1:对接阿里asr
1.1:pom
<dependency>
<groupId>com.alibaba.nls</groupId>
<artifactId>nls-sdk-recognizer</artifactId>
<version>2.2.1</version>
</dependency>
1.2:生成token
package com.dahuyou.ali.asr.generatetoken;
import com.alibaba.nls.client.AccessToken;
import java.io.IOException;
/**
* 生成token
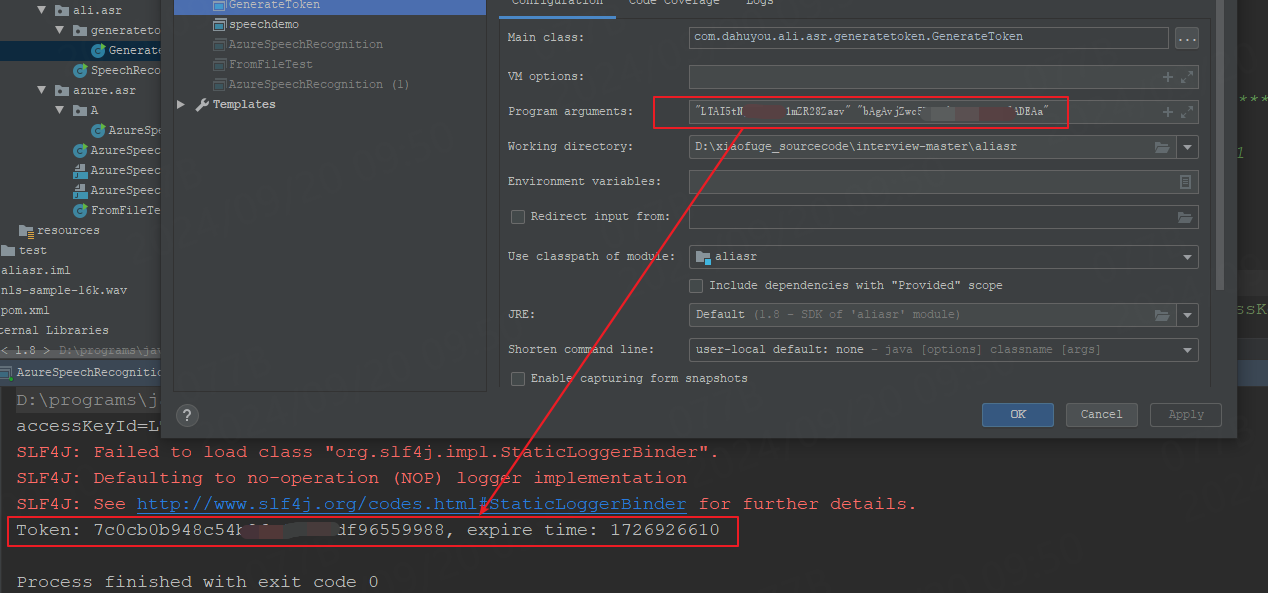
* program argument参数配置:"LTAI5tNg9N*****R28Zazv" "bAgAvjZwc5HVr******ADEAa"
*
* Token: 6599217b19214759*****42ddf0f8016, expire time: 1726774011
*/
public class GenerateToken {
public static void main(String[] args) {
if (args.length < 2) {
System.err.println("CreateTokenDemo need params: <accessKeyId> <accessKeySecret>");
System.exit(-1);
}
String accessKeyId = args[0];
String accessKeySecret = args[1];
System.out.println("accessKeyId="+accessKeyId+"; accessKeySecret="+accessKeySecret);
AccessToken accessToken = new AccessToken(accessKeyId, accessKeySecret);
try {
accessToken.apply();
System.out.println("Token: " + accessToken.getToken() + ", expire time: " + accessToken.getExpireTime());
} catch (IOException e) {
e.printStackTrace();
}
}
}
其中accessKeyId和accessKeySecret通过阿里云后台获取:
1.3:在线asr
package com.dahuyou.ali.asr;
import java.io.File;
import java.io.FileInputStream;
import com.alibaba.nls.client.protocol.InputFormatEnum;
import com.alibaba.nls.client.protocol.NlsClient;
import com.alibaba.nls.client.protocol.SampleRateEnum;
import com.alibaba.nls.client.protocol.asr.SpeechRecognizer;
import com.alibaba.nls.client.protocol.asr.SpeechRecognizerListener;
import com.alibaba.nls.client.protocol.asr.SpeechRecognizerResponse;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 此示例演示了
* ASR一句话识别API调用
* 通过本地文件模拟实时流发送
* 识别耗时计算
* (仅作演示,需用户根据实际情况实现)
*/
public class SpeechRecognizerDemo {
private static final Logger logger = LoggerFactory.getLogger(SpeechRecognizerDemo.class);
private String appKey;
NlsClient client;
public SpeechRecognizerDemo(String appKey, String token, String url) {
this.appKey = appKey;
//TODO 重要提示 创建NlsClient实例,应用全局创建一个即可,生命周期可和整个应用保持一致,默认服务地址为阿里云线上服务地址
if(url.isEmpty()) {
client = new NlsClient(token);
}else {
client = new NlsClient(url, token);
}
}
// 传入自定义参数
private static SpeechRecognizerListener getRecognizerListener(int myOrder, String userParam) {
SpeechRecognizerListener listener = new SpeechRecognizerListener() {
//识别出中间结果.服务端识别出一个字或词时会返回此消息.仅当setEnableIntermediateResult(true)时,才会有此类消息返回
@Override
public void onRecognitionResultChanged(SpeechRecognizerResponse response) {
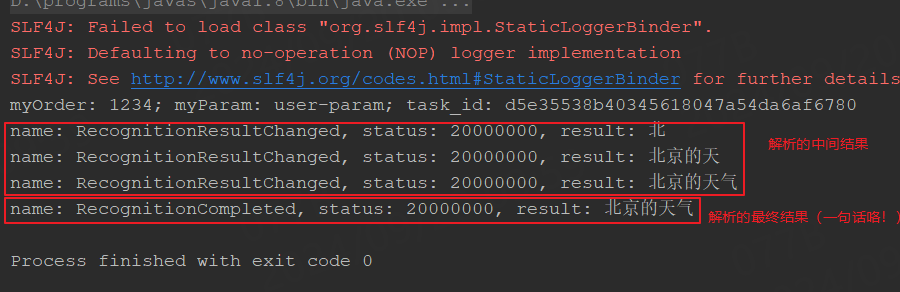
//事件名称 RecognitionResultChanged、 状态码(20000000 表示识别成功)、语音识别文本
System.out.println("name: " + response.getName() + ", status: " + response.getStatus() + ", result: " + response.getRecognizedText());
}
//识别完毕
@Override
public void onRecognitionCompleted(SpeechRecognizerResponse response) {
//事件名称 RecognitionCompleted, 状态码 20000000 表示识别成功, getRecognizedText是识别结果文本
System.out.println("name: " + response.getName() + ", status: " + response.getStatus() + ", result: " + response.getRecognizedText());
}
@Override
public void onStarted(SpeechRecognizerResponse response) {
System.out.println("myOrder: " + myOrder + "; myParam: " + userParam + "; task_id: " + response.getTaskId());
}
@Override
public void onFail(SpeechRecognizerResponse response) {
// TODO 重要提示: task_id很重要,是调用方和服务端通信的唯一ID标识,当遇到问题时,需要提供此task_id以便排查
System.out.println("task_id: " + response.getTaskId() + ", status: " + response.getStatus() + ", status_text: " + response.getStatusText());
}
};
return listener;
}
/// 根据二进制数据大小计算对应的同等语音长度
/// sampleRate 仅支持8000或16000
public static int getSleepDelta(int dataSize, int sampleRate) {
// 仅支持16位采样
int sampleBytes = 16;
// 仅支持单通道
int soundChannel = 1;
return (dataSize * 10 * 8000) / (160 * sampleRate);
}
public void process(String filepath, int sampleRate) {
SpeechRecognizer recognizer = null;
try {
// 传递用户自定义参数
String myParam = "user-param";
int myOrder = 1234;
SpeechRecognizerListener listener = getRecognizerListener(myOrder, myParam);
recognizer = new SpeechRecognizer(client, listener);
recognizer.setAppKey(appKey);
//设置音频编码格式 TODO 如果是opus文件,请设置为 InputFormatEnum.OPUS
recognizer.setFormat(InputFormatEnum.PCM);
//设置音频采样率
if(sampleRate == 16000) {
recognizer.setSampleRate(SampleRateEnum.SAMPLE_RATE_16K);
} else if(sampleRate == 8000) {
recognizer.setSampleRate(SampleRateEnum.SAMPLE_RATE_8K);
}
//设置是否返回中间识别结果
recognizer.setEnableIntermediateResult(true);
//此方法将以上参数设置序列化为json发送给服务端,并等待服务端确认
long now = System.currentTimeMillis();
recognizer.start();
logger.info("ASR start latency : " + (System.currentTimeMillis() - now) + " ms");
File file = new File(filepath);
FileInputStream fis = new FileInputStream(file);
byte[] b = new byte[3200];
int len;
while ((len = fis.read(b)) > 0) {
logger.info("send data pack length: " + len);
recognizer.send(b, len);
// TODO 重要提示:这里是用读取本地文件的形式模拟实时获取语音流并发送的,因为read很快,所以这里需要sleep
// TODO 如果是真正的实时获取语音,则无需sleep, 如果是8k采样率语音,第二个参数改为8000
// 8000采样率情况下,3200byte字节建议 sleep 200ms,16000采样率情况下,3200byte字节建议 sleep 100ms
int deltaSleep = getSleepDelta(len, sampleRate);
Thread.sleep(deltaSleep);
}
//通知服务端语音数据发送完毕,等待服务端处理完成
now = System.currentTimeMillis();
// TODO 计算实际延迟: stop返回之后一般即是识别结果返回时间
logger.info("ASR wait for complete");
recognizer.stop();
logger.info("ASR stop latency : " + (System.currentTimeMillis() - now) + " ms");
fis.close();
} catch (Exception e) {
System.err.println(e.getMessage());
} finally {
//关闭连接
if (null != recognizer) {
recognizer.close();
}
}
}
public void shutdown() {
client.shutdown();
}
// "e6hRW********ho" "659*************42ddf0f8016" "wss://nls-gateway.cn-shanghai.aliyuncs.com/ws/v1"
public static void main(String[] args) throws Exception {
String appKey = "你的appkey,在asr应用列表获取";
String token = "你的token,上一步生成的,也支持在asr后台获取临时的";
String url = ""; // 默认即可,默认值:wss://nls-gateway.cn-shanghai.aliyuncs.com/ws/v1
if (args.length == 2) {
appKey = args[0];
token = args[1];
} else if (args.length == 3) {
appKey = args[0];
token = args[1];
url = args[2];
} else {
System.err.println("run error, need params(url is optional): " + "<app-key> <token> [url]");
System.exit(-1);
}
SpeechRecognizerDemo demo = new SpeechRecognizerDemo(appKey, token, url);
// TODO 重要提示: 这里用一个本地文件来模拟发送实时流数据,实际使用时,用户可以从某处实时采集或接收语音流并发送到ASR服务端
demo.process("./nls-sample-16k.wav", 16000);
//demo.process("./nls-sample.opus", 16000);
demo.shutdown();
}
}
运行:
nls-sample-16k.wav 。
2:对接azure asr
2.1:pom
<dependency>
<groupId>com.microsoft.cognitiveservices.speech</groupId>
<artifactId>client-sdk</artifactId>
<version>1.40.0</version>
</dependency>
2.2:在线asr
package com.dahuyou.azure.asr.A;
import com.microsoft.cognitiveservices.speech.CancellationReason;
import com.microsoft.cognitiveservices.speech.ResultReason;
import com.microsoft.cognitiveservices.speech.SpeechConfig;
import com.microsoft.cognitiveservices.speech.SpeechRecognizer;
import com.microsoft.cognitiveservices.speech.audio.AudioConfig;
import com.microsoft.cognitiveservices.speech.audio.PushAudioInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class AzureSpeechRecognition {
public static void main(String[] args) {
try {
// 替换为你的订阅密钥和区域
String speechSubscriptionKey = "你的订阅密钥";
String region = "你的区域";
SpeechConfig speechConfig = SpeechConfig.fromSubscription(speechSubscriptionKey, region);
// 设置中文
speechConfig.setSpeechRecognitionLanguage("zh-CN");
// PushAudioInputStream pushAudioInputStream = new PushAudioInputStream();
PushAudioInputStream pushAudioInputStream = PushAudioInputStream.create();
// 使用默认麦克风
// AudioConfig audioConfig = AudioConfig.fromDefaultMicrophoneInput();
// Recognized: 北京的天气。
// AudioConfig audioConfig = AudioConfig.fromWavFileInput("D:\\xiaofuge_sourcecode\\interview-master\\aliasr\\nls-sample-16k.wav");
// AudioConfig audioConfig = AudioConfig.fromWavFileInput("D:\\test\\ttsmaker-file-2024-9-19-17-35-30.wav");
AudioConfig audioConfig = AudioConfig.fromStreamInput(pushAudioInputStream);
// 假设你有一个方法可以从网络接收音频流
// InputStream audioStream = receiveAudioStreamFromNetwork();
//
// // 准备AudioConfig(这里需要你自己实现转换逻辑)
// AudioConfig audioConfig = prepareAudioConfig(audioStream);
SpeechRecognizer recognizer = new SpeechRecognizer(speechConfig, audioConfig);
// 订阅事件
recognizer.recognized.addEventListener((s, e) -> {
if (e.getResult().getReason() == ResultReason.RecognizedSpeech) {
System.out.println("Recognized: " + e.getResult().getText());
}
});
recognizer.recognizing.addEventListener((s, e) -> {
if (e.getResult().getReason() == ResultReason.RecognizingSpeech) {
System.out.println("RecognizingSpeech: " + e.getResult().getText());
}
});
recognizer.canceled.addEventListener((s, e) -> {
System.out.println("Canceled " + e.getReason());
if (e.getReason() == CancellationReason.Error) {
System.out.println("Error details: " + e.getErrorDetails());
}
});
// 开始识别
recognizer.startContinuousRecognitionAsync().get();
String filepath = "d:\\test\\ttsmaker-file-2024-9-19-18-51-21.wav";
File file = new File(filepath);
FileInputStream fis = new FileInputStream(file);
byte[] b = new byte[3200];
int len;
while ((len = fis.read(b)) > 0) {
// recognizer.send(b, len);
byte[] usedByte = new byte[len];
if (len < 3200) {
System.arraycopy(b, 0, usedByte, 0, len);
} else {
usedByte = b;
}
System.out.println(" usedByte send data pack length: " + usedByte.length);
// pushAudioInputStream.write(b);
pushAudioInputStream.write(usedByte);
// TODO 重要提示:这里是用读取本地文件的形式模拟实时获取语音流并发送的,因为read很快,所以这里需要sleep
// TODO 如果是真正的实时获取语音,则无需sleep, 如果是8k采样率语音,第二个参数改为8000
// 8000采样率情况下,3200byte字节建议 sleep 200ms,16000采样率情况下,3200byte字节建议 sleep 100ms
// int deltaSleep = getSleepDelta(len, sampleRate);
int deltaSleep = 200;
Thread.sleep(deltaSleep);
usedByte = null;
}
pushAudioInputStream.close();
// 保持程序运行,等待用户输入或其他方式停止
System.in.read();
// 停止识别
recognizer.stopContinuousRecognitionAsync().get();
} catch (Exception ex) {
ex.printStackTrace();
}
}
// // 假设你有一个方法来接收网络上的音频流(这里用伪代码表示)
// static InputStream receiveAudioStreamFromNetwork() {
// // 使用HTTP、WebSocket等接收音频流
// // 这里返回一个InputStream,但实际上你可能需要更复杂的处理
// return new InputStream() {
// // 实现InputStream的read等方法来从网络读取数据
// };
// }
// // 将InputStream转换为Azure Speech SDK可以处理的格式(这里简化为直接返回)
在实际中,你可能需要将其写入WAV文件或使用内存中的流
// static AudioConfig prepareAudioConfig(InputStream inputStream) {
// // 注意:Azure Speech SDK的Java版本通常不直接从InputStream读取
// // 你可能需要将inputStream写入到WAV文件,并使用AudioConfig.fromWavFileInput
// // 但这里我们假设有一个方法可以直接处理
// // return AudioConfig.fromCustomStream(inputStream); // 这是一个假设的方法
// return null; // 实际上你需要实现这个转换
// }
}
运行:
RecognizingSpeech: 你好啊我
usedByte send data pack length: 3200
usedByte send data pack length: 3200
usedByte send data pack length: 3200
RecognizingSpeech: 你好啊我是
usedByte send data pack length: 3200
usedByte send data pack length: 3200
usedByte send data pack length: 3200
usedByte send data pack length: 3200
RecognizingSpeech: 你好啊我是张三
usedByte send data pack length: 2894
Recognized: 你好啊,我是张三。
Recognized:
Canceled EndOfStream
ttsmaker-file-2024-9-19-18-51-21.wav 。
写在后面
参考文章列表
Java SDK 。
azure 。
在线配音工具 。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 对接阿里asr和Azure asr

发表评论 取消回复