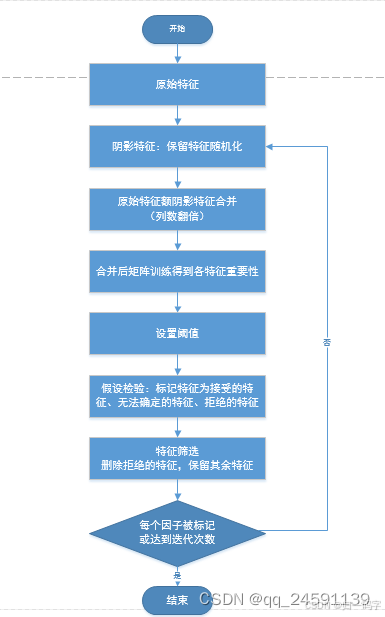
我在一个kaggle比赛时间预测中发现Boruta我并不熟悉与是我学习了一下
Boruta 的工作原理:
-
影子特征(Shadow Features):
-
Boruta 首先创建一组影子特征,这些影子特征是通过随机打乱原始特征的值生成的。影子特征的目的是作为对照组,帮助识别哪些原始特征是真正重要的。
-
-
特征重要性评估:
-
使用随机森林或其他基于树的模型(如 XGBoost、LightGBM)来评估每个特征(包括原始特征和影子特征)的重要性。
-
特征重要性通常通过计算特征在树模型中的平均信息增益或基尼指数来衡量。
-
-
统计显著性检验:
-
对于每个原始特征,Boruta 比较其重要性与影子特征的重要性。
-
如果原始特征的重要性显著高于影子特征的重要性,则认为该特征是重要的。
-
使用统计显著性检验(如 Wilcoxon signed-rank test)来判断原始特征的重要性是否显著高于影子特征。
-
-
迭代过程:
-
Boruta 通过多次迭代来逐步确认或排除特征。
-
在每次迭代中,Boruta 会标记出重要的特征(“确认”)、不重要的特征(“拒绝”)和不确定的特征(“暂定”)。
-
迭代过程会继续,直到所有特征都被确认或拒绝,或者达到预定的迭代次数。
-
Boruta 的优点:
-
自动化特征选择: Boruta 能够自动选择重要的特征,减少了手动特征工程的工作量。
-
统计显著性: 通过统计显著性检验,Boruta 能够识别出真正对目标变量有影响的特征。
-
适用于高维数据: Boruta 能够处理高维数据,并且能够识别出多个相关的特征。
Boruta 的缺点:
-
计算开销: Boruta 的迭代过程可能会导致较高的计算开销,尤其是在处理大规模数据集时。
-
参数调整: Boruta 有一些参数需要调整,如迭代次数、随机森林的参数等,这些参数可能会影响特征选择的结果。
-
-
引用CSDN这篇题主发的图片可以理解的更加清楚,其实质是对数据尽行预处理的处理低价值区
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Boruta 的库的初识

发表评论 取消回复