一、需求分析
假设有n个互不相交的集合
◼问题1:给定某个集合中的一个元素,查找该元素属于哪个集合?
◼问题2:如何合并两个集合?
实例:
有n个村庄,有些村庄之间有连接的路,有些没有(有路连接的村庄视为同一个集合)
设计一个数据结构,能快速的执行下面两个操作
◼查询2个村庄之间是否有连接的路
◼连接两个的村庄
若使用数组、线性链表等其两者操作的复杂度至少是O(n),而并查集能够办到查询、连接的均摊时间复杂度都是O(log2n),非常适合解决这类“连接”相关的问题。
二、并查集
顾名思义,并查集是一种对集合以及集合里元素操作的结构,其中“并”就是合并,“查”就是查询某元素属于哪个集合,这也是它的两大核心操作
◼查找(Find):查找元素所在的集合(这里的集合指的是逻辑上(数学上)的集合而不是具体某个特定集合)
◼合并(Union):将两个元素所在的集合合并为一个集合
如何选择并查集的存储结构?从树的形状出发,我们知道一棵树上的叶子必定属于同一棵树(额,这好像是废话),把树看作集合,叶子作为集合的元素。给定一片叶子,找到它对应的树干(或根)就可以确定叶子的归属。数据结构中树的常用存储结构有三种方式:【双亲表示法,孩子表示法,孩子兄弟表示法】我们选择双亲表示法,因为这种设计方法很适合找到根结点,从而很容易确定元素所属集合。对于合并集合,我们只需要修改其中一个集合的parent指向另一个集合的 “根” 即可。
双亲表示法:
给定一块连续的内存空间存货结点,给每个结点附设一个指针器,指示它的双亲结点在存储空间中的位置
其存储表示如下:
#define MAX_TREE_SIZE 20
typedef int TElemType;
typedef struct {
TElemType num;
int parent;
} TNode;
typedef struct {
TNode nodes[MAX_TREE_SIZE];
int length;//结点数
} PTree
//并查集的存储表示(为了方便直接使用数组(集合为数集),且num既是集合中的元素也是结点本身在存储空间中的位置)
typedef TNode unionFind[MAX_TREE_SIZE];
(备注:为了方便直接使用数组(集合为数集),且num即是集合中的元素也是结点本身在存储空间中的位置)
三、代码实现
规定:用一块连续的内存空间存储n个集合的全部元素,每个集合对应一棵树,树的根结点的parent值记为 -1
3.1 Find函数
//查找元素e所属的集合,即找到该集合的“根”元素,返回根元素
TElemType* Find(unionFind uf,TElemType e){
int root=e;//当前元素本身
int x=uf[e].parent;//e的双亲所在的位置
while(x!=-1){
root=x;
x=uf[x].parent;
}
return root;
}
时间复杂度
最坏:O(n)、平均:O(log2n)、最好:O(1)
3.2 Union函数
//合并两个集合,rooti(i=1,2)为集合的根
void Union(unionFind uf,int root1,int root2){
if(root1==root2) return;//如果是同一个集合,不用合并
uf[root2].parent=root1;
}
时间复杂度O(1)
3.3 优化1
在进行Find的时,发现查找的长度和树的高度有关,且最坏时间复杂度是O(n),这时棵树变成了单支树(退化成为链表)。因此,可以从树高的角度出发减少树高从而达到优化Find的时间效率。优化思路是在每次Union的时候,尽可能的让树 “不长高”,让小的树合并到大的树(树的大小指的是结点数量的多少)或者是让矮的树合并到高树上。下面采用第一种,这种方法需要有一个计数器保存一个集合(树)的大小,我们直接利用一个集合的“根”的parent来保存集合的大小,同时为了保留根的标识(parent为-1),parent==集合大小的相反数。
void Union(unionFind uf,root1,root2){
if(uf[root1].parent<uf[root2].parent){
uf[root1].parent+=uf[root2].parent;
uf[root2].parent=root1;
}else{
uf[root2].parent+=uf[root1].parent;
uf[root1].parent=root2;
}n
}
优化后,Find最坏的时间复杂度变为:O(log2n)
(第二种方法—矮树合并到高树上,如何实现,大家可以自行思考)
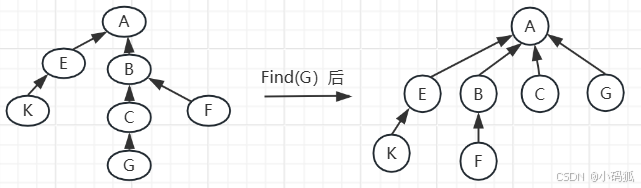
3.4 终极优化2—压缩策略
所谓压缩是指压缩树的高度。我们对Find操作进行优化,当执行Find时,我们把传入的元素到根的路径上的结点(包含元素本身所在的结点)全部都直接挂在根的孩子位置上(如果已经是根的孩子了,则不用修改)。当再次查找该元素所属集合时,只需要常数级别的操作就可以完成查找。
void Find(unionFind uf,TElemType e){
int root=e;//当前元素本身
int x=uf[e].parent;//当前元素的双亲位置
//找到元素所在集合的”根“
while(x>=0){
root=x;
x=uf[e].parent;
}
while(e!=root){
int t=uf[e].parent;//t表示路径上元素的位置,t等价uf[uf[e].parent].num,前面黄字部分已表明
uf[e].parent=root;
e=uf[t].num;
}
return root;
}
如下图,调用Find后
优化后时间复杂度
最坏:
O
(
α
(
n
)
)
O(\alpha(n))
O(α(n)),其中,
α
(
n
)
\alpha(n)
α(n)是比log2n增长速度小的数量级
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 并查集【数据结构与算法】【C语言版-笔记】

发表评论 取消回复