文章目录
0.简介
本文将延续上一篇文章内容,上一篇介绍了PG事务涉及到的模块,本文介绍日志模块,主要介绍PG包含的日志分类,和WAL日志、CLOG的详细介绍。
1.PG日志介绍
在PG中,日志包含三种:
1)pg_log:数据库运行日志,一般用于记录数据库服务状态、sql执行情况和一些错误信息,警告信息。
2)pg_xlog:WAL(Write Ahead Log),即预写日志,记录事务日志信息。
3)pg_clog:事务提交日志,记录事务的元数据。
2.事务日志介绍
常见的事务日志分为两类,即Redo Log和Undo Log,其区别如下:
1)Redo Log:记录修改前的值,Replay时用旧值覆盖当前值,用于回滚。
2)Undo Log:记录修改后的值,Replay时用新值覆盖当前值,用于重做。
事务日志需要在数据真正修改发生之前来做记录,且Replay操作需要保证幂等性,对于PG来说,回滚并不涉及到Undo日志,而是用MVCC来处理,在下一篇会介绍PG的MVCC实现。
3.WAL分析
3.1 WAL概述
如果每次的数据修改都直接去写表文件,那么更新的代价是比较大的,需要去做硬盘随机写入且修改可能是没有顺序的,多次随机寻址和更新页面信息,所以一般会引入Buffer Pool,将数据写入内存,但是面临的问题就是如果在没有刷盘前发生系统故障,就会造成数据丢失,所以需要日志记录,相较于直接更行表文件,WAL Log代价更小。
写入顺序为:先写入WAL Log,在更新内存。在这种情况下,断电或系统故障都能准确恢复数据。
另外,现在WAL Log还可以用来做主从同步,数据备份等。
3.2 WAL设计考虑
对于WAL的设计,下面将介绍一般考虑的点和PG对应的实现
3.2.1 存储格式
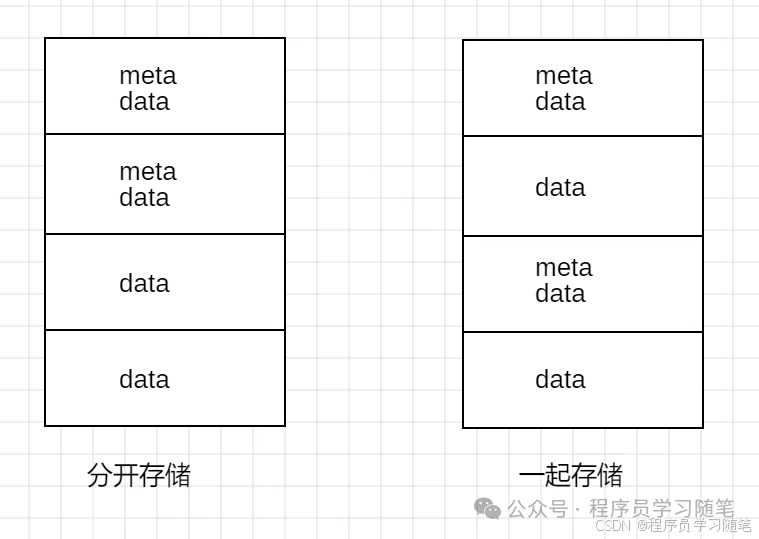
数据库中的数据一般分为元数据和数据,元数据和数据可以分开存储,也可以一起存储,如下图:
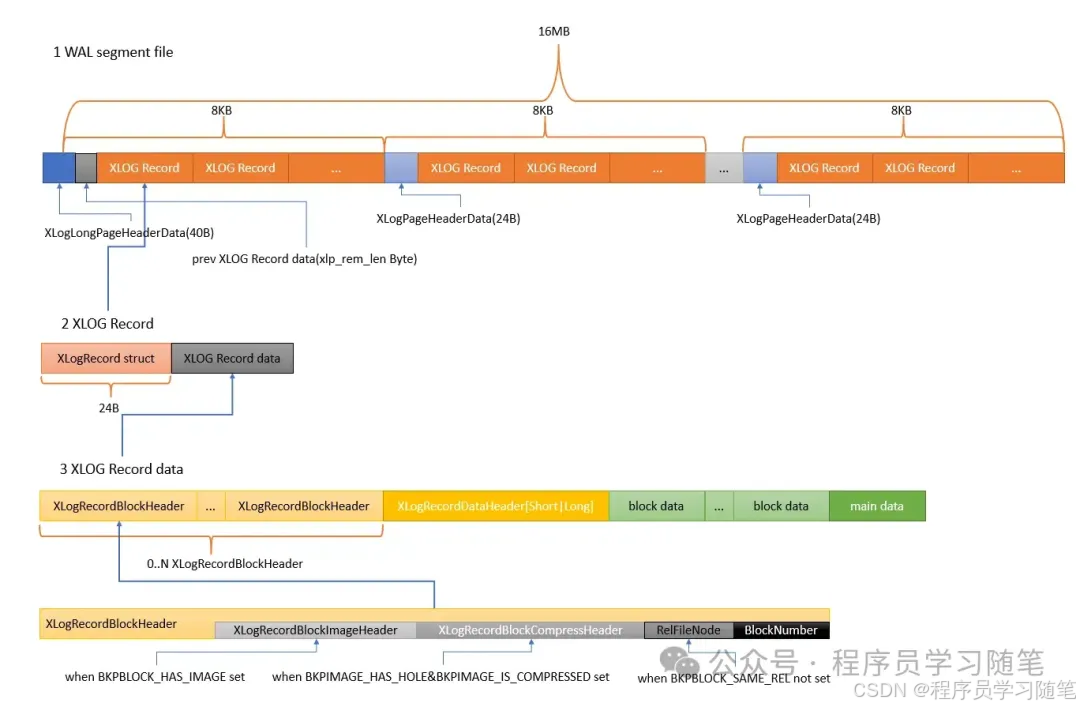
对于PG,其WAL被分为多个文件,被称为WAL segment file,每个文件最大是16M。其命名规则是,24个字符被分为三部分:TimeLineID、逻辑文件ID、物理文件ID。每个八位,取值都是0x00000000到0xFFFFFFFF(实际上物理文件id到不了0xFFFFFFFF)。
寻址规则是:32bit的逻辑文件id+8bit的物理文件id+16M的24bit地址,组成一共64bit地址。
其内部层级如下:
文件中包含N个大小为8K的page,其中有两种page header,一种是XLogLongPageHeaderData,另一种是XLogPageHeaderData,除了第一个page header是XLogLongPageHeaderData,其余都是XLogPageHeaderData。
typedef struct XLogPageHeaderData
{
uint16 xlp_magic; /* magic value for correctness checks */
uint16 xlp_info; /* flag bits, see below */
TimeLineID xlp_tli; /* TimeLineID of first record on page */
XLogRecPtr xlp_pageaddr; /* XLOG address of this page */
/*
* When there is not enough space on current page for whole record, we
* continue on the next page. xlp_rem_len is the number of bytes
* remaining from a previous page; it tracks xl_tot_len in the initial
* header. Note that the continuation data isn't necessarily aligned.
*/
uint32 xlp_rem_len; /* total len of remaining data for record */
} XLogPageHeaderData;
typedef struct XLogLongPageHeaderData
{
XLogPageHeaderData std; /* standard header fields */
uint64 xlp_sysid; /* system identifier from pg_control */
uint32 xlp_seg_size; /* just as a cross-check */
uint32 xlp_xlog_blcksz; /* just as a cross-check */
} XLogLongPageHeaderData;
可以看到XLogLongPageHeaderData成员除了XLogPageHeaderData还有三个成员。xlp_sysid对应的是pg_control中的system identifier,而剩下的xlp_seg_size和xlp_xlog_blcksz为固定大小,分别为segment文件的大小(16M)和page的大小(8K)。
在一个page中,page header之后是N个XLog record。XLog record的布局和结构体信息如下:
/*
* The overall layout of an XLOG record is:
* Fixed-size header (XLogRecord struct)
* XLogRecordBlockHeader struct
* XLogRecordBlockHeader struct
* ...
* XLogRecordDataHeader[Short|Long] struct
* block data
* block data
* ...
* main data
*/
typedef struct XLogRecord
{
uint32 xl_tot_len; /* total len of entire record */
TransactionId xl_xid; /* xact id */
XLogRecPtr xl_prev; /* ptr to previous record in log */
uint8 xl_info; /* flag bits, see below */
RmgrId xl_rmid; /* resource manager for this record */
/* 2 bytes of padding here, initialize to zero */
pg_crc32c xl_crc; /* CRC for this record */
/* XLogRecordBlockHeaders and XLogRecordDataHeader follow, no padding */
} XLogRecord;
typedef struct XLogRecordBlockHeader
{
uint8 id; /* block reference ID */
uint8 fork_flags; /* fork within the relation, and flags */
uint16 data_length; /* number of payload bytes (not including page
* image) */
/* If BKPBLOCK_HAS_IMAGE, an XLogRecordBlockImageHeader struct follows */
/* If BKPBLOCK_SAME_REL is not set, a RelFileLocator follows */
/* BlockNumber follows */
} XLogRecordBlockHeader;
typedef struct XLogRecordDataHeaderShort
{
uint8 id; /* XLR_BLOCK_ID_DATA_SHORT */
uint8 data_length; /* number of payload bytes */
} XLogRecordDataHeaderShort;
typedef struct XLogRecordDataHeaderLong
{
uint8 id; /* XLR_BLOCK_ID_DATA_LONG */
/* followed by uint32 data_length, unaligned */
} XLogRecordDataHeaderLong;
3.2.2 实现方式
实现方式分为Undo和Redo方式,对于PG来说,记录的是Redo日志。
3.2.3 数据完整性校验
对应数据完整性的校验,使用的是循环校验码的方式,这种方式可以有两种实现方式,一种是对整个日志块进行校验,优势的话就是速度快,缺点有一个记录损坏的话恢复代价大,要整块处理;另外一种是分段校验,对于校验速度比第一种稍慢,但出问题更容易找到出问题的小段来进行恢复,对于PG来说,可以看到,每个XLog Record都有自己的循环校验码。
3.3 check ponit
对于WAL文件和WAL buffer,在执行的过程中,数据量一直在增加,如果数量过多,会影响系统性能,PG清理机制依赖于checkpoint,其主要作用就是脏数据的写回,xlog的回收和更新Redo point(恢复启动的起点)等信息到pg_control文件中。
4.事务提交日志(CLOG)
4.1 clog存储使用介绍
CLOG日志记录的是事务的状态,在内存中是由使用SLRU作为淘汰算法的缓冲池进行缓存,由CLOG日志管理器来进行管理。
在PG事务模块一共定义了事务的四种状态:
#define TRANSACTION_STATUS_IN_PROGRESS 0x00 //事务正在运行中
#define TRANSACTION_STATUS_COMMITTED 0x01 //事务已提交
#define TRANSACTION_STATUS_ABORTED 0x02 //事务被终止
#define TRANSACTION_STATUS_SUB_COMMITTED 0x03 //事务的子事务已提交
可以看到,事务的状态只有四种,使用2byte就可以记录一个事务状态,一个page(8k)可以记录32k个日志记录。其存储文件以4位的16进制数字命名,位于PGDATA/pg_act目录下,内部内容如下:
/* We need two bits per xact, so four xacts fit in a byte --*/
#define CLOG_BITS_P ER_XACT 2 ---个事务占用2个bit位
#define CLOG_XACTS_PER_BYTE 4 --一个字节可以存放4个事务状态
#define CLOG_XACTS_PER_PAGE (BLCKSZ * CLOG_XACTS_PER_BYTE)--一个页块可以存放多少个事务状态
#define CLOG_XACT_BITMASK ((1 << CLOG_BITS_PER_XACT) - 1)
#define TransactionIdToPage(xid) ((xid) / (TransactionId) CLOG_XACTS_PER_PAGE) --事务存放在第几页
#define TransactionIdToPgIndex(xid) ((xid) % (TransactionId) CLOG_XACTS_PER_PAGE) --页内的偏移量
#define TransactionIdToByte(xid) (TransactionIdToPgIndex(xid) / CLOG_XACTS_PER_BYTE) --页内的第几个字节
#define TransactionIdToBIndex(xid) ((xid) % (TransactionId) CLOG_XACTS_PER_BYTE) --字节内的偏移量
可以看到,有一个事务id之后,可以计算得到页,页内偏移,页内字节和字节内偏移量,从而找到事务状态。
4.2 slru缓冲池并发控制
因为slru(最近最少使用)的概念是比较容易理解的,下面主要描述PG在slru的缓冲池上实现并发控制的方式。
对于SLRU缓冲池,PG使用了两种锁来进行并发控制。
1)ControlLock:整个缓冲区的控制锁(读写锁)。
2) buffer_locks:每个缓冲区页面锁(读写锁)。
一次读取到slru的流程
获取ControlLock的全局锁-》挑选出替换的缓存,更新缓存的状态为正在读-》获取缓存的写锁-》释放ControlLock的全局锁,因为刷新磁盘的时间会很长,这里释放全局锁提高并发性能-》从文件中读取数据到缓存-》重新获取ControlLock全局锁,因为接下来要修改缓存的状态-》设置缓存的状态为有效状态-》释放ControlLock全局锁-》释放缓存的写锁,并且设置缓存为最近访问。
可以看到PG采用了分页控制的方式提高了并发操作的性能。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PostgreSQL技术内幕10:PostgreSQL事务原理解析-日志模块介绍

发表评论 取消回复