
摘要
轻量级视觉变换器(ViTs)在资源受限的移动设备上表现出优越的性能和较低的延迟,相比之下轻量级卷积神经网络(CNNs)稍显逊色。研究人员发现了许多轻量级 ViTs 和轻量级 CNNs 之间的结构联系。然而,它们在块结构、宏观和微观设计上的显著架构差异尚未得到充分研究。在本研究中,我们从 ViT 的角度重新审视轻量级 CNNs 的高效设计,并强调其在移动设备上的光明前景。具体而言,我们通过整合轻量级 ViTs 的高效架构设计,逐步增强标准轻量级CNN(即MobileNetV3)的移动友好性。最终形成了一种新的纯轻量级 CNN 家族,即 RepViT。大量实验表明,RepViT 优于现有的最先进的轻量级 ViTs,并在各种视觉任务中表现出良好的延迟性能。
介绍
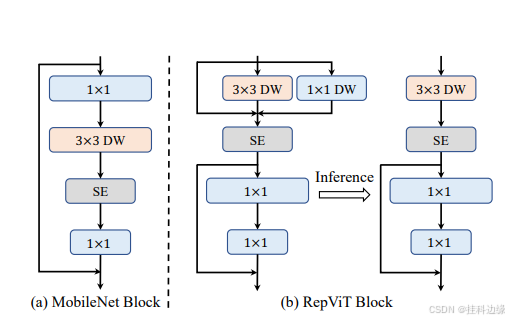
通过集成轻量级 ViT 的设计理念,如分离的 token 混合器和通道混合器,使用结构重参数化技术(SR),调整扩展比和网络宽度等,RepViT 模型实现了在移动设备上的高效推理。RepViT 在多个计算机视觉任务(包括图像分类、物体检测、实例分割等)上表现出色,与其他轻量级ViT和CNN模型的性能对比显示,RepViT在延迟和准确率方面具有显著的优势。CNN 的性能和延迟通常受到卷积核大小的影响。例如,ConvNeXt 通过使用大卷积核来捕捉长距离依赖关系,展现了性能提升的效果。同样,RepLKNet 展示了一种强大的使用超大卷积核的 CNN 范式。然而,较大的卷积核并不适合移动设备,因为它们的计算复杂度和内存访问成本较高。此外,与3×3卷积相比,较大卷积核通常未被编译器和计算库高度优化。SE层是轻量级 CNN 的常见选择,通过全局信息动态调整通道权重。然而,SE层带来了额外的计算成本,尤其是在通道数量较大的后期阶段。为了优化这一点,在 RepViT 块中设置了可选的 SE 层。通过试验,发现将 SE 层放置在早期阶段效果更好,而后期阶段对性能的影响较小。因此,将 SE 层仅放置在前两个阶段。
如下图,(a)是带有可选挤压和激励(SE)层的 MobileNetV3 模块。(b)是设计的 RepViT 模块,通过结构重新参数化技术将令牌混合器和通道混合器分开。SE 层在 RepViT 模块中也是可选的。为简化起见,省略了规范层和非线性部分。
理论详解可以参考链接:论文地址
代码可在这个链接找到:代码地址
本文在YOLOv9中的主干网络
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » YOLOv9改进,YOLOv9主干网络替换为RepViT (CVPR 2024,清华提出,独家首发),助力涨点

发表评论 取消回复