目录
3. 阻塞 I/O、Reactor 和 Proactor:不同的 I/O 处理方式
用户态缓存区在网络通信中扮演着至关重要的角色,它连接着应用程序和内核网络协议栈,确保数据能够顺利地从用户空间传输到内核空间,反之亦然。
1. 用户态缓存区工作背景
想象一下,你正在和朋友通过即时通讯软件聊天。你发送的信息需要经过多个步骤才能到达朋友的手机,同样,接收到的信息也需要经过一系列处理才能呈现在你的屏幕上。在计算机网络中,用户态缓存区 就是应用程序和操作系统之间传递数据的“中转站”。下面,我们将一步步拆解这个过程,并解释其背后的原因。
1.1 为什么每条连接都需要读写缓存区
1.1.1 读缓存区(Read Buffer)
读缓存区 就像是你手机上的消息通知中心。当朋友发送一条消息时,这条消息可能并不总是以一个完整的包裹(数据包)的形式到达,或者你可能在某个时刻收到多条消息。读缓存区的存在解决了以下两个关键问题:
-
数据不一定包含一个完整的包:
- 现实场景:有时候,你收到的消息可能被拆分成多个部分发送,或者网络状况不好导致数据包丢失。
- 解决方法:读缓存区可以暂存这些不完整的数据,等待完整的数据包到达后再进行解析。这就像你在拆开快递包裹时,如果发现里面的文件不全,你会暂时保留这些文件,等待快递员补齐遗漏的部分。
-
生产者速度大于消费者速度:
- 现实场景:假设朋友发送消息的速度很快,而你的应用程序处理消息的速度相对较慢。
- 解决方法:读缓存区可以充当一个缓冲区,暂时存储这些快速到达的数据,避免数据丢失。这就像快递员送快递时,如果你一时无法及时取件,快递员会将包裹暂存在邻居家,而不是直接丢弃。
1.1.2 写缓存区(Write Buffer)
写缓存区 则类似于你准备发送消息时的草稿箱。当你打字输入消息时,这些信息需要被缓存在一个地方,等待发送。写缓存区的存在同样解决了两个关键问题:
-
数据不一定能一次性写出去:
- 现实场景:你准备发送一条较长的消息,但网络状况不佳,导致消息无法一次性全部发送出去。
- 解决方法:写缓存区可以将这条消息分成多个部分,逐步发送。这就像你写了一封长信,但邮局一次只能处理一部分,你会将信件分批投递,确保最终信件能够完整送达。
-
生产者速度大于消费者速度:
- 现实场景:应用程序生成数据(如视频流、文件传输)的速度超过了网络发送的速度。
- 解决方法:写缓存区可以暂时存储这些数据,等网络有空闲时再逐步发送,避免数据丢失。这就像你在准备大量邮件发送时,会先将邮件暂存在信封中,等邮局有足够资源时再统一投递。
1.2 用户态缓存区的工作流程
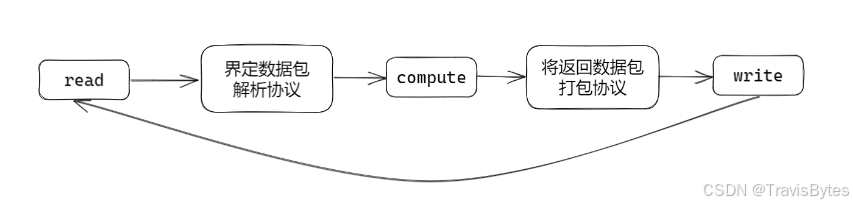
现在,我们了解了为什么需要读写缓存区,接下来让我们看看 用户态缓存区 的具体工作流程。整个过程可以分为以下几个步骤:
-
读取数据(Read):
- 应用程序通过系统调用(如
read()、recv())从内核的接收缓存区读取数据。 - 这些数据可能不包含一个完整的包,或者有多条数据同时到达。
- 应用程序通过系统调用(如
-
界定数据包解析协议(Protocol Parsing):
- 应用程序根据预定的协议(如 HTTP、FTP、SMTP 等)解析接收到的数据包。
- 解析过程中可能需要组合多个部分的数据,确保获取完整的包。
-
计算与处理(Compute):
- 解析后的数据被应用程序处理,执行相应的业务逻辑,如数据库查询、数据计算、状态更新等。
-
将返回数据包打包协议(Packaging Response):
- 应用程序将处理后的数据按照协议要求进行封装,准备发送回去。
- 这包括添加必要的头部信息,确保数据符合网络传输的规范。
-
写入数据(Write):
- 应用程序通过系统调用(如
write()、send())将封装好的数据写入内核的发送缓存区。 - 数据可能无法一次性全部发送出去,写缓存区会暂存剩余的数据,等待后续发送。
- 应用程序通过系统调用(如
-
循环处理(Read):
- 网络通信是一个持续的过程,应用程序需要不断地读取新的数据和写入响应数据,确保实时响应网络事件。
1.3 用户态缓存区的重要性
用户态缓存区在网络通信中起到了以下几个关键作用:
- 数据完整性:确保应用程序接收到的数据是完整的包,即使这些包被拆分成多个部分到达。
- 流量控制:在生产者(数据发送方)和消费者(数据处理方)速度不匹配时,缓存区能够平衡数据流,防止数据丢失或阻塞。
- 提高性能:通过缓存机制,减少频繁的系统调用和内存拷贝操作,提升整体数据传输效率。
- 灵活性:支持不同的应用场景和协议,适应各种复杂的网络环境和需求。
2. UDP 和 TCP 的设计差异
在网络通信中,UDP(用户数据报协议)和 TCP(传输控制协议)是最常用的两种传输层协议。它们各自有不同的设计理念和应用场景。让我们来看看它们在设计上的主要区别。
2.1 UDP:基于报文,不可靠传输
UDP 就像是发送明信片一样,简单快速,但不保证明信片一定能到达目的地,也不关心对方是否收到。这种设计有其独特的优势,特别是在需要高效传输但不要求绝对可靠的场景中。
-
基于报文:
- 特点:UDP 是面向报文的协议,每个
send()调用对应一个独立的报文(datagram)。接收方会按照报文的边界接收数据,不需要处理粘包问题。 - 优势:避免了 TCP 中的粘包和拆包问题,简化了数据处理流程。
- 特点:UDP 是面向报文的协议,每个
-
不可靠传输:
- 特点:UDP 不保证数据包的送达、不保证顺序、不进行重传。
- 应用场景:适用于对实时性要求高、容忍一定丢包率的应用,如视频直播、在线游戏、DNS 查询等。
-
内核协议栈设计:
- 发送缓存区:由于 UDP 是无连接的、不需要确认应答机制,内核协议栈中没有专门的发送缓存区。
- 确认机制:没有确认应答机制,内核协议栈只负责尽力发送,不关心对端是否接受。
-
报文大小限制:
- 最大大小:UDP 报文的最大大小为 64KB(包括头部和数据),超过这个大小的数据需要在应用层进行分片。
2.2 TCP:基于流,可靠传输
TCP 则像是通过邮局寄送包裹,确保包裹按顺序、安全地到达对方手中。这种设计确保了数据传输的可靠性,但也带来了更多的开销和复杂性。
-
基于流:
- 特点:TCP 是面向字节流的协议,数据被视为一个连续的字节流,发送方和接收方需要自行处理数据的分段和组装。
- 粘包处理:由于数据是流式传输的,接收方需要处理可能的粘包和拆包问题。这意味着接收到的数据不一定与发送的数据块一一对应,需要应用层协议进行分界。
-
可靠传输:
- 特点:TCP 提供可靠的数据传输,通过确认应答机制、重传机制、流量控制、拥塞控制等手段,确保数据按序到达、不丢失。
- 应用场景:适用于需要高可靠性的应用,如网页浏览、文件传输、电子邮件等。
-
内核协议栈设计:
- 发送缓存区:TCP 需要维护发送缓存区,用于存储尚未被确认的数据包。这样,即使数据包丢失,TCP 也能通过重传机制保证数据的完整性。
- 确认应答机制:TCP 使用确认应答机制,接收方会发送 ACK 包确认已收到的数据,发送方根据 ACK 信息调整发送策略。
-
分段与分片:
- TCP 分段:TCP 会将大块数据分段,每个段包含 TCP 头部信息,确保数据能够按序传输。
- IP 分片:如果 TCP 段过大,网络层的 IP 协议会进一步将其分片,确保数据在不同网络设备之间传输时能够被正确处理和重组。
3. 阻塞 I/O、Reactor 和 Proactor:不同的 I/O 处理方式
在处理网络 I/O 时,如何高效地管理和响应数据的读取与写入是关键。阻塞 I/O、Reactor 和 Proactor 是三种常见的 I/O 处理模型,它们各有优缺点,适用于不同的应用场景。
3.1 阻塞 I/O
阻塞 I/O 就像是你在餐厅点了一道菜,厨师开始准备,而你在餐桌上等待,直到菜做好后才能继续其他活动。这种方式简单直接,但当需要同时处理多个连接时,效率较低。
-
工作方式:
- 当应用程序发起 I/O 操作(如读取数据)时,如果数据尚未准备好,线程会被阻塞,直到数据到达。
- 同样,在写入数据时,如果发送缓存区已满,线程会被阻塞,直到有足够的空间可用。
-
优点:
- 实现简单,编程模型直观。
- 适用于少量连接和低并发的场景。
-
缺点:
- 当需要处理大量并发连接时,每个连接需要一个独立的线程,导致资源浪费和上下文切换开销大。
- 线程阻塞可能导致应用程序响应变慢。
3.2 Reactor 模式
Reactor 模式 类似于机场的调度塔,集中监控多个飞行器的状态,一旦有飞行器需要起降,调度塔立即响应。这种模式通过事件驱动机制,高效地管理多个并发连接。
-
工作方式:
- 事件检测:Reactor 将 I/O 操作分为两个部分:检测 I/O 事件和操作 I/O。
- 事件分发:使用 I/O 多路复用技术(如
select、poll、epoll)统一检测多个连接的 I/O 事件。 - 事件处理:一旦检测到某个连接有 I/O 事件(如数据到达),Reactor 会调用相应的事件处理程序,执行具体的 I/O 操作。
-
优点:
- 能高效地处理大量并发连接,减少线程数量和上下文切换开销。
- 适用于高并发、需要快速响应的应用场景,如 Web 服务器、实时通信系统等。
-
缺点:
- 编程模型较为复杂,需要处理事件驱动的异步逻辑。
- 事件处理程序需要快速完成,避免阻塞其他事件的处理。
3.3 Proactor 模式
Proactor 模式 更像是你委托一个助理去完成某项任务,当任务完成后助理会通知你。这种模式通过异步操作机制,让内核处理 I/O 操作的检测和执行,应用程序只需等待通知即可。
-
工作方式:
- 异步请求:应用程序发起异步 I/O 请求,将读取或写入的任务委托给内核。
- 内核处理:内核负责检测和执行这些 I/O 操作。
- 完成通知:当 I/O 操作完成后,内核会通知应用程序,应用程序只需处理完成的结果。
-
优点:
- 完全异步,应用程序无需主动检测 I/O 事件,简化了编程模型。
- 内核高效地管理和执行 I/O 操作,减少用户态与内核态之间的切换。
-
缺点:
- 支持 Proactor 模式的操作系统和库较少,兼容性有限。
- 需要依赖内核的异步 I/O 支持,灵活性和可控性较低。
3.4 Reactor 与 Proactor 的比较
-
Reactor:
- 事件检测和操作分离:应用程序负责检测 I/O 事件并执行相应的操作。
- 适用场景:高并发、需要灵活处理 I/O 事件的应用,如 Web 服务器。
-
Proactor:
- 异步处理:内核负责检测和执行 I/O 操作,应用程序只需处理完成的结果。
- 适用场景:需要完全异步 I/O 支持的应用,如某些高性能数据库。
-
共同点:
- 都是为了解决阻塞 I/O 在高并发场景下的效率问题。
- 都依赖于 I/O 多路复用技术,提高资源利用率和响应速度。
4. 缓存区的迭代优化过程
在网络通信中,缓存区的设计和优化直接影响到数据传输的效率和系统的性能。随着应用需求和技术的发展,缓存区的实现方式也在不断迭代和优化。以下是缓存区设计演进的三个主要阶段,以及每个阶段带来的优势和挑战。
4.1 固定内存块 + 长度信息
最初的设计 就是使用一块固定大小的内存来存储数据,并通过长度信息来标识数据的边界。这种方法简单直观,但存在一些问题。
-
优点:
- 实现简单,容易管理。
- 数据移动操作少,处理效率较高。
-
缺点:
- 内存浪费:固定大小的内存块可能导致内存利用率低,尤其是当数据量波动较大时。
- 数据移动:为了处理不同大小的数据包,需要频繁地移动数据,增加了 CPU 的负担。
4.2 Ring Buffer(环形缓冲区)
环形缓冲区 是一种高效的数据结构,通过循环使用固定大小的缓冲区,减少数据移动和内存管理开销。
-
优点:
- 减少数据移动:数据在环形缓冲区中循环写入和读取,避免了频繁的数据拷贝操作。
- 高效缓存管理:适用于高并发场景,能够快速响应数据的读写请求。
-
缺点:
- 内存可伸缩性问题:环形缓冲区的大小是固定的,难以适应动态变化的数据量。
- 增加系统调用:为了管理环形缓冲区,可能需要频繁地进行系统调用,增加了开销。
4.3 Chain Buffer(链式缓冲区)
链式缓冲区 通过将多个缓冲区块链接在一起,解决了环形缓冲区的可伸缩性问题,同时继续减少数据移动。
-
优点:
- 减少数据移动:数据在多个缓冲区块中分散存储,避免了大规模的数据拷贝操作。
- 解决内存可伸缩性:通过动态添加或移除缓冲区块,适应不同的数据量需求。
-
缺点:
- 增加系统调用:为了管理链式结构,可能需要更多的系统调用,带来一定的开销。
4.4 通过 readv 和 writev 优化系统调用
为了进一步优化缓存区的性能,Linux 提供了 readv 和 writev 函数,这些函数允许一次性读取或写入多个缓冲区,从而减少系统调用的次数和开销。
-
readv:- 功能:一次性从文件描述符读取数据到多个缓冲区中。
- 优势:减少了多次系统调用的开销,提高了数据读取效率。
#include <sys/uio.h> ssize_t readv(int fd, const struct iovec *iov, int iovcnt); -
writev:- 功能:一次性将多个缓冲区的数据写入文件描述符。
- 优势:减少了多次系统调用的开销,提高了数据写入效率。
#include <sys/uio.h> ssize_t writev(int fd, const struct iovec *iov, int iovcnt); -
示例:
struct iovec iov[2]; char buf1[100]; char buf2[100]; // 读取数据到 buf1 和 buf2 ssize_t n = readv(sockfd, iov, 2); // 写入 buf1 和 buf2 到 socket ssize_t m = writev(sockfd, iov, 2); -
优势总结:
- 减少系统调用次数:一次操作可以处理多个缓冲区,显著降低系统调用的频率。
- 提高数据传输效率:减少了内核和用户空间之间的上下文切换,提高了整体数据传输的吞吐量。
5. 总结
Linux 系统中 用户态缓存区 的工作背景、UDP 与 TCP 的设计差异、不同的 I/O 处理方式,以及缓存区的迭代优化过程。每个部分都有其独特的设计理念和应用场景,确保了网络通信的高效性和可靠性。
- 用户态缓存区 是连接应用程序和内核网络协议栈的关键桥梁,通过读写缓存区解决了数据传输中的速度差异和数据完整性问题。
- UDP 和 TCP 分别适用于不同的传输需求,UDP 提供快速但不可靠的传输,而 TCP 则确保数据的可靠性和顺序。
- 阻塞 I/O、Reactor 和 Proactor 提供了不同的 I/O 处理模型,适应了从简单到复杂、高并发的各种应用需求。
- 缓存区的迭代优化 通过不断改进数据结构和系统调用,提升了数据传输的效率和系统的整体性能。
参考:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 用户态缓存:高效数据交互与性能优化

发表评论 取消回复