1、如何解决热key
1、本地缓存
采用本地缓存的优点在于简单,扩容方便。但是会带来一致性的问题。
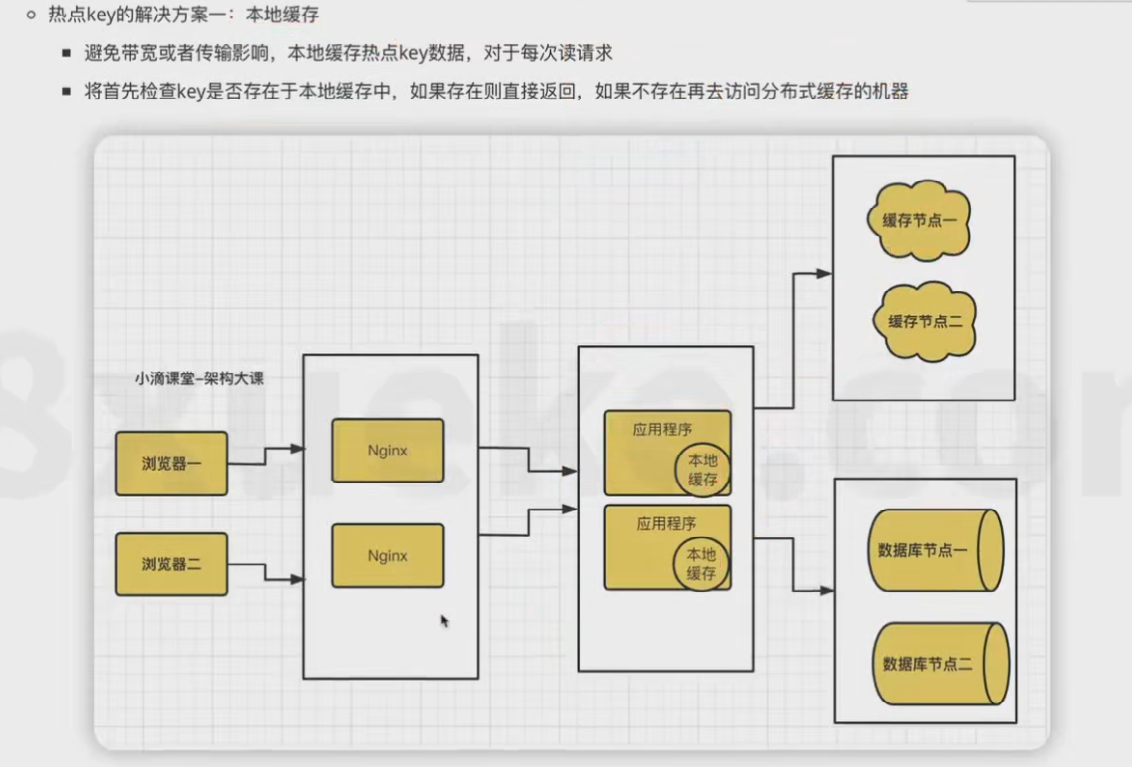
2、离散热点key
做法:结合当前节点的ip或者机器的MAC地址去得出一个固定值拼接在key后面。访问时也是根据key,到后端固定的edis上。
优点:不会出现热key(即数据不会过于倾斜某个节点)
缺点:每次更新和新增的时候都要去改动N个key
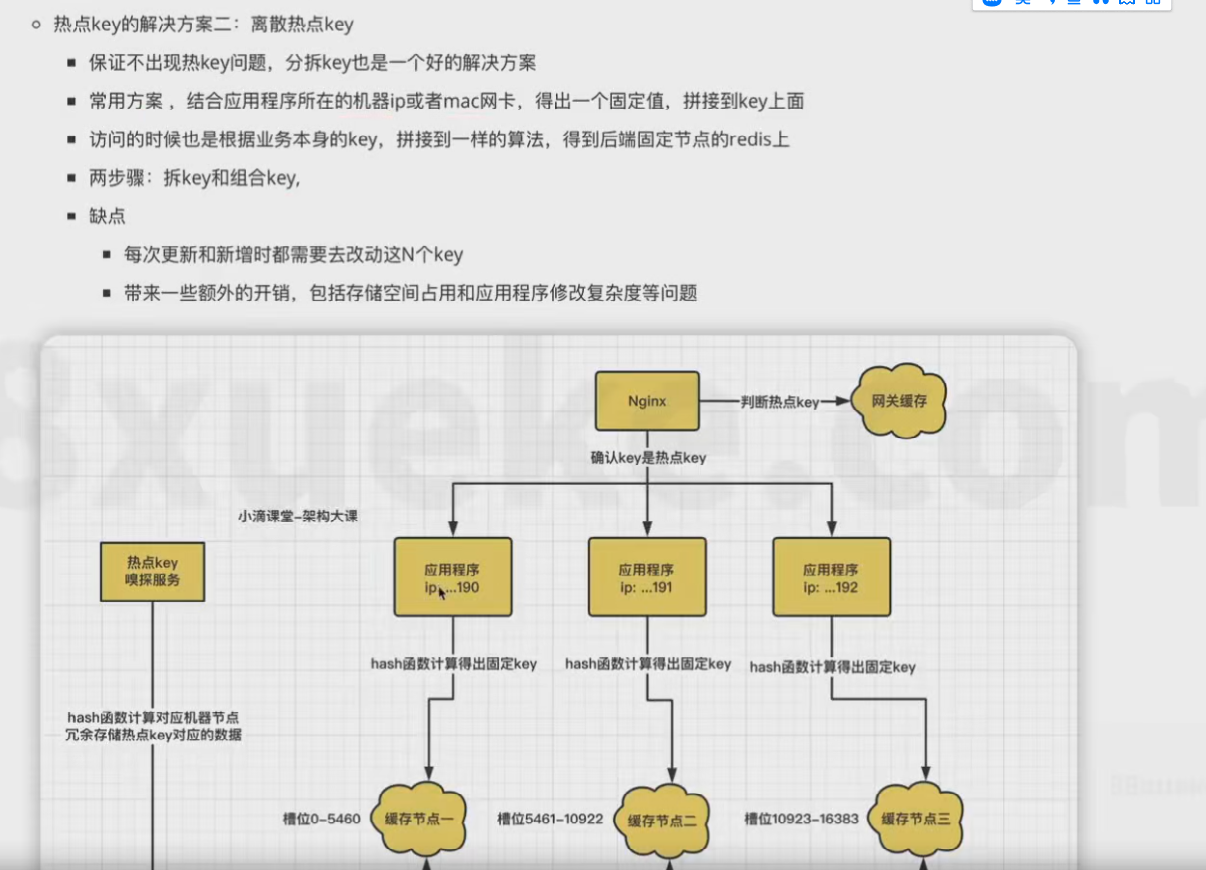
3、网关缓存+实时计算(推荐)
通过监控日志,结合流式计算,时间范围内统计,计算出超过一定阈值的热点key,时间时间窗口内(比如1分钟)访问增快,预判会成为热点key,放置到网关缓存里。当客户端请求过来时,先判断网关层是否包含当前key,存在的话直接从网关返回,
优点:nginx直连redis,性能非常高。
缺点:开发相对复杂
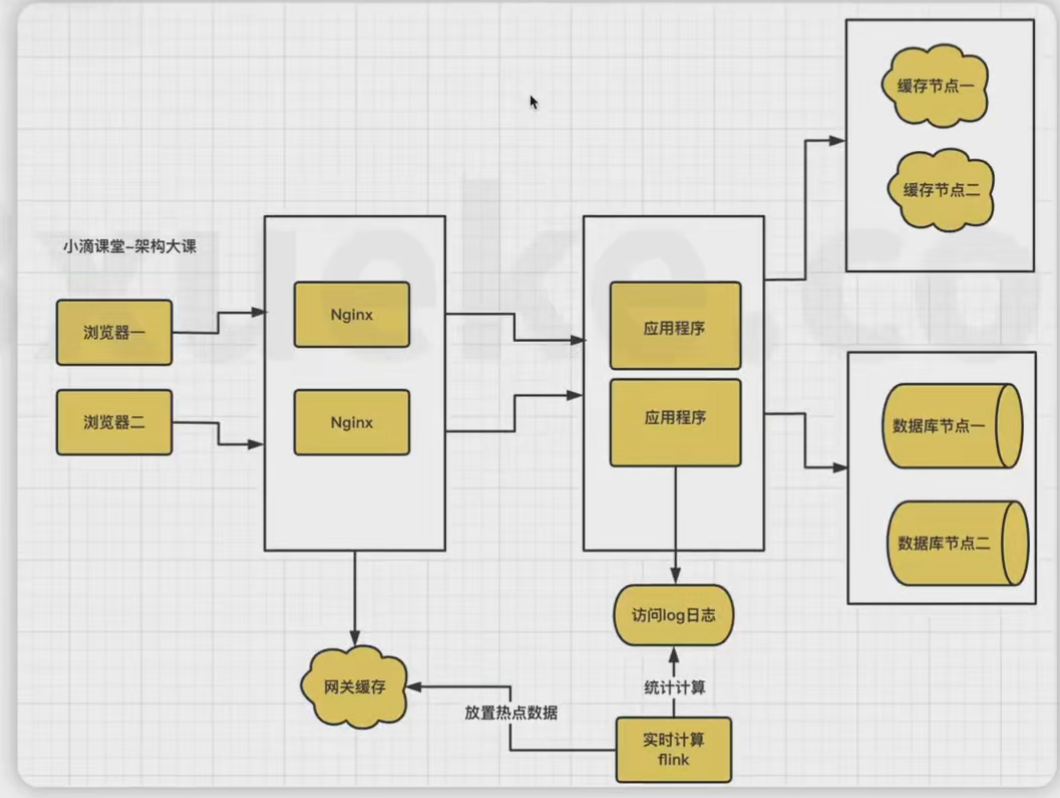
案例:
例如A 系统 给B系统引流,A系统的登录接口QPS 10w+ ,B系统 5000+。 用户同时登录B系统无法承接流量,可以采用方案3。首先通过分析log将一段时间内登录的用户,做一个已登录,然后将缓存写入网关缓存,从而减少B服务的压力。
二、Redis Big key
1、如何发现Big key
方案一:使用Redis自带的命令 redis-cli --bigkeys
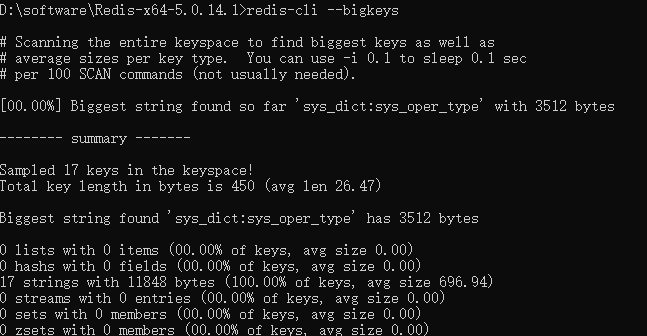
这个命令可以帮助管理员找到可能导致性能问题的大键,并进行相应的优化。
使用时需要注意,redis-cli --bigkeys 在运行时可能会对 Redis 实例造成一定的负载,因为它会遍历整个键空间来查找大键。
客户端自己分装redis客户端,存储之前判断对象大小,大于阈值的打印相关日志。结合elk采集进行可视化监控
如何解决:
(1)直接删除,注意这里不要使用del key ,因为bigkey会导致阻塞,推荐使用lazy del 或者 unlink命令,异步的来删除bigkey
(2)选用合适的结构,例如某个对象字段太多则不使用string来存储。对对象进行拆分,例如使用hash,取的时候只取要用到的字段。
(3)优化存储架构,例如有着一个场景,大V的粉丝列表可能有几十万个用户,而普通用户的粉丝列表就几个,我们可以规定超过一定数量后,标记当前账号存储在不同的地方,避免和业务redis混用。(例如存到mongodb中)
三、分布式锁(Redis)
一、Redis+Lua脚本
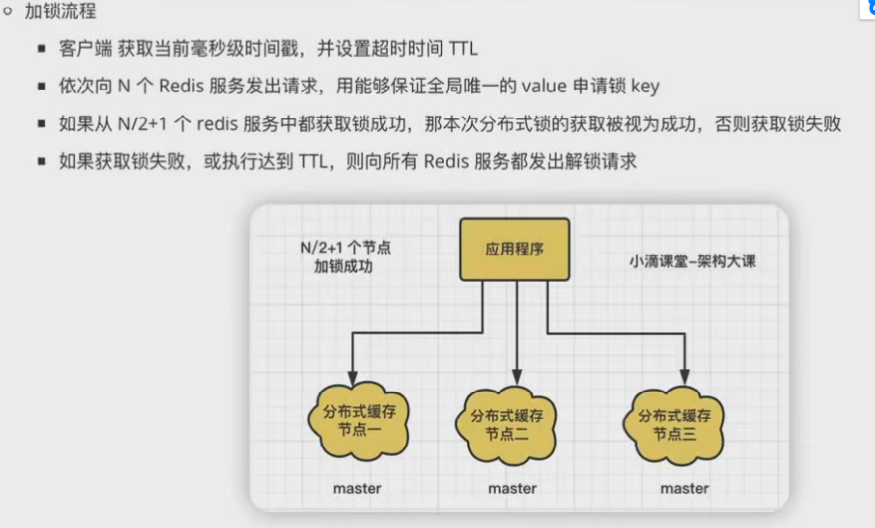
二、Redlock
简单的来说就是向多个独立的Redis实力同时加锁,超过一半成功则加锁成功。

四、数据库和缓存
一、写数据
1、先写数据库再写缓存
最常用的,
2、Read/Write Throw(很少使用)
先写缓存再写数据库,应用把缓存作为主要数据源,数据库对于应用而言是透明的。更新数据库和从数据库读取都交由缓存来实现。
优点:写操作很快,一致性较高,缓存和数据库保持一致,缓存命中率高
缺点:读操作相对慢,如果没有命中缓存每次都会查询数据库。
应用场景:系统处理写操作频繁但是读操作不频繁的场景,例如云存储Ceph
3、Write Behind
被成为Write Back模式或者异步写入模式,一般较少使用,
如果有写操作则先写缓存,但是不会立即同步到数据库中,一般会把缓存中的数据更新到磁盘中,等后续有查询操作(或者隔一段时间)后再批量更新到数据库中。
优点:写速度非常快,不会对性能有影响,同时也避免了频繁更新数据库,提升了数据库性能,且数据一致性较高。
缺点:读操作较慢,由于异步更新数据库,可能会存在数据的延迟。
应用场景:用于数据读写比重较高的场景,如游戏中的用户积分,刚开始对写操作要求较高,后续查找比较少。
二、更新数据
1、先更新数据库,再更新缓存
2、先删除缓存,再更新数据库
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 学习笔记缓存篇(一)

发表评论 取消回复