在统计建模中,普通最小二乘法(OLS)和岭回归是两种广泛使用的线性回归分析技术。OLS是一种传统的方法,它通过最小化预测值和实际值之间的平方误差之和来找到数据的最佳拟合线。然而,OLS可以遭受高方差和过拟合时,预测变量的数量是大的。为了解决这个问题,岭回归引入了一个正则化项,将系数缩小到零,这可以导致具有较低方差的更好模型。
相关概念:
- 普通最小二乘法(OLS):普通最小二乘法(OLS)是一种用于计算线性回归模型参数的技术。目标是找到最佳拟合线,使观测数据点与线性模型的预期值之间的残差平方和最小化。
- 岭回归:岭回归是线性回归中用于解决过拟合问题的一种技术。它通过向损失函数添加正则化项来实现这一点,这将系数缩小到零。这降低了模型的方差,并可以提高其预测性能。
- 正则化:正则化是一种用于防止机器学习模型中过拟合的技术。它通过向损失函数添加惩罚项来实现这一点,这阻止了模型拟合数据中的噪声。正则化可以通过L1正则化(Lasso),L2正则化(Ridge)或弹性网络等方法来实现,具体取决于实际问题。
- 均方误差(MSE):MSE是用于评估回归模型性能的指标。它测量预测值与实际值之间的平方差的平均值。较低的MSE表明模型和数据之间的拟合更好。
- R-Squared:R-Squared是用于评估回归模型拟合优度的度量。它测量因变量中由自变量解释的方差的比例。R-Squared的范围为0到1,值越大表示模型与数据之间的拟合越好。
示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.metrics import mean_squared_error
# Generate a synthetic dataset with a non-linear relationship
np.random.seed(42)
X = np.linspace(0, 10, 50)
y = np.sin(X) + np.random.normal(0, 0.5, 50)
# Fit OLS and Ridge Regression models with polynomial features
poly = PolynomialFeatures(degree=4)
X_poly = poly.fit_transform(X.reshape(-1, 1))
ols = LinearRegression().fit(X_poly, y)
ridge = Ridge(alpha=1).fit(X_poly, y)
# Predict the output for the test data points
X_test = np.linspace(-2, 12, 100).reshape(-1, 1)
X_test_poly = poly.transform(X_test)
ols_pred = ols.predict(X_test_poly)
ridge_pred = ridge.predict(X_test_poly)
# Compute the mean squared error on the test dataset
ols_mse = mean_squared_error(y_true=y, y_pred=ols.predict(X_poly))
ridge_mse = mean_squared_error(y_true=y, y_pred=ridge.predict(X_poly))
# Plot the data and the regression lines for OLS
plt.scatter(X, y, color='blue', label='Data')
plt.plot(X_test, ols_pred, color='red', label=f'OLS (MSE={ols_mse:.2f})')
plt.legend()
plt.title('Ordinary Least Squares with Polynomial Features')
plt.show()
# Plot the data and the regression lines for Ridge Regression
plt.scatter(X, y, color='blue', label='Data')
plt.plot(X_test, ridge_pred, color='green', label=f'Ridge (MSE={ridge_mse:.2f})')
plt.legend()
plt.title('Ridge Regression with Polynomial Features')
plt.show()
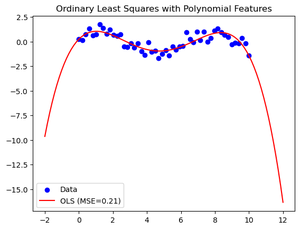
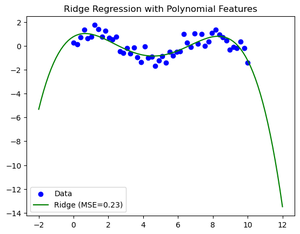
普通最小二乘与岭回归
假设我们有一个数据集,包含一个响应变量Y和一个预测变量X,其中有n个预测变量,如x1,x2,x3,…为了根据预测因子X预测Y,我们需要构建一个线性回归模型。在这种情况下,我们将比较岭回归和最小二乘(OLS)方法。
普通最小二乘法(OLS):OLS的目标是最小化残差平方和,并找到预测因子的最佳拟合系数。OLS估计量由下式给出:
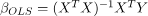
岭回归:岭回归将一个称为正则化参数的惩罚项添加到残差平方和中,以控制系数的大小。岭估计量由下式给出:
这里,λ(lambda)是正则化参数,I是单位矩阵。
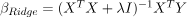
现在,让我们考虑预测变量的方差对使用OLS和岭回归获得的系数的影响。
假设x1的方差显著大于x2的方差。换句话说,与x2相比,x1具有更宽的值范围。
在OLS中,使用(X^T * X)的逆来估计系数,因此如果一个预测器具有较大的方差,则其将对估计的系数具有较大的影响。因此,与x2的系数相比,x1的系数将具有更高的方差。
在岭回归中,惩罚项λ乘以单位矩阵,这有助于将系数缩小到零。因此,岭回归减少了具有高方差的预测变量的影响。因此,即使x1具有更高的方差,x1和x2的岭系数也将具有相似的方差。
总之,当预测变量之间的方差存在差异时,OLS倾向于为与具有较高方差的预测变量相对应的系数提供给予较高的方差,而岭回归通过将系数之间的方差差缩小到零来减小它们。
注意:这里提供的示例假设了一个简单的场景来演示OLS和岭回归之间的方差差异。在实践中,OLS和岭回归之间的选择取决于各种因素,如数据特征,多重共线性的存在,以及偏差和方差之间的理想权衡。
代码示例
下面的代码生成了一个包含10个特征和50个样本的合成数据集。我们将数据分为训练集和测试集,并将OLS和岭回归模型拟合到训练数据中。然后,我们在测试数据集上计算两个模型的均方误差,并绘制两个模型的系数以可视化方差的差异。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.metrics import mean_squared_error
# Generate a synthetic dataset
np.random.seed(23)
X = np.random.normal(size=(50, 10))
y = X.dot(np.random.normal(size=10)) + np.random.random(size=50)
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = X[:40], X[40:], y[:40], y[40:]
# Fit OLS and Ridge Regression models to the training data
ols = LinearRegression().fit(X_train, y_train)
ridge = Ridge(alpha=1.2).fit(X_train, y_train)
# Compute the mean squared error on the test dataset
ols_mse = mean_squared_error(y_true=y_test, y_pred=ols.predict(X_test))
ridge_mse = mean_squared_error(y_true=y_test, y_pred=ridge.predict(X_test))
# Print the mean squared error of the two models
print(f"OLS MSE: {ols_mse:.2f}")
print(f"Ridge MSE: {ridge_mse:.2f}")
# Plot the coefficients of the two models
plt.figure(figsize=(10, 5))
plt.bar(range(X.shape[1]), ols.coef_, color='blue', label='OLS')
plt.bar(range(X.shape[1]), ridge.coef_, color='green', label='Ridge')
plt.xticks(range(X.shape[1]))
plt.legend()
plt.title('Coefficients of OLS and Ridge Regression Models')
plt.show()
输出
OLS MSE: 0.13
Ridge MSE: 0.09
该图显示,与岭回归模型的系数相比,OLS模型的系数在幅度上更大,范围更广。因此,可以得出结论,OLS模型在方差和对数据噪声的敏感性方面优于岭回归模型。
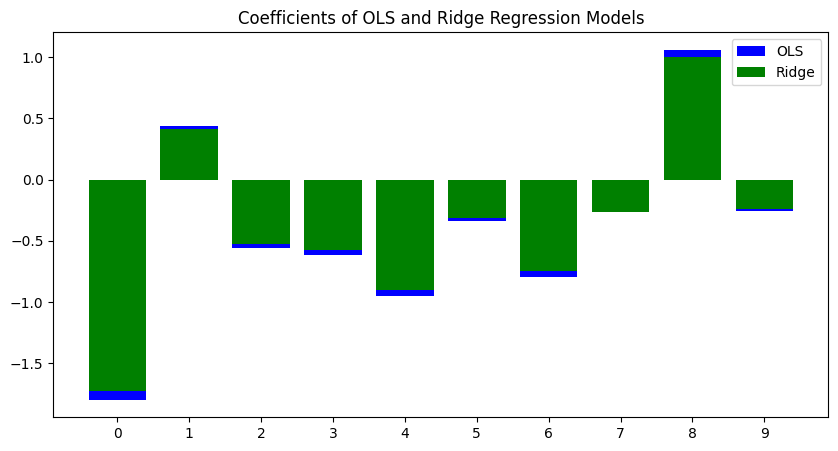
- OLS模型:OLS模型的MSE较高(0.13)表明与岭回归模型相比,它具有相对较高的总体方差。
- 岭回归模型:岭回归模型的MSE较低(0.09)表明与OLS模型相比,它具有较低的总体方差。
岭回归中的正则化参数(lambda)有助于管理最小化系数幅度和最小化残差平方和之间的权衡。岭回归可以通过添加惩罚项来减少模型中的方差,从而减少过拟合并提高泛化性能。
因此,岭回归模型的MSE较低(0.09)表明其方差低于OLS模型(0.13)。这表明岭回归模型在MSE方面对数据集的表现更好,因为它更好地消除了过拟合并捕获了数据中的潜在模式。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习 | Scikit Learn中的普通最小二乘法和岭回归

发表评论 取消回复