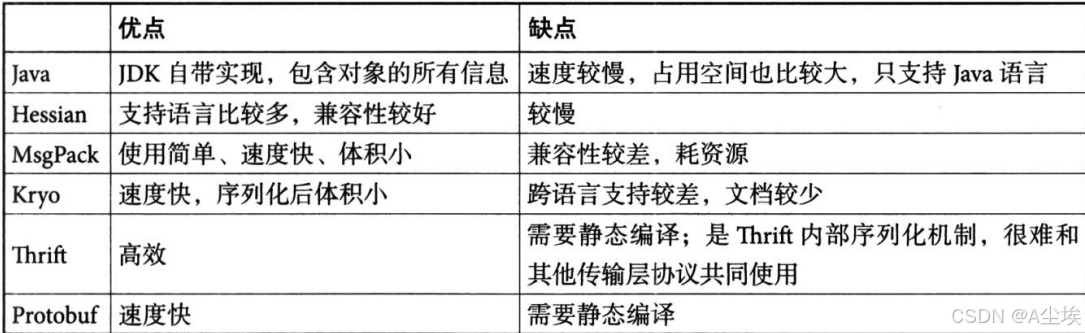
序列化框架对比:
一、Java Serialiazer
字段serialVersionUID的作用是为了在序列化时保持版本的兼容性,即版本升级时反序列化仍保持对象的唯一性。
//序列化
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutoutStream out = new ObjectOutputStream(bout);
out.writeObject(obj);
byte[] bytes = bout.toByteArray();
//反序列化
ObjectInputStream bin = new ObjectInputStream(new ByteArrayInputStream(bytes));
bin.readObject();
二、Hessian
底层基于list和HashMap实现
其在序列化的类有父类的时候,如果有字段相同,父类的值会覆盖子类的值,因此使用时一定要注意子类和父类不能有同名字段
Hessian的实现有v1和v2两个版本,并不兼容。推荐使用Hessian2相关的类
//序列化
ByteArrayOutputStream os = new ByteArrayOutputStream();
Hessian2Output out = new Hessian2Output(os);
out.startMessage();
TestUser user = new TestUser();
out.writeObject(user);
out.completeMessage()
out.flush();
byte[] bytes = os.toByteArray();
out.close();
os.close();
//反序列化
ByteArrayInputStream ins = new ByteArrayInputStream(bytes);
Hessian2Input input = new Hessian2Input(ins);
input.startMessage();
TestUser newUser = (TestUser)input.readObject();
input.completeMessage();
input.close();
ins.close();
三、MsgPack
需要在序列化的类上加@Message注解
为了保证序列化向后兼容,新增加的属性需要加在类的最后面,且要加@Optional注解
MsgPack提供了动态类型的功能,通过接口Value来实现动态类型
首先将数组序列化为Value类型的对象,然后用converter转化为本身的类型
//TestUser.java
@Message
public class TestUser{
private String name;
private String mobile;
//...
}
TestUser user = new TestUser();
MessagePack messagePack = new MessagePack();
//序列化
byte[] bs = messagePack.write(user);
//反序列化
user = messagePack.read(bs,TestUser.class);
四、Kryo
Kryo kryo = new Kryo();
//序列化
ByteArrayOutputStream os = new ByteArrayOutputStream();
Output output = new Output(os);
TestUser user = new TestUser();
kryo.writeObject(output,user);
output.close();
byte[] bytes = os.toByteArray();
//反序列化
Input input = new Input(new ByteArrayInputStream(bytes));
TestUser newUser = kryo.readObject(input,TestUser.class);
input.close();
五、Thrift
需要先定义IDL,再使用Thrift
//定义IDL
//TestUser.thrift
namespace java.me.rowkey.pje.datatrans.rpc.thrift
struct TestUser{
1: required string name
2: required string mobile
}
thrift --gen java TestUser.trhrift
使用生成的TestUser类做序列化和反序列化
TestUser user = new TestUser();//由Thrift代码生成引擎生成
//序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
user.write(new TBinaryProtocol(new TIOStreamTransport(bos)));
byte[] result = bos.toByteArray();
bos.close();
//反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(result);
TestUser user = new TestUser();
user.read(new TBinaryProtocol(new TIOStreamTransport(bis)));
bis.close();
由于Thrift序列化时,丢弃了部分信息,故使用ID+Type来做标识
因此对新增的字段属性采用ID递增的方式标识并以Optional修饰来添加,这样才能做到向后兼容
六、Protobuf
Google开源的序列化框架
首先需要编写.proto文件,并使用Protobuf代码生成引擎生成Java代码
//TestUser.proto
syntax = "proto3";
option java_package = "me.rowkey.pje.datatras.rpc.proto";
option java_outer_classname = "TestUserProto";
message TestUser{
string name = 1;
string mobile = 2;
}
protoc --java_out = ./TestUser.proto
即生成TestUserProto.java,使用此类即可完成序列化和反序列化
//序列化
TestUserProto.TestUser testUser = TestUserProto.TestUser.newBuilder()
.setMobile("xxx")
.setName("xxx")
.build();
byte[] bytes = testUser.toByteArray();
//反序列化
testUser = TestUserProto.TestUser.parseFrom(bytes);
使用提示:
面对RPC框架,选择的时候需要一下方面进行选择
- 是否允许代码侵入,即需要依赖响应的代码生成器生成代码,入Thrift
- 是否需要长连接获取高性能,如果性能需求高,则选择基于TCP的Thrift/Dubbo
- 是否需要跨网段、跨防火墙,需要基于HTTP协议的Hessian和Thrift的HTTP Transport
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » RPC远程调用的序列化框架

发表评论 取消回复