一·Spark
定义:Spark 是一个开源的分布式计算系统,它提供了一个快速且通用的集群计算平台。Spark 被设计用来处理大规模数据集,并且支持多种数据处理任务,包括批处理、交互式查询、机器学习、图形处理和流处理。
核心架构:
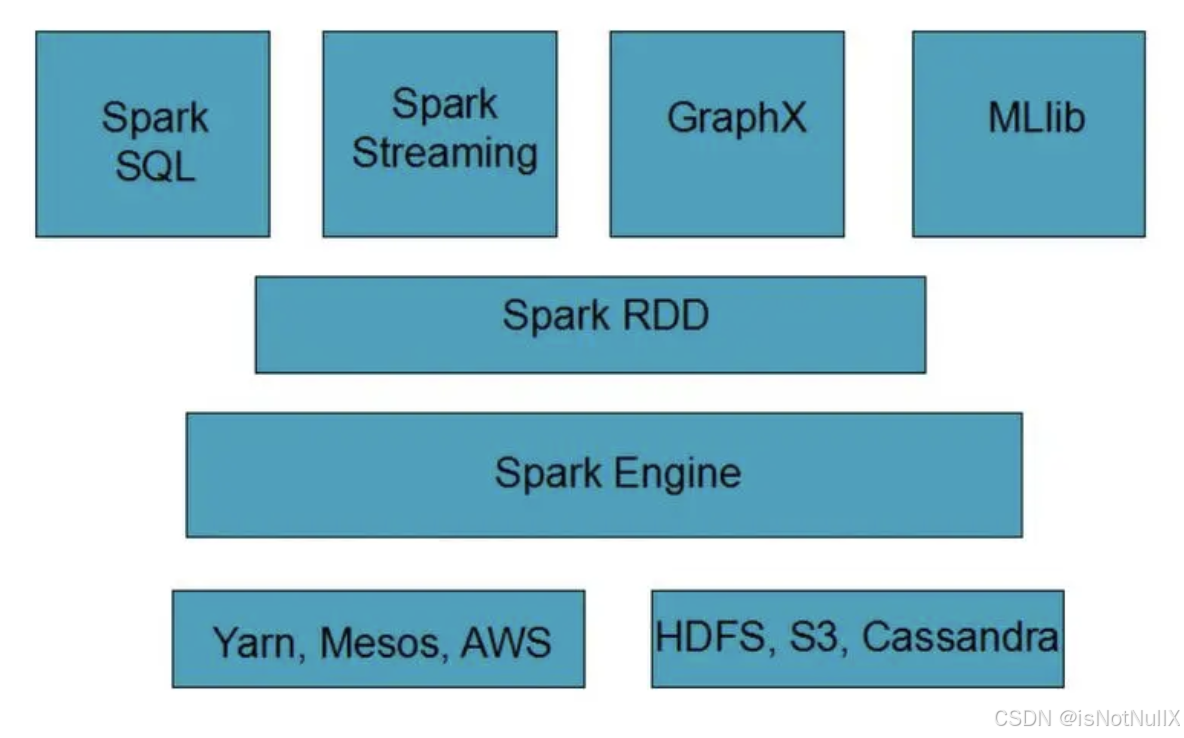
1.Spark Core:这是 Spark 的基础组件,提供了基本的数据结构和分布式计算的原语。它包括了 Spark 的核心功能,如任务调度、内存管理、错误恢复(通过血统机制)等。
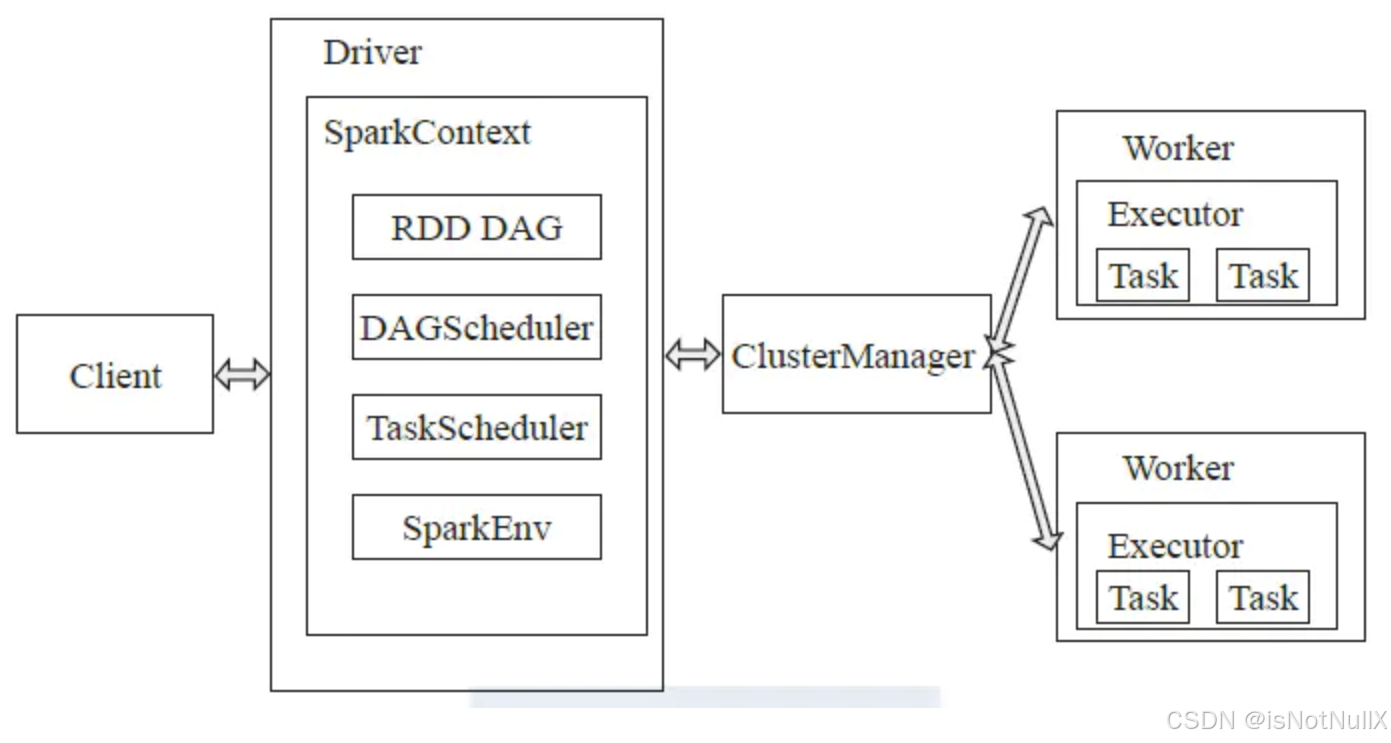
2. Spark Context:是用户与 Spark 交互的主要入口点。它负责初始化 Spark 应用程序,管理任务的调度和执行,以及与集群管理器的通信。
3. Cluster Manager:集群管理器负责在集群中的节点上分配资源。Spark 可以与多种集群管理器协同工作,包括 Hadoop YARN、Apache Mesos 和 Spark 自己的 Standalone 集群管理器。
4. Worker Node:工作节点是集群中的物理机或虚拟机,它们提供了执行计算任务所需的资源。
5. Executor:每个工作节点上运行一个或多个 Executor 进程,这些进程负责执行任务并缓存数据。
6. Task:任务是 Spark 中的最小执行单元,由 Executor 执行。一个作业(Job)会被拆分为多个阶段(Stage),每个阶段又包含多个任务。
7. DAG Scheduler:有向无环图(DAG)调度器负责将用户程序转换为一个由多个阶段组成的 DAG,然后根据依赖关系和集群资源情况将这些阶段拆分为任务。
8.RDD(Resilient Distributed Dataset):弹性分布式数据集是 Spark 中最基本的数据抽象,代表不可变、分区的、能够在计算节点之间进行并行操作的数据集合。
9.Spark SQL:用于结构化数据处理,提供了 SQL 接口和对多种数据源的支持。
10. MLlib:机器学习库,提供了多种机器学习算法和工具
11. GraphX:图计算库,用于处理图数据结构和进行并行图计算。
12.Spark Streaming:用于实时数据流处理,可以将数据流分割成一系列连续的批次,然后使用 Spark 进行处理。
spark优点:
1. 速度快:Spark 通过内存计算优化了数据处理速度,比传统的磁盘存储计算框架如 Hadoop MapReduce 快很多。
2. 易于使用:Spark 提供了丰富的 API,支持多种编程语言,如 Scala、Java、Python 和 R。
3. 通用性:Spark 支持多种数据处理任务,可以用于批处理、流处理、机器学习等。
4. 可扩展性:Spark 可以在多种集群管理器上运行,如 Hadoop YARN、Apache Mesos 和 Kubernetes。
5. 兼容性:Spark 可以与 Hadoop 生态系统中的其他工具集成,如 HDFS、HBase 和 Flume。
6. 高容错性:Spark 提供了容错机制,能够在节点故障时自动重新计算丢失的数据。
二·Spark streaming实时数据流处理
Spark用于数据流处理的功能十分强大,尤其是在数据同步功能上。
Spark Streaming 是 Spark 生态系统中用于处理实时数据流的一个重要组件。它将输入数据分成小批次(micro-batch),然后利用 Spark 的批处理引擎进行处理,从而结合了批处理和流处理的优点。这种处理方式使得 Spark Streaming 既能够保持高吞吐量,又能够处理实时数据流。
特点:
1.实时数据处理:能够处理实时产生的数据流,如日志数据、传感器数据、社交媒体更新等 。
2.微批次处理:将实时数据切分成小批次,每个批次的数据都可以使用 Spark 的批处理操作进行处理。
3.容错性:提供容错性,保证在节点故障时不会丢失数据,使用弹性分布式数据集(RDD)来保证数据的可靠性。
4.灵活性:支持多种数据源,包括 Kafka、Flume、HDFS、TCP 套接字等,适用于各种数据流输入。
5.高级 API:提供窗口操作、状态管理、连接到外部数据源等高级操作。
工作原理:
Spark Streaming 接收实时输入的数据流,并将其分成小批次,每个批次的数据都被转换成 Spark 的 RDD,然后利用 Spark 的批处理引擎进行处理。DStream 上的任何操作都转换为在底层 RDD 上的操作,这些底层 RDD 转换是由 Spark 引擎计算的 。
应用场景包括:
- 实时监控和分析。
- 事件驱动的应用程序。
- 实时数据仓库更新。
- 实时特征计算和机器学习。
spark作为开源的分布式计算系统,被广泛利用,尤其是在实时数据同步功能上,如FineDataLink内嵌了Spark计算引擎以增强数据同步过程中的处理和计算能力,结合ETL任务的异步/并发读写机制,保证了在数据同步和数据处理场景下的高性能表现

帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,内嵌spark计算引擎拥有强大数据同步处理能力。同时通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
了解更多数据同步与数据集成关干货内容请关注>>>FineDataLink官网
免费试用、获取更多信息,点击了解更多>>>体验FDL功能
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » spark计算引擎-架构和应用

发表评论 取消回复