内容回顾:
深入理解指针第一章节的内容已经结束。
深入理解指针(一):深入理解指针(一)-CSDN博客
深入理解指针(二):深入理解指针(二)-CSDN博客
深入理解指针(三):深入理解指针(三)-CSDN博客
1.数组名的理解
在上一章节我们在使用指针访问数组的内容时,有这样的代码:
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];这里我们使用&arr[0]的方式拿到了数组的第一个元素的地址,但是其实数组名本身就是地址,而且是数组首元素的地址,我们拿来做个测试。
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}输出结果:
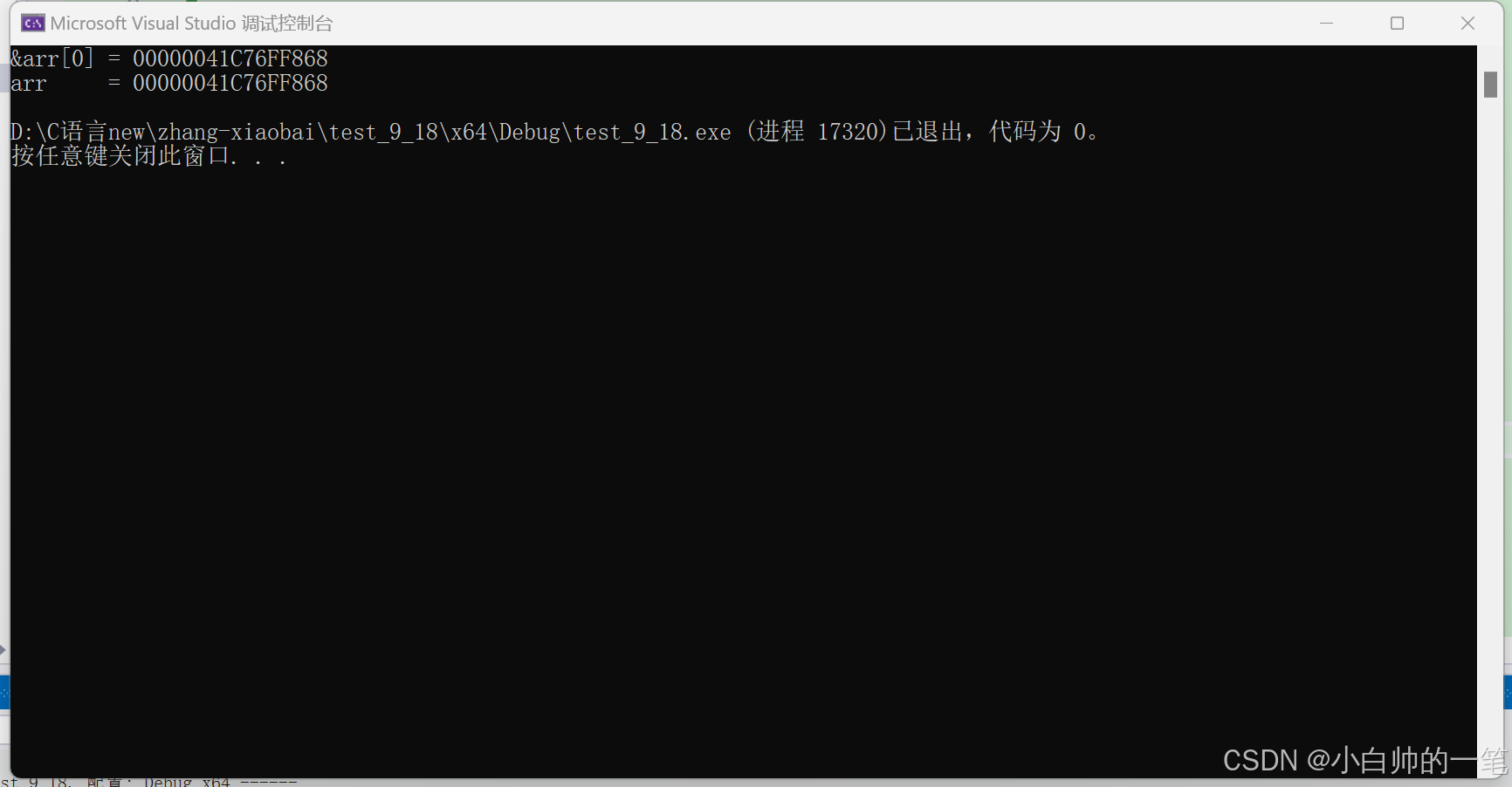
我们发现数组名和数组首元素的地址打印出来的结果一模一样,数组名就是数组首元素(第一个元素)的地址。
但是!
数组名是数组首元素的地址,但有两个例外:
- sizeof(数组名),sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节
- &数组名,这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的)
除此之外,任何地方使用数组名,数组名都是首元素的地址。
观察下列代码:
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
printf("&arr = %p\n", &arr);
return 0;
}结果运行发现三个打印结果一摸一样,那arr和&arr有什么区别呢?
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}输出结果:
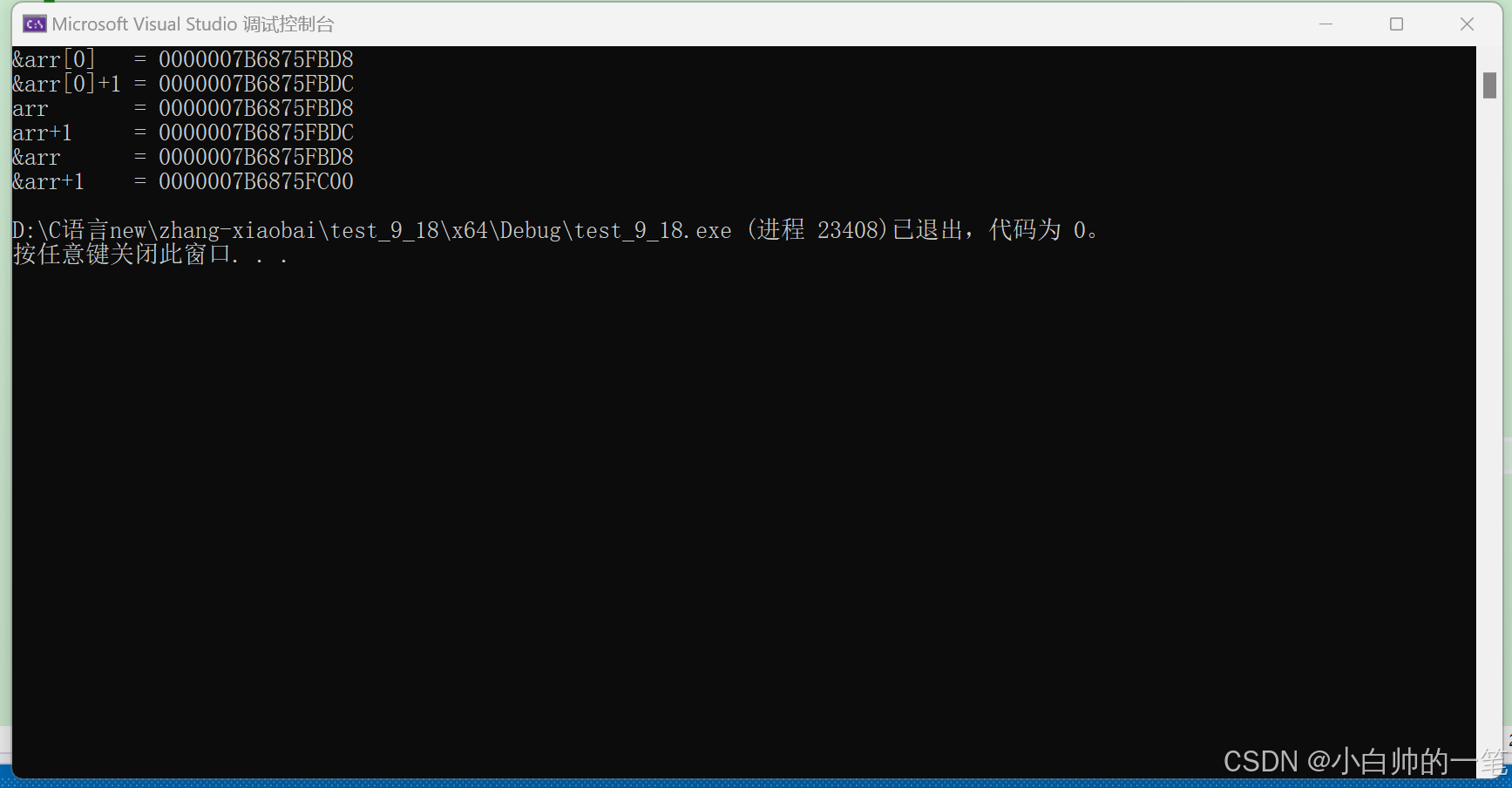
这里我们发现&arr[0]和&arr[0]+1相差4个字节,arr和arr+1相差4个字节,是因为&arr[0]和arr都是首元素的地址,+1就是跳过一个元素。
但是&arr和&arr+1相差40个字节,这就是因为&arr是数组的地址,+1跳过整个数组。
这样就可以很好的李俊杰数组名的意义了。
2.使用指针访问数组
int main()
{
int arr[10] = { 0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
}
for (i = 0; i < sz; i++)
{
printf("%d ", *(p + i));
}
return 0;
}搞懂了这个代码, 我们再分析一下,数组名arr是数组首元素的地址,可以赋值给p,其实数组名arr和p在这里是等价的。那我们可以使用arr[i]访问数组的元素,那p[i]是否也可以访问数组呢?
int main()
{
int arr[10] = { 0 };
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
int* p = arr;
for (i = 0; i < sz; i++)
{
scanf("%d", p + i);
}
for (i = 0; i < sz; i++)
{
printf("%d ", p[i]);
}
return 0;
}我们将*(p+i)换成p[i]也是可以正常打印的,所以本质上p[i] == *(p+i)。
同理arr[i] == *(arr+i),数组元素的访问在编译期处理的时候,也是转换为首元素的地址+偏移量求出元素的地址,然后解引用来访问的。
3.一维数组传参的本质
数组我们学习过,数组是可以传递给参数的,接下来我们讨论一下数组传参的本质。
首先,我们之前都是在函数外部计算数组的元素个数,那我们可以把数组传给一个参数后,函数内部求数组的元素个数吗?
void test(int arr[])
{
int sz2 = sizeof(arr) / sizeof(arr[0]);
printf("sz2=%d\n", sz2);
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int sz1 = sizeof(arr) / sizeof(arr[0]);
printf("sz1=%d\n", sz1);
test(arr);
return 0;
}输出的结果:

我们发现在元素内部没有获得正确的数组的元素个数。
上一部分我们讲过:数组名是数组首元素的地址;那么在数组传参的时候,传递的是数组名,也就是本质上数组传参传递的是数组首元素的地址。
所以函数形参的部分理论上应该是使用指针变量来接收首元素的地址。那么在函数内部我们写siezof(arr)计算的是一个地址的大小(单位字节) 而不是数组的大小(单位字节)。正是因为函数的参数部分的本质是指针,所以在函数内部是没有办法求数组元素个数的。
void test(int arr[])//参数写成数组形式,本质上还是指针
{
printf("%d\n", sizeof(arr));
}
void test(int* arr)//参数写成指针形式
{
printf("%d\n", sizeof(arr));//计算一个指针变量的大小
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
test(arr);
return 0;
}总结:一维数组传参,形参的部分可以写成数组的形式,也可以写成指针的形式。
4.冒泡排序
了解了以上知识,我们可以运用起来学习冒泡排序。
冒泡排序在之前文章详细讲解过,链接为:C语言如何进行冒泡排序-CSDN博客
5.二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里?
就是二级指针中。
int main()
{
int a = 10;
int* pa = &a;
int** ppa = &pa;
return 0;
}对于二级指针的运算有:
- *ppa通过对ppa中的地址进行解引用,这样找到的是pa,*ppa其实访问的是pa。
- **ppa先通过*ppa找到pa,然后对pa进行解引用操作:*pa,那找到的就是a。
6.指针数组
指针数组是指针还是数组?
类比一下可知,整型数组是存放整形的数组,字符数组是存放字符的数组。
那指针数组就是存放指针的数组。
指针数组的每个元素都是用来存放地址(指针)的。
指针数组的每个元素是地址,又可以指向一块区域。
7.指针数组模拟二维数组
int main()
{
int arr1[] = { 1,2,3,4,5 };
int arr2[] = { 2,3,4,5,6 };
int arr3[] = { 3,4,5,6,7 };
int* parr[3] = { arr1,arr2,arr3 };
int i = 0;
int j = 0;
for (i = 0; i < 3; i++)
{
for (j = 0; j < 5; j++)
{
printf("%d ", parr[i][j]);
}
printf("\n");
}
return 0;
}parr[i]是访问parr数组的元素,parr[i]找到的数组元素指向了整形一维数组,parr[i][j]就是整型一维数组中的元素。
上述代码模拟出二维数组的效果,但实际上并非完全是二维数组,因为每一行并非是连续的。
完。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 深入理解指针(四)

发表评论 取消回复