
https://arxiv.org/pdf/2303.17651
目录
2 Iterative Refinement with SELF-REFINE
Abstract
与人类一样,大型语言模型(LLMs)并非总能在首次尝试时产生最佳输出结果。受人类如何完善书面文本的启发,作者引入了 SELF-REFINE,这是一种通过迭代反馈和完善来改进 LLM 初始输出的方法。
其主要思路是使用 LLM 生成初始输出;然后,同一 LLM 为其输出提供反馈,并利用反馈反复改进自身。
SELF-REFINE 不需要任何有监督的训练数据、额外的训练或强化学习,而是使用单个 LLM 作为生成器、改进器和反馈提供者。
作者使用最先进的 LLM(GPT-3.5 和 GPT-4)对 SELF-REFINE 在 7 个不同任务中的表现进行了评估,这些任务包括对话响应生成和数学推理。
在所有评估的任务中,与使用传统的一步生成法通过相同的 LLM 生成的结果相比,使用 SELF-REFINE 生成的输出结果都受到人类和自动度量的青睐,任务性能的绝对值平均提高了 20%。
作者的工作表明,即使是最先进的 LLM(如 GPT-4),也能在测试时利用我们简单的独立方法得到进一步改进。
Introduction
尽管大型语言模型(LLM)可以生成连贯的输出结果,但它们往往无法满足复杂的要求。
这主要包括具有多方面目标的任务,如对话响应生成,或具有难以定义的目标的任务,如增强程序的可读性。
在这些情况下,现代 LLM 可能会产生可理解的初始输出,但可能会受益于进一步的迭代改进--即迭代地将候选输出映射到改进输出,以确保达到所需的质量。
迭代改进通常包括训练一个依赖于特定领域数据的改进模型(如 Reid 和 Neubig (2022);Schick 等人 (2022a);Welleck 等人 (2022))。其他依赖外部监督或奖励模型的方法需要大量的训练集或昂贵的人工注释(Madaan 等人,2021 年;欧阳等人,2022 年),而这可能并不总是可行的。这些局限性突出表明,作者需要一种有效的提炼方法,这种方法可以应用于各种任务,而不需要大量的监督。
迭代式自我完善是人类解决问题的基本特征(Simon,1962;Flower 和 Hayes,1981;Amabile,1983)。迭代自我完善是一个涉及创建初始草案并随后根据自我提供的反馈对其进行完善的过程。
在起草向同事索取文件的电子邮件时,一个人最初可能会写一个直接的请求,如 “请尽快将数据发给我”。但经过反思,作者意识到这种措辞可能有失礼貌,于是将其修改为 "你好,阿什利,请尽早将数据发给我好吗?在编写代码时,程序员可能会先实现一个 “快速而肮脏 ”的实现,然后经过反思,重构出一个更高效、更易读的解决方案。在本文中,作者证明了 LLM 可以提供迭代式的自我完善,而无需额外的训练,从而在各种任务中获得更高质量的产出
作者提出了 SELF-REFINE:一种迭代式自我精炼算法,在两个生成步骤--反馈和精炼--之间交替进行。这两个步骤相互配合,生成高质量的输出结果。给定模型 M 生成的初始输出,作者将其传递回同一个模型 M 以获得反馈。然后,再将反馈传回同一模型,以完善之前生成的草稿。这个过程会重复一定次数的迭代,或者直到 M 认为没有必要进一步完善。作者使用 “少量提示”(Brown 等人,2020 年)来引导 M 生成反馈,并将反馈纳入改进后的草稿中。图 1 展示了高层次的想法,即 SELF-REFINE 使用相同的底层语言模型来生成反馈并完善其输出。
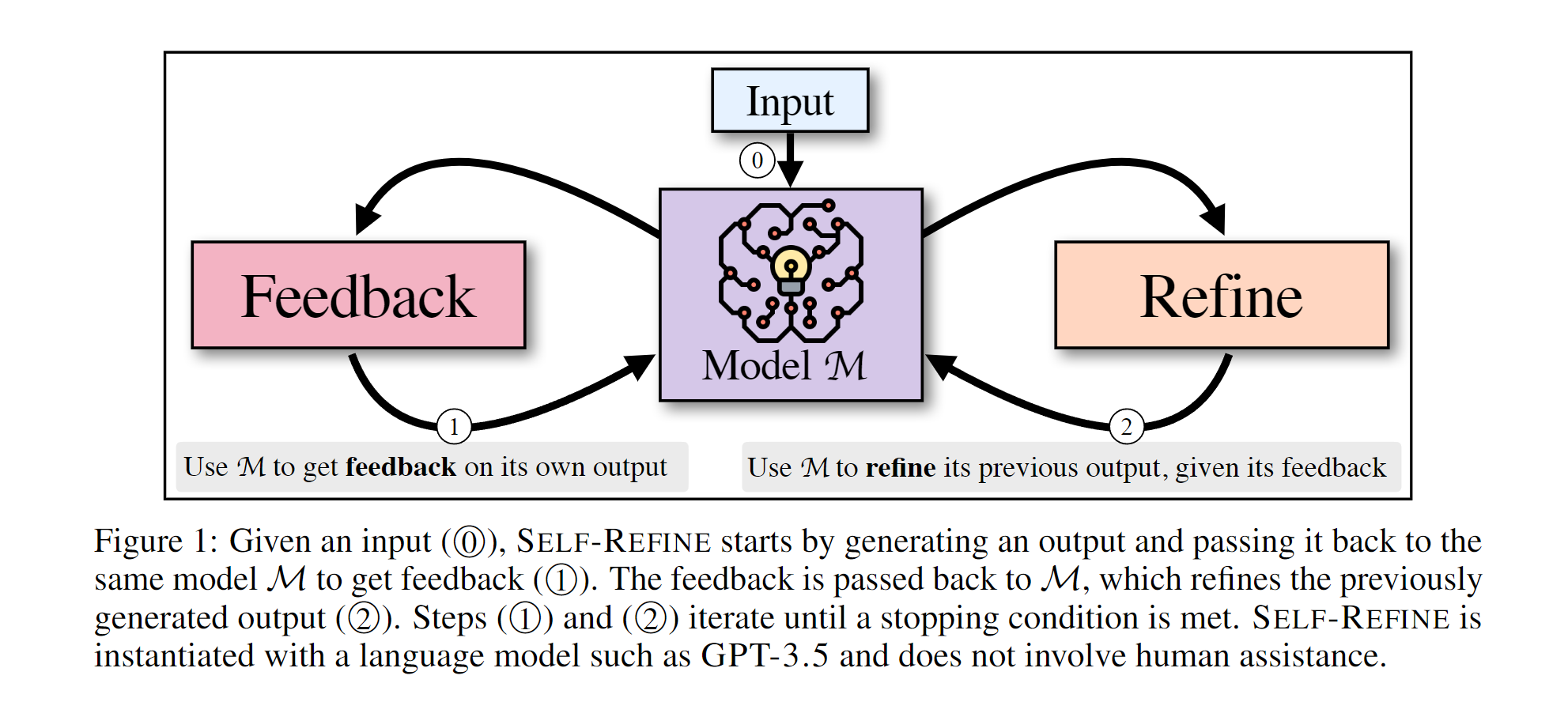
图 1:给定一个输入 ( 0⃝),SELF-REFINE 首先生成一个输出,然后将其传递回同一个模型 M 以获得反馈 ( 1⃝)。反馈信息被传回 M,M 再对之前生成的输出进行改进 ( 2⃝)。步骤 ( 1⃝) 和 ( 2⃝) 重复进行,直到满足停止条件。SELF-REFINE 使用 GPT-3.5 等语言模型实例化,不需要人工辅助。()
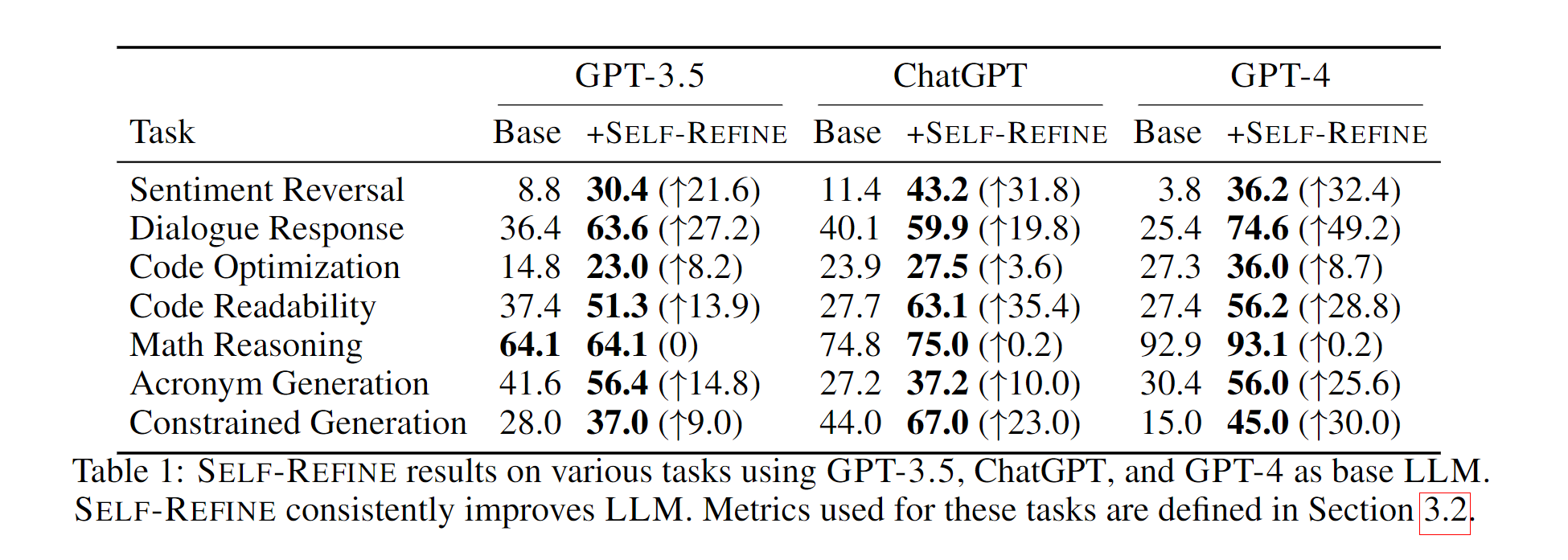
作者对 SELF-REFINE 的 7 项生成任务进行了评估,这些任务涉及多个领域,包括自然语言和源代码生成。结果表明,SELF-REFINE 的绝对生成能力比 GPT-3.5(text-davinci-003 和 gpt-3.5-turbo;OpenAI;欧阳等人,2022 年)和 GPT-4(OpenAI,2023 年)等强 LLM 的直接生成能力强 5-40%。
在代码生成任务中,当 SELF-REFINE 应用于 Codex(code-davinci-002;陈等人,2021 年)等强代码模型时,其初始生成的绝对值可提高 13%。
作者发布了所有代码,这些代码可以很容易地扩展到其他 LLM。
从本质上讲,作者的研究结果表明,即使 LLM 无法在首次尝试时生成最优输出,LLM 通常也能提供有用的反馈,并相应地改进自己的输出。
反过来,通过迭代(自我)反馈和改进,SELF-REFINE 提供了一种无需额外训练就能从单一模型中获得更好输出的有效方法。
2 Iterative Refinement with SELF-REFINE
给定输入序列后,SELF-REFINE 会生成初始输出,提供输出反馈,并根据反馈完善输出。SELF-REFINE 在反馈和改进之间反复进行,直到满足所需的条件。SELF-REFINE 依靠一个合适的语言模型和三个提示(用于初始生成、反馈和完善),不需要训练。SELF-REFINE 如图 1 和算法 1 所示。接下来,将详细介绍 SELF-REFINE。

初始生成 给定输入 x、提示 pgen 和模型 M,SELF-REFINE 生成初始输出 y0:

例如,在图 2(d) 中,模型为给定输入生成功能正确的代码。这里,pgen 是初始生成的特定于任务的少量提示(或指令),∥ 表示串联。 Few-shot 提示包含任务的输入输出对 〈x(k), y(k)〉
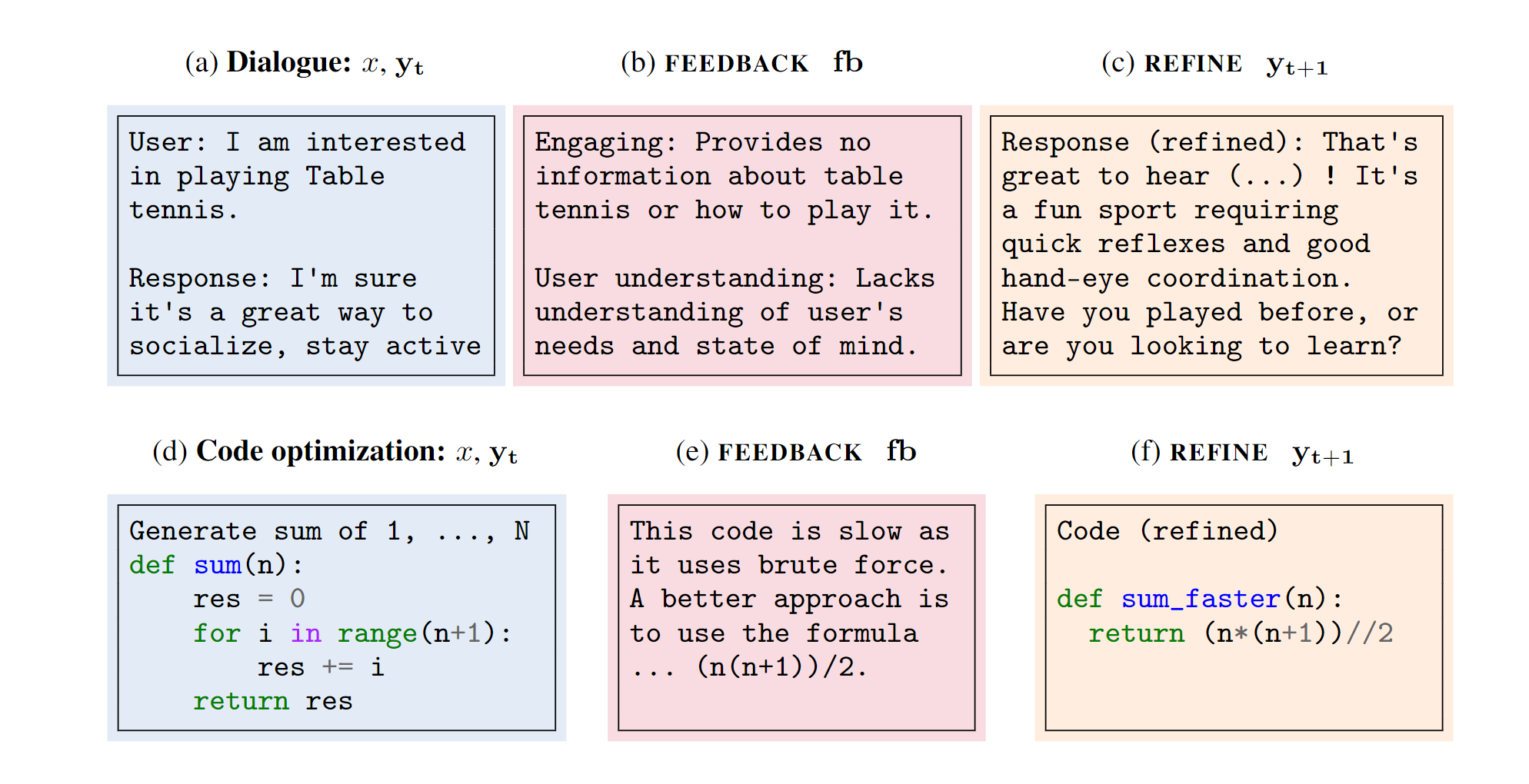
(图 2:自我完善(Self-Refine)示例:基础 LLM 生成初始输出,然后传回同一 LLM,由同一 LLM 接收反馈以完善输出。上一行说明的是对话生成,通过应用反馈,可以将初始对话响应转化为更吸引人、更能理解用户的对话响应。下一行说明的是代码优化,通过应用反馈使代码更加高效。)
反馈 接下来,SELF-REFINE 使用相同的模型 M,在特定任务提示 pfb 的情况下,对自己的输出提供反馈 f bt,以产生反馈:

直观地说,反馈可能涉及输出的多个方面。例如,在代码优化中,反馈可能涉及代码的效率、可读性和整体质量。
在这里,提示 pfb 以输入-输出-反馈三元组〈x(k), y(k), f b(k)〉 的形式提供反馈示例。通过 f b(k)促使模型写出可操作的具体反馈。所谓 “可操作”,是指反馈应包含一个可能改善输出的具体操作。所谓 “具体”,是指反馈应指出输出中需要改变的具体语句。例如,图 2(e)中的反馈是 "这段代码很慢,因为它使用了一个 for 循环,这是一种蛮力。更好的方法是使用公式...(n(n+1))/2"。这个反馈是可执行的,因为它建议执行 “使用公式......”。反馈是具体的,因为它提到了 “for 循环”。
REFINE 接下来,SELF-REFINE 使用 M 来根据自己的反馈来优化其最新输出:

例如,在图 2(f)中,给定初始输出和生成的反馈,模型生成的重新实现比初始实现更短,运行速度更快。提示前缀提供了根据反馈改进输出的示例,其形式为输入-输出-反馈-改进四元组〈x(k), y(k) t , f b(k) t , y(k) t+1〉 。
迭代 SELF-REFINE SELF-REFINE 在反馈和改进步骤之间交替进行,直到满足停止条件。停止条件 stop(f bt, t) 要么在指定的时间步 t 停止,要么从反馈中提取一个停止指标(如标量停止分数)。在实践中,可以在 pfb 中提示模型生成停止指标,并根据任务确定条件。
为了让模型了解之前的迭代情况,通过将之前的反馈和输出添加到提示中来保留它们的历史。直观地说,这可以让模型从过去的错误中吸取教训,避免重蹈覆辙。更准确地说,等式(3)实际上可以具体化为
最后,将最后一次细化 yt 作为 SELF-REFINE 的输出结果。
Evaluation
对 SELF-REFINE 的 7 项不同任务进行了评估: 对话响应生成(附录 M;Mehri 和 Eskenazi,2020 年)、代码优化(附录 N;Madaan 等人,2023 年)、代码可读性改进(附录 L;Puri 等人,2021 年)、数学推理(附录 O;Cobbe 等人,2021 年)、情感反转(附录 P;Zhang 等人,2015 年),还引入了两项新任务: 缩略词生成(附录 Q)和约束生成(Lin 等人(2020)的更难版本,有 20-30 个关键词约束,而不是 3-5 个;附录 R)。
表 4(附录 A)提供了所有任务和数据集统计数据的示例。

(表 4:评估 SELF-REFINE 的任务概览及其相关数据集和规模。对于每项任务,都演示了对输入 x、先前生成的输出 yt、反馈生成的 f bt 和细化后的 yt+1 的一次迭代细化。用于 “反馈 ”和 “完善 ”的提示信息见附录 S。)
3.1 Instantiating SELF-REFINE
按照第 2 节中的高级描述对 SELF-REFINE 进行实例化。FEEDBACK- REFINE 的迭代一直持续到达到所需的输出质量或特定任务的标准为止,最多可迭代 4 次。为了使评估在不同的模型中保持一致,将 FEEDBACK 和 REFINE 作为少量提示来实施,即使是对指令反应良好的模型,如 ChatGPT 和 GPT-4。
基础 LLM 我们的主要目标是评估能否利用 SELF-REFINE 提高任何强基础 LLM 的性能。因此,将 SELF-REFINE 与相同的基础 LLM 进行了比较,但没有进行反馈-改进迭代。在所有任务中使用了三种主要的强基础 LLM: GPT-3.5(text-davinci-003)、ChatGPT(gpt-3.5-turbo)和 GPT-4(OpenAI,2023)。对于基于代码的任务,还尝试了 CODEX(代码-达文西-002)。在所有任务中,GPT-3.5 或 GPT-4 都是以前的最先进版本。
3.2 Metrics
我们报告了三类指标: - 特定任务指标:
在有可用指标的情况下,使用先前工作中的自动指标(数学推理:求解率百分比;代码优化:程序优化百分比;受限基因:覆盖率百分比)
--人工推荐指标:在对话回复生成、代码可读性改进、情感反转和缩略语生成中,由于没有可用的自动指标,
对部分输出结果进行了盲人工 A/B 评估,以选出首选输出结果。更多详情见附录 C。
- GPT-4-pref:除了人类偏好之外,还使用 GPT-4 作为人类偏好的替代,这也是之前的工作(Fu 等人,2023 年;Chiang 等人,2023 年;Geng 等人,2023 年;Sun 等人,2023 年)所采用的方法,并且发现 GPT-4 与人类偏好具有很高的相关性(情感反转为 82%,缩略语生成为 68%,对话响应生成为 71%)。为了提高代码的可读性,提示 GPT- 4 计算根据上下文适当命名的变量分数(例如,x = [] → input_buffer = [] )。更多详情见附录 D。
3.3 Results
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读 - SELF-REFINE: Iterative Refinement with Self-Feedback

发表评论 取消回复