ISIC 2024 - Skin Cancer Detection with 3D-TBP | Kaggle
这是一个kaggle项目,我以前都是仅使用了kaggle的数据集,较少的完整参与了一次kaggle项目,这一次就是我自己独立完成的一次kaggle竞赛,没有其他人组队,然后成功提交了一个不怎么样的结果哈哈,虽然我这一次参加的比赛比较仓促,获得的分数也比较低,但是我还是记录一下自己的建模和数据处理和分析过程,以便于记录一下自己的kaggle成长记录。
1、概述
在这场比赛中,将开发基于图像的算法,从3D全身照片(TBP)中识别组织学确诊的具有单病变作物的皮肤癌症病例。图像质量类似于特写智能手机照片,这些照片通常用于远程医疗目的。预测的二元分类算法可以在没有专业护理的情况下使用,并改进早期皮肤癌症检测的分类。
2、说明
如果不及早发现,皮肤癌症可能是致命的,但许多人群缺乏专门的皮肤科护理。在过去的几年里,基于皮肤镜的人工智能算法已被证明有利于临床医生诊断黑色素瘤、基底细胞癌和鳞状细胞癌。然而,确定哪些人应该首先去看临床医生具有巨大的潜在影响。分类应用具有显著的潜力,可以使服务不足的人群受益,并改善癌症的早期检测,这是长期患者结果的关键因素。
皮肤镜图像显示了肉眼不可见的形态特征,但这些图像通常只在皮肤科诊所拍摄。使初级保健或非临床环境中的人们受益的算法必须擅长评估低质量的图像。这场比赛利用3D TBP展示了来自三大洲数千名患者的每一个病变的新数据集,其图像类似于手机照片。
这场比赛挑战开发人工智能算法,将组织学上确诊的恶性皮肤病变与患者的良性病变区分开来。您的工作将有助于提高早期诊断和疾病预后,将自动皮肤癌症检测的优势扩展到更广泛的人群和环境中。
3、评价指标
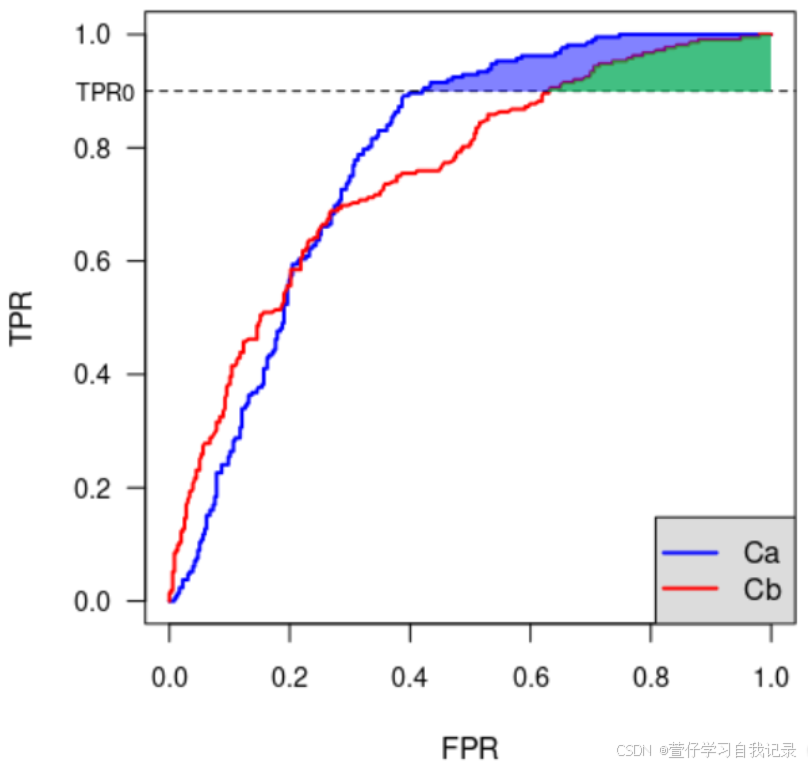
提交的材料根据ROC曲线下部分面积(pAUC)进行评估,真实阳性率(TPR)高于80%,用于恶性病例的二元分类。
(ROC)曲线说明了给定二元分类器系统在其鉴别阈值变化时的诊断能力。然而,在ROC空间中,有些区域的TPR值在临床实践中是不可接受的。辅助诊断癌症的系统需要高度敏感,因此该指标主要是 ROC 曲线下部分面积 (pAUC) 高于 80% 真阳性率 (TPR)。因此,得分范围为[0.0,0.2]。
以下示例中的阴影区域表示两个任意算法(Ca和Cb)在任意最小TPR下的pAUC:
(也就是说如下图所示,就是要带颜色的那一块来算)
4、数据集介绍
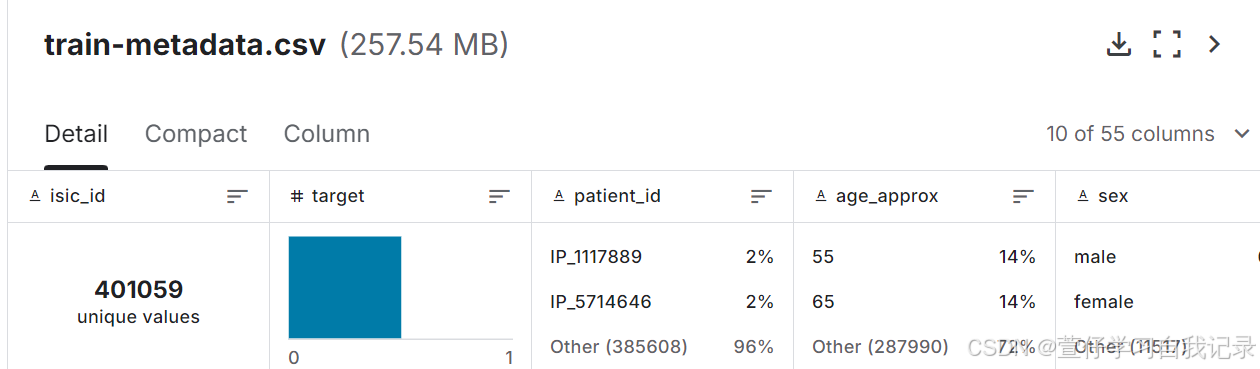
该数据集由带有额外元数据的诊断标记图像组成。这些图像是JPEG格式的。相关的.csv文件包含一个二进制诊断标签(目标)、潜在的输入变量(例如age_approx、sex、anatom_site_general等)和其他属性(例如图像源和精确诊断)。
在这个挑战中,要区分良性和恶性病例。对于每幅图像(isic_id),您将分配该病例为恶性的概率(目标)范围[0,1]。
SLICE-3D数据集-从3D TBP提取的皮肤病变图像作物,用于皮肤癌症检测:
为了模拟非皮肤镜图像,本次比赛使用了来自3D全身摄影(TBP)的标准化裁剪病变图像。Vectra WB360是Canfield Scientific的3D TBP产品,可在一张宏观质量分辨率断层图像中捕获完整的可见皮肤表面区域。然后,基于人工智能的软件在给定的3D捕捉中识别出单个病变。这允许图像捕获和识别患者身上的所有病变,并将其导出为单独的15x15 mm视场裁剪照片。该数据集包含2015年至2024年间在九个机构和三大洲看到的数千名患者的每个病变。
文件介绍
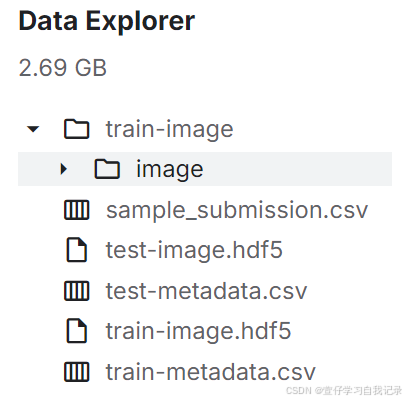
1.train-image-训练集的图像文件

(这里被我手动打了个码,可以去官网自行下载数据集)
2.train-image.hdf5-包含在单个hdf5文件中的训练图像数据,以isic_id为关键字
3.train-metadata.csv-训练集的数据
4.test-image.hdf5-包含在单个hdf5文件中的测试图像数据,以isic_id为键。这包含3个测试示例,测试一下我的模型是不是好的。当重新运行提交的结果的时候,此文件将与包含约50万张图像的完整隐藏测试集交换。
5.test-metadata.csv-测试子集的元数据
6.sample_submission.csv-格式正确的示例提交文件
5、自己的模型建立流程
首先要对数据集进行清理,可以发现,数据集有图像数据集和特征的数据集构成,我个人准备将图像数据和一些特征的数据结合,然后将图像预测的生成相应的特征,再输入到后续的模型(可以深度学习也可以机器学习)进行处理,这就需要图像这方面搞一个深度学习模型,后面加入了一个机器学习模型。
数据清理流程如下:
对除了图像以外的特征进行数据处理,由于肉眼观察法(哈哈)的train和test的列数目都不一样,也就是特征不太一样,节约时间处理我选择了直接去掉不一样的列(但是大家不要学我,因为这个处理方式导致我的模型结果非常拉跨,但是我发现这个比赛已经快结束了,我只呢选择了最快的处理方式,主要为了尝试一下我的想法是否能对形成一个很好的结果,事实证明数据特征工程是非常重要的,如果自己没有好好处理数据,得到训练模型的结果可能非常不同)
以下代码是把图像数据和原本其他的结构数据读出来的方法:
import h5py
import io
import pandas as pd
from PIL import Image
from torch.utils.data import Dataset
class XUANDataset(Dataset):
def __init__(self, csv_file, img_hdf5_file, transform=None, is_test=False):
self.data = pd.read_csv(csv_file)
self.img_hdf5_file = img_hdf5_file
self.transform = transform
self.is_test = is_test
self.image_ids = self.data['isic_id'].values
if 'target' in self.data.columns:
self.structured_data = self.data.drop(columns=['isic_id', 'target'])
else:
self.structured_data = self.data.drop(columns=['isic_id'])
for col in self.structured_data.columns:
if self.structured_data[col].dtype == 'object':
self.structured_data[col] = self.structured_data[col].astype(str).str.extract('(\d+)').astype(float)
self.structured_data = self.structured_data.fillna(0).values.astype(np.float32)
if not is_test:
self.targets = self.data['target'].values.astype(np.float32)
else:
self.targets = None
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
with h5py.File(self.img_hdf5_file, 'r') as hdf5_file:
image_key = self.image_ids[idx]
image_data = hdf5_file[image_key][()]
image = Image.open(io.BytesIO(image_data))
if self.transform:
image = self.transform(image)
structured_data = torch.tensor(self.structured_data[idx], dtype=torch.float32)
if self.targets is not None:
target = torch.tensor(self.targets[idx], dtype=torch.float32)
return image, structured_data, target
else:
return image, structured_data, self.image_ids[idx]
因为他那个图像很小,我这边选择了不太大的深度学习模型进行训练,比如lenet和自己设了一个简单的simplecnn和resnet18和MobileNetV1模型进行对图像的处理,然后后面的由于时间原因,我在进行图形之后都直接加入了了一个xgb模型,进行和这些结构的数据进行合并。
示例:
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, kernel_size=5)
self.conv2 = nn.Conv2d(6, 16, kernel_size=5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 1)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
其他模型的代码我都放入了我的代码仓库里面,希望大家能给我打个星星(感谢大佬
训练过程:
我这边还是选择了把train数据集掰成90-10的部分进行一个训练,
train_size = int(0.9 * len(train_dataset))
val_size = len(train_dataset) - train_size
train_set, val_set = random_split(train_dataset, [train_size, val_size])然后接下来是保存我训练权重,然后进行一个训练过程
best_auc = 0
for epoch in range(20):
train_features = []
train_labels = []
# 训练过程
for images, structured_data, targets in train_loader:
images, structured_data = images.to(device), structured_data.to(device)
features = combined_model(images, structured_data)
train_features.append(features)
train_labels.append(targets.numpy())
train_features = np.vstack(train_features)
train_labels = np.hstack(train_labels)
xgb_model.fit(train_features, train_labels)
# 验证过程
val_features = []
val_labels = []
for images, structured_data, targets in val_loader:
images, structured_data = images.to(device), structured_data.to(device)
features = combined_model(images, structured_data)
val_features.append(features)
val_labels.append(targets.numpy())
val_features = np.vstack(val_features)
val_labels = np.hstack(val_labels)
val_preds = xgb_model.predict_proba(val_features)[:, 1]
auc = roc_auc_score(val_labels, val_preds)
print(f"Epoch {epoch+1}: AUC = {auc:.4f}")
# 保存最佳模型
if auc > best_auc:
best_auc = auc
torch.save(combined_model.state_dict(), '0906best_combined_model.pth')
xgb_model.save_model('0906best_xgb_model.json')然后,重点就是,他那个kaggle的笔记本,必须得传进去之后先跑一边,这样才能上传结果并保存,我这边就是先训练好了模型,然后把模型放入到笔记本里,直接进行一个测试的步骤,省的他自己在那个笔记本上进行训练,免费gpu时间不够主要是。
这样上传,等他跑完就可以了
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » kaggle项目:ISIC 2024 - Skin Cancer Detection with 3D-TBP

发表评论 取消回复