点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
- Hadoop(已更完)
- HDFS(已更完)
- MapReduce(已更完)
- Hive(已更完)
- Flume(已更完)
- Sqoop(已更完)
- Zookeeper(已更完)
- HBase(已更完)
- Redis (已更完)
- Kafka(已更完)
- Spark(已更完)
- Flink(已更完)
- ClickHouse(已更完)
- Kudu(已更完)
- Druid(正在更新…)
章节内容
上节我们完成了如下的内容:
- Apache Druid 系统架构 核心组件介绍
- Druid 单机模式配置启动

整体介绍
Apache Druid 是一种高性能、分布式的列式存储数据库,专门用于实时分析和查询大规模数据集。它适用于 OLAP(在线分析处理)场景,尤其在处理大数据实时流时表现优异。Druid 的架构由多个组件组成,主要包括数据摄取、存储、查询和管理。
在集群配置方面,Druid 通常由以下节点构成:
- 数据摄取层:使用 MiddleManager 节点来处理数据的实时摄取,负责从不同数据源(如 Kafka、HDFS 等)读取数据并进行实时处理。
- 存储层:数据存储在 Historical 节点上,这些节点负责存储和管理较老的数据,支持高效的查询。数据被以列式格式存储,优化了查询性能。
- 查询层:Broker 节点充当查询路由器,接受用户的查询请求并将其分发到相应的 Historical 或 Real-time 节点,然后将结果汇总返回给用户。
- 协调层:Coordinator 节点负责集群的状态管理和数据分配,确保数据均匀分布并自动处理节点故障。
Druid 的配置文件允许用户自定义参数,如 JVM 设置、内存分配和数据分片策略,以便根据不同的工作负载和性能需求进行优化。此外,Druid 还支持多种查询语言,包括 SQL,便于用户进行灵活的数据分析。整体上,Druid 提供了一种高效、可扩展的解决方案,适合需要快速实时分析的大数据应用场景。
修改配置【续接上篇】
historical
参数大小根据实际情况调整
vim $DRUID_HOME/conf/druid/cluster/data/historical/jvm.config
原配置内容如下所示:
-server
-Xms8g
-Xmx8g
-XX:MaxDirectMemorySize=13g
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改内容如下:
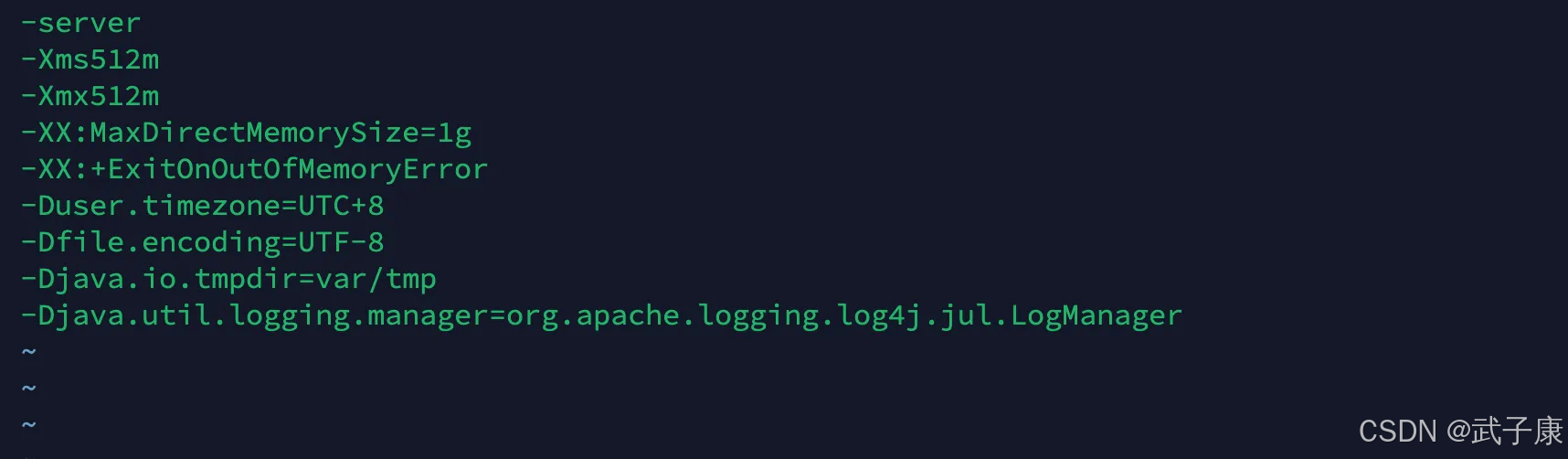
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=1g
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改结果如下图:
此外还有一个参数:
vim $DRUID_HOME/conf/druid/cluster/data/historical/runtime.properties
原配置内容如下:
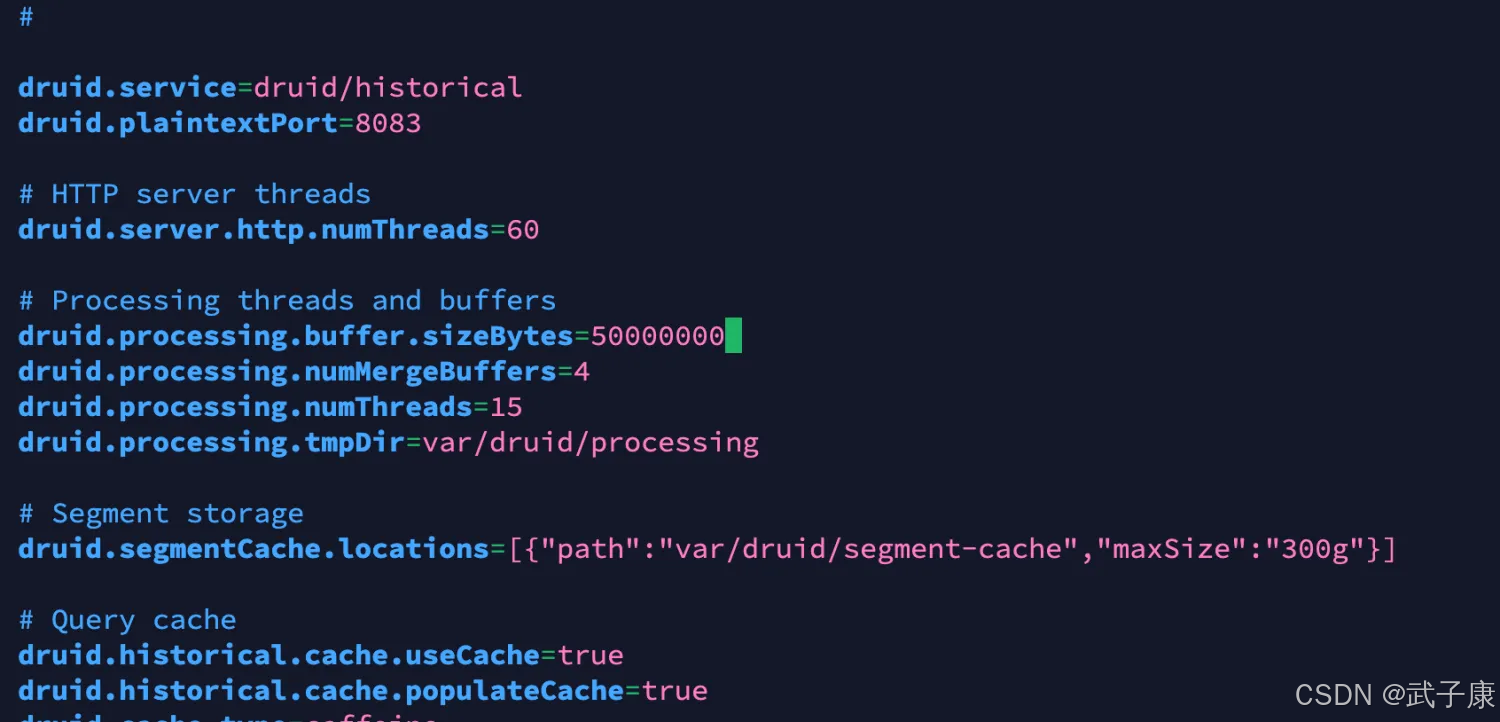
druid.processing.buffer.sizeBytes=500MiB
修改为如下内容:
# 相当于 50MiB
druid.processing.buffer.sizeBytes=50000000
修改的截图如下:
备注:
- druid.processing.buffer.sizeBytes 每个查询用于聚合的对外哈希表的大小
- maxDirectMemory = druid.processing.buffer.sizeBytes * (durid.processing.numMergeBuffers + druid.processing.numThreads + 1)
- 如果 druid.processing.buffer.sizeBytes太大的话,需要加大 maxDirectMemory,否则 historical服务无法启动
broker
vim $DRUID_HOME/conf/druid/cluster/query/broker/jvm.config
原配置如下:
-server
-Xms12g
-Xmx12g
-XX:MaxDirectMemorySize=6g
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改配置如下:
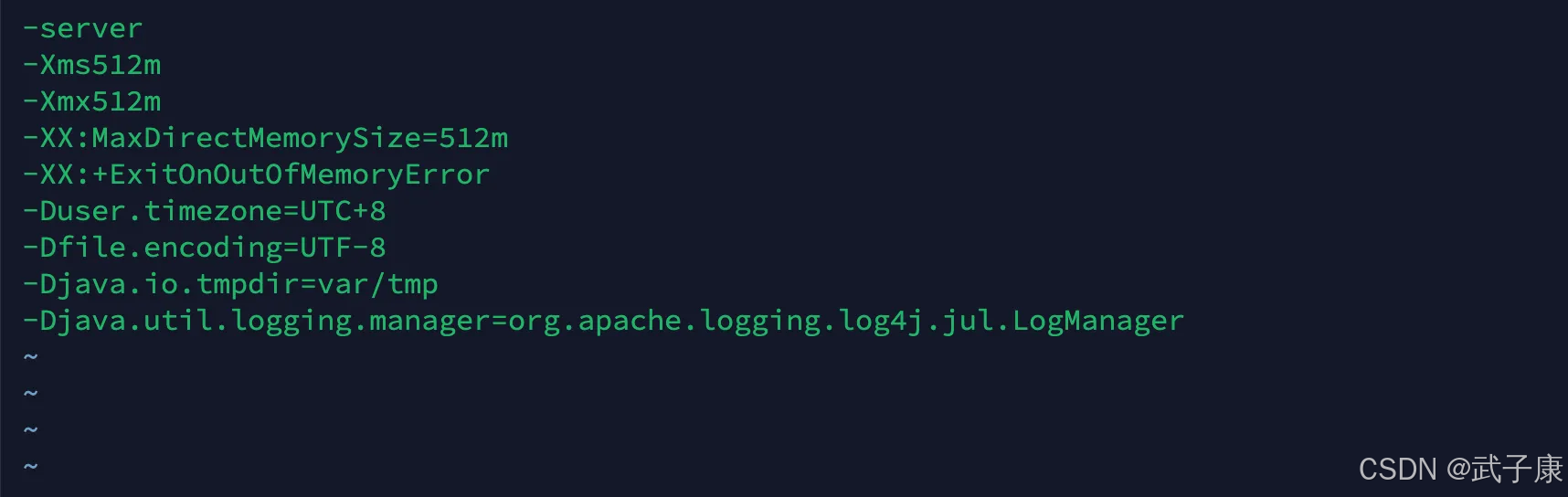
-server
-Xms512m
-Xmx512m
-XX:MaxDirectMemorySize=512m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改截图如下图:
此外还需要修改额外的参数:
vim $DRUID_HOME/conf/druid/cluster/query/broker/runtime.properties
原参数为:
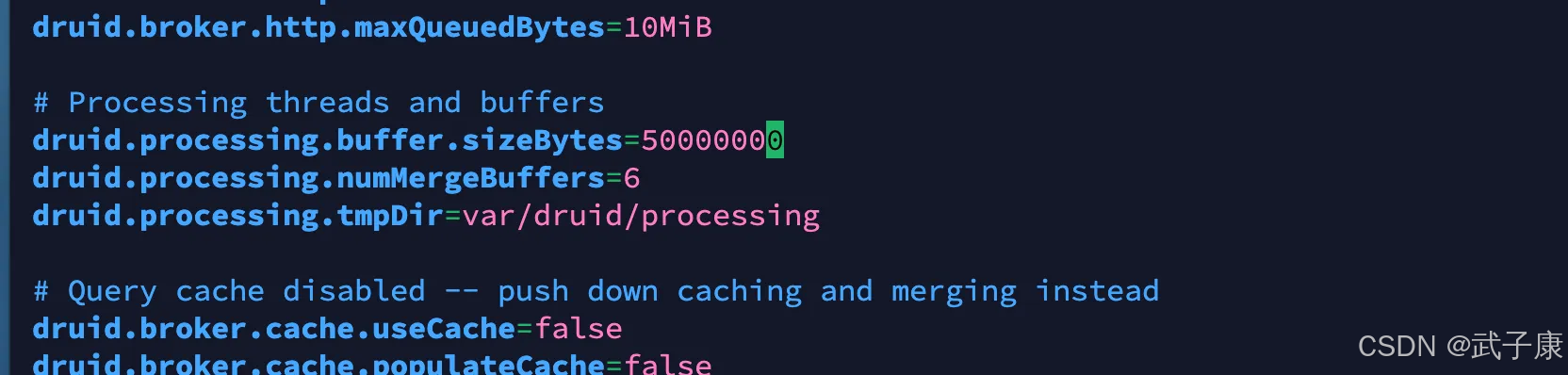
druid.processing.buffer.sizeBytes=500MiB
修改为:
# 与刚才修改的一样 大约是50MiB
druid.processing.buffer.sizeBytes=50000000
修改截图如下所示:
备注:
- druid.processing.buffer.sizeBytes 每个查询用于聚合的堆外哈希表的大小
- maxDirectMemory = druid.processing.buffer.sizeBytes*(druid.processing.numMergeBuffers + druid.processing.numThreads + 1)
- 如果 druid.processing.buffer.sizeBytes 太大,那么需要加大maxDirectMemory,否则 broker 服务无法启动
router
vim $DRUID_HOME/conf/druid/cluster/query/router/jvm.config
原配置如下:
-server
-Xms1g
-Xmx1g
-XX:+UseG1GC
-XX:MaxDirectMemorySize=128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改配置如下:
-server
-Xms128m
-Xmx128m
-XX:+UseG1GC
-XX:MaxDirectMemorySize=128m
-XX:+ExitOnOutOfMemoryError
-Duser.timezone=UTC+8
-Dfile.encoding=UTF-8
-Djava.io.tmpdir=var/tmp
-Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
修改截图如下:
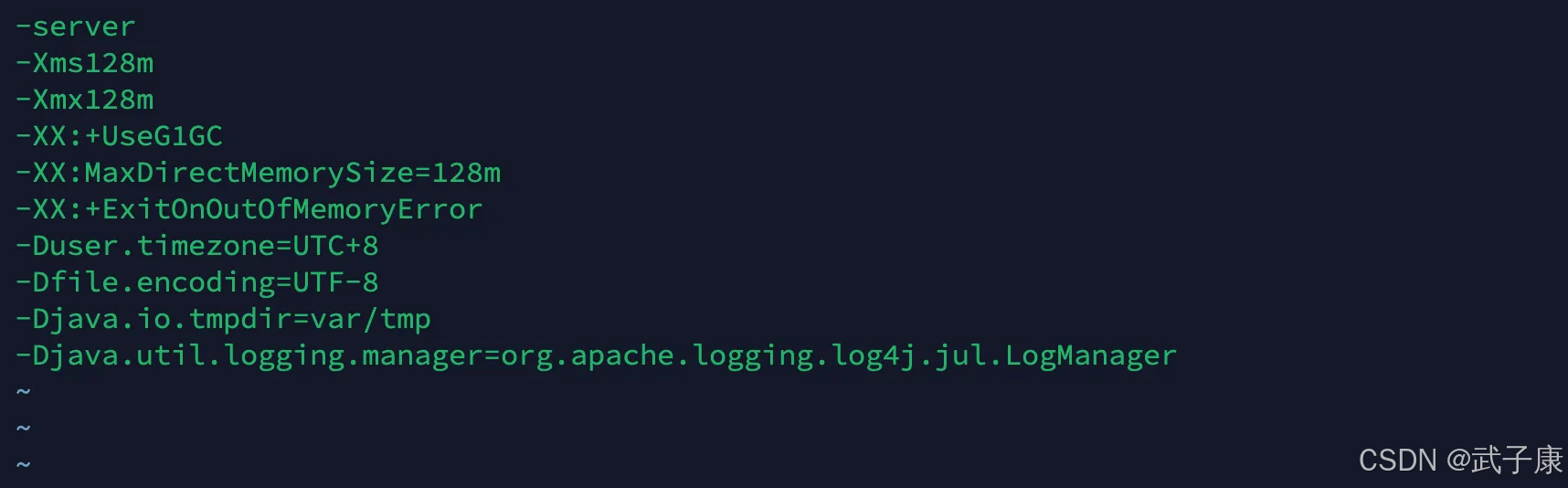
配置汇总
- coordinator-overlord:512M
- historical:512M,堆外1G
- middleManger:128M
- broker:512M、堆外512M
- router:128M,堆外128M
分发软件
你可以用的方式完成,我这里用之前写好的 rsync-script 工具进行分发,刚才我们配置都是在 h121 节点上完成的,所以接下来,我们从 h121 节点分发到 h122、h123
rsync-script apache-druid-30.0.0
运行结果如下图所示:
分发之后,要注意你需要修改的东西:
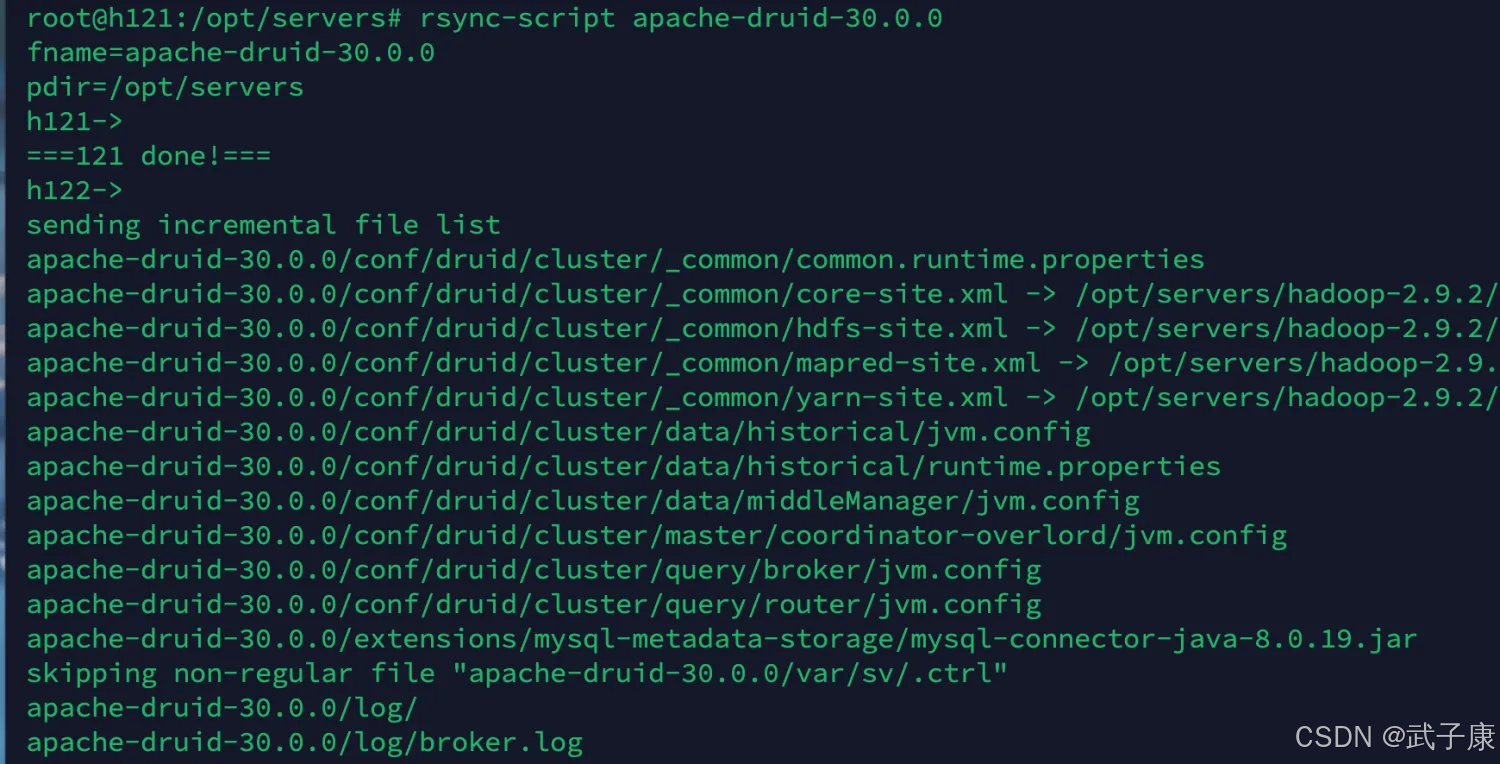
- common.runtime.properties中的 druid.host 为所在节点的IP
- h121 h122 h123 上都配置好环境、环境变量等内容
启动服务
ZK启动
在三台节点上都需要启动ZK,并且需要组成ZK集群。
这部分内容之前已经有 ZooKeeper集群环境搭建,且在多个环节中,如Kafka集群环节中已经测试过。
zkServer.sh start
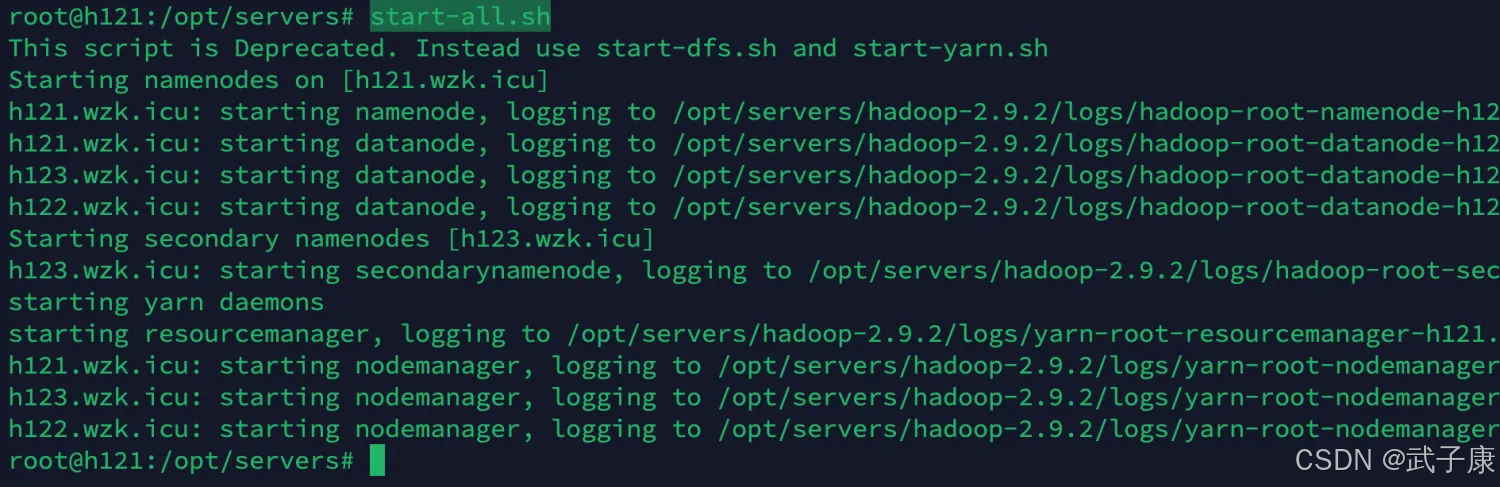
启动 Hadoop
start-all.sh
# 或者只启动 dfs也行
start-dfs.sh
执行结果如下图所示:
Druid启动
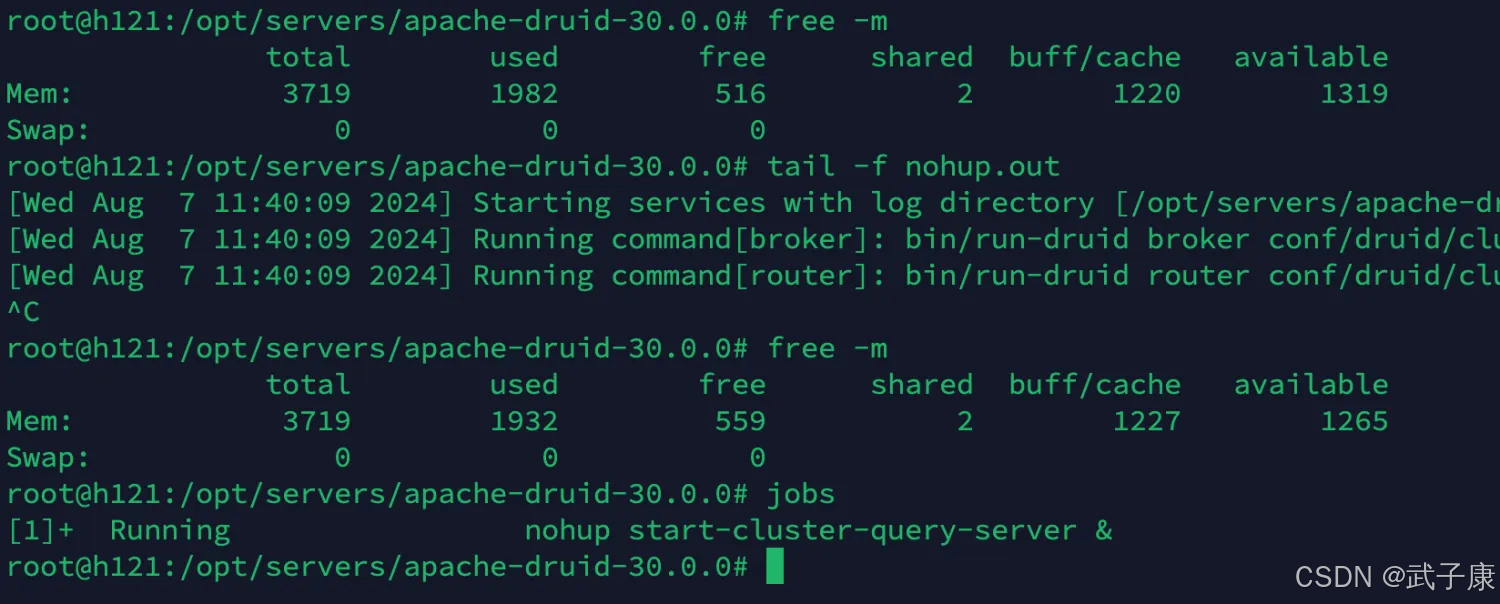
h121 查询节点
这里是查询节点
cd /opt/servers/apache-druid-30.0.0
nohup start-cluster-query-server &
运行结果如下图所示:
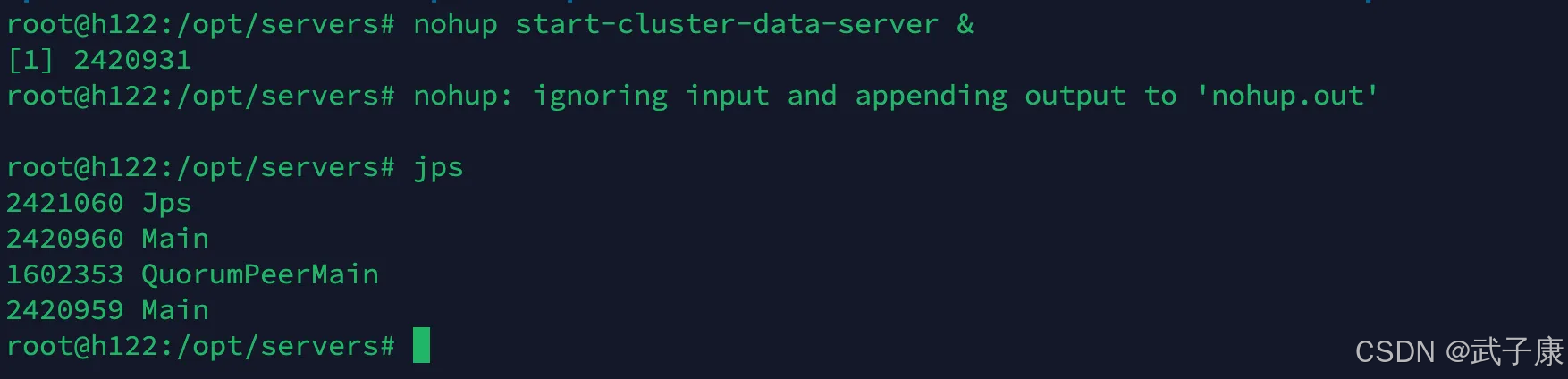
h122 数据节点
这里是数据节点
cd /opt/servers/apache-druid-30.0.0
nohup start-cluster-data-server &
运行结果如下图所示:
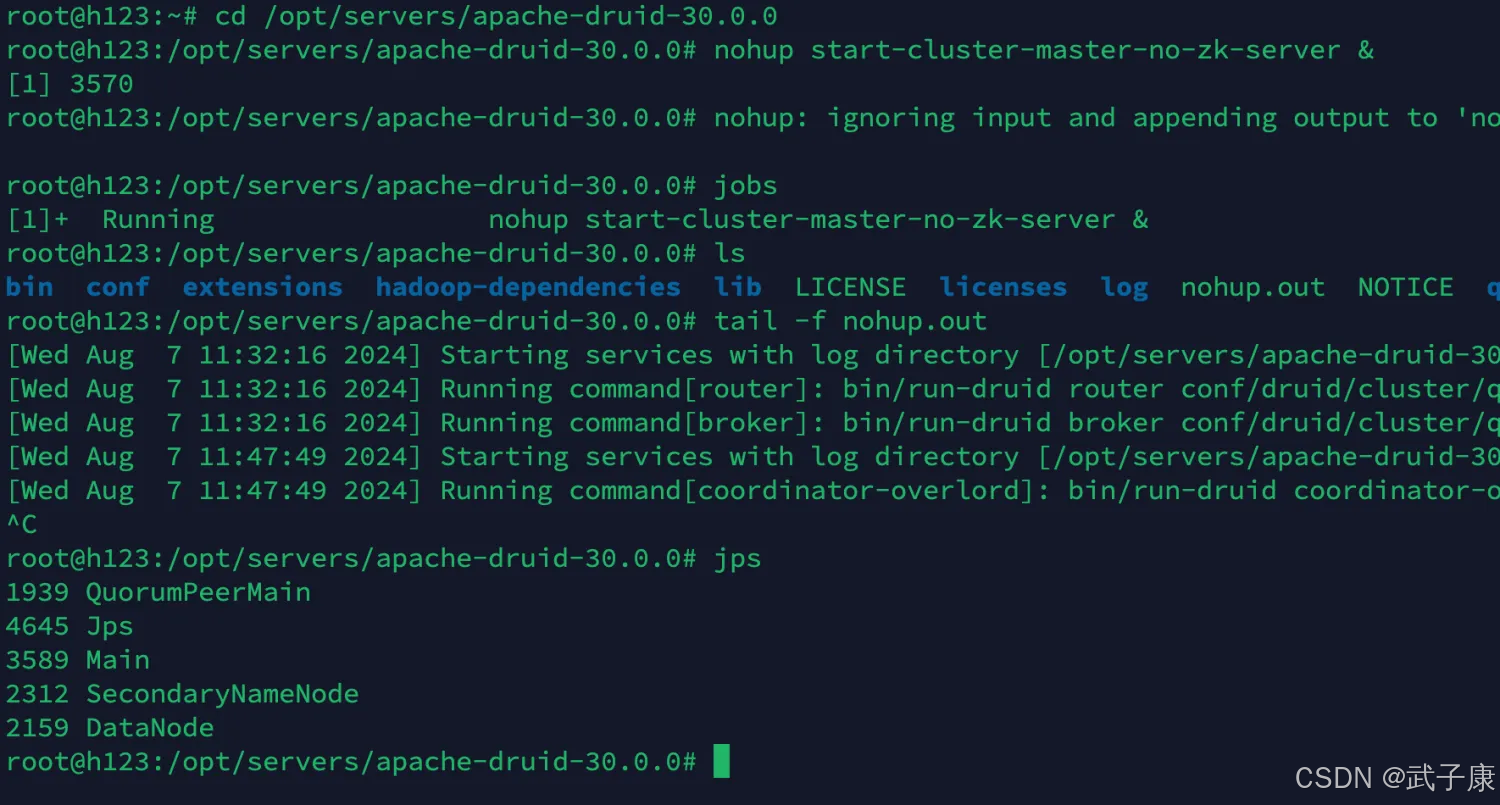
h123 主节点
这里是主节点
cd /opt/servers/apache-druid-30.0.0
nohup start-cluster-master-no-zk-server &
运行结果如下所示:
日志查看
可以在log下查看,我这里是查看了 nohup 的内容
h121

h122
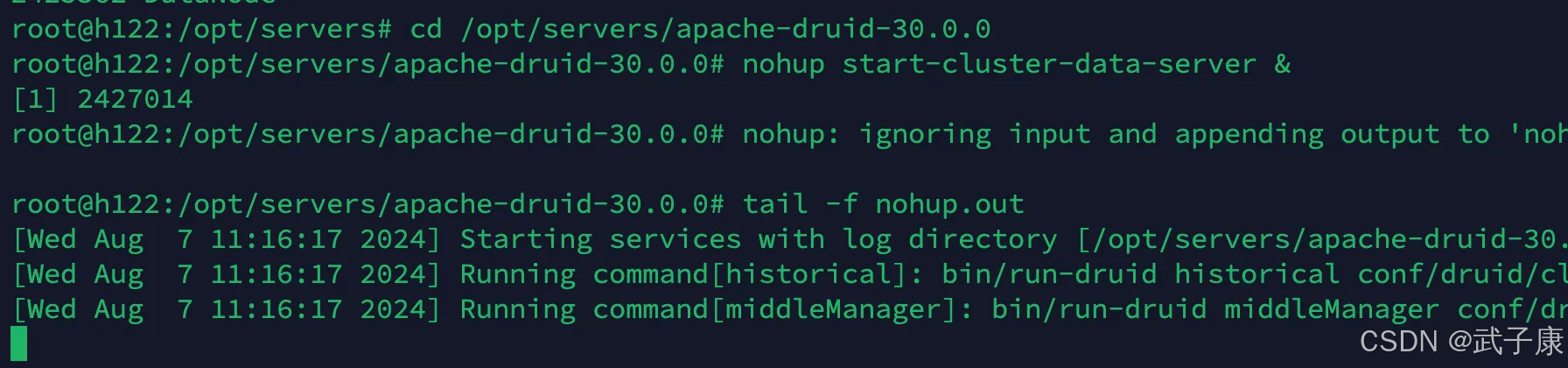
h123

停止服务
需要在每个节点都执行:
# 在各个节点运行
/opt/servers/apache-druid-30.0.0/bin/service --down
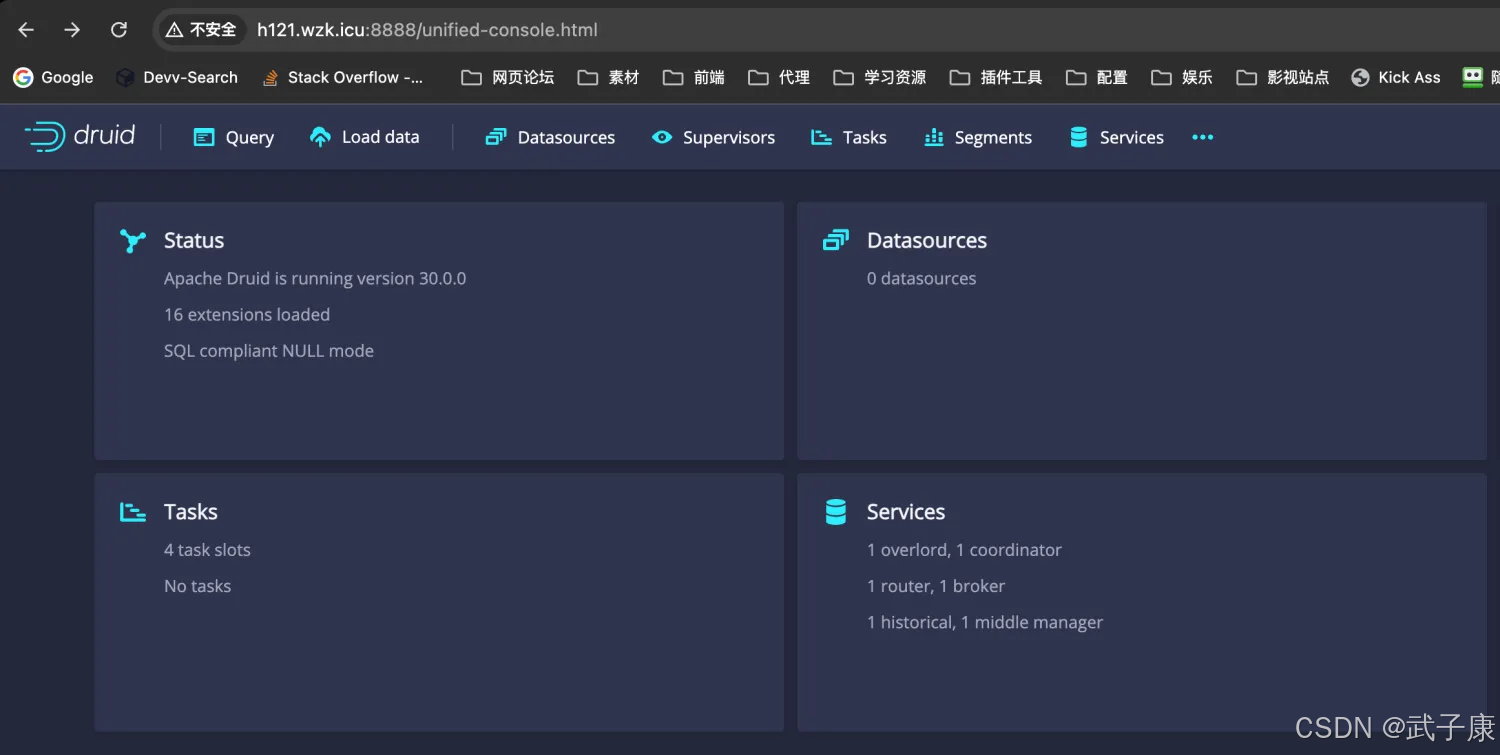
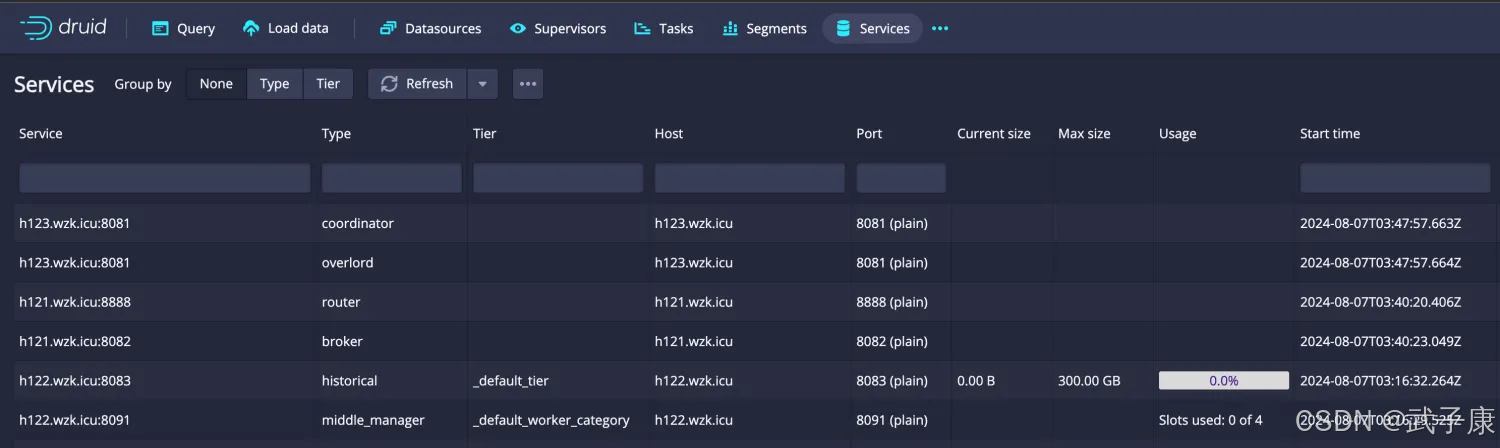
查看界面
http://h121.wzk.icu:8888
页面结果如下:
到此!顺利完成!一路艰难险阻!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大数据-152 Apache Druid 集群模式 配置启动【下篇】 超详细!

发表评论 取消回复