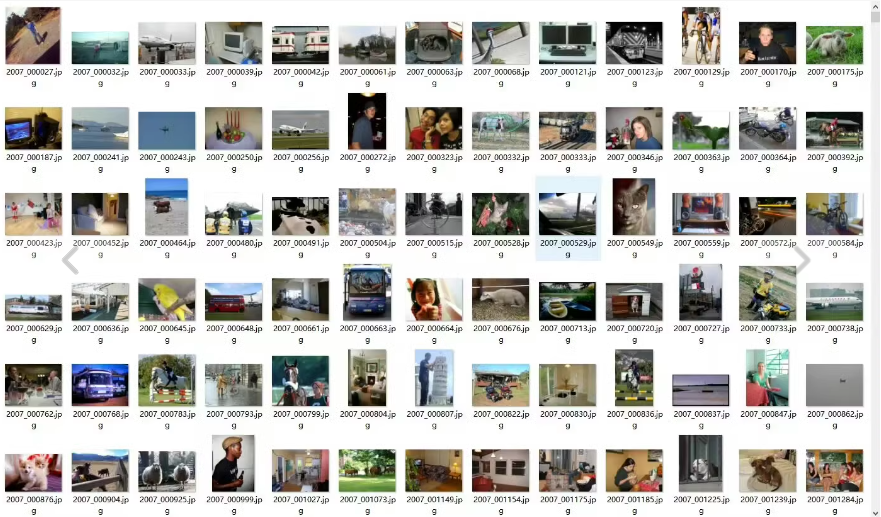
VOC2012数据集是PASCAL VOC挑战赛官方使用的数据集之一,主要包含20类物体,这些物体包括人、动物(如猫、狗、鸟等)、交通工具(如车、船、飞机等)以及家具(如椅子、桌子、沙发等)。每个图像平均包含2.4个目标,所有标注的图片都带有目标检测所需的标签。VOC2012数据集分为trainval和test两部分,其中trainval部分包含11540张图片共27450个物体,主要用于训练和验证;test部分包含11530张图片,用于测试。 VOC2012数据集的分类包括: 人 动物:鸟、猫、牛、狗、马、羊 车辆:飞机、自行车、船、巴士、汽车、摩托车、火车 室内:瓶、椅子、餐桌、盆栽植物、沙发、电视/监视器 此外,VOC2012数据集还提供了丰富的文件夹结构,包括Annotations(存放xml格式的标签文件)、ImageSets(包含不同任务的图像集信息)、JPEGImages(存放原始图像文件)、SegmentationClass(类别分割label图)和SegmentationObject(实例分割label图)等,这些文件夹为不同的计算机视觉任务提供了便利。 VOC2012数据集是目标检测和图像分割等领域研究的重要基准之一,广泛应用于监督学习中的标签数据提供,支持图像分类、目标检测识别、图像分割等多类任务。
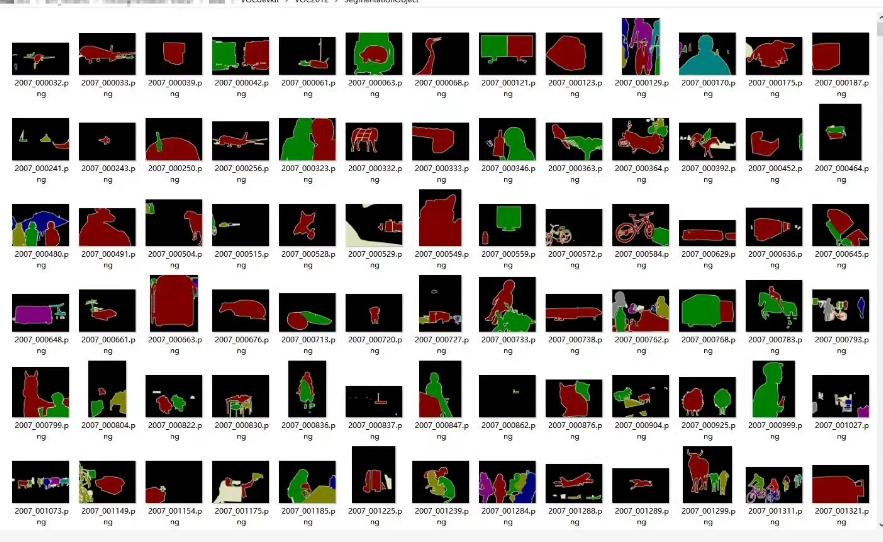
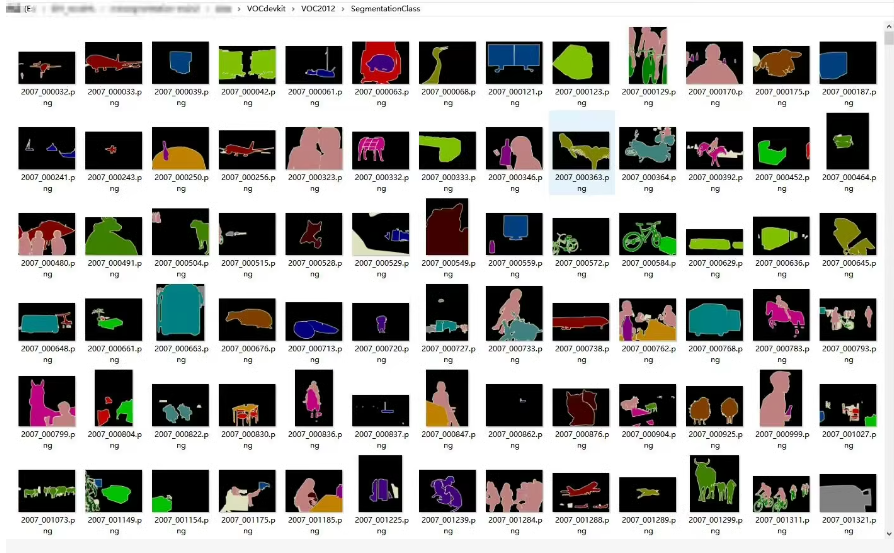
PASCAL VOC 2012 数据集介绍
数据集名称
PASCAL Visual Object Classes (VOC) 2012
数据集概述
PASCAL VOC 2012 是一个广泛使用的计算机视觉数据集,主要用于图像分类、目标检测、语义分割和实例分割等任务。该数据集由一系列的挑战赛和相关的基准测试组成,旨在促进物体识别领域的研究和发展。PASCAL VOC 2012 是其中的一个版本,它继承了之前版本的特点,并在此基础上进行了扩展。
数据集规格
- 总图像数量:23,070张
- 训练验证集 (trainval):11,540张图像,共27,450个物体
- 测试集 (test):11,530张图像
- 类别:涵盖20种常见的物体类别,包括人、动物(如猫、狗、鸟等)、交通工具(如车、船、飞机等)以及家具(如椅子、桌子、沙发等)。
- 标注格式:
- VOC格式:每个图像对应一个XML文件,包含边界框坐标及类别信息。
- 分割标签:提供像素级别的分割标签,用于语义分割和实例分割任务。
数据集结构
VOC2012/
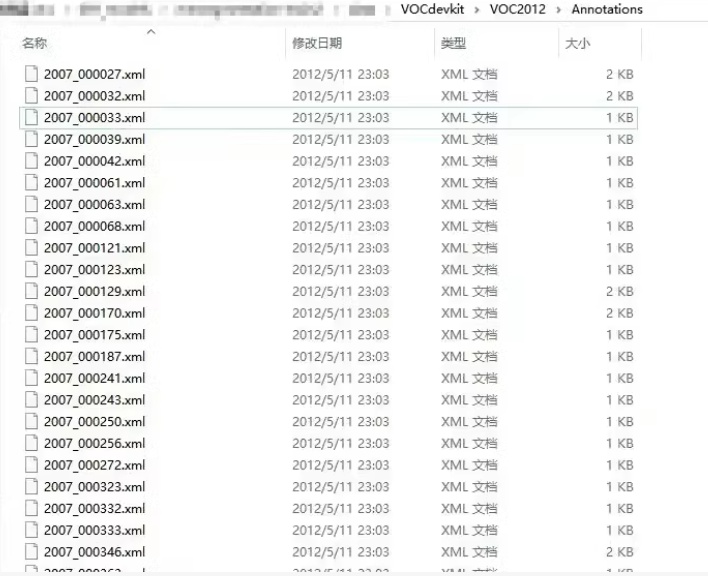
├── Annotations/ # 存放XML格式的标签文件
├── ImageSets/ # 包含不同任务的图像集信息
│ ├── Action/ # 动作识别任务
│ ├── Layout/ # 布局任务
│ ├── Main/ # 主要分类任务
│ ├── Segmentation/ # 分割任务
│ └── Video/ # 视频任务
├── JPEGImages/ # 存放原始图像文件
├── SegmentationClass/ # 类别分割label图
├── SegmentationObject/ # 实例分割label图
└── README.txt # 数据集说明文件Annotations/目录下存放的是每个图像对应的XML格式的标签文件,包含了边界框坐标及类别信息。ImageSets/目录下包含多个子目录,每个子目录提供了针对不同任务的图像列表,例如分类、检测、分割等。JPEGImages/目录下存放的是原始图像文件。SegmentationClass/目录下存放的是像素级别的类别分割标签图。SegmentationObject/目录下存放的是像素级别的实例分割标签图。
数据集配置文件
对于不同的任务,PASCAL VOC 2012 提供了相应的配置文件。例如,在使用YOLO或其他目标检测框架时,可以创建一个类似于以下的配置文件 data.yaml:
# 训练集图像路径
train: path_to_your_train_images
# 验证集图像路径
val: path_to_your_val_images
# 测试集图像路径(如果有的话)
test: path_to_your_test_images
# 类别数量
nc: 20
# 类别名称
names: [
'aeroplane',
'bicycle',
'bird',
'boat',
'bottle',
'bus',
'car',
'cat',
'chair',
'cow',
'diningtable',
'dog',
'horse',
'motorbike',
'person',
'pottedplant',
'sheep',
'sofa',
'train',
'tvmonitor'
]标注统计
- 平均每个图像的目标数:2.4个
- 总计 (total):
- 训练验证集 (trainval):11,540张图像,共27,450个物体
- 测试集 (test):11,530张图像
使用说明
-
准备环境:
- 确保安装了必要的软件库以支持所选版本的目标检测模型或分割模型。例如,对于YOLOv5,可以使用以下命令安装依赖库:
pip install -r requirements.txt
- 确保安装了必要的软件库以支持所选版本的目标检测模型或分割模型。例如,对于YOLOv5,可以使用以下命令安装依赖库:
-
数据预处理:
- 将图像和标注文件分别放在相应的目录下。
- 修改配置文件中的路径以匹配你的数据集位置。
- 如果需要,可以使用脚本将VOC格式的标注文件转换为其他格式(如YOLO格式),或者反之。
-
修改配置文件:
- 更新配置文件以反映正确的数据路径。
- 如果使用特定版本的YOLO或其他模型,还需要更新相应的模型配置文件(如
models/yolov5s.yaml)。
-
开始训练:
- 使用提供的训练脚本启动模型训练过程。例如,对于YOLOv5,可以使用以下命令进行训练: bash
深色版本
python train.py --img 640 --batch 16 --epochs 100 --data data.yaml --weights yolov5s.pt
- 使用提供的训练脚本启动模型训练过程。例如,对于YOLOv5,可以使用以下命令进行训练: bash
-
性能评估:
- 训练完成后,使用验证集或测试集对模型进行评估,检查mAP等指标是否达到预期水平。例如,对于YOLOv5,可以使用以下命令进行评估: bash
深色版本
python val.py --data data.yaml --weights runs/train/exp/weights/best.pt --img 640
- 训练完成后,使用验证集或测试集对模型进行评估,检查mAP等指标是否达到预期水平。例如,对于YOLOv5,可以使用以下命令进行评估: bash
-
部署应用:
- 将训练好的模型应用于实际场景中,实现物体检测、分类或分割功能。例如,可以使用以下命令进行推理: bash
深色版本
python detect.py --source path_to_your_test_images --weights runs/train/exp/weights/best.pt --conf 0.4
- 将训练好的模型应用于实际场景中,实现物体检测、分类或分割功能。例如,可以使用以下命令进行推理: bash
注意事项
- 数据增强:可以通过调整数据增强策略来进一步提高模型性能,例如随机裁剪、旋转、亮度对比度调整等。
- 超参数调整:根据实际情况调整学习率、批大小等超参数,以获得最佳训练效果。
- 硬件要求:建议使用GPU进行训练,以加快训练速度。如果没有足够的计算资源,可以考虑使用云服务提供商的GPU实例。
- 平衡数据:注意数据集中各类别之间的不平衡问题,可以通过过采样、欠采样或使用类别权重等方式来解决。
- 复杂背景:图像中的背景可能非常复杂,因此在训练时需要注意模型对这些特性的适应性。
- 多目标检测:在同一张图像中可能同时出现多个目标,确保模型能够正确区分并定位这些目标。
通过上述步骤,你可以成功地使用PASCAL VOC 2012数据集进行多种计算机视觉任务的研究和开发。该数据集是目标检测、图像分割等领域的重要基准之一,广泛应用于监督学习中的标签数据提供,支持图像分类、目标检测识别、图像分割等多类任务。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » PASCAL VOC 2012数据集 20类物体,这些物体包括人、动物(如猫、狗、鸟等)、交通工具(如车、船、飞机等)以及家具(如椅子、桌子、沙发等)。

发表评论 取消回复