1 需求
需求:自动下载模型和分词器
需求:手动导入模型和分词器
需求:pipeline使用预训练模型
需求:训练和评估
需求:测试
关键词:训练数据集、评估数据集、测试数据集
需求:上线
2 接口
3 自动下载模型与分词器
示例一:
from transformers import BertModel, BertTokenizer
# 指定模型和分词器的名称
model_name = 'bert-base-uncased'
# 指定下载路径
cache_dir = './my_models'
# 下载模型和分词器,并指定下载路径
model = BertModel.from_pretrained(model_name, cache_dir=cache_dir)
tokenizer = BertTokenizer.from_pretrained(model_name, cache_dir=cache_dir)
# 现在你可以使用模型和分词器进行推理或其他任务了import os
os.environ['http_proxy'] = 'http://proxyhk.zte.com.cn'
os.environ['https_proxy'] = 'http://proxyhk.zte.com.cn'
import torch
from transformers import BertModel, BertTokenizer
# 加载预训练的模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
model = BertModel.from_pretrained('bert-base-chinese')
# 示例文本
text = "这是一个使用BERT进行中文文本处理的例子。"
# 对文本进行分词
inputs = tokenizer(text, return_tensors="pt") # 返回张量形式的输入
# 通过模型获取输出
with torch.no_grad(): # 不计算梯度以节省内存
outputs = model(**inputs)
# 输出最后一层的隐藏状态
last_hidden_states = outputs.last_hidden_state
# 获取文本的第一个标记(通常是[CLS]标记)的向量表示
text_embedding = last_hidden_states[:, 0]
print(text_embedding)3 手动导入模型和分词器
- 模型权重文件:pytorch_model.bin 或 tf_model.h5
- 模型配置文件:config.json
- 分词器的词汇表文件:vocab.txt
- 分词器配置文件:tokenizer.json、tokenizer_config.json
当手动下载 Hugging Face 模型时,通常需要以下类型的文件:
一、模型权重文件
- PyTorch 格式(.bin 或.pt)
- 如果模型是基于 PyTorch 开发的,其权重文件通常以
.bin或.pt格式存在。这些文件包含了模型的参数,例如神经网络的每层权重、偏置等信息。- 例如,对于一个预训练的 BERT 模型(PyTorch 版本),这些权重文件定义了模型如何将输入文本转换为有意义的表示。
- TensorFlow 格式(.h5 或.ckpt)
- 对于基于 TensorFlow 的模型,可能会有
.h5或者.ckpt格式的权重文件。.h5文件是一种常见的保存 Keras(TensorFlow 后端)模型的格式,它可以包含模型的结构和权重信息。.ckpt文件则是 TensorFlow 原生的检查点文件,主要用于保存模型在训练过程中的中间状态。二、模型配置文件
- JSON 或 YAML 格式
- 模型配置文件以 JSON 或 YAML 格式为主。这些文件描述了模型的架构,如模型的层数、每层的神经元数量、激活函数类型、输入输出形状等信息。
- 以 GPT - 2 模型为例,其配置文件会指定模型是由多少个 Transformer 块组成,每个块中的头数量、隐藏层大小等关键架构参数。
三、分词器(Tokenizer)相关文件
- 词汇表文件(.txt 或.pkl 等)
- 分词器用于将输入文本转换为模型能够处理的标记(tokens)。词汇表文件包含了模型所使用的所有词汇(对于基于单词的分词器)或者子词(对于基于子词的分词器,如 BPE、WordPiece 等)。
- 例如,对于一个基于 BPE 算法的分词器,词汇表文件定义了模型能够识别的所有子词单元。这个文件可能是一个简单的文本文件(
.txt),其中每行包含一个词汇或子词,也可能是经过序列化的 Python 对象(如.pkl文件,用于保存 Python 的字典等数据结构)。- 分词器配置文件(JSON 或 YAML 格式)
- 类似于模型配置文件,分词器配置文件描述了分词器的一些参数,如分词算法(BPE、WordPiece 等)、特殊标记(如开始标记、结束标记、填充标记等)的定义等。
具体需要下载哪些文件取决于模型的类型(如文本生成模型、图像分类模型等)、框架(PyTorch 或 TensorFlow 等)以及模型开发者所采用的存储和组织方式。
第一步
第二步
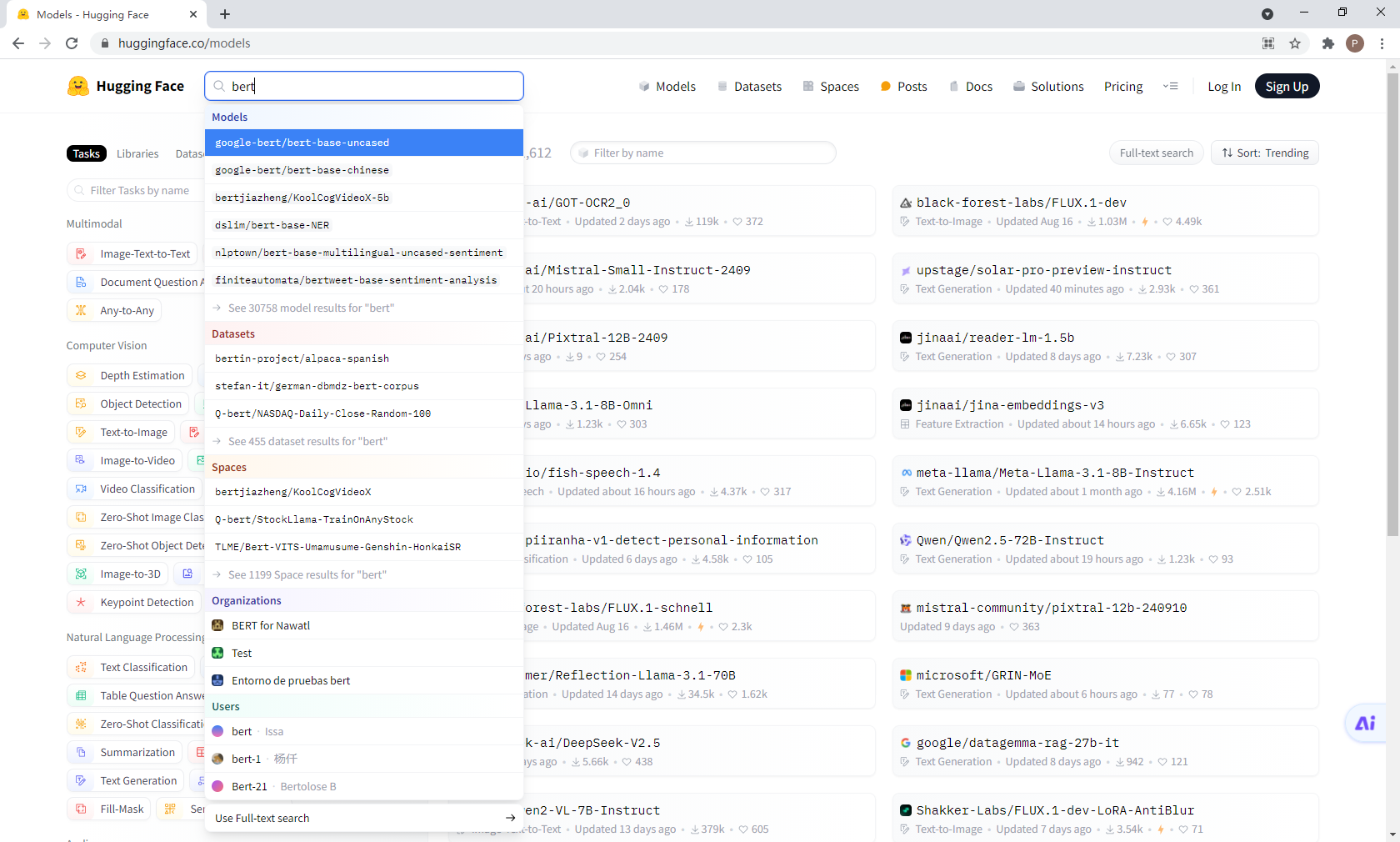
第三步
https://huggingface.co/google-bert/bert-base-chinese
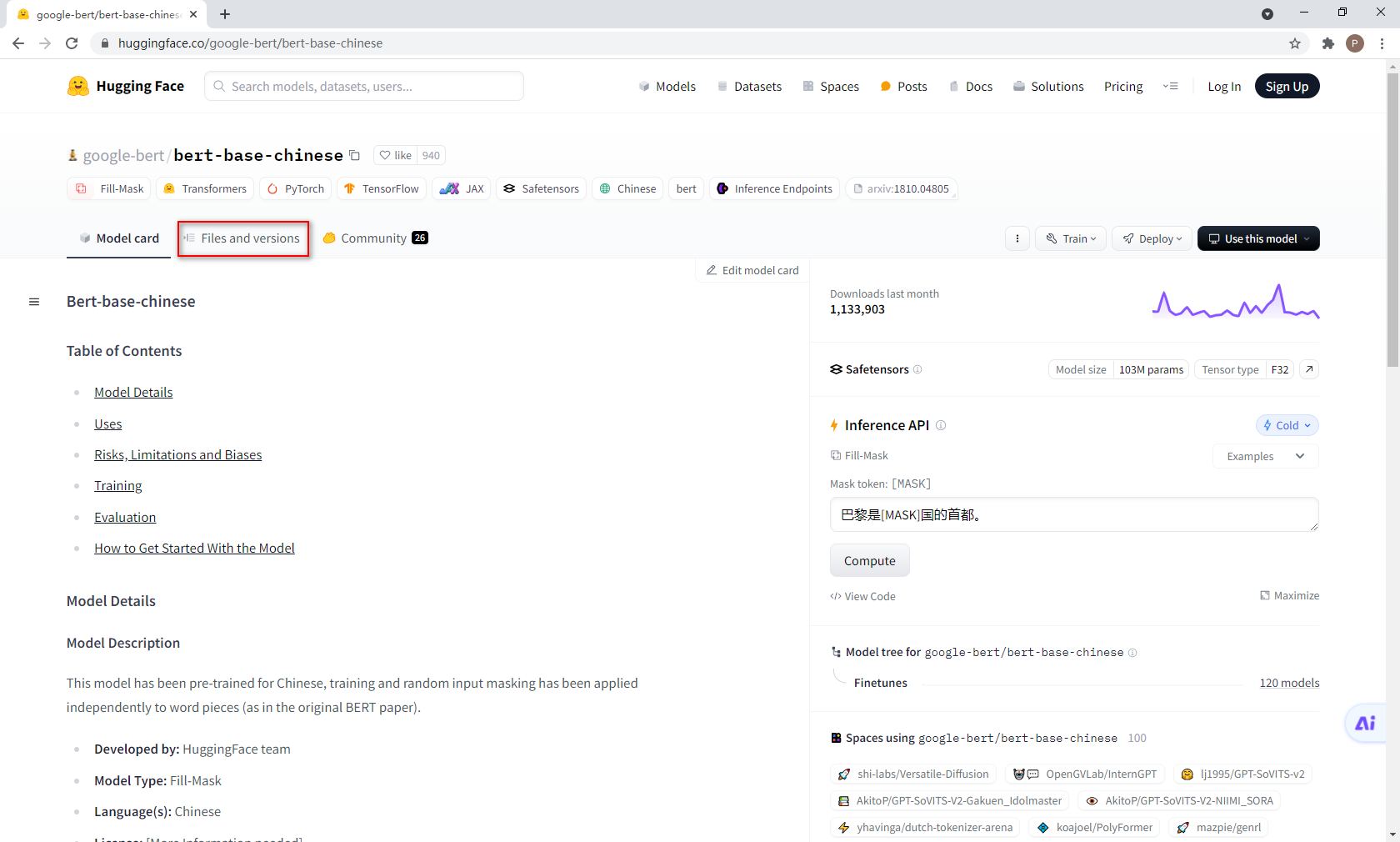
第四步
https://huggingface.co/google-bert/bert-base-chinese/tree/main
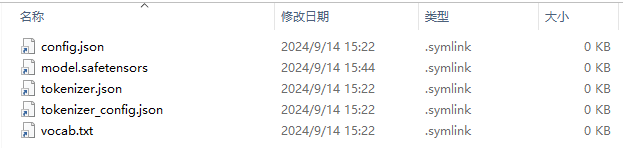
第五步 PyCharm手动添加模型和分词器
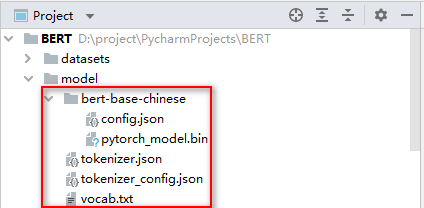
示例一:
from transformers import BertModel, BertTokenizer
# 指定本地模型文件和分词器文件的路径
model_path = './my_bert_model'
# 加载模型和分词器
model = BertModel.from_pretrained(model_path)
tokenizer = BertTokenizer.from_pretrained(model_path)
# 使用分词器对文本进行编码
inputs = tokenizer("Hello, world!", return_tensors="pt")
# 使用模型进行推理
outputs = model(**inputs)
# 输出模型的预测结果(例如,最后一个隐藏层的表示)
print(outputs.last_hidden_state)示例二:
from huggingface_hub import snapshot_download
snapshot_download(repo_id="bert-base-chinese", local_dir="./test2", local_dir_use_symlinks=False)参考资料:
https://huggingface.co/docs/huggingface_hub/guides/download
huggingface下载模型文件(基础入门版)-CSDN博客
3 pipeline使用预训练模型
示例一:使用在线预训练模型
from transformers import pipeline
# 创建一个pipeline,指定模型名称和任务类型
# 这里以'bert-base-uncased'模型的'fill-mask'任务为例
fill_mask_pipeline = pipeline(
"fill-mask",
model="bert-base-uncased",
tokenizer="bert-base-uncased"
)
# 使用pipeline进行推理
# 例如,填充句子中的[MASK]标记
result = fill_mask_pipeline("Hello I'm a [MASK] model.")
# 打印结果
print(result)
示例二:使用本地已下载的预训练模型
from transformers import pipeline
# 设定本地模型文件的存储路径
local_model_path = './my_local_bert_model'
# 创建一个pipeline,用于执行特定的任务,例如'fill-mask'
# 在此过程中,我们指定了本地模型的路径
fill_mask_pipeline = pipeline(
"fill-mask",
model=local_model_path,
tokenizer=local_model_path # 假设分词器文件也存放在同一目录下
)
# 使用pipeline进行推理
# 例如,填充句子中的[MASK]部分
result = fill_mask_pipeline("Hello, I'm a [MASK] model.")
# 输出结果
print(result)参考资料:
transformers库的使用【一】——pipeline的简单使用_transformer pipeline-CSDN博客
【人工智能】Transformers之Pipeline(十七):文本分类(text-classification)-CSDN博客
【人工智能】Transformers之Pipeline(十八):文本生成(text-generation)_文本生成数据集-CSDN博客
3 微调和评估
微调步骤:
1. 准备数据集:首先,你需要准备一个与你的任务相关的标注数据集。这个数据集应该包含输入文本以及相应的标签或注释,用于训练和评估模型。
2. 加载预训练模型:使用 Hugging Face 的 Transformers 库加载预训练的 `bert-base-chinese` 模型。你可以选择加载整个模型或只加载其中的一部分,具体取决于你的任务需求。
3. 创建模型架构:根据你的任务需求,创建一个适当的模型架构。这通常包括在 `bert-base-chinese` 模型之上添加一些额外的层,用于适应特定的任务。
4. 数据预处理:将你的数据集转换为适合模型输入的格式。这可能包括将文本转换为输入的编码表示,进行分词、填充和截断等操作。
5. 定义损失函数和优化器:选择适当的损失函数来衡量模型预测与真实标签之间的差异,并选择合适的优化器来更新模型的参数。
6. 微调模型:使用训练集对模型进行训练。在每个训练步骤中,将输入文本提供给模型,计算损失并进行反向传播,然后使用优化器更新模型的参数。
7. 评估模型:使用验证集或测试集评估模型的性能。可以计算准确率、精确率、召回率等指标来评估模型在任务上的表现。
8. 调整和优化:根据评估结果,对模型进行调整和优化。你可以尝试不同的超参数设置、模型架构或训练策略,以获得更好的性能。
9. 推断和应用:在微调完成后,你可以使用微调后的模型进行推断和应用。将新的输入文本提供给模型,获取预测结果,并根据任务需求进行后续处理。
需要注意的是,微调的过程可能需要大量的计算资源和时间,并且需要对模型和数据进行仔细的调整和优化。此外,合适的数据集规模和质量对于获得良好的微调结果也非常重要。
3 测试
……
3 交互式部署
……
参考资料:
交互式AI技术与模型部署:bert-base-chinese模型交互式问答界面设置_bert-base-chinese 问答-CSDN博客
4 参考资料
在Hugging Face上下载并使用Bert-base-Chinese_bert-base-chinese下载-CSDN博客
3 文本分类入门finetune:bert-base-chinese-CSDN博客
4如何对BERT 微调-案例_tokenizer input max length: 1000000000000000019884-CSDN博客
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 谷歌-BERT-“bert-base-chinese ”

发表评论 取消回复