点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(正在更新…)
章节内容
上节我们完成了如下的内容:
- Apache Druid 数据存储
- Apache Druid 数据分区
- 索引服务
- 压缩机制
- 数据聚合

整体流程
- Kafka 数据源: Kafka 是一个分布式流处理平台,负责接收、存储并传输数据。它支持从各类应用、日志、传感器等设备采集实时数据,将数据划分为多个主题(Topic),并将消息分发给消费者。在这个案例中,Kafka 是 Druid 的数据源。
- Kafka Producer: 数据生产者(Producer)负责将数据发送到 Kafka 的主题中。例如,应用程序可以向 Kafka 写入日志、用户行为数据、传感器数据等。每条消息可以是 JSON、Avro 等格式的数据记录。
- Druid Kafka Ingestion: Druid 提供了对 Kafka 的原生支持。通过 Kafka Indexing Service,Druid 可以持续从 Kafka 的某个主题中消费数据,实时地将这些数据摄取到 Druid 中。摄取过程中,Druid 会将数据拆解为小的段(Segment),并将这些段存储在 Druid 集群的深度存储中(如 HDFS、S3 等)。
- 实时数据摄取和索引: Druid 的 Kafka 摄取任务会监听 Kafka 的分区,按照流数据的到达顺序消费数据,并在内部创建索引。这些索引结构化存储了数据,并通过分片和分区机制,保证了查询的高效性和水平扩展能力。
- Druid 查询层: Druid 提供了非常强大的查询能力,可以通过 SQL 查询方式进行交互,也支持多维查询、聚合查询等。这些查询可以是低延迟的实时查询,也可以对历史数据进行复杂的分析。用户通过 Druid 查询接口或 BI 工具(如 Apache Superset、Tableau 等)向集群发送查询。
- Kafka 消费者 Offset 管理: Druid 使用 Kafka 消费者模型,实时消费消息并管理 Offset(偏移量),确保数据不丢失或重复摄取。Offset 会被定期提交到 Kafka 中,保证即使任务重启,摄取进度也能从上一次的位置继续。
- 持久化和数据存储: 数据在经过摄取和索引后,Druid 会定期将数据段(Segment)持久化到深度存储中,并对旧数据进行合并和压缩,减少存储空间的占用。Druid 的集群架构支持分布式存储和查询,并能根据数据规模进行自动扩展。
案例假设
假设我们在构建一个用户行为分析系统,通过 Kafka 采集用户点击日志,并通过 Druid 实时分析用户行为。
- Kafka 数据生产: 电商平台的应用程序会将每次用户点击产生的日志记录(例如点击商品、页面浏览等)发送到 Kafka 中的 user-clicks 主题。每条记录都包含用户ID、商品ID、时间戳、页面信息等。
- Druid 数据摄取: 配置 Druid 的 Kafka Indexing Service,从 user-clicks 主题消费数据。数据会实时流入 Druid 中,Druid 将数据按照时间范围切分为段,并存储到其深度存储中。
- 实时数据查询与分析: 业务方可以通过 SQL 查询或多维查询接口,实时分析用户的点击行为。查询的例子可能是统计每个小时的页面浏览量、分析不同商品的受欢迎程度等。这些查询可以直接反映用户的当前行为,帮助业务方做出快速决策。
- 可视化和报表: Druid 的查询结果可以通过 Apache Superset 等工具进行可视化展示,创建实时仪表盘,展示用户行为的各种关键指标。数据分析师和运营人员可以在可视化平台上直观地看到当前系统的运营状态。
需求分析
场景分析
- 数据量大,需要在这些数据中根据业务需要灵活查询
- 实时性要求高
- 数据实时的推过来,要在秒级对数据进行分析并查询出结果
数据描述
{"ts":1607499629841,"orderId":"1009388","userId":"807134","orderStatusId":1,"orderStatus":"已支付","payModeId":0,"payMode":"微信","payment":"933.90","products":
[{"productId":"102163","productName":"贝合xxx+粉","price":18.7,"productNum":3,"categoryid":"10360","catname1":"厨卫清洁、纸制用品","catname2":"生活日用","catname3":"浴室用品"},{"productId":"100349","productName":"COxxx0C","price":877.8,"productNum":1,"categoryid":"10302","catname1":"母婴、玩具乐器","catname2":"西洋弦乐器","catname3":"吉他"}]}
- ts 交易时间
- orderId 订单编号
- userId 用户id
- orderStatusId 订单状态Id
- orderStatus 订单状态 0-11:未支付,已支付,发货中,已发货,发货失败,已退款,已关单,订单过期,订单已失效,产品已失效,代付拒绝,支付中
- payModelId 支付方式id
- payMode 支付方式:0-6:微信,支付宝,信用卡,银联,货到付款,现金,其他
- payment:支付金额
- products:购买商品 (一个订单可能包含多个商品,这里是嵌套结构)
- productId 商品Id
- productName 商品名称
- price 单价
- productNum 购买数量
- categoryid 商品分类Id
- catname1 商品一级分类名称
- catname2 商品二级分类名称
- catname3 商品三级分类名称
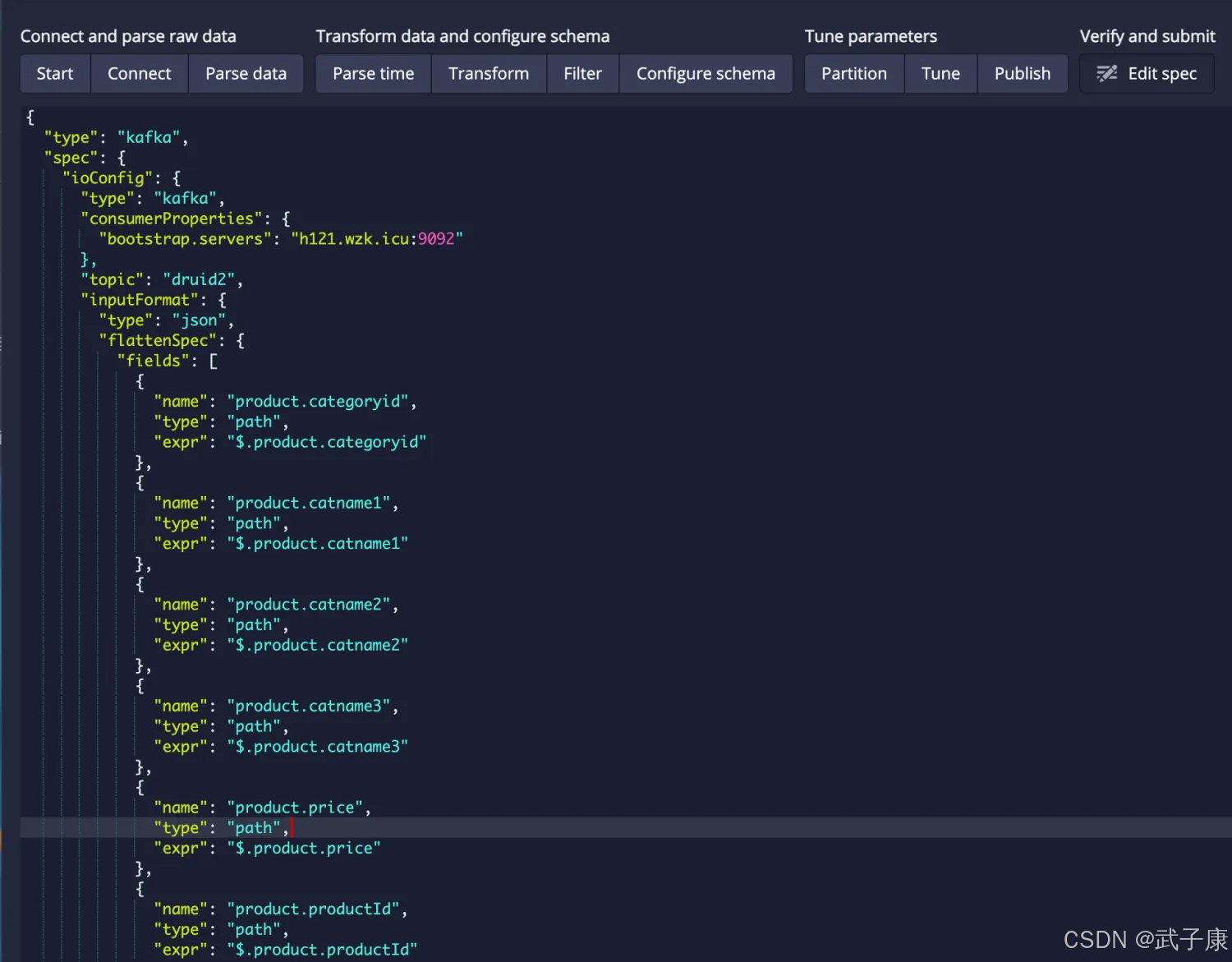
以上的嵌套的json数据格式,Druid不好处理,需要对数据进行预处理,将数据拉平,处理后的数据格式:
{"ts":1607499629841,"orderId":"1009388","userId":"807134","orderStatusId":1,"orderStatus":"已支付","payModeId":0,"payMode":"微信","payment":"933.90","product":
{"productId":"102163","productName":"贝合xxx+粉","price":18.7,"productNum":3,"categoryid":"10360","catname1":"厨卫清洁、纸制用品","catname2":"生活日用","catname3":"浴室用品"}}
{"ts":1607499629841,"orderId":"1009388","userId":"807134","orderStatusId":1,"orderStatus":"已支付","payModeId":0,"payMode":"微信","payment":"933.90","product":
{"productId":"100349","productName":"COxxx0C","price":877.8,"productNum":1,"categoryid":"10302","catname1":"母婴、玩具乐器","catname2":"西洋弦乐器","catname3":"吉他"}}
Kafka生产者
好久没用Scala了,用Scala写一个:
package icu.wzk.kafka
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.common.serialization.StringSerializer
import java.util.Properties
import scala.io.BufferedSource
object KafkaProducerForDruid {
def main(args: Array[String]): Unit = {
val brokers = "h121.wzk.icu:9092"
val topic = "druid2"
val prop = new Properties()
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokers)
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, classOf[StringSerializer])
val producer = new KafkaProducer[String, String](prop);
val source: BufferedSource = scala.io.Source.fromFile("orders1.json")
val iter: Iterator[String] = source.getLines();
iter.foreach {
line => val msg = new ProducerRecord[String, String](topic, line);
producer.send(msg)
println(msg)
Thread.sleep(10)
}
producer.close()
source.close()
}
}
运行结果如下图:
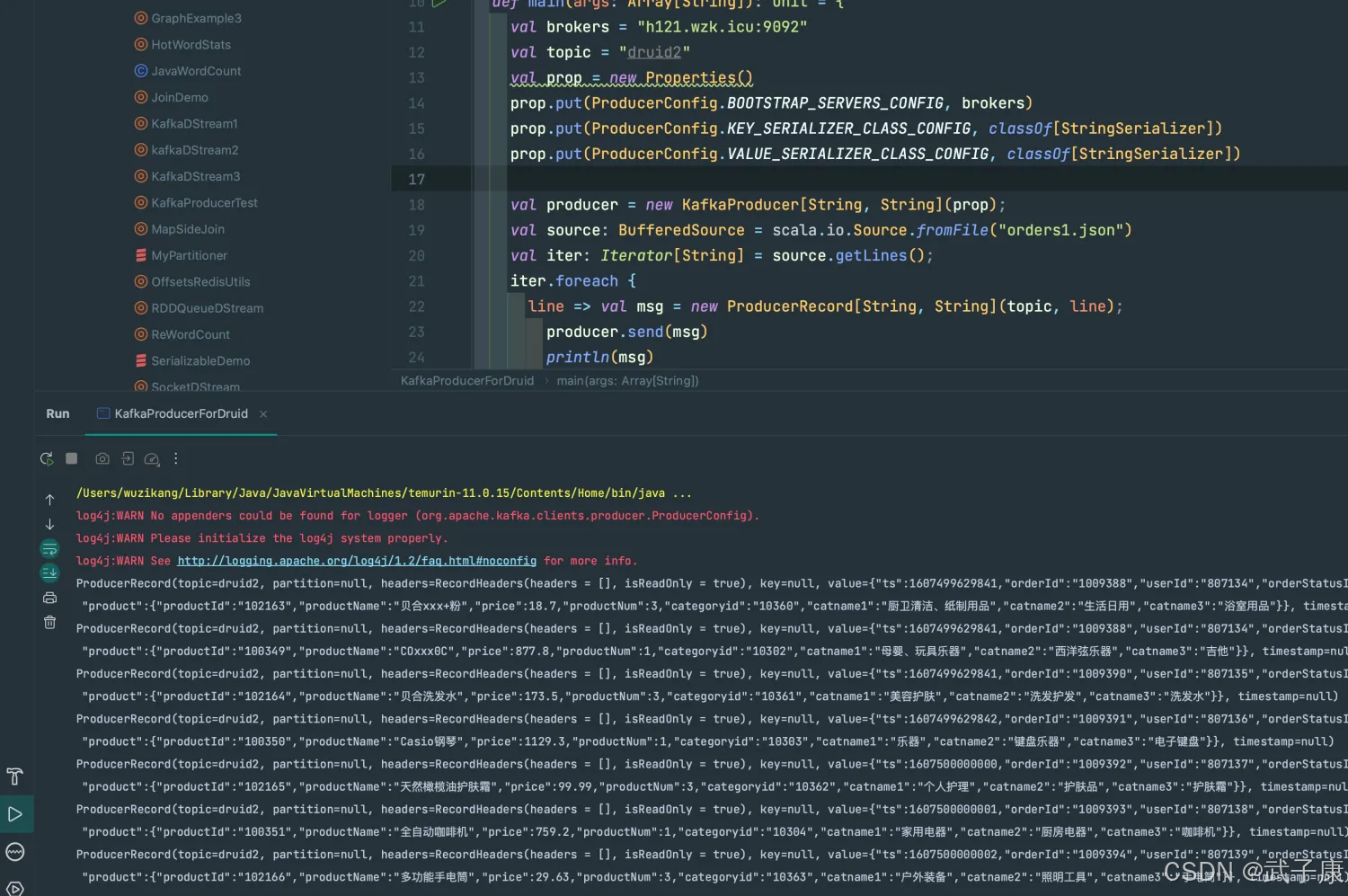
Druid导入数据
这里就不详细描述了,之前入门阶段已经走过完整的流程了:
- JSON数据要拉平
- 不定义 RollUp
加载数据源:
JSON 拉平:
时间戳:
不要进行 RollUp:
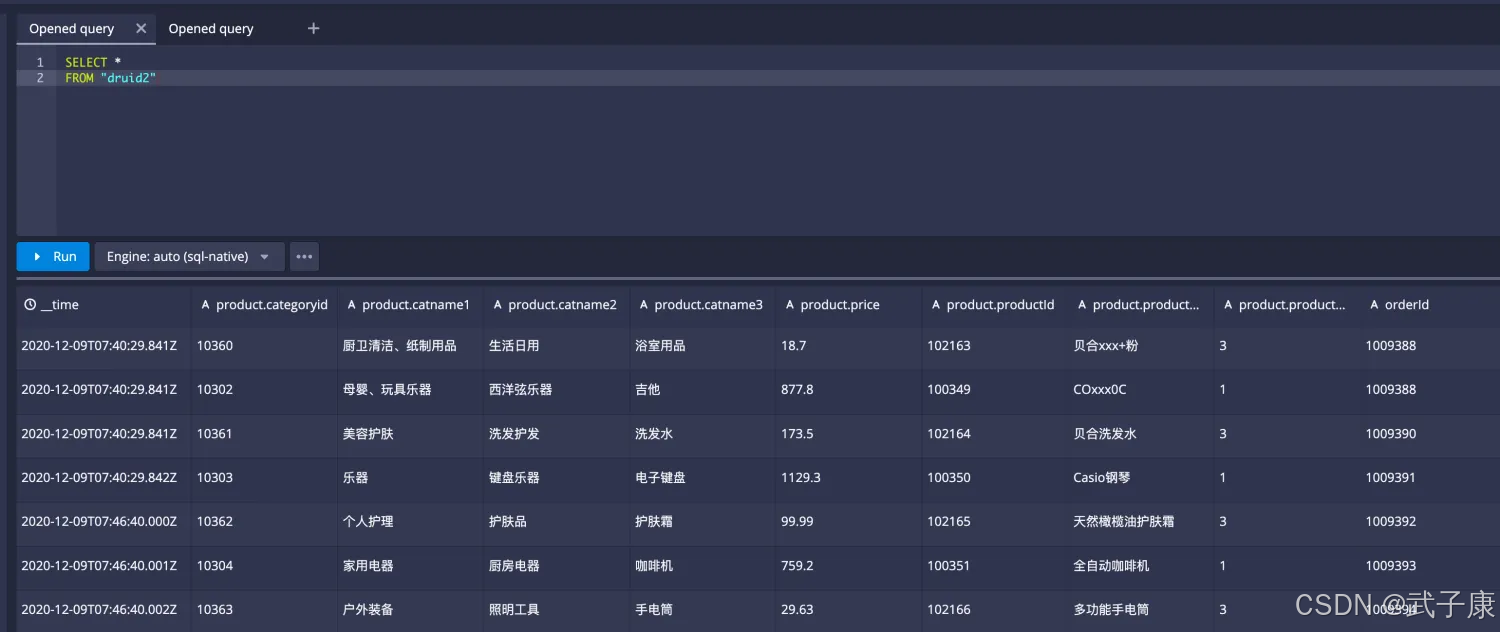
最终结果如下图所示:
计算结果如下图所示:
运行测试的SQL,一切正常!
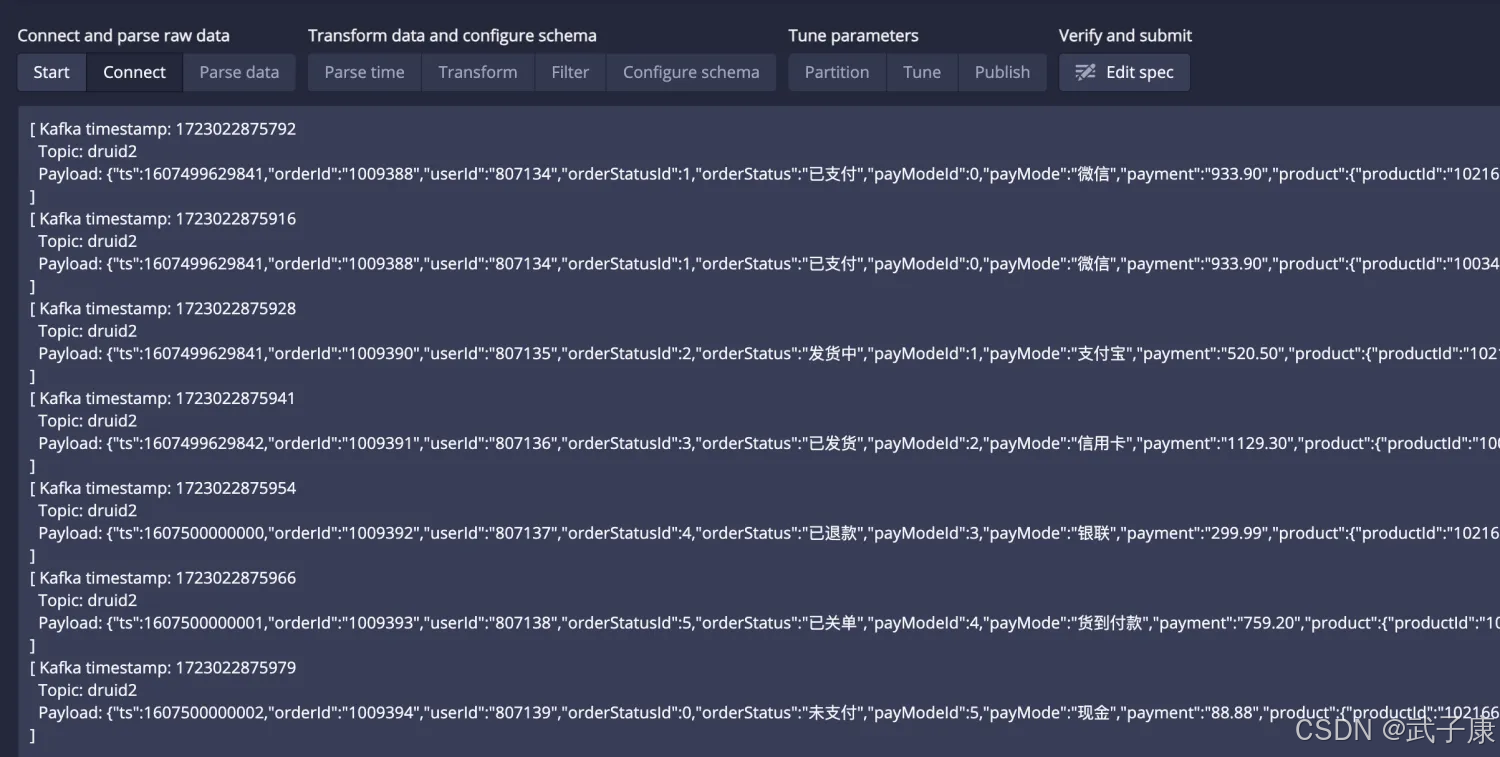
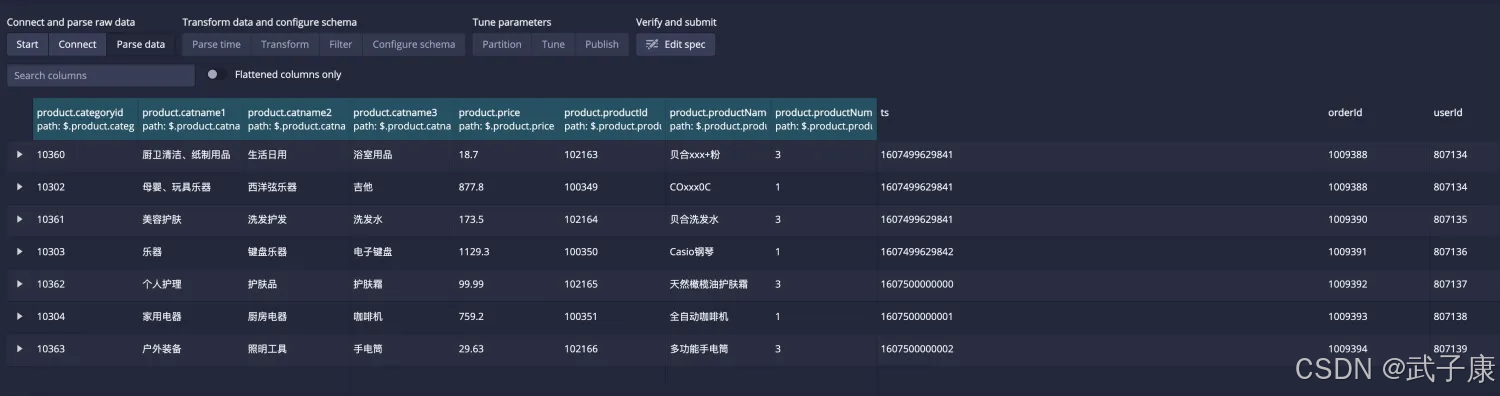
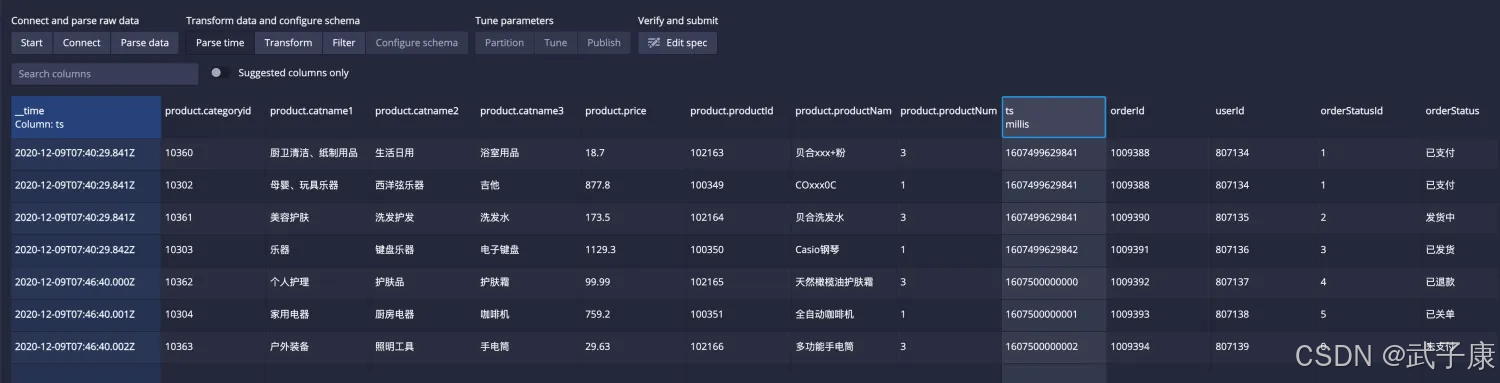

查询计算
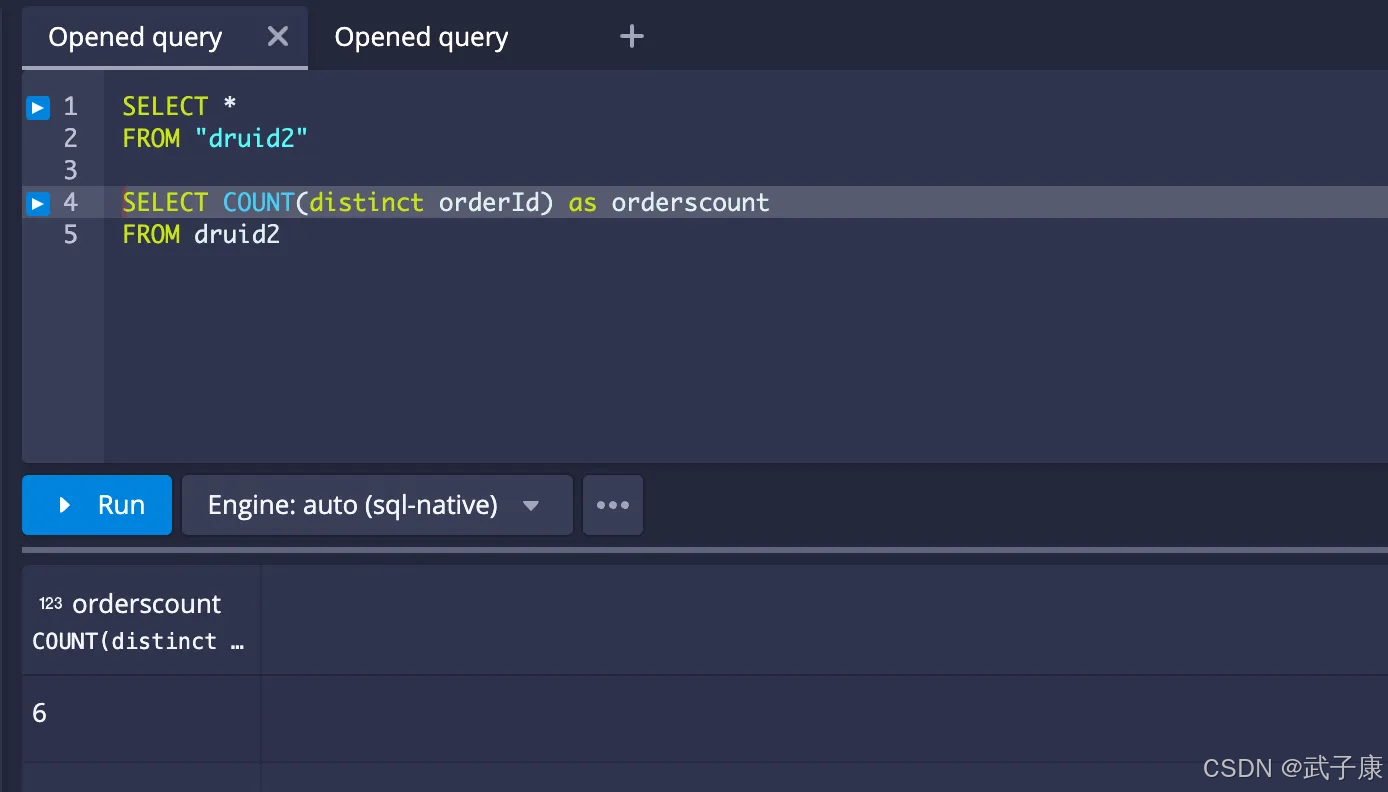
订单总数
-- 查询订单总数
SELECT COUNT(distinct orderId) as orderscount
FROM druid2
运行结果如下图所示:
用户总数
-- 查询用户总数
SELECT COUNT(distinct userId) as usercount
FROM druid2
运行结果如下图:
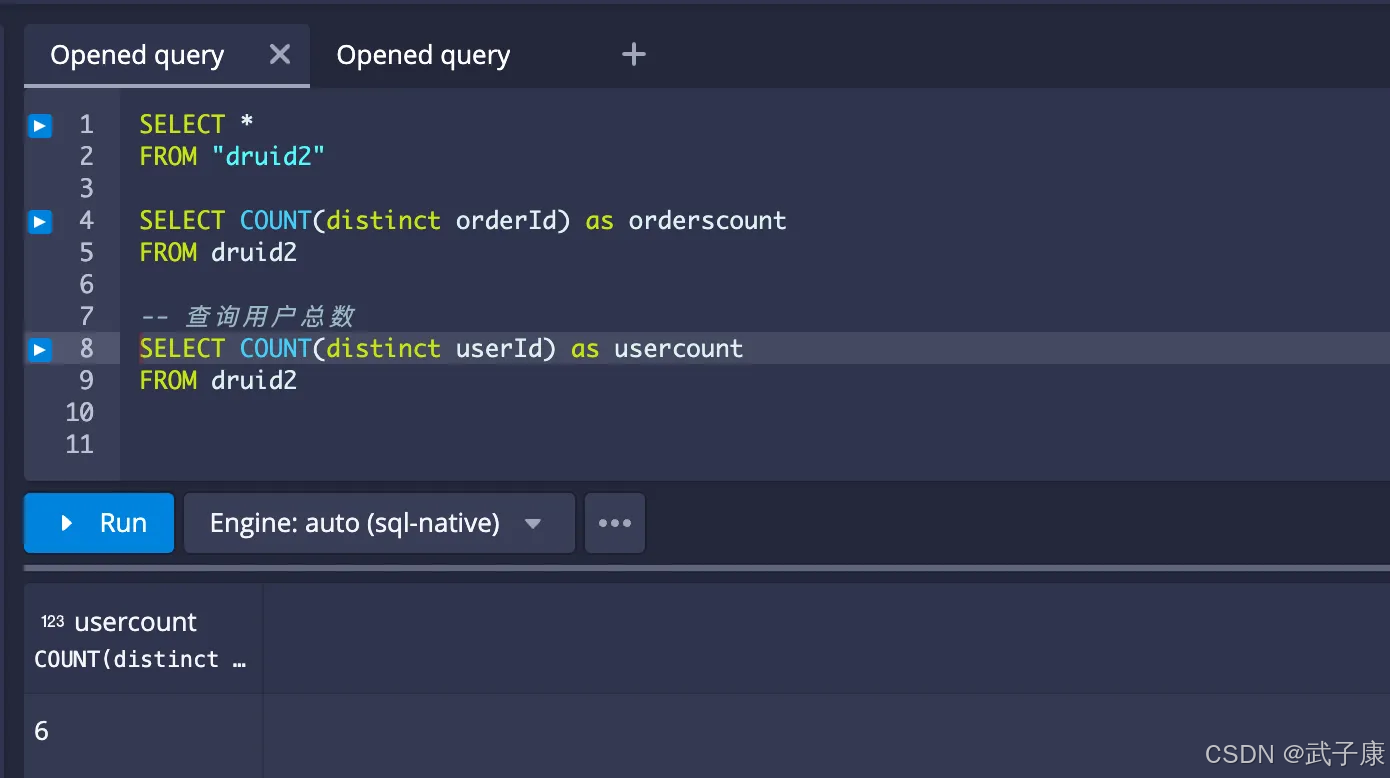
统计结果状态订单数
-- 统计各种订单状态的订单数
SELECT orderStatus, count(*)
FROM (
SELECT orderId, orderStatus
FROM druid2
GROUP BY orderId, orderStatus
)
GROUP BY orderStatus
执行结果如下图所示:
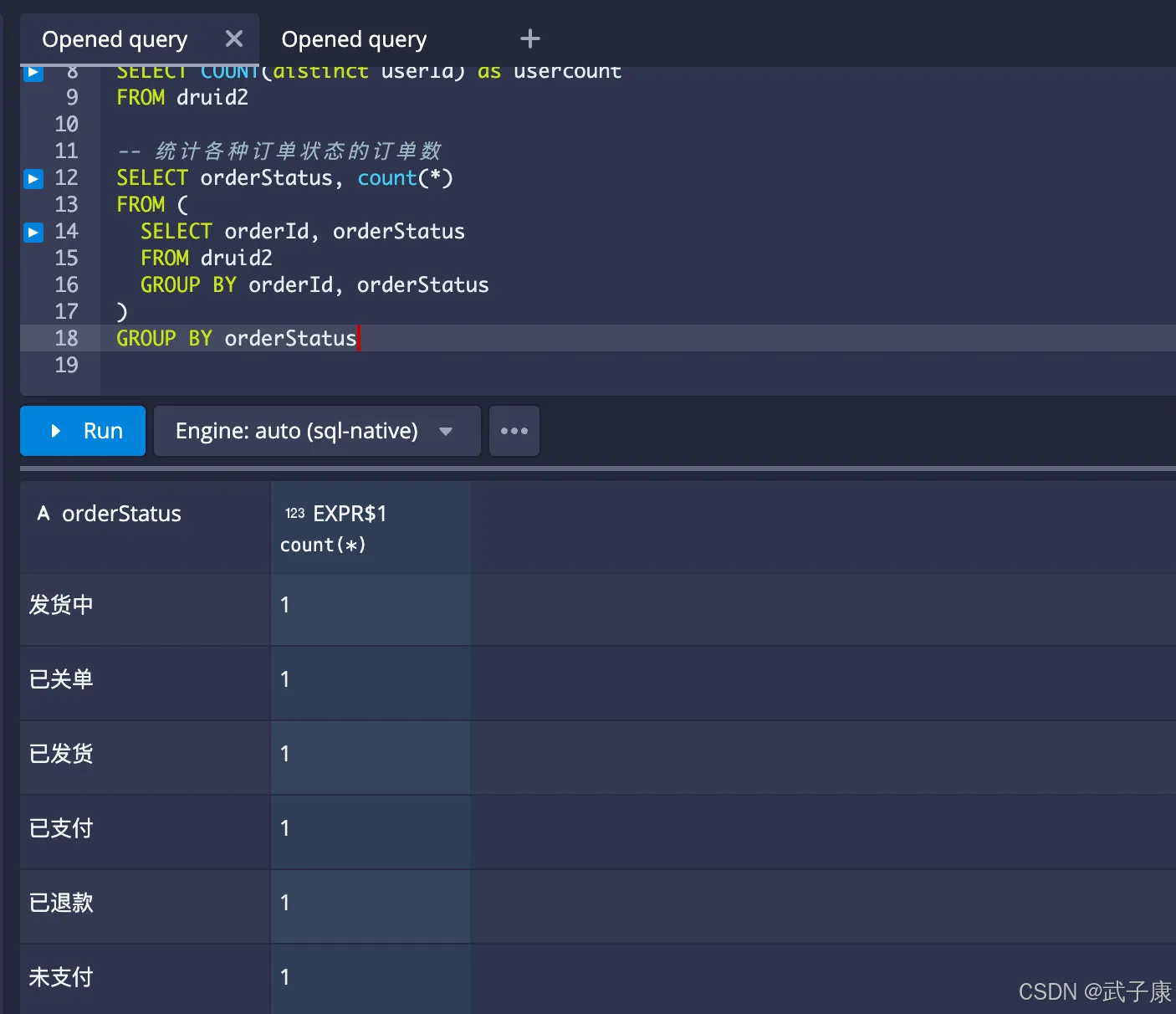
统计各种支付方式的订单数
-- 统计各种支付方式订单数
SELECT payMode, count(1)
FROM (
SELECT orderId, payMode
FROM druid2
GROUP BY orderId, payMode
)
GROUP BY payMode
执行结果如下图所示:
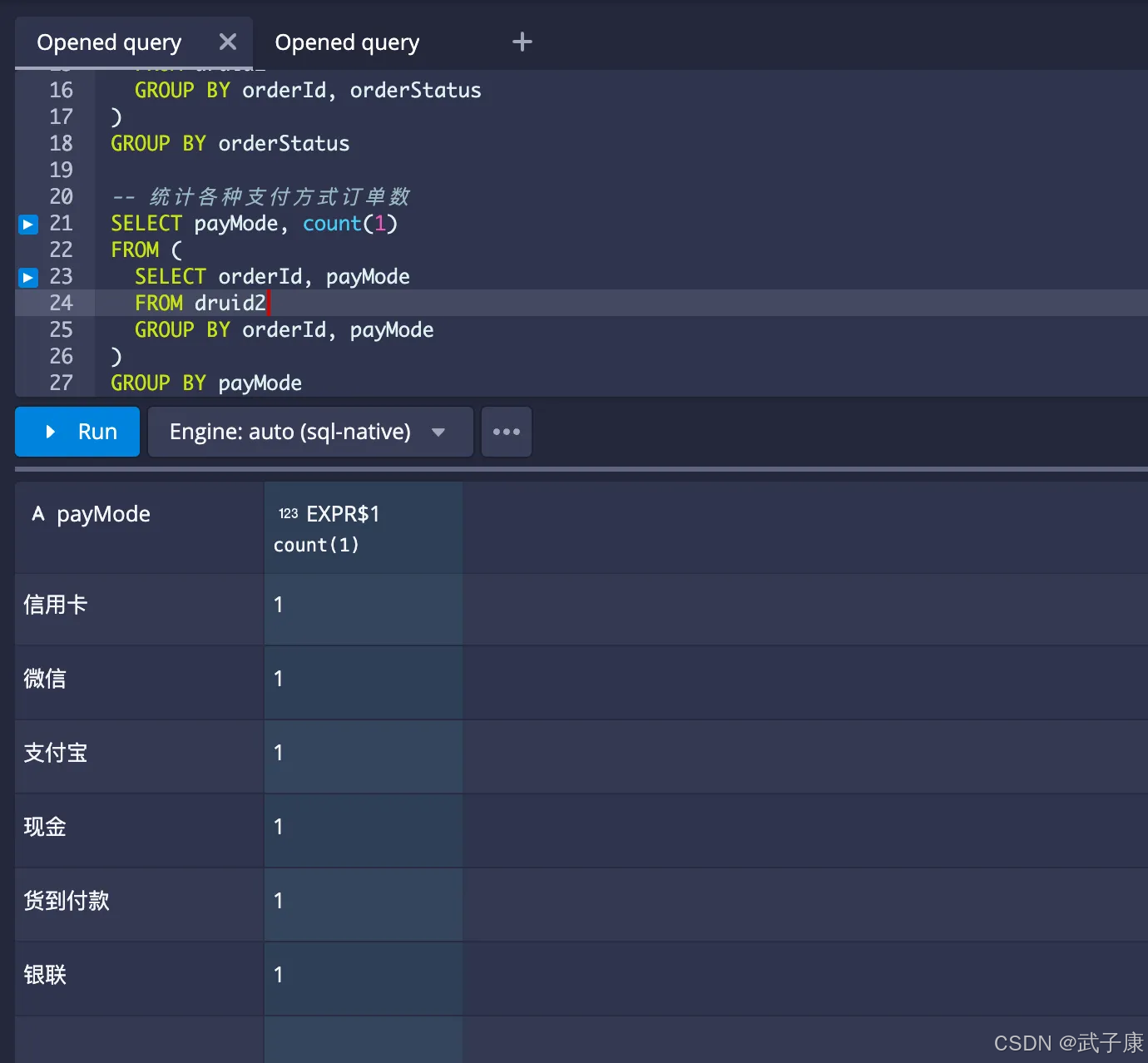
订单金额最大的前10名
-- 订单金额最大的前10名
SELECT orderId, payment, count(1) as productcount, sum("product.productNum") as products
FROM druid2
GROUP BY orderId, payment
执行结果如下图所示:
案例小节
- 在配置摄入源时要设置为True从流的开始进行消费数据,否则在数据源中可能查不到数据
- Druid的JOIN能力非常有限,分组或者聚合多的场景推荐使用
- SQL支持能力非常受限
- 数据的分区组织只有时间序列一种方式
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-156 Apache Druid 案例实战 Scala Kafka 订单统计

发表评论 取消回复