需求:
1、做某个文件的词频统计//某个单词在这个文件出现次数
步骤:
- 文件单词规律(空格分开)
- 单词切分
- 单词的统计(k,v)->(k:单词,V:数量)
- 打印
框架:
- 单例对象,main()
- 创建CONF
- 创建SC-->读取文件的方式--》RDD
- RDD进行处理
- 闭资源关
一、新建object类取名为WordCount

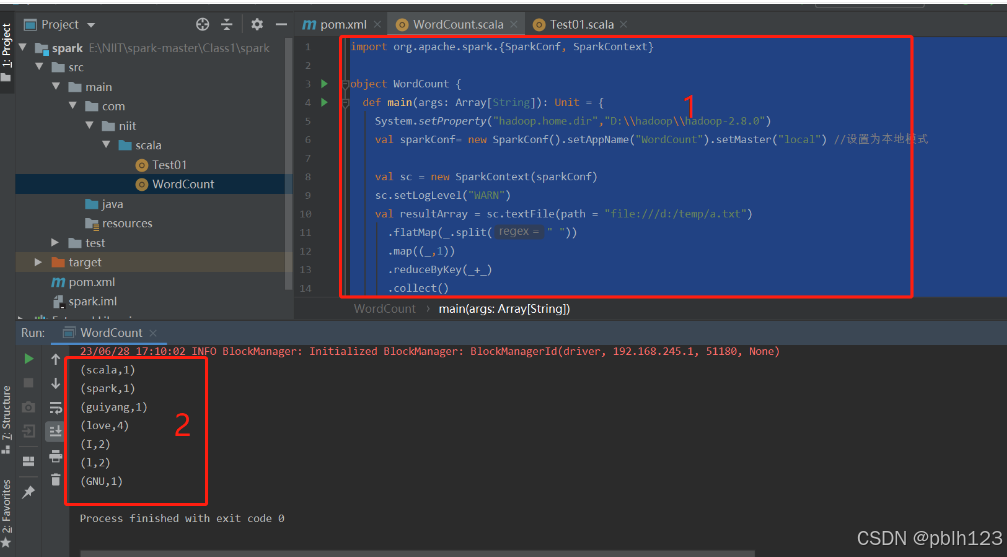
2、编写如下代码
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir","D:\\hadoop\\hadoop-2.8.0")
val sparkConf= new SparkConf().setAppName("WordCount").setMaster("local") //设置为本地模式
val sc = new SparkContext(sparkConf)
sc.setLogLevel("WARN")
val resultArray = sc.textFile(path = "file:///d:/temp/a.txt")
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.collect()
resultArray.foreach(println )
sc.stop()
}
}3、本地运行,查看运行结果如下:
解决无法下载spark与打包插件的办法
maven打包插件与spark所需依赖下载地址:
链接:百度网盘 请输入提取码
提取码:jnta
解决步骤:
到网盘下载maven打包插件与spark依赖,网盘吗中的内容如下:
- 将下载的插件plugins.rar解压,并复制插件文件夹到你本地maven仓库下
- 将下载的spark依赖spark.rar解压,并复制spark文件夹到你本地maven仓库下
- 重启idea,重新build下工程
将下载的插件plugins.rar解压,并复制插件文件夹到你本地maven仓库下
将下载的spark依赖spark.rar解压,并复制spark文件夹到你本地maven仓库下
重启idea,重新build下工程
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 2023_Spark_实验九:编写WordCount程序(Scala版)

发表评论 取消回复