdin{}}output{stdout{}}'
。。。。。。
等待一段时间,当下面这段文字出现后再进行操作
The stdin plugin is now waiting for input:
01:47:27.213 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com (手动输入)
2021-03-30T17:51:24.294Z node2 www.baidu.com (这个就是标准输出)
www.sina.com (手动输入)
2021-03-30T17:51:28.962Z node2 www.sina.com (标准输出)
Ctrl+C退出
******(3)使用rubydebug显示详细输出,dodec是一种编码器
[root@node2 ~]# logstash -e 'input { stdin{} } output { stdout { codec=>rubydebug } }'
。。。。。。
再次等待一段时间,出现下面字段后进行操作
01:56:30.916 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com (标准输入)
{
"@timestamp" => 2021-03-30T17:56:36.133Z, (这个就是处理过后的输出)
"@version" => "1",
"host" => "node2",
"message" => "www.baidu.com"
}
Ctrl+C退出
******(4)使用logstash将信息写入到elasticsearch中,并且远程主机192.168.100.1:9200
[root@node2 ~]# [root@node2 ~]# logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.234.140:9200"] } }'
。。。。。。
02:01:27.882 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
www.baidu.com (三个标准输入,会发现没有进行输出,这是因为发送到了elasticsearch中了)
www.sina.com
www.aaa.com
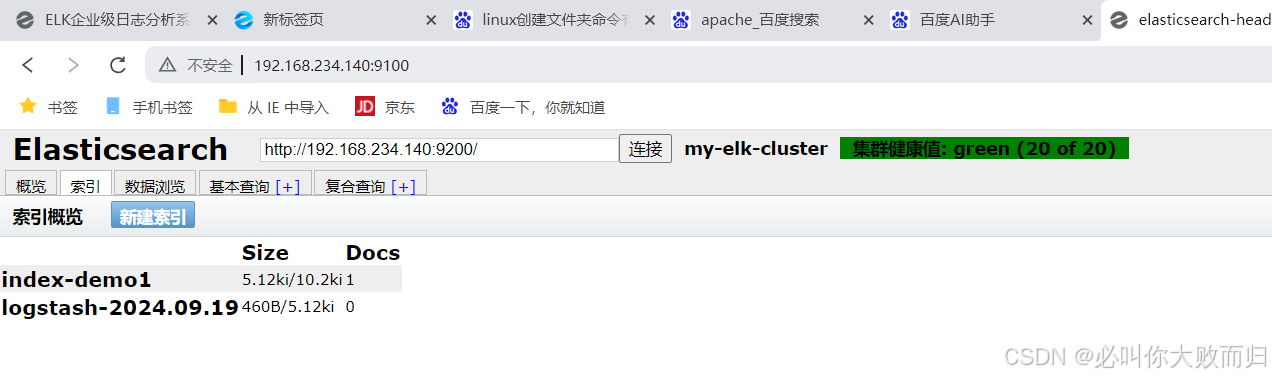
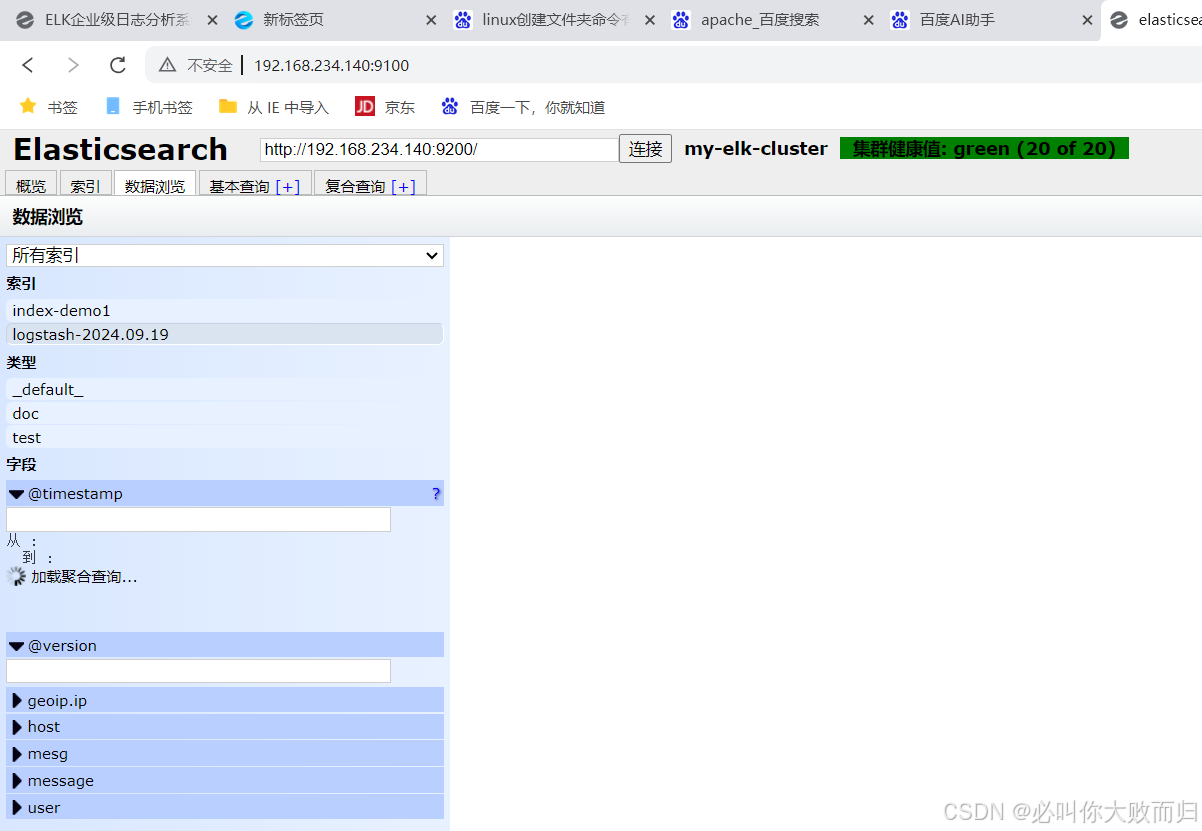
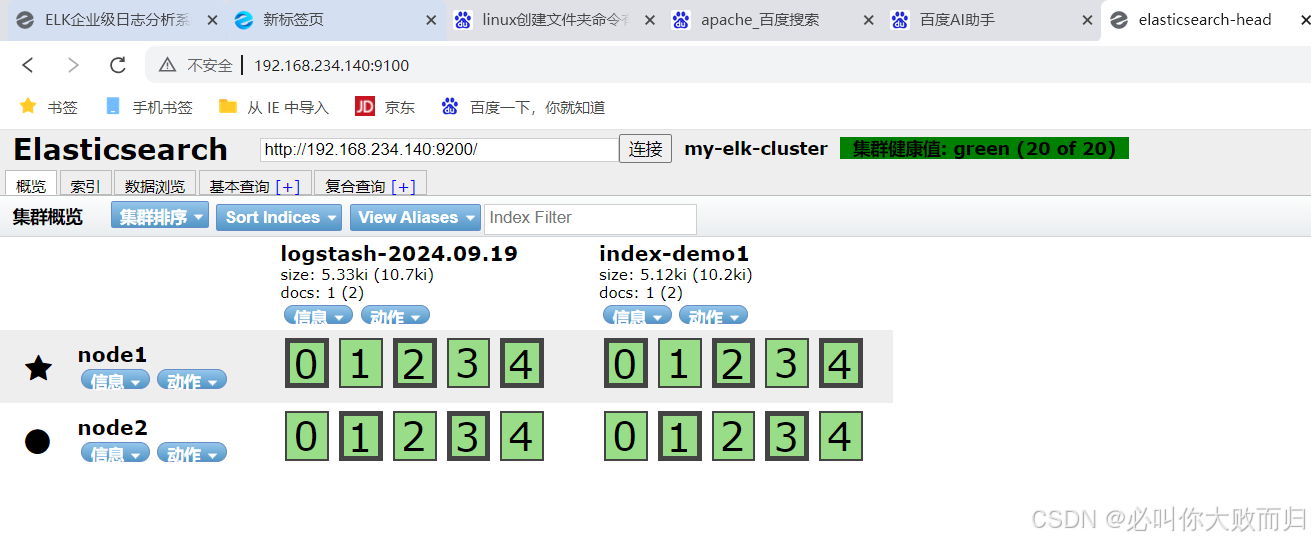
2.2.10查看索引和数据浏览
2.2.11定义logstash配置文件
******(5)编辑logstash配置文件,收集系统日志,输出到elasticsearch中
————————————————————————————————华丽分割线————————————————————————————————————
logstash配置文件基本上是由三部分组成的,input、output以及用户需要时才添加的filter
标准的配置文件格式为:
input{。。。。}
filter{。。。。}
output{。。。。}
在每个部分中,可以指定多个访问方式,例如:想要指定两个日志来源文件,那么就可以这样写,指定多个也是这种格式即可
input {
file { path => "/var/log/messages" type => "sylog" }
file { path => "/var/log/apache/access.log" type => "apache" }
}
—————————————————————————————————————————————————————————————————————————————
[root@node2 ~]# ll /var/log/messages
-rw-------. 1 root root 1184764 3月 31 02:06 /var/log/messages
[root@node2 ~]# chmod o+r /var/log/messages (给系统日志添加其他用户的只读权限)
[root@node2 ~]# ll /var/log/messages
-rw----r--. 1 root root 1185887 3月 31 02:07 /var/log/messages
[root@node2 ~]# ls /etc/logstash/conf.d/
[root@node2 ~]# vim /etc/logstash/conf.d/system.conf (编写一个新文件)
input {
file { #从文件中读取
path => "/var/log/messages" #文件路径
type => "system"
start_position => "beginning" #是否从头开始读取
}
}
output {
elasticsearch { #输出到elasticsearch中
hosts => ["192.168.234.140:9200"] #指定elasticsearch的主机地址和端口
index => "system-%{+YYYY.MM.dd}" #索引名称,这个是日期
}
}
保存退出
[root@node2 ~]# systemctl restart logstash (重启服务)
2.2.12 在node2上面安装kibana
******(1)使用rpm方式安装kibana
[root@node1 ~]# ll kibana-5.5.1-x86_64.rpm (上传rpm包)
-rw-r--r-- 1 root root 52255853 3月 31 02:22 kibana-5.5.1-x86_64.rpm
[root@node1 ~]# rpm -ivh kibana-5.5.1-x86_64.rpm
。。。。。。
[root@node1 ~]# systemctl enable kibana (设置为开机自启)
Created symlink from /etc/systemd/system/multi-user.target.wants/kibana.service to /etc/systemd/system/kibana.service.
******(2)配置kibana主配置文件
[root@node1 ~]# vim /etc/kibana/kibana.yml
。。。。。。
2 server.port: 5601 #打开kibana的端口
3
。。。。。。
7 server.host: "0.0.0.0" #kibana侦听的地址,0.0.0.0为侦听所有
8
。。。。。。
28 elasticsearch.hosts: ["http://192.168.234.140:9200"]
22
。。。。。。
30 kibana.index: ".kibana" #再elasticsearch中添加.kibana索引
31
。。。。。。
保存退出
******(3)启动Kibana服务
[root@node1 ~]# systemctl start kibana
[root@node1 ~]# netstat -anpt | grep 5601
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 1373/node
登录192.168.234.140:5601
然后要创建索引步骤如下
三、扩展Filebeat+ELK 部署
这里就要再填一个虚拟机做filebeat
3.环境部署
cd /opt
rpm -ivh filebeat-6.6.1-x86_64.rpm
cd /usr/local/filebeat
vim filebeat.ym1
filebeat.prospectors:- type: log
#指定1og类型,从日志文件中读取消息
enabled: true
paths:
- /var /log/messages
#指定监控的日志文件
- /var /log/* . log
fields:
#可以使用fields配置选项设置一些参数字段添加到output中
service_name: filebeat
log_type: log
service_id: 192.168.234.160
--Elasticsearch output------------------
(全部注释掉)
---------------Logstash output------------------output.logstash :
hosts: ["192.168.234.150:5044"]
#指定 logstash 的 IP和端口
#启动filebeat
filebeat -e -c filebeat.yml
3.在 Logstash组件所在节点上新建一个 Logstash配置文件cd /etc/logstash/conf.d
vim logstash.conf
input {
beats {
port => "5044""
}
}
output {
elasticsearch {
hosts =>["192.168.234.140:9200"]
index =>"%{[fields] [service_name]}-%{+YYYY. MM.dd}"
}
stdout {
codec => rubydebug
}
}
#启动logstash
logstash -f logstash.conf
4.浏览器访问http: / /192.168.234.140:5601登录Kibana,
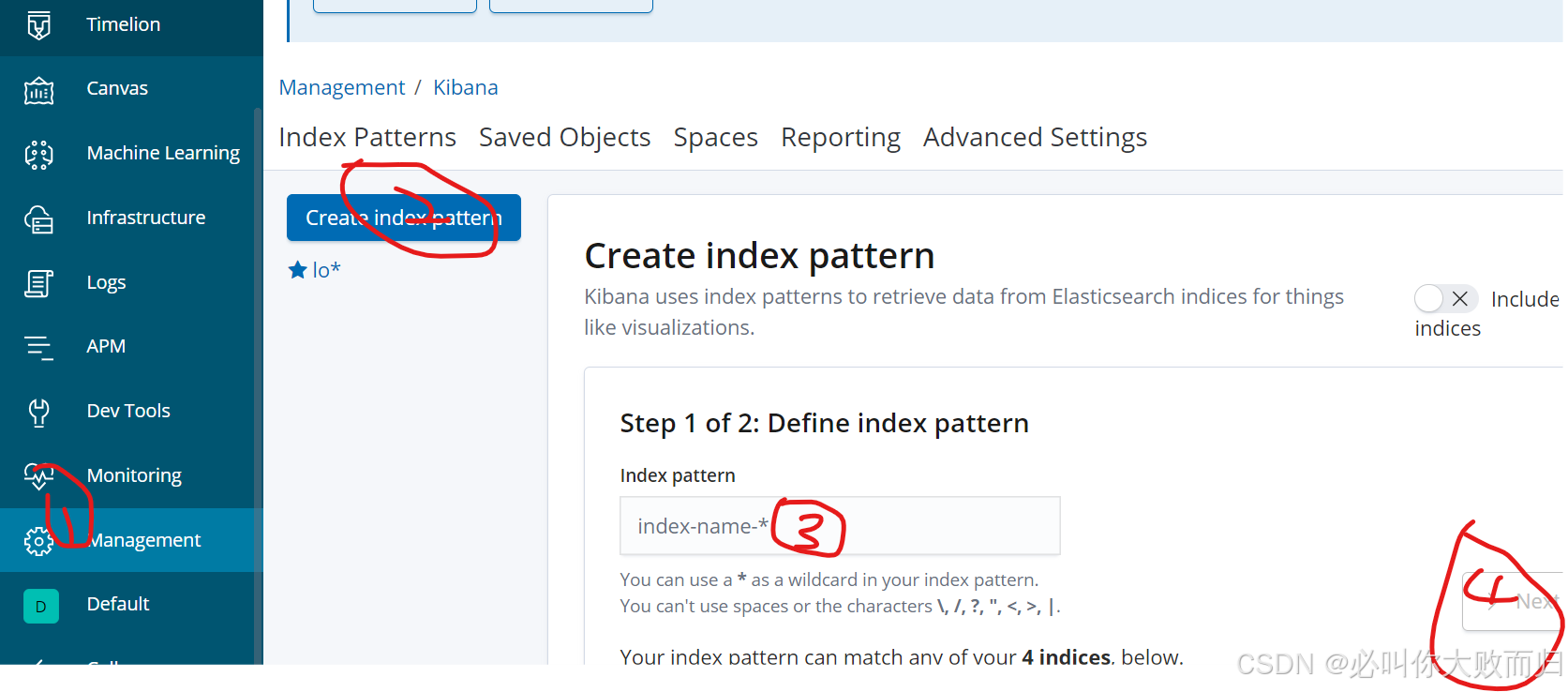
先点击Management--》“Index Pattern"--》"create Index Pattern"按钮创建--》选择输入“Index Pattern"--》然后Next step(下一步) --》Time Filter field name--》@timestarmp
单击“Discover”按钮可查看图表信息及日志信息。按钮添加索引“filebeat-*”
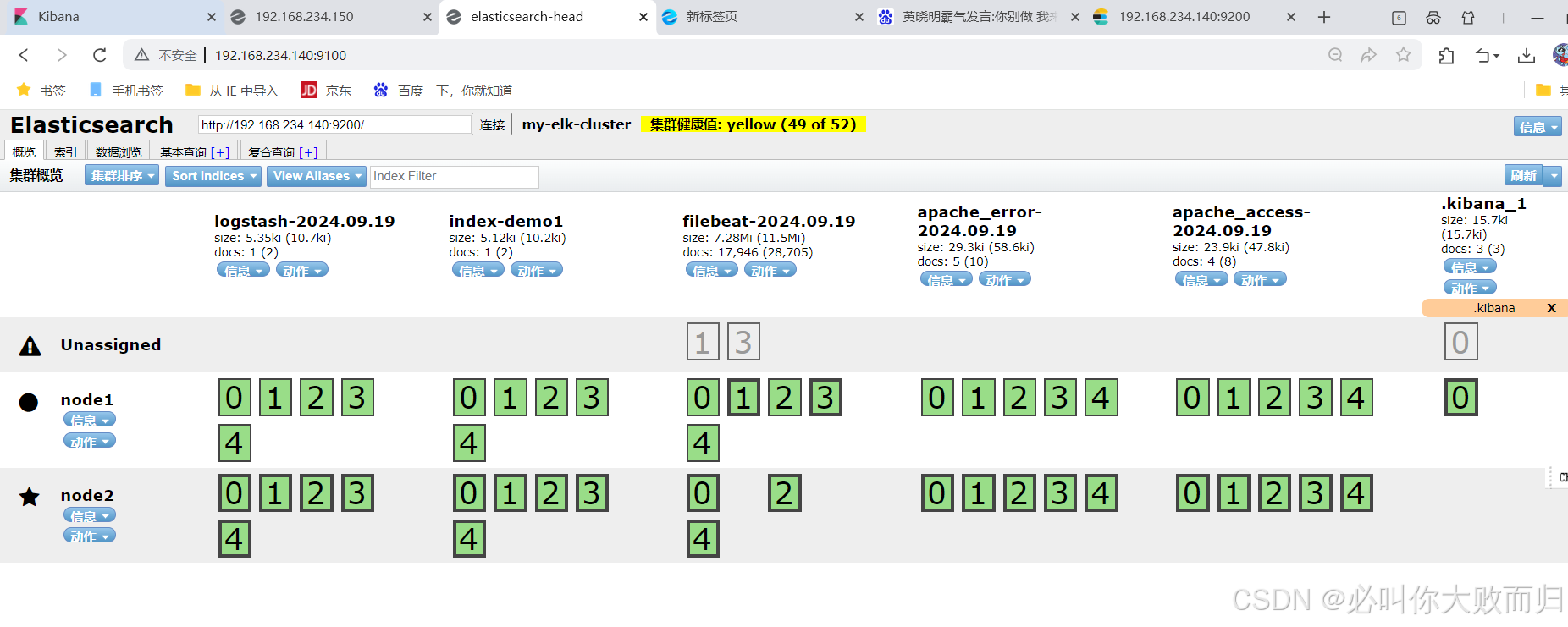
我这里内存不够,节点上面会存在一些问题
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » ELK日志分析系统

发表评论 取消回复