爬虫有几部分功能???
1.发请求,获得网页源码 #1.和2是在一步的 发请求成功了之后就能直接获得网页源码
2.解析我们想要的数据
3.按照需求保存
注意:开始爬虫前,需要给其封装
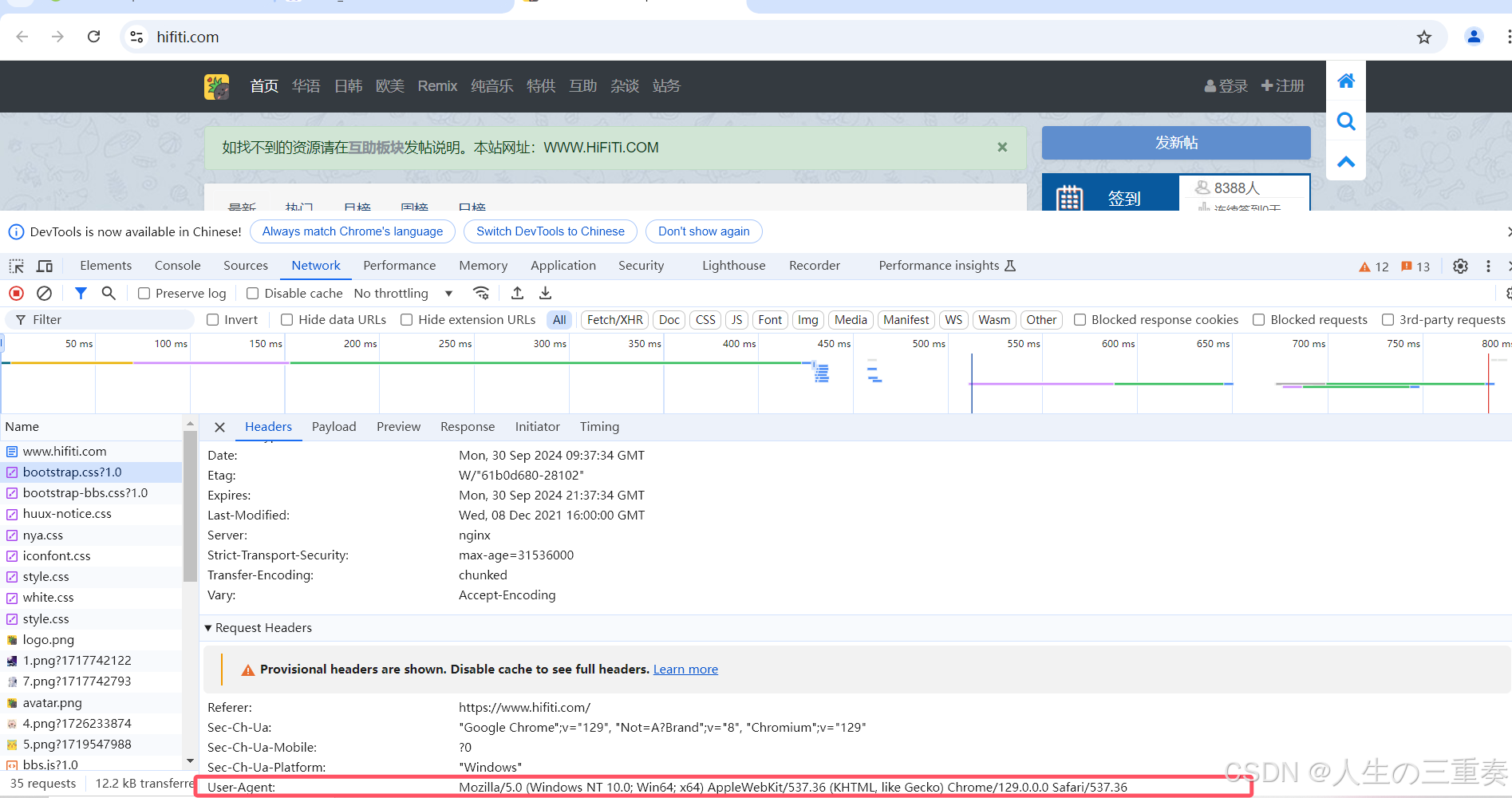
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
爬虫分析:
第一步:从列表页抓取详情页面的链接
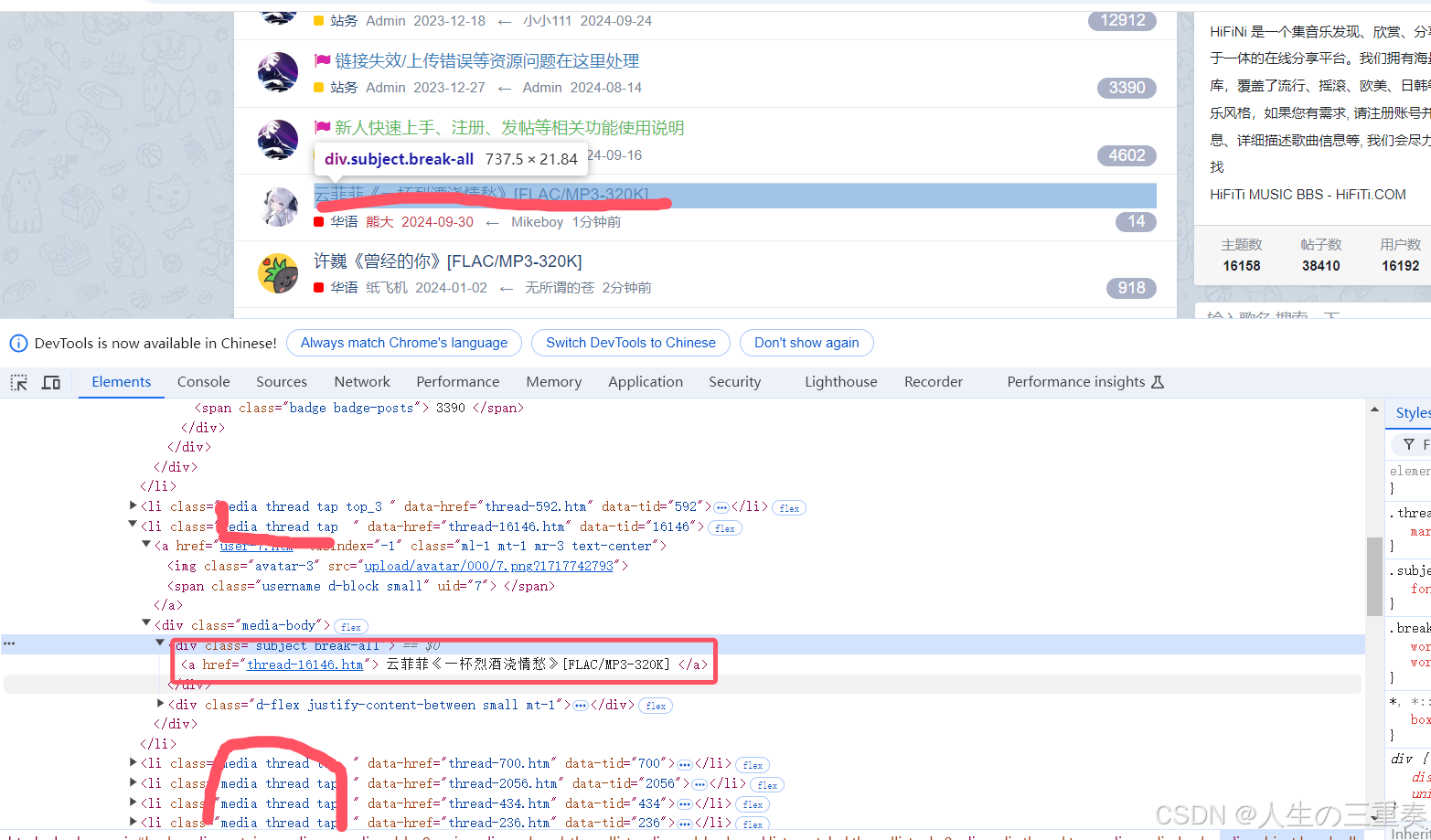
正则表达式:
<li\sclass="media\sthread\stap\s\s".*?>.*?<div\sclass="subject\sbreak-all">.*?<a\shref="(.*?)">(.*?)</a>
得到如下结果
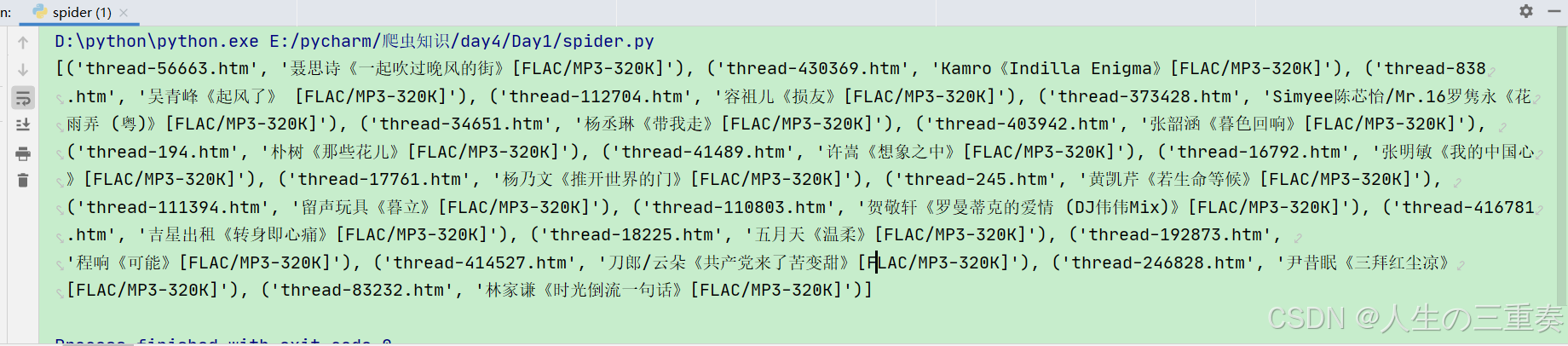
从以上结果可以看出,此链接不可直接点击,缺少https://www.hifini.com/这一部分
https://www.hifini.com/thread-20945.htm
因此如下处理
for i in result:
# print(i)#元祖下标取值
href = "https://www.hifini.com/"+i[0]
name = i[1]
print(href)
print(name)
print('======================')
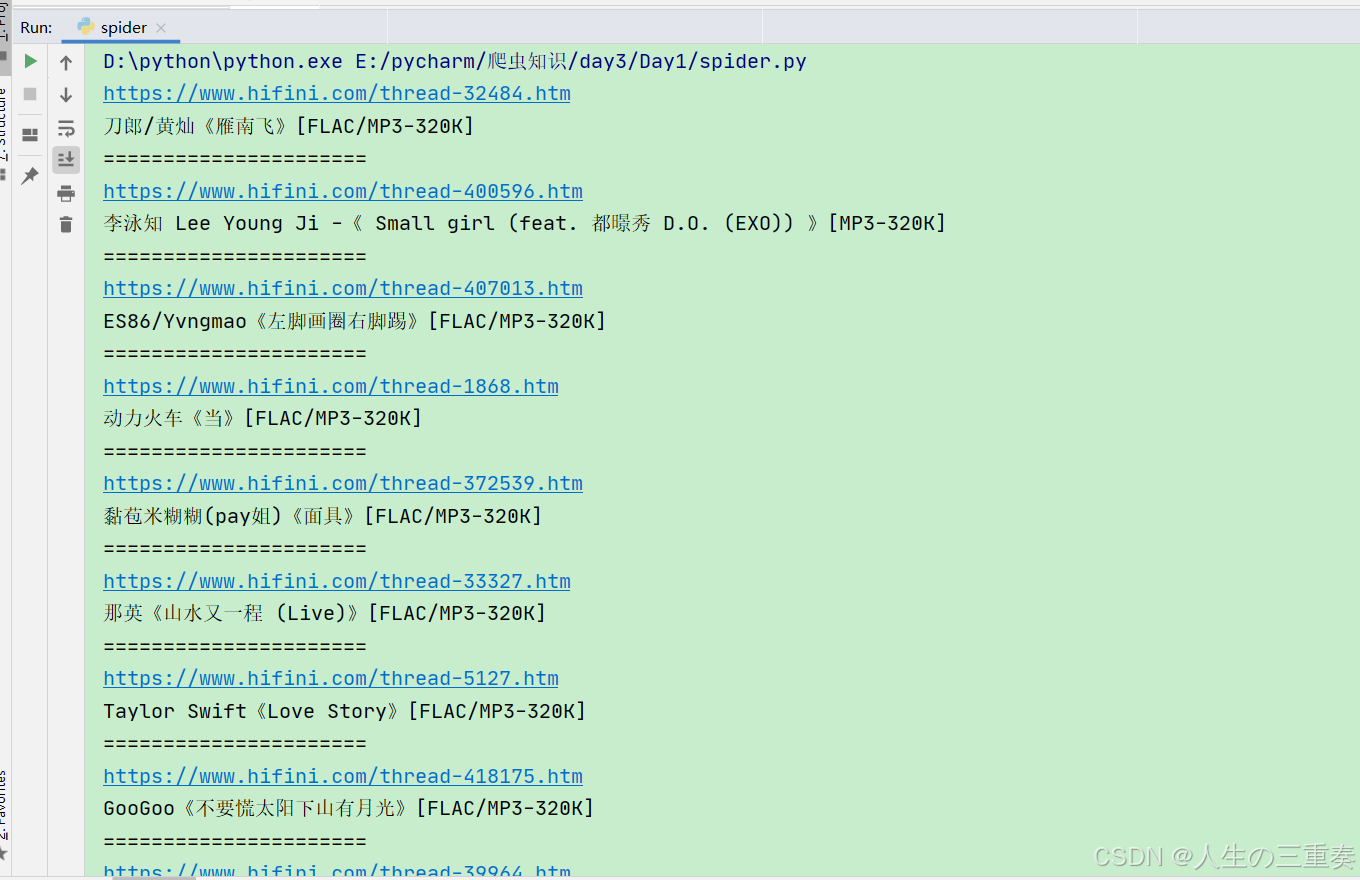
第二步:获取歌曲播放资源
找到歌曲url的xpath:
music:\s\[.*?title:\s'(.*?)',.*?url:\s'(.*?)'
代码:
#解析歌曲的播放组员
song_re = "music:\s\[.*?title:\s'(.*?)',.*?url:\s'(.*?)'"
r = re.findall(song_re,song_html_data,re.S)
# print('歌曲信息',r)
for i in r:
song_name = i[0]
song_link = "https://www.hifini.com/"+i[1]
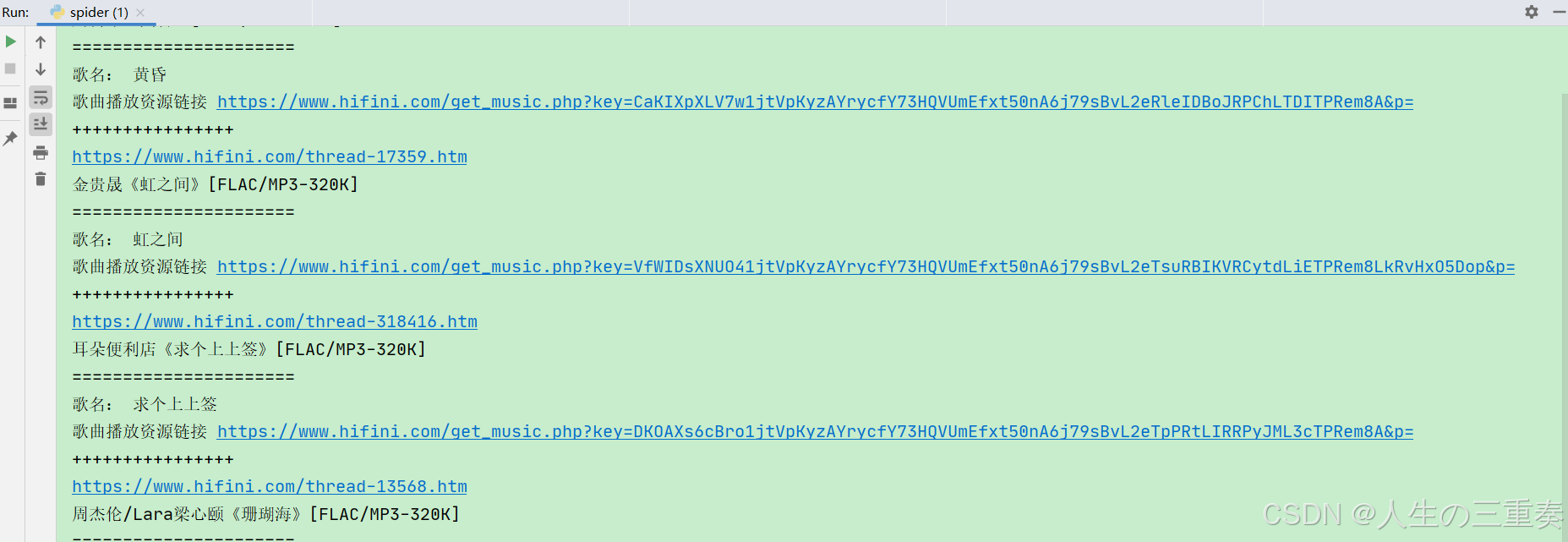
print('歌名:',song_name)
print("歌曲播放资源链接",song_link)
print('++++++++++++++++')
第三步:再次像歌曲播放资源链接发请求 获得二进制数据,进行保存
1.创建文件夹
#保存歌曲 先创建一个文件夹 导入os模块
#判断文件是否存在
if not os.path.exists('歌曲'):
os.makedirs("歌曲")
2.创建文件流,将歌曲保存在文件夹中
with open('歌曲\{}.m4a'.format(song_name),'wb')as f:
f.write(data_bytes)
代码:
import requests
import re
import os
shouye_url = 'https://www.hifini.com/'
# 1.起始目标
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36'
}
response = requests.get(shouye_url, headers=headers)
#1.发请求,获得网页源码
def get_data(url):
response = requests.get(url,headers=headers)
# print(response.status_code)
# print(response.text)
if response.status_code == 200:
return response.text
#2.解析我们想要的数据
def parse_data(data):#形参站位 模拟的就是爬虫爬取下来的源码
z ='<li\sclass="media\sthread\stap\s\s".*?>.*?<div\sclass="subject\sbreak-all">.*?<a\shref="(.*?)">(.*?)</a>'
result = re.findall(z,data,re.S)
# print(result)
# https://www.hifini.com/thread-20945.htm
for i in result:
# print(i)#元祖下标取值
href = "https://www.hifini.com/"+i[0]
name = i[1]
print(href)
print(name)
print('======================')
get_song_link(href)
#https://www.hifini.com/get_music.php?key=2Ydoqazb8E6jj+Nvl6rZLnuh3Fu1MRARle/srx5zQfZVMkPqsGrSzFHehon89oIENCUU19ru3GEJax60Ew
# 像详情页发请求 获得网页源码
def get_song_link(link):#link模拟的是详情页的url
song_html_data = get_data(link)
# print("详情页的网页源码",song_html_data)
#解析歌曲的播放组员
song_re = "music:\s\[.*?title:\s'(.*?)',.*?url:\s'(.*?)'"
r = re.findall(song_re,song_html_data,re.S)
# print('歌曲信息',r)
for i in r:
song_name = i[0]
song_link = "https://www.hifini.com/"+i[1]
print('歌名:',song_name)
print("歌曲播放资源链接",song_link)
print('++++++++++++++++')
#再次像歌曲播放资源链接发请求 获得二进制数据
data_bytes = requests.get(song_link,headers=headers).content
# print(data_bytes)
#保存歌曲 先创建一个文件夹 导入os模块
#判断文件是否存在
if not os.path.exists('歌曲'):
os.makedirs("歌曲")
with open('歌曲\{}.m4a'.format(song_name),'wb')as f:
f.write(data_bytes)
#对应的功能写在不同的函数里面 如果需要互用功能 互相调用即可
if __name__ == '__main__':
h = get_data(shouye_url)
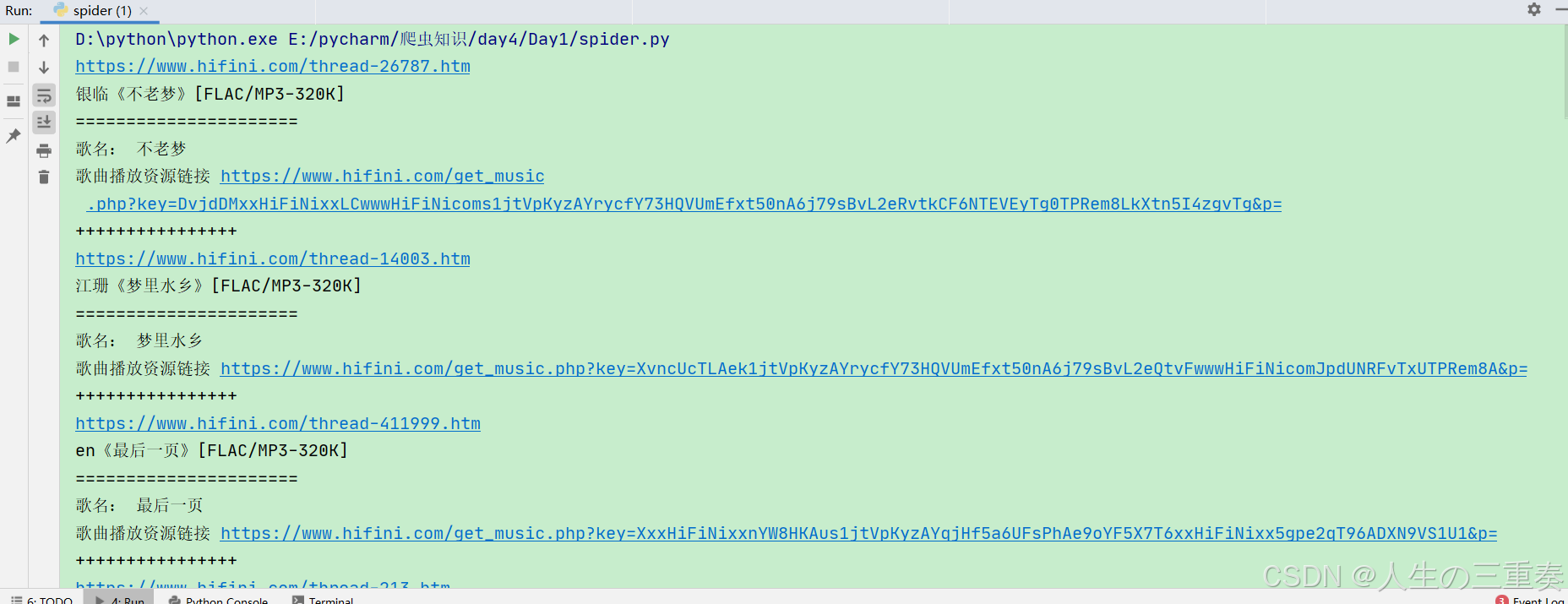
parse_data(h)结果:
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 爬虫——爬取小音乐网站

发表评论 取消回复