目录
一、Docker网络
1、原生bridge网络
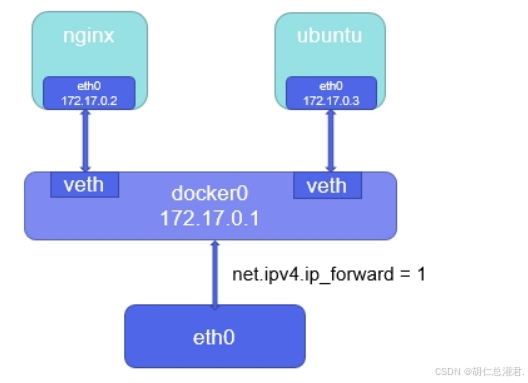
在原生 Docker 中,网络模式为 bridge 时的 docker0 起着关键作用。它充当一个虚拟网桥,连接着容器和宿主机的网络环境,使得容器可以通过这个网桥与宿主机以及外部网络进行通信,实现容器在隔离环境下的网络连接和数据传输功能。
bridge模式下容器没有一个公有ip,只有宿主机可以直接访问,外部主机是不可见的。 容器通过宿主机的NAT规则后可以访问外网。
[root@docker-node1 ~]# grubby --update-kernel ALL --args iptables=true
[root@docker-node1 ~]# reboot
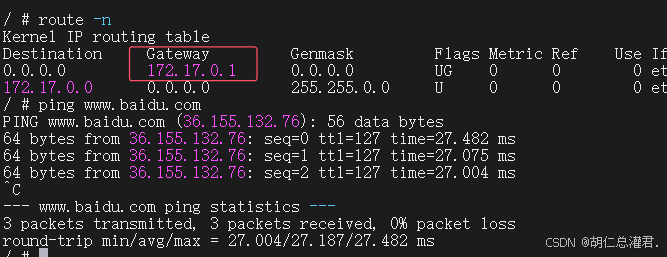
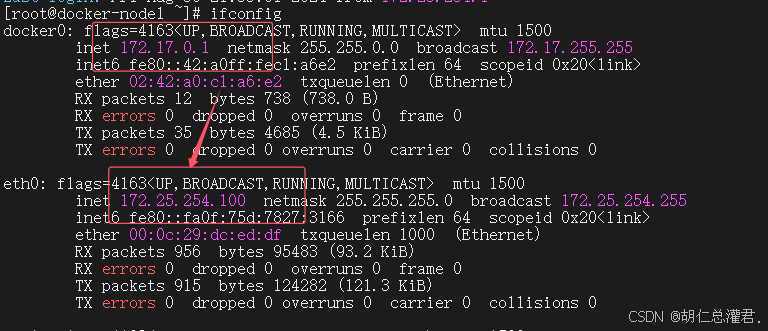
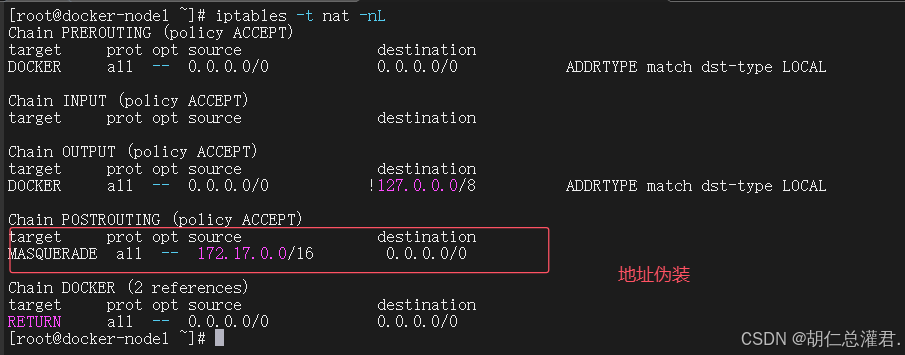
“grubby --update-kernel ALL --args iptables=true” 这个命令的作用是更新所有内核,并为内核传递参数 “iptables=true”。这通常用于确保系统内核在启动时启用 iptables(一种防火墙工具)。通过这个命令,可以确保系统在启动新内核时能够正确地配置和使用 iptables 进行网络流量过滤和安全控制等操作。在 Docker 使用 bridge 网络模式时,容器的 IP 地址通常在 172.17.0.0/16 这个网段。当容器中的应用发出访问外网的请求并经过 POSTROUTING 链时,“MASQUERADE” 规则发挥作用。这个规则会将来自 172.17.0.0/16 网段的流量进行源地址伪装,也就是把容器的源 IP 地址伪装成宿主机的真实 IP 地址,使得外部网络看到的请求来源像是来自宿主机,从而实现容器能够顺利地访问外网。这样的设置确保了容器可以与外部网络进行通信,同时也便于对容器的网络流量进行管理和控制。
2、host网络
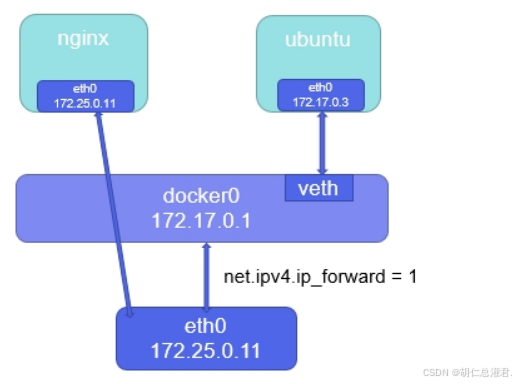
在 Docker 中,host 网络模式使容器直接使用宿主机的网络栈,容器不会拥有独立的网络命名空间。这意味着容器将共享宿主机的 IP 地址、端口范围、网络接口等,与宿主机在网络层面几乎完全一致。其作用在于可以让容器直接使用宿主机的网络资源,避免网络隔离带来的复杂性,适用于那些对网络性能要求高或者需要与宿主机完全一致网络环境的应用场景。
3、none网络
在 Docker 中,none 网络模式为容器提供了一种完全隔离的网络环境。在这种模式下,容器没有任何网络接口、IP 地址等网络配置,不与任何外部网络或其他容器进行通信。它的主要作用是为那些对网络安全有极高要求,或者希望完全控制容器网络配置的用户提供一种基础的、无网络连接的起始状态,以便后续根据特定需求进行自定义的网络配置。
4、docker自定义桥接网络
1、Docker自定义网络
自定义网络模式,docker提供了三种自定义网络驱动: bridge overlay macvlan bridge驱动类似默认的bridge网络模式,但增加了一些新的功能, overlay和macvlan是用于创建跨主机网络 建议使用自定义的网络来控制哪些容器可以相互通信,还可以自动DNS解析容器名称到IP地址。
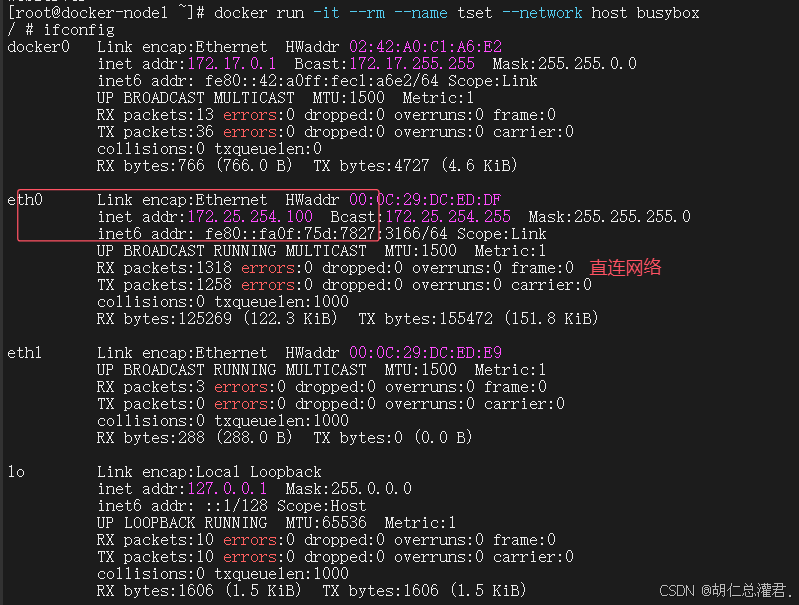
[root@docker-node1 ~]# docker run -it --name test --network bridge busybox
[root@docker-node1 ~]# docker run -it --name test1 --network bridge busybox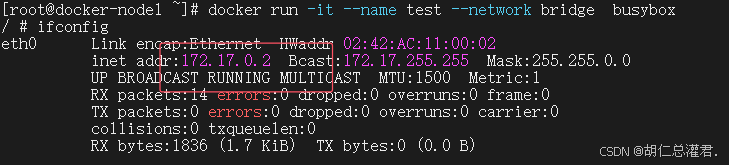

按照开启容器的先后顺序进行ip分配
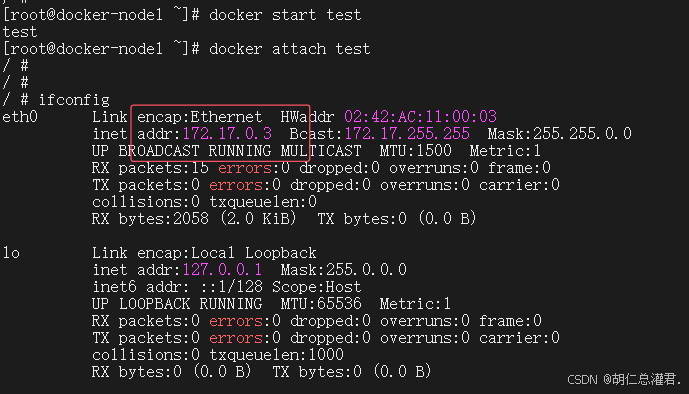
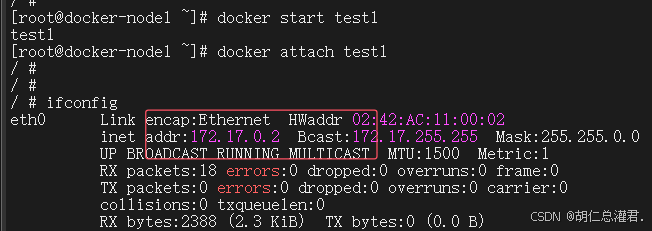
退出重进容器ip地址互换,对用户访问造成影响,所以一般使用容器名进行通信,但是原生bridge没有dns解析。
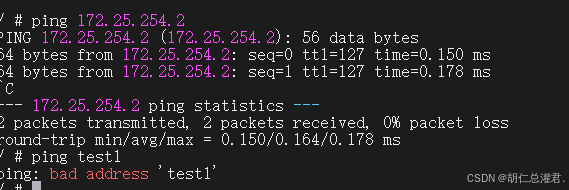
[root@docker-node1 ~]# docker network create mynet -d bridge
[root@docker-node1 ~]# docker run -it --name test --network mynet busybox
[root@docker-node1 ~]# docker run -it --name test --network mynet busybox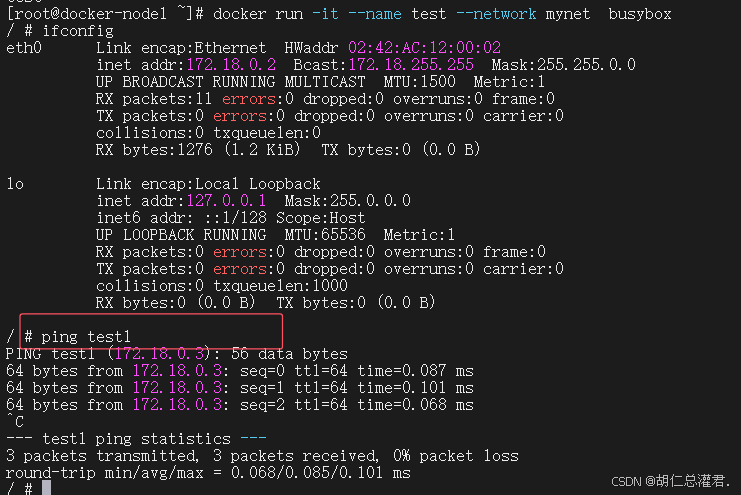
docker引擎在分配ip时时根据容器启动顺序分配到,谁先启动谁用,是动态变更的 多容器互访用ip很显然不是很靠谱,那么多容器访问一般使用容器的名字访问更加稳定 docker原生网络是不支持dns解析的,自定义网络中内嵌了dns。
2、不同自定义网络通信
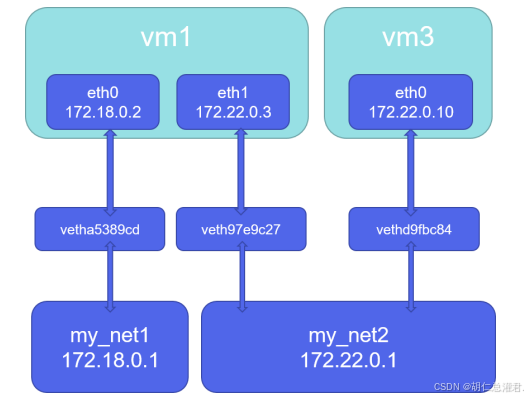
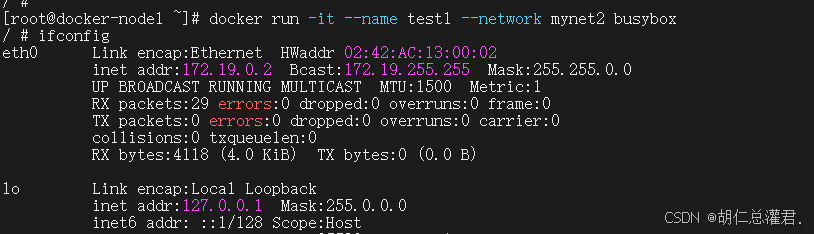
[root@docker-node1 ~]# docker network create mynet1 -d bridge
[root@docker-node1 ~]# docker network create mynet2 -d bridge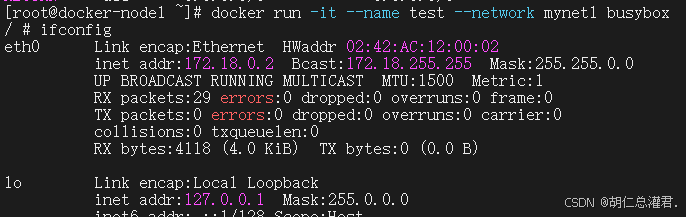
[root@docker-node1 ~]# docker network connect mynet1 test1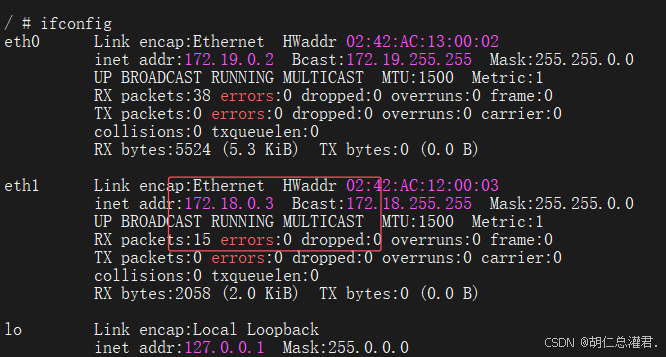
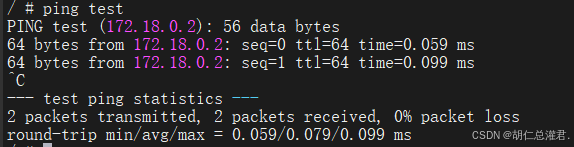
3、joined容器网络
[root@docker-node1 ~]# docker run -it --name test --network mynet1 busybox
[root@docker-node1 ~]# docker run -it --name test1 --network container:test busybox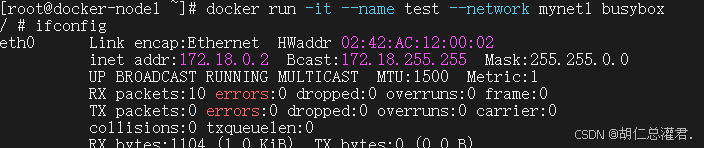

[root@docker-node1 ~]# docker run -d --name test --network mynet1 nginx
[root@docker-node1 ~]# docker run -it --name test1 --network container:test centos:7
[root@fe0a5b7bacba /]# curl localhost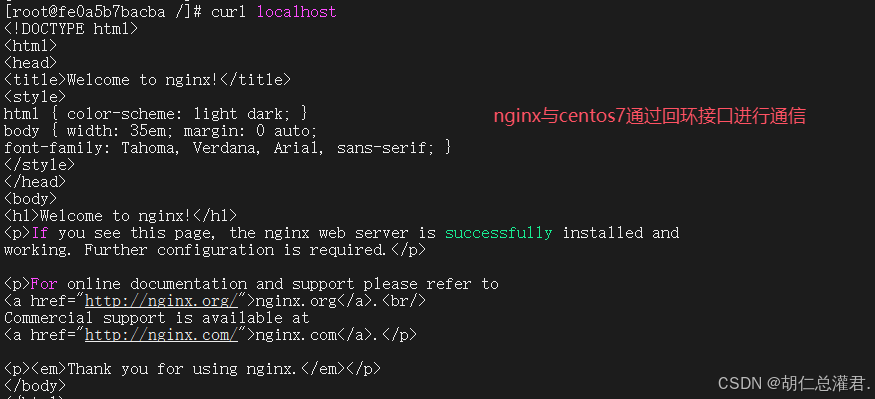
利用容器部署phpmyadmin管理mysql
运行phpmysqladmin和数据库
[root@docker-node1 ~]# docker run -d --name mysqladmin --network mynet1 \
> -e PMA_ARBITRARY=1 \ #在web页面中可以手动输入数据库地址和端口
> -p 80:80 phpmyadmin:latest
[root@docker-node1 ~]# docker run -d --name mysql \
> -e MYSQL_ROOT_PASSWORD=^C
[root@docker-node1 ~]# docker run -d --name mysql --network container:mysqladmin \ #把数据库容器添加到phpmyadmin容器中
> -e MYSQL_ROOT_PASSWORD='leo' \ #设定数据库密码
> mysql:5.7
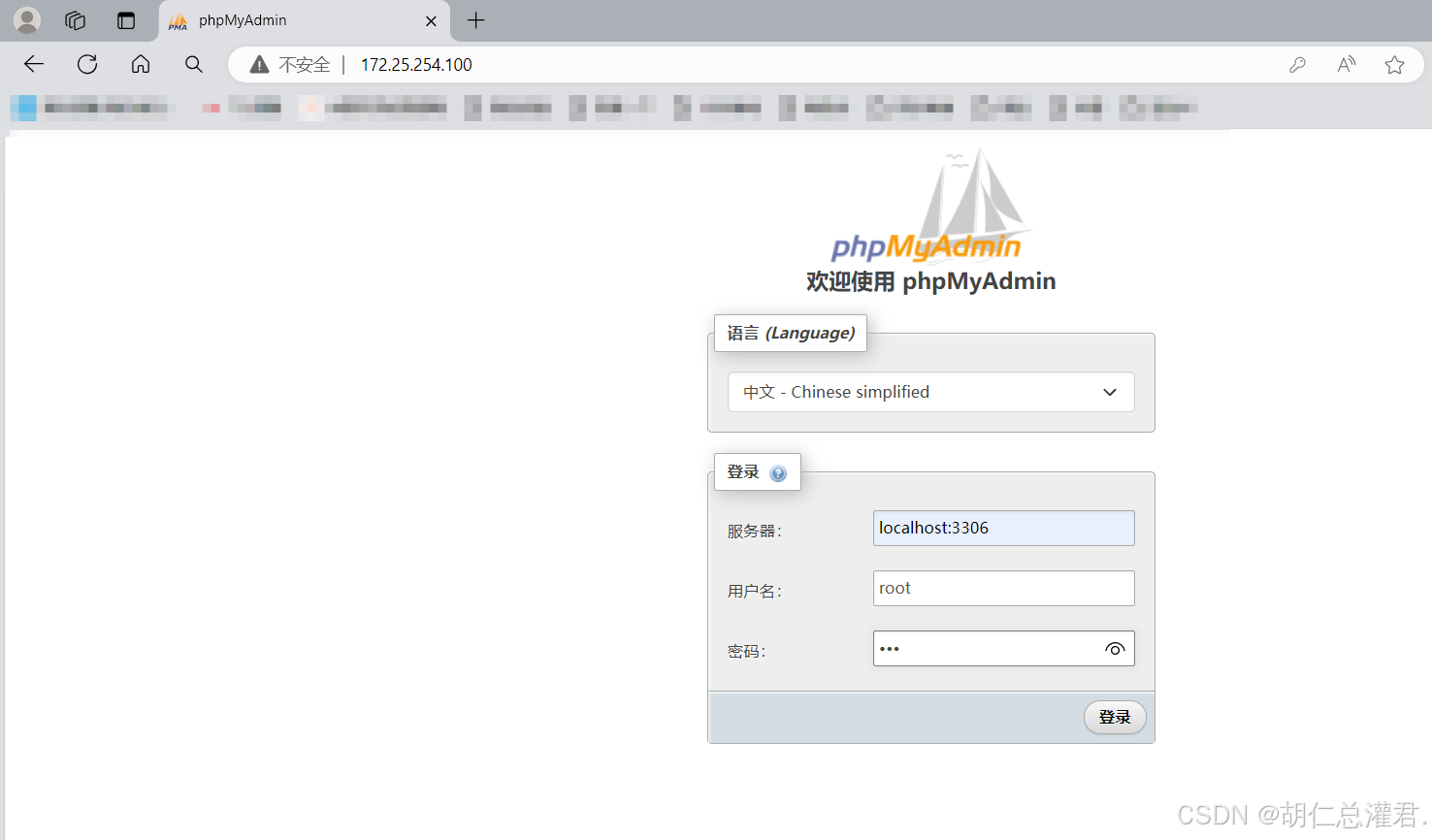
[root@docker-node1 ~]# docker exec -it mysql bash
bash-4.2# mysql -uroot -p123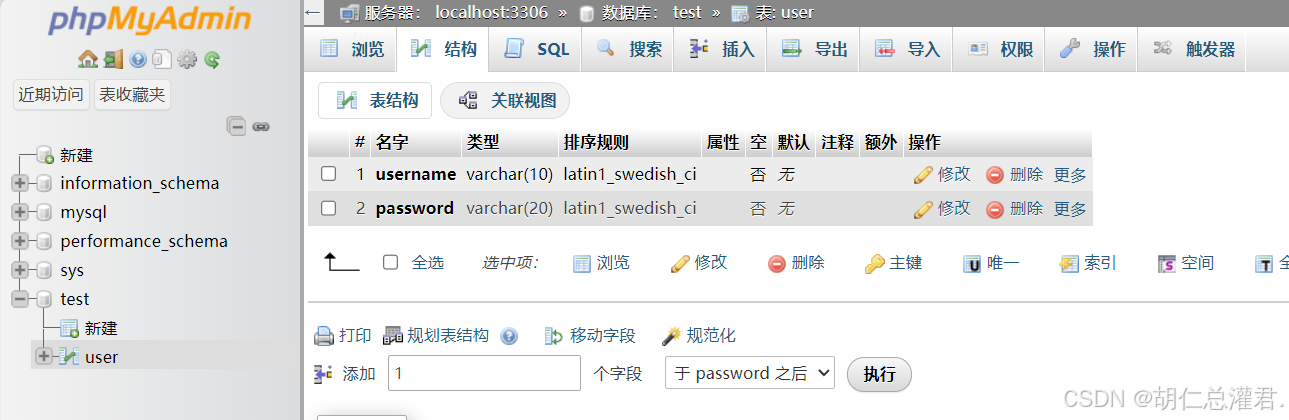
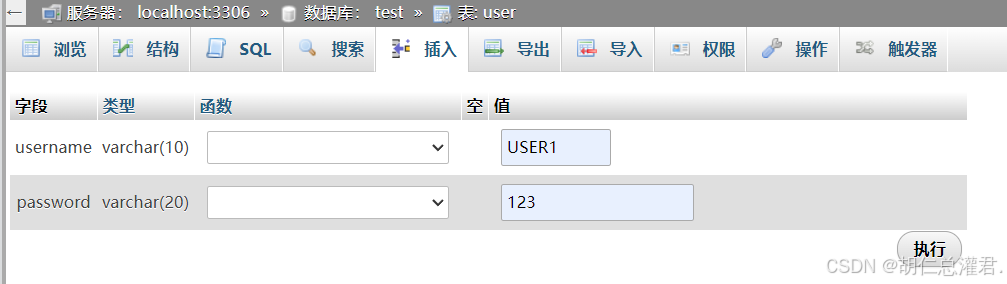
5、Docker容器内外网访问
1、容器访问外网
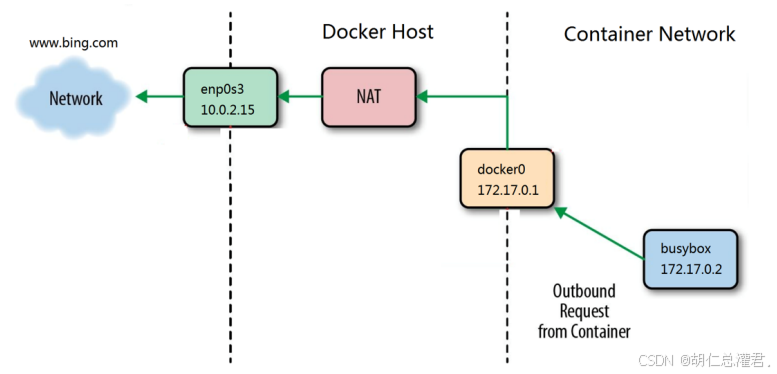
在rhel7中,docker访问外网是通过iptables添加地址伪装策略来完成容器网文外网
在rhel7之后的版本中通过nftables添加地址伪装来访问外网
2、外网访问容器
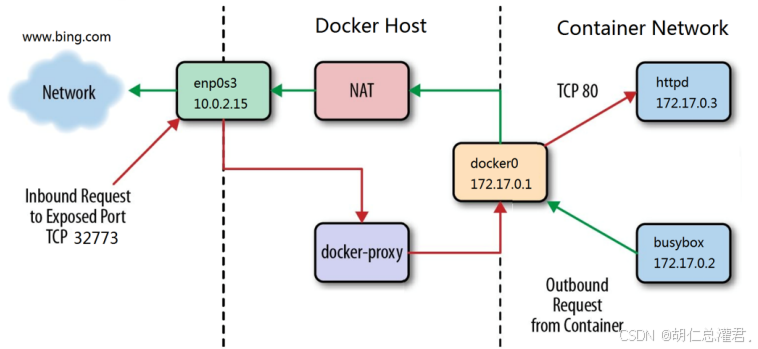
端口映射 -p 本机端口:容器端口来暴漏端口从而达到访问效果
#通过docker-proxy对数据包进行内转
[root@docker-node1 ~]# docker run -d --name test --rm -p 80:80 nginx
[root@docker-node1 ~]# iptables -t nat -nL
#通过dnat策略来完成浏览内转
Docker 会在 iptables 的 NAT 表中添加一条 DNAT(目的网络地址转换)策略。当外网的请求到达宿主机,目的端口为 80 时,这条策略会将请求的目的 IP 和端口转换为容器的 IP(172.17.0.2)和相应端口(80),从而将外网请求转发到对应的容器内的 Nginx 服务。这样就实现了外网对容器的访问,通过这种网络地址转换机制,在不暴露容器内部网络结构的情况下,使得外部网络能够与容器内的服务进行通信。[root@docker-node1 ~]# iptables -t nat -D DOCKER 2
[root@docker-node1 ~]# iptables -t nat -nL
[root@docker-node1 ~]# curl 172.25.254.100
#删除dnat策略后依旧能访问/usr/bin/docker-proxy与 iptables 的 DNAT 策略在实现外网访问容器方面有不同的作用机制: 一、docker-proxy的作用 /usr/bin/docker-proxy是 Docker 自身提供的一种代理机制。当容器启动并进行端口映射时,Docker 会启动相应的代理进程。例如,当执行 “docker run -d -p 80:80 nginx” 时,Docker 可能会启动一个代理进程来处理宿主机 80 端口的请求,并将这些请求转发到容器内的 80 端口。它直接在应用层进行请求的转发,监听宿主机指定的端口,接收来自外网的请求,并将请求转发给对应的容器。 二、DNAT 策略的作用 iptables 的 DNAT(目的网络地址转换)策略则是在网络层进行操作。当外网请求到达宿主机时,DNAT 策略根据规则将请求的目的 IP 和端口转换为容器的 IP 和端口。这样,请求就被引导到了容器所在的网络地址。 两者关系及优势 这两种方式共同为外网访问容器提供了保障,形成一种类似 “双保险” 的机制。一方面,DNAT 策略在网络层快速地将请求引导到正确的方向;另一方面,docker-proxy在应用层提供了更灵活的请求转发和管理功能。如果 DNAT 策略出现问题或被意外删除,docker-proxy可能仍然能够维持一定程度的外网对容器的访问,确保服务的连续性。同时,它们相互配合可以更好地适应不同的网络环境和需求,为容器的网络通信提供更稳定和可靠的解决方案。
6、macvlan网络实现跨主机通信
macvlan网络方式 Linux kernel提供的一种网卡虚拟化技术。 无需Linux bridge,直接使用物理接口,性能极好 容器的接口直接与主机网卡连接,无需NAT或端口映射。macvlan会独占主机网卡,但可以使用vlan子接口实现多macvlan网络 vlan可以将物理二层网络划分为4094个逻辑网络,彼此隔离,vlan id取值为1~4094
macvlan网络间的隔离和连通 macvlan网络在二层上是隔离的,所以不同macvlan网络的容器是不能通信的 可以在三层上通过网关将macvlan网络连通起来 docker本身不做任何限制,像传统vlan网络那样管理即可
macvlan网络实现跨主机通信
实验环境:两台双网卡docker主机
实验配置
[root@docker-node1 & 2 ~]# ip linke set eth1 promisc on
[root@docker-node1 & 2 ~]# ip link set up eth1
[root@docker-node1 & 2 ~]# docker network create \
> -d macvlan \
> --subnet 4.4.4.0/24 \
> --gateway 4.4.4.4 \
> -o parent=eth1 macvlan1测试
[root@docker-node1 ~]# docker run -it --name busybox --network macvlan1 --rm busybox
/ # ping 4.4.4.2
PING 4.4.4.2 (4.4.4.2): 56 data bytes
64 bytes from 4.4.4.2: seq=0 ttl=64 time=0.392 ms
64 bytes from 4.4.4.2: seq=1 ttl=64 time=0.263 ms
[root@docker-node2 ~]# docker run -it --name busybox --network macvlan1 --ip 4.4.4.2 --rm busybox
/ # ping 4.4.4.1
PING 4.4.4.1 (4.4.4.1): 56 data bytes
64 bytes from 4.4.4.1: seq=0 ttl=64 time=0.536 ms
64 bytes from 4.4.4.1: seq=1 ttl=64 time=0.298 ms二、Docker数据卷管理
Docker 数据卷是一个可供容器使用的特殊目录,它绕过了容器的文件系统,直接将数据存储在宿主机 上。
这样可以实现以下几个重要的目的: 数据持久化:即使容器被删除或重新创建,数据卷中的数据仍然存在,不会丢失。 数据共享:多个容器可以同时挂载同一个数据卷,实现数据的共享和交互。 独立于容器生命周期:数据卷的生命周期独立于容器,不受容器的启动、停止和删除的影响。
docker分层文件系统 性能差 生命周期与容器相同 docker数据卷 mount到主机中,绕开分层文件系统 和主机磁盘性能相同,容器删除后依然保留 仅限本地磁盘,不能随容器迁移 docker提供了两种卷: bind mount 和 docker managed volume
1、bind mount数据卷
是将主机上的目录或文件mount到容器里。 使用直观高效,易于理解。 使用 -v 选项指定路径,格式 :-v选项指定的路径,如果不存在,挂载时会自动创建
[root@docker-node1 ~]# mkdir /leo
[root@docker-node1 ~]# docker run -it --rm --name test -v /leo:/data1:rw -v /etc/passwd:/data2/passwd:ro busybox
#默认权限为读写2、docker managed数据卷
bind mount必须指定host文件系统路径,限制了移植性 docker managed volume 不需要指定mount源,docker自动为容器创建数据卷目录 默认创建的数据卷目录都在 /var/lib/docker/volumes 中 如果挂载时指向容器内已有的目录,原有数据会被复制到volume中
[root@docker-node1 ~]# docker run -d --rm --name mysql -e MYSQL_ROOT_PASSWORD='leo' mysql:5.7
[root@docker-node1 ~]# docker inspect mysql
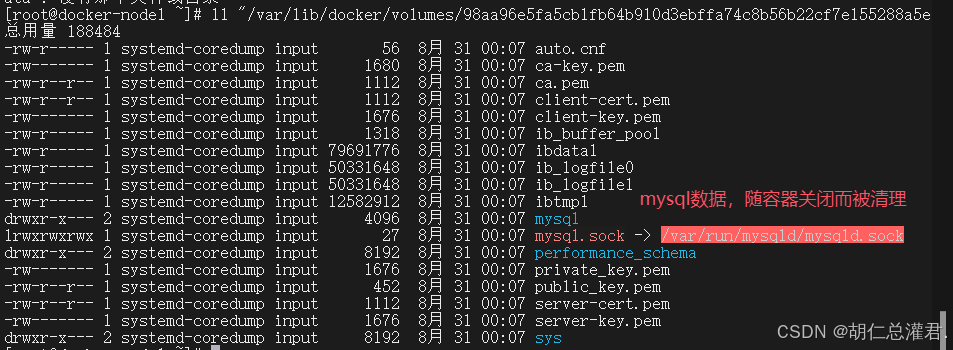
[root@docker ~]# docker volume prune #清理未使用的 Docker 数据卷
[root@docker-node1 ~]# docker volume create mysqldata
[root@docker-node1 ~]# docker run -d --rm --name mysql -e MYSQL_ROOT_PASSWORD='leo' -v mysqldata:/var/lib/mysql mysql:5.7

mysql数据持久化保存
三、Docker安全优化
Docker容器的安全性,很大程度上依赖于Linux系统自身 评估Docker的安全性时,主要考虑以下几个方面: Linux内核的命名空间机制提供的容器隔离安全 Linux控制组机制对容器资源的控制能力安全。 Linux内核的能力机制所带来的操作权限安全 Docker程序(特别是服务端)本身的抗攻击性。 其他安全增强机制对容器安全性的影响。
#在rhel9中默认使用cgroup-v2 但是cgroup-v2中不利于观察docker的资源限制情况,所以推荐使用
cgroup-v1
[root@docker ~]# grubby --update-kernel=/boot/vmlinuz-$(uname -r) \
--args="systemd.unified_cgroup_hierarchy=0
systemd.legacy_systemd_cgroup_controller"
[root@docker-node1 ~]# mount -t cgroup2
#回车后无提示证明使用的cgroup1命名空间隔离的安全
当docker run启动一个容器时,Docker将在后台为容器创建一个独立的命名空间。命名空间提供了 最基础也最直接的隔离。
与虚拟机方式相比,通过Linux namespace来实现的隔离不是那么彻底。
容器只是运行在宿主机上的一种特殊的进程,那么多个容器之间使用的就还是同一个宿主机的操作 系统内核。
在 Linux 内核中,有很多资源和对象是不能被 Namespace 化的,比如:磁盘等等
[root@docker-node1 ~]# docker run -d --name web nginx
3c2fac6e177ae1b369378c5ef5bd373b9520f98b497d15ab00c6b76a322ef531
[root@docker-node1 ~]# docker inspect web | grep Pid
"Pid": 9608,
"PidMode": "",
"PidsLimit": null,
[root@docker-node1 ~]# cd /proc/9608/ns/
[root@docker-node1 ns]# ls
cgroup ipc mnt net pid pid_for_children time time_for_children user uts
[root@docker-node1 ns]# ls -d /sys/fs/cgroup/memory/docker/3c2fac6e177ae1b369378c5ef5bd373b9520f98b497d15ab00c6b76a322ef531/
/sys/fs/cgroup/memory/docker/3c2fac6e177ae1b369378c5ef5bd373b9520f98b497d15ab00c6b76a322ef531/
#资源隔离信息1、限制CPU使用
[root@docker-node1 ~]# cat /sys/fs/cgroup/cpu/docker/tasks
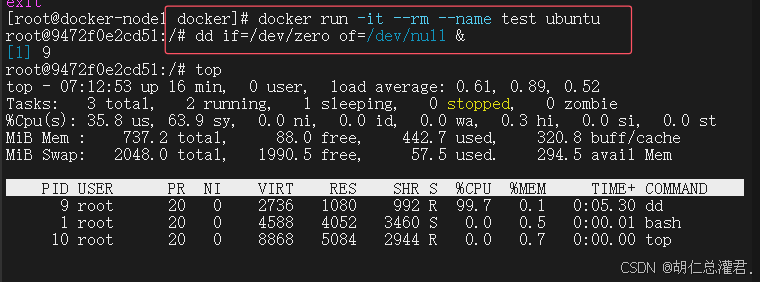
[root@docker-node1 docker]# docker run -it --rm --name test --cpu-period 100000 --cpu-quota 20000 ubuntu
root@a96a802a251f:/# dd if=/dev/zero of=/dev/null &
[root@docker-node1 ~]# docker run -it --rm --name test1 ubuntu
root@3cef28365cd1:/# dd if=/dev/zero of=/dev/null &
cpu最大使用量
限制cpu优先级
[root@docker-node1 docker]# cat cpu.shares
1024
#默认cpu优先级为1024,最高位1024
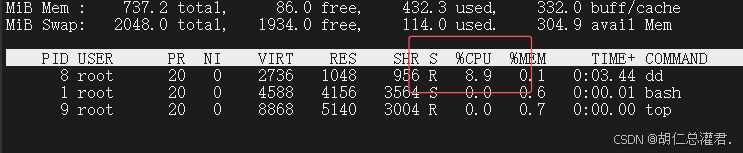
[root@docker-node1 docker]# docker run -it --rm --cpu-shares 1000 ubuntu
root@ef61e9e2c3a6:/# dd if=/dev/zero of=/dev/null &
[root@docker-node1 ~]# docker run -it --rm --cpu-shares 100 ubuntu
root@765826e7735c:/# dd if=/dev/zero of=/dev/null &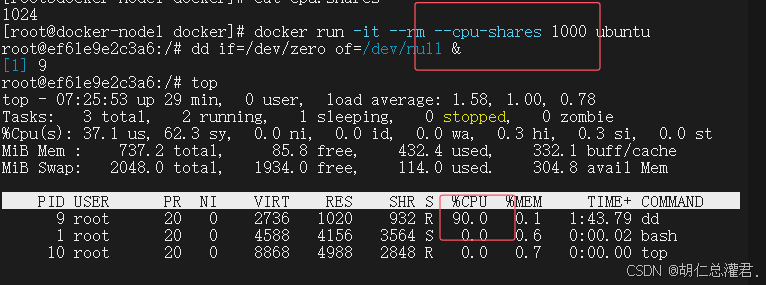
2、限制内存使用
[root@docker-node1 d2ceb9330f2baa98846622c43f0a9c1f66ea6edd7ae16610e5318d74312a19c8]# cat memory.limit_in_bytes
209715200
[root@docker-node1 cgroup]# cgexec -g memory:docker/e7207c5943ab54c2acd74672cb9cd7b7ca46057a62919e763f25fa5f3fcc3564 dd if=/dev/zero of=/dev/shm/tsetfile bs=1M count=100
[root@docker-node1 cgroup]# cgexec -g memory:docker/e7207c5943ab54c2acd74672cb9cd7b7ca46057a62919e763f25fa5f3fcc3564 dd if=/dev/zero of=/dev/shm/tsetfile bs=1M count=194
记录了194+0 的读入
记录了194+0 的写出
203423744字节(203 MB,194 MiB)已复制,0.0437973 s,4.6 GB/s
[root@docker-node1 cgroup]# cgexec -g memory:docker/e7207c5943ab54c2acd74672cb9cd7b7ca46057a62919e763f25fa5f3fcc3564 dd if=/dev/zero of=/dev/shm/tsetfile bs=1M count=200
已杀死
3、限制docker的磁盘io
[root@docker-node1 ~]# docker run -it --rm --device-write-bps /dev/nvme0n1:30M ubuntu
root@61b38c0f8462:/# dd if=/dev/zero of=bigfile bs=1M count=500 #开启容器后会发现速度和设定不匹配,是因为系统的缓存机制
root@61b38c0f8462:/# dd if=/dev/zero of=bigfile bs=1M count=500 oflag=direct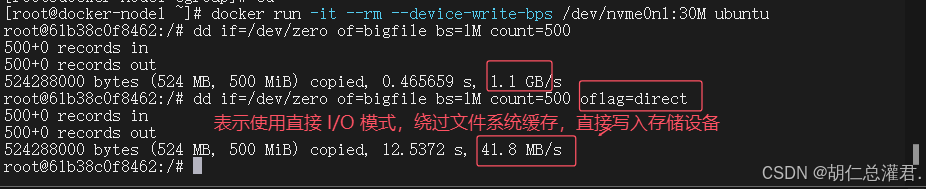
4、解决docker默认隔离性
LXCFS 是一个为 LXC(Linux Containers)容器提供增强文件系统功能的工具。
主要功能
-
资源可见性: LXCFS 可以使容器内的进程看到准确的 CPU、内存和磁盘 I/O 等资源使用信息。在没有 LXCFS 时,容器内看到的资源信息可能不准确,这会影响到在容器内运行的应用程序对资源的评估和 管理。
-
性能监控: 方便对容器内的资源使用情况进行监控和性能分析。通过提供准确的资源信息,管理员和开发 人员可以更好地了解容器化应用的性能瓶颈,并进行相应的优化。
#在rhel9中lxcfs是被包含在epel源中,可以直接下载安装包进行安装
[root@docker ~]# ls lxcfs
lxcfs-5.0.4-1.el9.x86_64.rpm lxc-libs-4.0.12-1.el9.x86_64.rpm lxc-templates4.0.12-1.el9.x86_64.rpm
[root@docker~]# dnf install lxc*.rpm运行lxcfs并解决容器隔离性

[root@docker-node1 ~]# docker run -it --rm --name test -v /var/lib/lxcfs/proc/cpuinfo:/proc/cpuinfo:rw -v /var/lib/lxcfs/proc/diskstats:/proc/diskstats:rw -v /var/lib/lxcfs/proc/meminfo:/proc/meminfo:rw -v /var/lib/lxcfs/proc/stat:/proc/stat:rw -v /var/lib/lxcfs/proc/swaps:/proc/swaps:rw \
> -m 200M \
> ubuntu
root@3296a9544778:/# free -m
total used free shared buff/cache available
Mem: 200 1 190 0 7 198
Swap: 400 0 4005、docker容器特权
[root@docker-node1 ~]# docker run -it --rm --name test busybox
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
21: eth0@if22: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
/ # ip a a 1.1.1.1/24 dev eth0
ip: RTNETLINK answers: Operation not permitted
这是因为容器使用的很多资源都是和系统真实主机公用的,如果允许容器修改这些重要资源,系统的稳
定性会变的非常差
[root@docker-node1 ~]# docker run -it --rm --name test --privileged busybox
/ # ip a a 1.1.1.1/24 dev eth0
/ # ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
23: eth0@if24: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
inet 1.1.1.1/24 scope global eth0
valid_lft forever preferred_lft forever
/ # fdisk -l
Disk /dev/nvme0n1: 20 GB, 21474836480 bytes, 41943040 sectors
82241 cylinders, 255 heads, 2 sectors/track
Units: sectors of 1 * 512 = 512 bytes
#--privileged:使容器以特权模式运行。在特权模式下,容器几乎拥有与宿主机相同的权限,可以访问宿主机上的各种设备和资源
容器特权的白名单:
--privileged=true 的权限非常大,接近于宿主机的权限,为了防止用户的滥用,需要增加限制,只提供
给容器必须的权限。此时Docker 提供了权限白名单的机制,使用--cap-add添加必要的权限
[root@docker-node1 ~]# docker run --rm -it --name test --cap-add NET_ADMIN busybox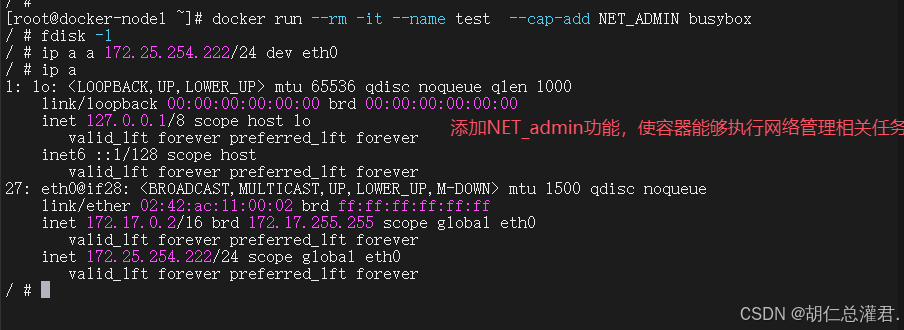
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Docker网络、数据卷及安全优化

发表评论 取消回复