前言
Embeddings(嵌入)是表示任何类型数据的AI原生方式,它非常适用于各种AI驱动的工具和算法中。它们可以表示文本、图像,很快还可以表示音频和视频。有许多创建嵌入的选项,无论是在本地使用已安装的库,还是通过调用API。
而Chroma为流行的嵌入提供商提供了轻量级的封装,使其易于在你的应用程序中使用。你可以在创建Chroma集合时设置一个嵌入函数,该函数将自动使用,也可以自己直接调用它们。
下面是提供嵌入函数的厂商,当然也包括国内厂商,可以自行了解,这里不再罗列。
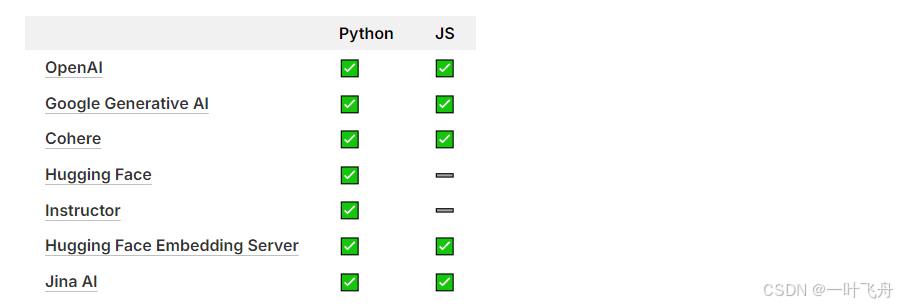
下面博主通过Hugging Face提供的all-MiniLM-L6-v2模型创建嵌入,请各位紧随博主,以防迷路。
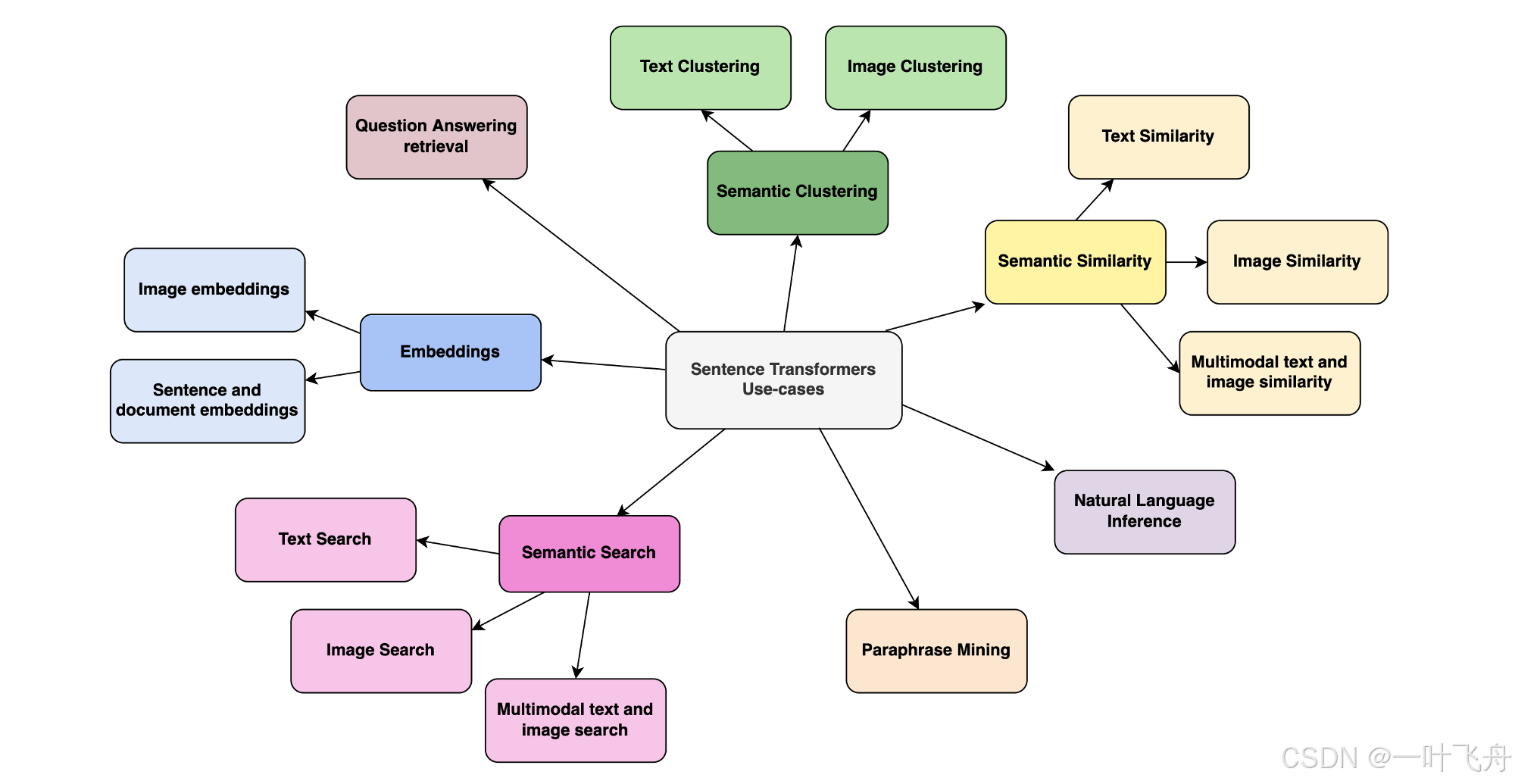
Q:如何通过langchain结合chroma完成检索
langchain提供了各种嵌入的接口,所以你根据它可以很容易完成数据的embedding。在试用前,必须安装相关模块:
| 序号 | 模块名称 | 模块用途 |
|---|---|---|
| 1 | langchain | 安装langchain框架,集成嵌入接口 |
| 2 | langchain-chroma | 集成chroma数据库 |
| 3 | sentence-transformers | hugging face模型库sdk,可以加载嵌入模型 |
| 4 | langchain_text_splitters | 集成文本切割器 |
| 5 | chroma | chroma数据库 |
1. 安装langchain
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain-core
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain-community
2. 安装langchain-chroma
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain-chroma
3. 安装langchain_text_splitters
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple langchain_text_splitters
4. 安装sentence-transformers
sentence-transformers是一个python库,该库提供了一种简单的方法来计算句子、段落和图像的密集向量表示。这些模型基于BERT/RoBERTa/XLM RoBERTa等网络,在各种任务中实现了最先进的性能。同时也支持文本嵌入在向量空间中,使得相似的文本更接近,并且可以使用余弦相似度有效地找到。
pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple sentence-transformers
5. 安装chroma
请参考 ChromaDB教程_2024最新版(上)完成。
6. 下载all-MiniLM-L6-v2
去hugging face官网,将该模型下载至本地后,保持原目录存储,如下所示:

7. 基于all-MiniLM-L6-v2嵌入并查询的示例
from langchain_community.document_loaders import UnstructuredHTMLLoader
from langchain_text_splitters import CharacterTextSplitter
from langchain_community.vectorstores import Chroma
# 加载txt/html文件为document
file_path = "html/云原生.txt"
# 数据存储位置
vector_dir = 'chromadb/col01'
# embedding模型
model_path = 'embedding/all-MiniLM-L6-v2'
loader = UnstructuredHTMLLoader(file_path)
mydata = loader.load()
# 创建文本分割器
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=0
)
# 创建文档
docs = text_splitter.split_documents(mydata)
# 集成embedding函数
my_embedding = SentenceTransformerEmbeddings(
model_name=model_path
)
vectordb = Chroma.from_documents(
documents=docs,
embedding=my_embedding,
persist_directory=vector_dir
)
query = '一叶飞舟在哪里'
retriever = vectordb.as_retriever(search_type="mmr")
s = retriever.get_relevant_documents(query)
print(f'相似的文档:{s}')
执行结果如下:
当然你可以通过sqlite工具,看看这个库长什么样:

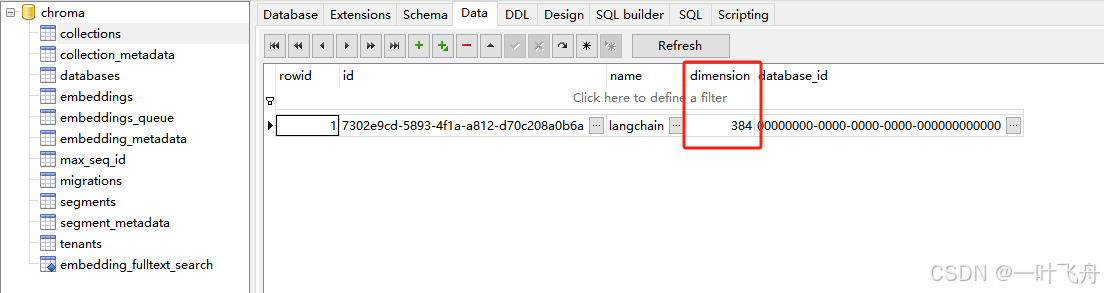
all-MiniLM-L6-v2支持384维的向量存储(适合学习、研究),如果维度更大,相对的存储要求更高。
结语
本文通过langchain结合chromadb实现相似建设,并且基于自定义embedding函数(依赖all-MiniLM-L6-v2)完成embedding。在这个基础上,可以结合大模型,完成最佳实践。
走过的、路过的盆友们,点点赞,收收藏,并加以指导,以备不时之需哈~
精彩回顾
ChromaDB教程_2024最新版(上)
基于LangChain的大模型学习手册之Embedding(保姆级)
基于DashScope+Streamlit构建你的机器学习助手(入门级)
基于LangChain的大模型学习手册(入门级)
基于Python的大模型学习手册(入门级)

本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » ChromaDB教程_2024最新版(下)

发表评论 取消回复